Python爬取求职网requests库和BeautifulSoup库使用详解
目录
- 一、requests库
- 1、requests简介
- 2、安装requests库
- 3、使用requests获取网页数据 我们先导入模块
- 4、总结requests的一些方法
- 二、BeautifulSoup库
- 1、BeautifulSoup简介
- 2、安装BeautifulSoup库
- 3、使用BeautifulSoup解析并提取获取的数据
- 4、BeautifulSoup提取数据的方法
一、requests库
1、requests简介
requests库就是一个发起请求的第三方库,requests允许你发送HTTP/1.1 请求,你不需要手动为 URL 添加查询字串,也不需要对 POST 数据进行表单编码。Keep-alive 和 HTTP 连接池的功能是 100% 自动化的,一切动力都来自于根植在 requests 内部的 urllib3。简单来说有了这个库,我们就能轻而易举向对应的网站发起请求,从而对网页数据进行获取,还可以获取服务器返回的响应内容和状态码。
requesets中文文档页面https://requests.kennethreitz.org/zh_CN/latest/
2、安装requests库
一般电脑安装的Python都会自带这个库,如果没有就可在命令行输入下面这行代码安装
pip install requests
3、使用requests获取网页数据 我们先导入模块
import requests
- 对想要获取数据的网站发起请求,以下以qq音乐官网为例
res = requests.get('https://y.qq.com/') #发起请求
print(res) #输出<Response [200]>
输出的200其实就是一个响应状态码,下面给大家列出有可能返回的各状态码含义
| 状态码 | 含义 |
|---|---|
| 1xx | 继续发送信息 |
| 2xx | 请求成功 |
| 3xx | 重定向 |
| 4xx | 客户端错误 |
| 5xx | 服务端错误 |
- 获取qq音乐首页的网页源代码
res = requests.get('https://y.qq.com/') #发起请求
print(res.text) #res.text就是网页的源代码
4、总结requests的一些方法
| 属性 | 含义 |
|---|---|
| res.status_code | HTTP的状态码 |
| res.text | 响应内容的文本 |
| res.content | 响应内容的二进制形式文本 |
| res.encoding | 响应内容的编码 |
既然我们学好了如何获取网页源代码,接下来我们就学习下怎么用BeautifulSoup库对我们获取的内容进行提取。
二、BeautifulSoup库
1、BeautifulSoup简介
BeautifulSoup是Python里的第三方库,处理数据十分实用,有了这个库,我们就可以根据网页源代码里对应的HTML标签对数据进行有目的性的提取。BeautifulSoup库一般与requests库搭配使用。 不熟的HTML标签的最好去百度下,了解一些常用的标签。
2、安装BeautifulSoup库
同样的如果没用这个库,可以通过命令行输入下列代码安装
pip install beautifulsoup4
3、使用BeautifulSoup解析并提取获取的数据
import requests
from bs4 import BeautifulSoup
header={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36'}
res = requests.get('https://y.qq.com/',headers=header) #headers是一种反爬虫措施
soup = BeautifulSoup(res.text,'html.parser') #第一个参数是HTML文本,第二个参数html.parser是Python内置的编译器
print(soup) #输出qq音乐首页的源代码
部分输出结果
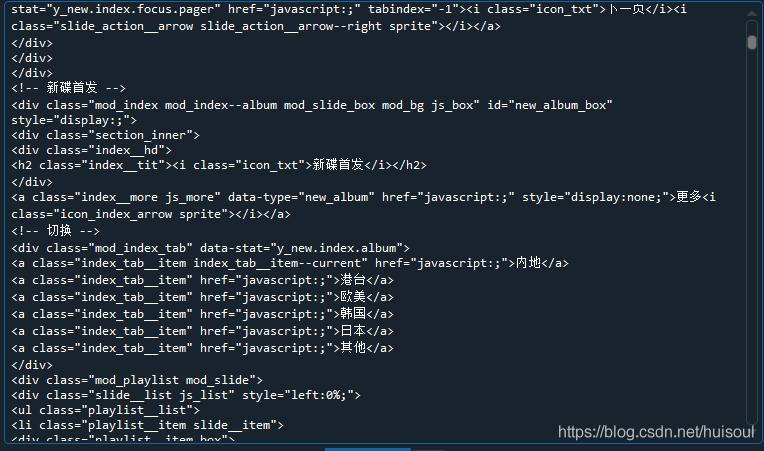
看到输出结果,我们已经成功将网页源代码解析成BeautifulSoup对象。这时可能有人就会问res.text输出的不就是网页代码了吗,何苦再将它转为BeautifulSoup对象呢?
