对pandas的行列名更改与数据选择详解
记录一些pandas选择数据的内容,此前首先说行列名的获取和更改,以方便获取数据。此文作为学习巩固。
这篇博的内容顺序大概就是: 行列名的获取 —> 行列名的更改 —> 数据选择
一、pandas的行列名获取和更改
1. 获取: df.index() df.columns()
首先,举个例子,做一个DataFrame如下:
>>>import pandas as pd
>>>import numpy as np
>>>data = pd.DataFrame({'a':[1,2,3],'b':[4,5,6],'c':[7,8,9]})
>>>data
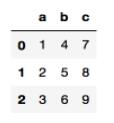
设置了列索引为 abc,行索引是自动生成的,也可以设置
>>>data.index = ['A','B','C'] >>>data
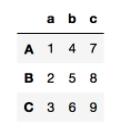
以下的做法都以这个 data 作为数据举例
接下来就可以获取索引了,index-行索引,columns-列索引
>>>data.index
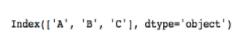
>>>data.columns
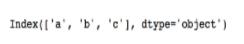
2. 修改,看到有很多方法,这里推荐一种比较灵活好用的方法
df.rename(index={ }, columns={ }, inplace=True)
>>>data.rename(index={'A':'D', 'B':'E', 'C':'F'}, columns={'a':'d', 'b':'e', 'c':'f'}, inplace = True)
>>>data

说明3点:
1. index和columns无关,可以分别指定,也就是说,可以只修改行索引,那么rename()中只写index
2. 索引可以任意挑选,如此处,index={'A':'D', 'C':'F'} 则只改A和C,columns同样
3. inplace=True, 在原dataframe上改动
二、pandas的数据选择
1. 直接用索引选(不灵活、不推荐) df[ ]
1) 选择‘a'列
>>>data['a']

注意:
1. 这样取出的数据类型为 Series
2. 这种方法只能取出一列,不能用数字下标,不能多选或片选, data['a','b'] , data['a':'c'] , data[0]
2)选择'A','B'行
>>>data['A':'B'] >>>data[0:2] # 两种方法同一结果
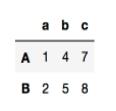
注意:
1. 这样取出的数据类型为 DateFrame
2. 这种方法只能用于片选行,可以用数字下标,不能单独取,即 data['A'] , data['A','B'] , data[1]
2.使用 .loc(推荐) df.loc(),()内参数先行后列,区别行列的取法
1) 取列:
>>>data.loc[:,['a','c']] #图1 需要行全取,再对应指定列
2)取行:
>>>data.loc[['A','B']] #图2 直接指定行
3)取行列交叉值:
>>>data.loc[['A'],['b','c']] #图3
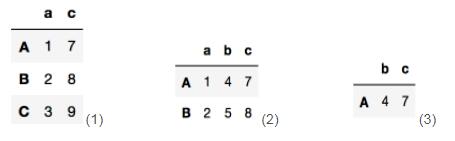
注意:
1. 区别 df.iloc()
.loc() —— 使用标签 label 作为索引取值
.iloc() —— 使用整数下标 index 作为索引取值,如上面三句可以换成以下三句,输出数据类型有不同
>>>data.iloc[:,[0,2]] # DataFrame >>>data.iloc[[0,1]] # DataFrame >>>data.iloc[0,[1,2]] # Series
2. 对于 数字类型的变量,可以使用bool 选取行,列不能用bool,如
>>>data.loc[data.b>5] # DataFrame
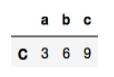
>>>data.loc[data.b>5,['c']] #DataFrame 输出为9位置的frame >>>data.iloc[data.b.values>5,[2]] #DataFrame 输出同上,需要有 .values取值
3. .ix[ ] 可以混用label和index,位置使用同 .loc[ ] .iloc[ ]
以上这篇对pandas的行列名更改与数据选择详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
python获取Pandas列名的几种方法
获取DataFrame虽然是一个比较简单的操作,但是有时候到手边就是写不出来,所以在这里总结记录一下: 1.链表推倒式 data = pd.read_csv('data/Receipt code January minute trading volume.csv') print([column for column in data]) #打印结果 ['COUNT', 'SUCC', 'FAIL', 'WAIT PAY', 'SUCCRatio', 'time'] 2.通过columns字段获取,
-
pandas修改DataFrame列名的方法
在做数据挖掘的时候,想改一个DataFrame的column名称,所以就查了一下,总结如下: 数据如下: >>>import pandas as pd >>>a = pd.DataFrame({'A':[1,2,3], 'B':[4,5,6], 'C':[7,8,9]}) >>> a A B C 0 1 4 7 1 2 5 8 2 3 6 9 方法一:暴力方法 >>>a.columns = ['a','b','c'] >>
-
解决pandas展示数据输出时列名不能对齐的问题
列名用了中文的缘故,设置pandas的参数即可, 代码如下: import pandas as pd #这两个参数的默认设置都是False pd.set_option('display.unicode.ambiguous_as_wide', True) pd.set_option('display.unicode.east_asian_width', True) 以上这篇解决pandas展示数据输出时列名不能对齐的问题就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
对pandas的行列名更改与数据选择详解
记录一些pandas选择数据的内容,此前首先说行列名的获取和更改,以方便获取数据.此文作为学习巩固. 这篇博的内容顺序大概就是: 行列名的获取 -> 行列名的更改 -> 数据选择 一.pandas的行列名获取和更改 1. 获取: df.index() df.columns() 首先,举个例子,做一个DataFrame如下: >>>import pandas as pd >>>import numpy as np >>>data = pd.D
-
Pandas实现在线文件和剪贴板数据读取详解
目录 前言 read_html 在线文件1 在线文件2 读取在线CSV文件 Pandas读取剪贴板 前言 大家好,我是Peter~ 本文记录的是Pandas两种少用的读取文件方式: 读取在线文件的数据 读取剪贴板的数据 声明:本文案例和在线数据仅用于学术分享 read_html 该函数表示的是直接读取在线的html文件,一般是表格的形式:将HTML的表格转换为DataFrame的一种快速方便的方法. 这个方法对于快速合并来自不同网页上的表格非常有用,就省去了爬取数据再来读取的时间. 具体函数的参
-

