使用Sharding-JDBC对数据进行分片处理详解
目录
- 前言
- 一、加入依赖
- 二、修改application.yml配置文件
- 三、数据源定义
- 四、数据源分配算法实现
- 五、数据表分配算法
- 六、数据源配置
- 七、开始测试
- 定义一个实体
- 定义实体DAO
- 测试类,插入1000条user数据
- 效果:数据被分片存储到0~9的数据表中
前言
Sharding-JDBC是ShardingSphere的第一个产品,也是ShardingSphere的前身。
它定位为轻量级Java框架,在Java的JDBC层提供的额外服务。它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
- 适用于任何基于Java的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
- 基于任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等支持任意实现JDBC规范的数据库。
- 目前支持MySQL,Oracle,SQLServer和PostgreSQL。
Sharding-JDBC的使用需要我们对项目进行一些调整:结构如下
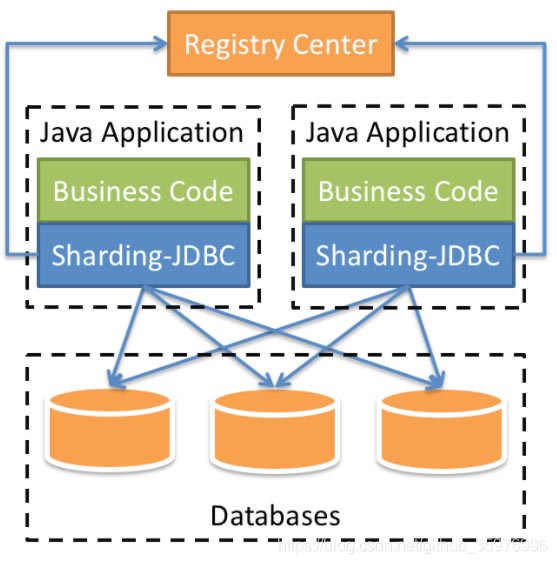
这里使用的是springBoot项目改造
一、加入依赖
<!-- 这里使用了druid连接池 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.9</version>
</dependency>
<!-- sharding-jdbc 包 -->
<dependency>
<groupId>com.dangdang</groupId>
<artifactId>sharding-jdbc-core</artifactId>
<version>1.5.4</version>
</dependency>
<!-- 这里使用了雪花算法生成组建,这个算法的实现的自己写的代码,各位客关老爷可以修改为自己的id生成策略 -->
<dependency>
<groupId>org.kcsm.common</groupId>
<artifactId>kcsm-idgenerator</artifactId>
<version>3.0.1</version>
</dependency>
二、修改application.yml配置文件
#启动接口
server:
port: 30009
spring:
jpa:
database: mysql
show-sql: true
hibernate:
# 修改不自动更新表
ddl-auto: none
#数据源0定义,这里只是用了一个数据源,各位客官可以根据自己的需求定义多个数据源
database0:
databaseName: database0
url: jdbc:mysql://kcsm-pre.mysql.rds.aliyuncs.com:3306/dstest?characterEncoding=utf8&useUnicode=true&useSSL=false&serverTimezone=Hongkong
username: root
password: kcsm@111
driverClassName: com.mysql.jdbc.Driver
三、数据源定义
package com.lzx.code.codedemo.config;
import com.alibaba.druid.pool.DruidDataSource;
import lombok.Data;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.stereotype.Component;
import javax.sql.DataSource;
/**
* 描述:数据源0定义
*
* @Auther: lzx
* @Date: 2019/9/9 15:19
*/
@Data
@ConfigurationProperties(prefix = "database0")
@Component
public class Database0Config {
private String url;
private String username;
private String password;
private String driverClassName;
private String databaseName;
public DataSource createDataSource() {
DruidDataSource result = new DruidDataSource();
result.setDriverClassName(getDriverClassName());
result.setUrl(getUrl());
result.setUsername(getUsername());
result.setPassword(getPassword());
return result;
}
}
四、数据源分配算法实现
package com.lzx.code.codedemo.config;
import com.dangdang.ddframe.rdb.sharding.api.ShardingValue;
import com.dangdang.ddframe.rdb.sharding.api.strategy.database.SingleKeyDatabaseShardingAlgorithm;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import java.util.ArrayList;
import java.util.Collection;
import java.util.List;
/**
* 描述:数据源分配算法
*
* 这里我们只用了一个数据源,所以所有的都只返回了数据源0
*
* @Auther: lzx
* @Date: 2019/9/9 15:27
*/
@Component