我们先来通过type()函数看下它们的类型
import requests
from bs4 import BeautifulSoup
header={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36'}
res = requests.get('https://y.qq.com/',headers=header) #headers是一种反爬虫措施
soup = BeautifulSoup(res.text,'html.parser') #第一个参数是HTML文本,第二个参数html.parser是Python内置的编译器
print(type(res.text))
print(type(soup))
输出结果

我们可以看到res.text的类型是字符串类型,而soup则是BeautifulSoup对象类型。相比于res.text的字符串类型,soup的BeautifulSoup对象类型拥有着更多可用的方法,以便我们快速提取出需要的数据。这就是为什么我们要多此一步了。
4、BeautifulSoup提取数据的方法
- 先来了解两个最常用的方法
| 方法 | 作用 |
|---|---|
| find() | 返回第一个符合要求的数据 |
| find_all() | 返回所有符合要求的数据 |
这两个函数传入的参数就是我们对数据的筛选条件了,我们可以向这两个函数分别传入什么参数呢?
我们以下面在qq音乐首页截取的源代码片段为例,试用两个函数
<div class="index__hd">
<h2 class="index__tit"><i class="icon_txt">歌单推荐</i></h2>
</div>
<!-- 切换 -->
<div class="mod_index_tab" data-stat="y_new.index.playlist">
<a href="javascript:;" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" class="index_tab__item index_tab__item--current js_tag" data-index="0" data-type="recomPlaylist" data-id="1">为你推荐</a>
<a href="javascript:;" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" class="index_tab__item js_tag" data-type="playlist" data-id="3056">网络歌曲</a>
<a href="javascript:;" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" class="index_tab__item js_tag" data-type="playlist" data-id="3256">综艺</a>
<a href="javascript:;" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" class="index_tab__item js_tag" data-type="playlist" data-id="59">经典</a>
<a href="javascript:;" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" class="index_tab__item js_tag" data-type="playlist" data-id="3317">官方歌单</a>
<a href="javascript:;" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" class="index_tab__item js_tag" data-type="playlist" data-id="71">情歌</a>
</div>
find()函数
如果想要获取歌单推荐这一行的内容,我们就需要先对歌单推荐的HTML标签进行识别,我们发现它在class="icon_txt"的i标签下,接着就可以通过以下这种方法进行提取
import requests
from bs4 import BeautifulSoup
header={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36'}
res = requests.get('https://y.qq.com/',headers=header) #headers是一种反爬虫措施
soup = BeautifulSoup(res.text,'html.parser') #第一个参数是HTML文本,第二个参数html.parser是Python内置的编译器
print(soup.find('i', class_='icon_txt')) #找到 class_='icon_txt'的 i 标签
因为 class 是 Python 中定义类的关键字,所以用 class_ 表示 HTML 中的 class
输出结果

find_all()函数
如果我们想要把歌单推荐的全部主题提取下来的话,就要用到find_all()函数
同样的,我们发现这几个主题都在 class="index_tab__item js_tag"的 a标签下,这时为了避免筛选到源代码中其他同为class="index_tab__item js_tag"的标签,我们需要再加多一个条件data-type=“playlist”,具体怎么操作呢?
import requests
from bs4 import BeautifulSoup
header={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36'}
res = requests.get('https://y.qq.com/',headers=header) #headers是一种反爬虫措施
soup = BeautifulSoup(res.text,'html.parser') #第一个参数是HTML文本,第二个参数html.parser是Python内置的编译器
print(soup.find('i', class_='icon_txt'))
items = soup.find_all('a',attrs={"class" :"index_tab__item js_tag","data-type":"playlist"})
实现的方法就是在第二个参数处传入一个键值对,在里面添加筛选的属性
输出结果

通过上面两个小案例,我们发现find()和find_all()函数返回的是Tag对象和Tag对象组成的列表,而我们需要的并不是这一大串东西,我们需要的只是Tag对象的text属性或者href(链接)属性,实现代码如下
import requests
from bs4 import BeautifulSoup
header={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36'}
res = requests.get('https://y.qq.com/',headers=header) #headers是一种反爬虫措施
soup = BeautifulSoup(res.text,'html.parser') #第一个参数是HTML文本,第二个参数html.parser是Python内置的编译器
tag1=soup.find('i', class_='icon_txt')
print(tag1.text)
items = soup.find_all('a',attrs={"class" :"index_tab__item js_tag","data-type":"playlist"})
for i in items: #遍历列表
tag2=i.text
print(tag2)
输出结果

这样我们就成功把主题的文本内容获取了,而想要提取标签中的属性值,则可以用对象名[‘属性']的方法获取,这里就不演示了
本次分享就到这里了,在下次介绍完反爬虫和如何将数据写进文件的方法后,我会结合我所写的三篇文章的方法来做一个爬取求职网的实例跟大家分享,有兴趣的可以看下,谢谢大家!