Pandas处理时间序列数据操作详解
目录 前言 一.获取时间 二.时间索引 三.时间推移 前言 一般从数据库或者是从日志文件读出的数据均带有时间序列,做时序数据处理或者实时分析都需要对其时间序列进行归类归档.而Pandas是处理这些数据很好用的工具包.此篇博客基于Jupyter之上进行演示,本篇博客的愿景是希望我或者读者通过阅读这篇博客能够学会方法并能实际运用.希望读者看完能够提出问题或者看法,博主会长期维护博客做及时更新.纯分享,希望大家喜欢. 一.获取时间 python自带datetime库,通过调用此库可以获取本地时间 fr
-
Python数据可视化详解
目录 一.Matplotlib模块 1.绘制基本图表 1. 绘制柱形图 2. 绘制条形图 3. 绘制折线图 4. 绘制面积图 5. 绘制散点图 6. 绘制饼图和圆环图 2.图表的绘制和美化技巧 1. 在一张画布中绘制多个图表 2. 添加图表元素 3. 添加并设置网格线 4. 调整坐标轴的刻度范围 3.绘制高级图表 1. 绘制气泡图 2. 绘制组合图 3. 绘制直方图 4. 绘制雷达图 5. 绘制树状图 6. 绘制箱形图 7. 绘制玫瑰图 二.pyecharts模块 1.图表配置项 2.绘制漏斗图
-
vue.js前后端数据交互之提交数据操作详解
本文实例讲述了vue.js前后端数据交互之提交数据操作.分享给大家供大家参考,具体如下: 前端小白刚开始做页面的时候,我们的前端页面中经常会用到表单,所以学会提交表单也是一个基本技能,其实用ajax就能实现,但他的原始语法有点...额 ...复杂,所以这里给大家提供一种用vue-resource向后端提交数据. (1)第一步,先在template中写一个表单: <el-form :model="ruleForm" :rules="rules" ref=&quo
-
MySQL中查询某一天, 某一月, 某一年的数据代码详解
今天 select * from 表名 where to_days(时间字段名) = to_days(now()); 昨天(包括昨天和今天的数据) SELECT * FROM 表名 WHERE TO_DAYS( NOW( ) ) - TO_DAYS( 时间字段名) <= 1 昨天(只包括昨天) SELECT * FROM 表名 WHERE DATEDIFF(字段,NOW())=-1; -- 同理,查询前天的就是-2 近7天 SELECT * FROM 表名 where DATE_SUB(CURD
-
对pandas通过索引提取dataframe的行方法详解
一.假设有这样一个原始dataframe 二.提取索引 (已经做了一些操作将Age为NaN的行提取出来并合并为一个dataframe,这里提取的是该dataframe的索引,道理和操作是相似的,提取的代码没有贴上去是为了不显得太繁杂让读者看着繁琐) >>> index = unknown_age_Mr.index.tolist() #记得转换为list格式 三.提取索引对应的原始dataframe的行 使用iloc函数将数据块提取出 >>> age_df.iloc[in
-
对python读取zip压缩文件里面的csv数据实例详解
利用zipfile模块和pandas获取数据,代码比较简单,做个记录吧: # -*- coding: utf-8 -*- """ Created on Tue Aug 21 22:35:59 2018 @author: FanXiaoLei """ from zipfile import ZipFile import pandas as pd myzip=ZipFile('2.zip') f=myzip.open('2.csv') df=pd.r
-
layui表格设计以及数据初始化详解
开发工具与关键技术: VisualStudio 2015 mvc 数据表格,在mvc项目中很多地方都会见到,一般做mvc项目我们所写的数据表格都不用自己纯敲的,因为纯敲代码量比较大且麻烦,所以我们都是用插件,以下面的为例,这是我写的layui表格设计以及数据初始化. 我们写数据表格之前,需要引用这个layui的插件,引用完后接下来就是,我们需要一个table来装数据,table里面有一些layui插件定义的元素. 如下图所示: 这个插件我们可以模块化使用,我们只用到table这一块,所以我们先需
-
pandas中read_csv、rolling、expanding用法详解
如下所示: import pandas as pd from pandas import DataFrame series = pd.read_csv('daily-min-temperatures.csv',header=0, index_col=0, parse_dates=True,squeeze=True) temps = DataFrame(series.values) width = 3 shifted = temps.shift(width-1) print(shifted) wi