public class DatabaseShardingAlgorithm implements SingleKeyDatabaseShardingAlgorithm {
@Autowired
private Database0Config database0Config;
/**
* = 条件时候返回的数据源
* @param collection
* @param shardingValue
* @return
*/
@Override
public String doEqualSharding(Collection collection, ShardingValue shardingValue) {
return database0Config.getDatabaseName();
}
/**
* IN 条件返回的数据源
* @param collection
* @param shardingValue
* @return
*/
@Override
public Collection<String> doInSharding(Collection collection, ShardingValue shardingValue) {
List<String> result = new ArrayList<String>();
result.add(database0Config.getDatabaseName());
return result;
}
/**
* BETWEEN 条件放回的数据源
* @param collection
* @param shardingValue
* @return
*/
@Override
public Collection<String> doBetweenSharding(Collection collection, ShardingValue shardingValue) {
List<String> result = new ArrayList<String>();
result.add(database0Config.getDatabaseName());
return result;
}
}
五、数据表分配算法
package com.lzx.code.codedemo.config;
import com.dangdang.ddframe.rdb.sharding.api.ShardingValue;
import com.dangdang.ddframe.rdb.sharding.api.strategy.table.SingleKeyTableShardingAlgorithm;
import com.google.common.collect.Range;
import org.springframework.stereotype.Component;
import java.util.Collection;
import java.util.LinkedHashSet;
/**
* 描述: 数据表分配算法的实现
*
* @Auther: lzx
* @Date: 2019/9/9 16:19
*/
@Component
public class TableShardingAlgorithm implements SingleKeyTableShardingAlgorithm<Long> {
/**
* = 条件时候返回的数据源
* @param collection
* @param shardingValue
* @return
*/
@Override
public String doEqualSharding(Collection<String> collection, ShardingValue<Long> shardingValue) {
for (String eaach:collection) {
Long value = shardingValue.getValue();
value = value >> 22;
if(eaach.endsWith(value%10+"")){
return eaach;
}
}
throw new IllegalArgumentException();
}
/**
* IN 条件返回的数据源
* @param tableNames
* @param shardingValue
* @return
*/
@Override
public Collection<String> doInSharding(Collection<String> tableNames, ShardingValue<Long> shardingValue) {
Collection<String> result = new LinkedHashSet<>(tableNames.size());
for (Long value : shardingValue.getValues()) {
for (String tableName : tableNames) {
value = value >> 22;
if (tableName.endsWith(value % 10 + "")) {
result.add(tableName);
}
}
}
return result;
}
/**
* BETWEEN 条件放回的数据源
* @param tableNames
* @param shardingValue
* @return
*/
@Override
public Collection<String> doBetweenSharding(Collection<String> tableNames, ShardingValue<Long> shardingValue) {
Collection<String> result = new LinkedHashSet<>(tableNames.size());
Range<Long> range = shardingValue.getValueRange();
for (Long i = range.lowerEndpoint(); i <= range.upperEndpoint(); i++) {
for (String each : tableNames) {
Long value = i >> 22;
if (each.endsWith(i % 10 + "")) {