希望大家以后多多支持我们!
相关推荐
-

python爬虫beautifulsoup库使用操作教程全解(python爬虫基础入门)
[python爬虫基础入门]系列是对python爬虫的一个入门练习实践,旨在用最浅显易懂的语言,总结最明了,最适合自己的方法,本人一直坚信,总结才会使人提高 1. BeautifulSoup库简介 BeautifulSoup库在python中被美其名为"靓汤",它和和 lxml 一样也是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据.BeautifulSoup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,若在没用安装此库的情况下
-
Python进阶篇之多线程爬取网页
目录 一.前情提要 二.并发的概念 三.并发与多线程 四.线程池 一.前情提要 相信来看这篇深造爬虫文章的同学,大部分已经对爬虫有不错的了解了,也在之前已经写过不少爬虫了,但我猜爬取的数据量都较小,因此没有过多的关注爬虫的爬取效率.这里我想问问当我们要爬取的数据量为几十万甚至上百万时,我们会不会需要要等几天才能将数据全都爬取完毕呢? 唯一的办法就是让爬虫可以 7×24 小时不间断工作.因此我们能做的就是多叫几个爬虫一起来爬数据,这样便可大大提升爬虫的效率. 但在介绍Python 如何让多个爬虫一
-
python爬虫利器之requests库的用法(超全面的爬取网页案例)
requests库 利用pip安装: pip install requests 基本请求 req = requests.get("https://www.baidu.com/") req = requests.post("https://www.baidu.com/") req = requests.put("https://www.baidu.com/") req = requests.delete("https://www.baid
-
Python基于BeautifulSoup和requests实现的爬虫功能示例
本文实例讲述了Python基于BeautifulSoup和requests实现的爬虫功能.分享给大家供大家参考,具体如下: 爬取的目标网页:http://www.qianlima.com/zb/area_305/ 这是一个招投标网站,我们使用python脚本爬取红框中的信息,包括链接网址.链接名称.时间等三项内容. 使用到的Python库:BeautifulSoup.requests 代码如下: # -*- coding:utf-8 -*- import requests from bs4 im
-
Python进阶多线程爬取网页项目实战
目录 一.网页分析 二.代码实现 一.网页分析 这次我们选择爬取的网站是水木社区的Python页面 网页:https://www.mysmth.net/nForum/#!board/Python?p=1 根据惯例,我们第一步还是分析一下页面结构和翻页时的请求. 通过前三页的链接分析后得知,每一页链接中最后的参数是页数,我们修改它即可得到其他页面的数据. 再来分析一下,我们需要获取帖子的链接就在id 为 body 的 section下,然后一层一层找到里面的 table,我们就能遍历这些链接的标题
-
Python3实现爬虫爬取赶集网列表功能【基于request和BeautifulSoup模块】
本文实例讲述了Python3实现爬虫爬取赶集网列表功能.分享给大家供大家参考,具体如下: python3爬虫之爬取赶集网列表.这几天一直在学习使用python3爬取数据,今天记录一下,代码很简单很容易上手. 首先需要安装python3.如果还没有安装,可参考本站前面关于python3安装与配置相关文章. 首先需要安装request和BeautifulSoup两个模块 request是Python的HTTP网络请求模块,使用Requests可以轻而易举的完成浏览器可有的任何操作 pip insta
-
Python爬取求职网requests库和BeautifulSoup库使用详解
目录 一.requests库 1.requests简介 2.安装requests库 3.使用requests获取网页数据 我们先导入模块 4.总结requests的一些方法 二.BeautifulSoup库 1.BeautifulSoup简介 2.安装BeautifulSoup库 3.使用BeautifulSoup解析并提取获取的数据 4.BeautifulSoup提取数据的方法 一.requests库 1.requests简介 requests库就是一个发起请求的第三方库,requests允许
-
Python爬取网页中的图片(搜狗图片)详解
前言 最近几天,研究了一下一直很好奇的爬虫算法.这里写一下最近几天的点点心得.下面进入正文: 你可能需要的工作环境: Python 3.6官网下载 本地下载 我们这里以sogou作为爬取的对象. 首先我们进入搜狗图片http://pic.sogou.com/,进入壁纸分类(当然只是个例子Q_Q),因为如果需要爬取某网站资料,那么就要初步的了解它- 进去后就是这个啦,然后F12进入开发人员选项,笔者用的是Chrome. 右键图片>>检查 发现我们需要的图片src是在img标签下的,于是先试着用