result.add(each);
}
}
}
return result;
}
}
六、数据源配置
package com.lzx.code.codedemo.config;
import com.dangdang.ddframe.rdb.sharding.api.ShardingDataSourceFactory;
import com.dangdang.ddframe.rdb.sharding.api.rule.DataSourceRule;
import com.dangdang.ddframe.rdb.sharding.api.rule.ShardingRule;
import com.dangdang.ddframe.rdb.sharding.api.rule.TableRule;
import com.dangdang.ddframe.rdb.sharding.api.strategy.database.DatabaseShardingStrategy;
import com.dangdang.ddframe.rdb.sharding.api.strategy.table.TableShardingStrategy;
import com.dangdang.ddframe.rdb.sharding.keygen.DefaultKeyGenerator;
import com.dangdang.ddframe.rdb.sharding.keygen.KeyGenerator;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.sql.DataSource;
import java.sql.SQLException;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Map;
/**
* 描述:数据源配置
*
* @Auther: lzx
* @Date: 2019/9/9 15:21
*/
@Configuration
public class DataSourceConfig {
@Autowired
private Database0Config database0Config;
@Autowired
private DatabaseShardingAlgorithm databaseShardingAlgorithm;
@Autowired
private TableShardingAlgorithm tableShardingAlgorithm;
@Bean
public DataSource getDataSource() throws SQLException {
return buildDataSource();
}
private DataSource buildDataSource() throws SQLException {
//分库设置
Map<String, DataSource> dataSourceMap = new HashMap<>(2);
//添加两个数据库database0和database1
dataSourceMap.put(database0Config.getDatabaseName(), database0Config.createDataSource());
//设置默认数据库
DataSourceRule dataSourceRule = new DataSourceRule(dataSourceMap, database0Config.getDatabaseName());
//分表设置,大致思想就是将查询虚拟表Goods根据一定规则映射到真实表中去
TableRule orderTableRule = TableRule.builder("user")
.actualTables(Arrays.asList("user_0", "user_1", "user_2", "user_3", "user_4", "user_5", "user_6", "user_7", "user_8", "user_9"))
.dataSourceRule(dataSourceRule)
.build();
//分库分表策略
ShardingRule shardingRule = ShardingRule.builder()
.dataSourceRule(dataSourceRule)
.tableRules(Arrays.asList(orderTableRule))
.databaseShardingStrategy(new DatabaseShardingStrategy("ID", databaseShardingAlgorithm))
.tableShardingStrategy(new TableShardingStrategy("ID", tableShardingAlgorithm)).build();
DataSource dataSource = ShardingDataSourceFactory.createDataSource(shardingRule);
return dataSource;
}
@Bean
public KeyGenerator keyGenerator() {
return new DefaultKeyGenerator();
}
}
七、开始测试
定义一个实体
package com.lzx.code.codedemo.entity;
import com.fasterxml.jackson.annotation.JsonIgnoreProperties;
import com.fasterxml.jackson.databind.annotation.JsonSerialize;
import com.fasterxml.jackson.databind.ser.std.ToStringSerializer;
import lombok.*;
import org.hibernate.annotations.GenericGenerator;
import javax.persistence.*;
/**
* 描述: 用户
*
* @Auther: lzx
* @Date: 2019/7/11 15:39
*/
@Entity(name = "USER")
@Getter
@Setter
@ToString
@JsonIgnoreProperties(ignoreUnknown = true)
@AllArgsConstructor
@NoArgsConstructor
public class User {
/**
* 主键
*/
@Id
@GeneratedValue(generator = "idUserConfig")
@GenericGenerator(name ="idUserConfig" ,strategy="org.kcsm.common.ids.SerialIdGeneratorSnowflakeId")
@Column(name = "ID", unique = true,nullable=false)
@JsonSerialize(using = ToStringSerializer.class)
private Long id;
/**
* 用户名
*/
@Column(name = "USER_NAME",length = 100)
private String userName;
/**
* 密码
*/
@Column(name = "PASSWORD",length = 100)
private String password;
}
定义实体DAO
package com.lzx.code.codedemo.dao;
import com.lzx.code.codedemo.entity.User;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.JpaSpecificationExecutor;
import org.springframework.data.rest.core.annotation.RepositoryRestResource;
/**
* 描述: 用户dao接口
*
* @Auther: lzx
* @Date: 2019/7/11 15:52
*/
@RepositoryRestResource(path = "user")
public interface UserDao extends JpaRepository<User,Long>,JpaSpecificationExecutor<User> {
}
测试类,插入1000条user数据
package com.lzx.code.codedemo;
import com.lzx.code.codedemo.dao.RolesDao;
import com.lzx.code.codedemo.dao.UserDao;
import com.lzx.code.codedemo.entity.Roles;
import com.lzx.code.codedemo.entity.User;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
@RunWith(SpringRunner.class)
@SpringBootTest
public class CodeDemoApplicationTests {
@Autowired
private UserDao userDao;
@Autowired
private RolesDao rolesDao;
@Test
public void contextLoads() {
User user = null;
Roles roles = null;
for(int i=0;i<1000;i++){
user = new User(
null,
"lzx"+i,
"123456"
);
roles = new Roles(
null,
"角色"+i
);
rolesDao.save(roles);
userDao.save(user);
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
效果:数据被分片存储到0~9的数据表中


以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

SpringBoot使用Sharding-JDBC实现数据分片和读写分离的方法
目录 一.Sharding-JDBC简介 二.具体的实现方式 1.maven引用 2.数据库准备 3.Spring配置 4.精准分片算法和范围分片算法的Java代码 5.测试 一.Sharding-JDBC简介 Sharding-JDBC是Sharding-Sphere的一个产品,它有三个产品,分别是Sharding-JDBC.Sharding-Proxy和Sharding-Sidecar,这三个产品提供了标准化的数据分片.读写分离.柔性事务和数据治理功能.我们这里用的是Sharding-JDB
-
基于sharding-jdbc的使用限制
目录 使用限制 JDBC未支持列表 DataSource接口 Connection接口 Statement和PreparedStatement接口 对于ResultSet接口 JDBC 4.1 SQL语句限制 shardingjdbc使用及踩坑内容 1.使用shardingjdbc做分库分表 2.踩坑内容 使用限制 JDBC未支持列表 Sharding-JDBC暂时未支持不常用的JDBC方法. DataSource接口 不支持timeout相关操作 Connection接口 不支持存储过程,函数
-
解决sharding JDBC 不支持批量导入问题
目录 sharding JDBC 不支持批量导入 sharding-jdbc不支持多条sql语句批量更新 修改思路 sharding JDBC 不支持批量导入 package com.ydmes.service.impl.log; import com.ydmes.domain.entity.log.BarTraceBackLog; import org.springframework.beans.BeansException; import org.springframework.contex
-
使用Sharding-JDBC对数据进行分片处理详解