-
利用python爬取散文网的文章实例教程
本文主要给大家介绍的是关于python爬取散文网文章的相关内容,分享出来供大家参考学习,下面一起来看看详细的介绍: 效果图如下: 配置python 2.7 bs4 requests 安装 用pip进行安装 sudo pip install bs4 sudo pip install requests 简要说明一下bs4的使用因为是爬取网页 所以就介绍find 跟find_all find跟find_all的不同在于返回的东西不同 find返回的是匹配到的第一个标签及标签里的内容 find_all返
-
python 爬取天气网卫星图片
项目地址: https://github.com/MrWayneLee/weather-demo 代码部分 下载生成文件功能 # 下载并生成文件 def downloadImg(imgDate, imgURLs, pathName): a,s,f = 0,0,0 timeStart = time.time() while a < len(imgURLs): req = requests.get(imgURLs[a]) imgName = str(imgURLs[a])[-13:-9] print
-
Python爬取当网书籍数据并数据可视化展示
目录 一.开发环境 二.模块使用 三.爬虫代码实现步骤 1. 导入所需模块 2. 发送请求, 用python代码模拟浏览器发送请求 3. 解析数据, 提取我们想要数据内容 4. 多页爬取 5. 保存数据, 保存csv表格里面 四.数据可视化 1.导入所需模块 2.导入数据 3.可视化 一.开发环境 Python 3.8 Pycharm 2021.2 专业版 二.模块使用 csv 模块 把爬取下来的数据保存表格里面的 内置模块requests >>> pip install request
-
python爬取之json、pickle与shelve库的深入讲解
前言 在使用Python进行网络编程或者爬取一些自己感兴趣的东西时,总避免不了进行一些数据传输.存取等问题,Python的文件对象以及其他扩展库,已经解决了很多关于文本和二进制数据存取的问题,比如网页内容.图片&音视频等多媒体内容,但这些数据基本是最终的数据形态存储,有没有办法可以存储Python本身的一些对象数据,后续在使用的时候,再直接加载为Python对象即可,本文便讲解下常用的Python对象数据存取.传输解决方案,即pickle.shelve.json. 内容比较基础,也比较简单,但也
-
python爬虫 爬取58同城上所有城市的租房信息详解
代码如下 from fake_useragent import UserAgent from lxml import etree import requests, os import time, re, datetime import base64, json, pymysql from fontTools.ttLib import TTFont ua = UserAgent() class CustomException(Exception): def __init__(self, statu
-
简单实现Python爬取网络图片
本文实例为大家分享了Python爬取网络图片的具体代码,供大家参考,具体内容如下 代码: import urllib import urllib.request import re #打开网页,下载器 def open_html ( url): require=urllib.request.Request(url) reponse=urllib.request.urlopen(require) html=reponse.read() return html #下载图片 def load_imag
-
实操Python爬取觅知网素材图片示例
目录 [一.项目背景] [二.项目目标] [三.涉及的库和网站] [四.项目分析] [五.项目实施] [六.效果展示] [七.总结] [一.项目背景] 在素材网想找到合适图片需要一页一页往下翻,现在学会python就可以用程序把所有图片保存下来,慢慢挑选合适的图片. [二.项目目标] 1.根据给定的网址获取网页源代码. 2.利用正则表达式把源代码中的图片地址过滤出来. 3.过滤出来的图片地址下载素材图片. [三.涉及的库和网站] 1.网址如下: https://www.51miz.com/
-
python利用多线程+队列技术爬取中介网互联网网站排行榜
目录 目标站点分析 编码时间 目标站点分析 本次要抓取的目标站点为:中介网,这个网站提供了网站排行榜.互联网网站排行榜.中文网站排行榜等数据. 网站展示的样本数据量是 :58341. 采集页面地址为 https://www.zhongjie.com/top/rank_all_1.html, UI如下所示: 由于页面存在一个[尾页]超链接,所以直接通过该超链接获取累计页面即可. 其余页面遵循简单分页规则: https://www.zhongjie.com/top/rank_all_1.html