目录 前言 一.加入依赖 二.修改application.yml配置文件 三.数据源定义 四.数据源分配算法实现 五.数据表分配算法 六.数据源配置 七.开始测试 定义一个实体 定义实体DAO 测试类,插入1000条user数据 效果:数据被分片存储到0~9的数据表中 前言 Sharding-JDBC是ShardingSphere的第一个产品,也是ShardingSphere的前身. 它定位为轻量级Java框架,在Java的JDBC层提供的额外服务.它使用客户端直连数据库,以jar包形式提供服务
-
Elasticsearches的集群搭建及数据分片过程详解
目录 Elasticsearch高级之集群搭建,数据分片 广播方式 单播方式 选取主节点 什么是脑裂 错误识别 Elasticsearch高级之集群搭建,数据分片 es使用两种不同的方式来发现对方: 广播 单播 也可以同时使用两者,但默认的广播,单播需要已知节点列表来完成 广播方式 当es实例启动的时候,它发送了广播的ping请求到地址224.2.2.4:54328.而其他的es实例使用同样的集群名称响应了这个请求. 一般这个默认的集群名称就是上面的cluster_name对应的elastics
-
JDBC中resutset接口操作实例详解
本文主要向大家展示JDBC接口中resutset接口的用法实例,下面我们看看具体内容. 1. ResultSet细节1 功能:封锁结果集数据 操作:如何获得(取出)结果 package com.sjx.a; import java.sql.Connection; import java.sql.DriverManager; import java.sql.ResultSet; import java.sql.Statement; import org.junit.Test; //1. next方
-
spring对JDBC和orm的支持实例详解
简介 Spring提供的DAO(数据访问对象)支持主要的目的是便于以标准的方式使用不同的数据访问技术,如JDBC,Hibernate或者JDO等.它不仅可以让你方便地在这些持久化技术间切换, 而且让你在编码的时候不用考虑处理各种技术中特定的异常. 一致的异常层次 Spring提供了一种方便的方法,把特定于某种技术的异常,如SQLException, 转化为自己的异常,这种异常属于以 DataAccessException 为根的异常层次.这些异常封装了原始异常对象,这样就不会有丢失任何错误信息的
-
Java中JDBC实现动态查询的实例详解
一 概述 1.什么是动态查询? 从多个查询条件中随机选择若干个组合成一个DQL语句进行查询,这一过程叫做动态查询. 2.动态查询的难点 可供选择的查询条件多,组合情况多,难以一一列举. 3.最终查询语句的构成 一旦用户向查询条件中输入数据,该查询条件就成为最终条件的一部分. 二 基本原理 1.SQL基本框架 无论查询条件如何,查询字段与数据库是固定不变的,这些固定不变的内容构成SQL语句的基本框架,如 select column... from table. 2.StringBuilder形成D
-
python软件测试Jmeter性能测试JDBC Request(结合数据库)的使用详解
JDBC Request 这个 Sampler 可以向数据库发送一个 jdbc 请求(sql 语句),并获取返回的数据库数据进行操作.它 经常需要和 JDBC Connection Configuration 配置原件(配置数据库连接的相关属性,如连接名.密码 等)一起使用. 1.本文使用的是 mysql 数据库进行测试 数据库的用户名为 root,用户名密码为 *********(看个人数据库用户名和密码填写) 2.数据库中有表:test,表的数据结构如下: 表中数据如下: select *
-
Elasticsearch Recovery索引分片分配详解
目录 基础知识点 减少集群Full Restart造成的数据来回拷贝 减少主副本之间的数据复制 特大热索引为何恢复慢 其他Recovery相关的专家级设置 基础知识点 在Eleasticsearch中recovery指的就是一个索引的分片分配到另外一个节点的过程:一般在快照恢复.索引副本数变更.节点故障.节点重启时发生.由于master保存整个集群的状态信息,因此可以判断出哪些shard需要做再分配,以及分配到哪个结点,例如: 如果某个shard主分片在,副分片所在结点挂了,那么选择另外一个可用
-
python FastApi实现数据表迁移流程详解
目录 啥是数据迁移 1.需要新的数据表 2.需要对现有表结构进行调整 回到ORM 迁移手段 安装alembic 初始化项目 修改alembic.ini 修改alembic/env.py 开始生成迁移工作 变更数据库 FAQ 啥是数据迁移 在我们平时的开发过程中,经常需要对一些数据进行调整.一般会有以下几种场景: 1.需要新的数据表 我们的接口自动化平台虽然已经较为完善了,但难免会继续迭代一些新的功能,假设我们需要做一个订阅用例的功能. 大体想一下就可以知道,订阅用例以后这个数据得持久化(即入库)
-
基于Spring-AOP实现自定义分片工具详解
目录 1.背景 2.Spring-AOP 3.功能实现 3.1 MethodPartAndRetryer 3.2 RetryUtil 3.3 RetryAspectAop 4.功能使用 4.1 配置文件 4.2 代码示例 5.小结 1.背景 随着数据量的增长,发现系统在与其他系统交互时,批量接口会出现超时现象,发现原批量接口在实现时,没有做分片处理,当数据过大时或超过其他系统阈值时,就会出现错误.由于与其他系统交互比较多,一个一个接口去做分片优化,改动量较大,所以考虑通过AOP解决此问题. 2.
-
mysql数据存储过程参数实例详解
MySQL 存储过程参数有三种类型:in.out.inout.它们各有什么作用和特点呢? 一.MySQL 存储过程参数(in) MySQL 存储过程 "in" 参数:跟 C 语言的函数参数的值传递类似, MySQL 存储过程内部可能会修改此参数,但对 in 类型参数的修改,对调用者(caller)来说是不可见的(not visible). drop procedure if exists pr_param_in; create procedure pr_param_in ( in id