python实现梯度下降算法
梯度下降(Gradient Descent)算法是机器学习中使用非常广泛的优化算法。当前流行的机器学习库或者深度学习库都会包括梯度下降算法的不同变种实现。
本文主要以线性回归算法损失函数求极小值来说明如何使用梯度下降算法并给出python实现。若有不正确的地方,希望读者能指出。
梯度下降
梯度下降原理:将函数比作一座山,我们站在某个山坡上,往四周看,从哪个方向向下走一小步,能够下降的最快。
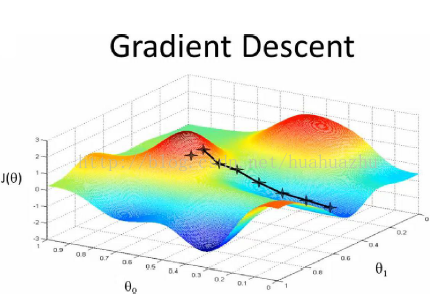
在线性回归算法中,损失函数为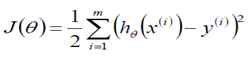
在求极小值时,在数据量很小的时候,可以使用矩阵求逆的方式求最优的θ值。但当数据量和特征值非常大,例如几万甚至上亿时,使用矩阵求逆根本就不现实。而梯度下降法就是很好的一个选择了。
使用梯度下降算法的步骤:
1)对θ赋初始值,这个值可以是随机的,也可以让θ是一个全零的向量。
2)改变θ的值,使得目标损失函数J(θ)按梯度下降的方向进行减少。
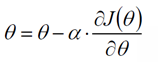
其中为学习率或步长,需要人为指定,若过大会导致震荡即不收敛,若过小收敛速度会很慢。
3)当下降的高度小于某个定义的值,则停止下降。
另外,对上面线性回归算法损失函数求梯度,结果如下:
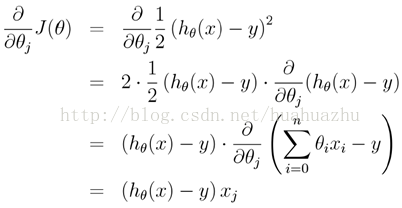
在实际应用的过程中,梯度下降算法有三类,它们不同之处在于每次学习(更新模型参数)使用的样本个数,每次更新使用不同的样本会导致每次学习的准确性和学习时间不同。下面将分别介绍原理及python实现。
批量梯度下降(Batch gradient descent)
每次使用全量的训练集样本来更新模型参数,即给定一个步长,然后对所有的样本的梯度的和进行迭代:
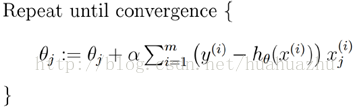
梯度下降算法最终得到的是局部极小值。而线性回归的损失函数为凸函数,有且只有一个局部最小,则这个局部最小一定是全局最小。所以线性回归中使用批量梯度下降算法,一定可以找到一个全局最优解。
优点:全局最优解;易于并行实现;总体迭代次数不多
缺点:当样本数目很多时,训练过程会很慢,每次迭代需要耗费大量的时间。
随机梯度下降(Stochastic gradient descent)
随机梯度下降算法每次从训练集中随机选择一个样本来进行迭代,即:
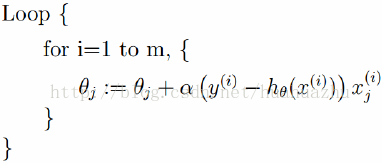
随机梯度下降算法每次只随机选择一个样本来更新模型参数,因此每次的学习是非常快速的,并且可以进行在线更新。
随机梯度下降最大的缺点在于每次更新可能并不会按照正确的方向进行,因此可以带来优化波动(扰动)。不过从另一个方面来看,随机梯度下降所带来的波动有个好处就是,对于类似盆地区域(即很多局部极小值点)那么这个波动的特点可能会使得优化的方向从当前的局部极小值点跳到另一个更好的局部极小值点,这样便可能对于非凸函数,最终收敛于一个较好的局部极值点,甚至全局极值点。
优点:训练速度快,每次迭代计算量不大
缺点:准确度下降,并不是全局最优;不易于并行实现;总体迭代次数比较多。
Mini-batch梯度下降算法
Mini-batch梯度下降综合了batch梯度下降与stochastic梯度下降,在每次更新速度与更新次数中间取得一个平衡,其每次更新从训练集中随机选择b,b<m个样本进行学习,即:

python代码实现
批量梯度下降算法
#!/usr/bin/python
#coding=utf-8
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
# 构造训练数据
x = np.arange(0., 10., 0.2)
m = len(x) # 训练数据点数目
print m
x0 = np.full(m, 1.0)
input_data = np.vstack([x0, x]).T # 将偏置b作为权向量的第一个分量
target_data = 2 * x + 5 + np.random.randn(m)
# 两种终止条件
loop_max = 10000 # 最大迭代次数(防止死循环)
epsilon = 1e-3
# 初始化权值
np.random.seed(0)
theta = np.random.randn(2)
alpha = 0.001 # 步长(注意取值过大会导致振荡即不收敛,过小收敛速度变慢)
diff = 0.
error = np.zeros(2)
count = 0 # 循环次数
finish = 0 # 终止标志
while count < loop_max:
count += 1
# 标准梯度下降是在权值更新前对所有样例汇总误差,而随机梯度下降的权值是通过考查某个训练样例来更新的
# 在标准梯度下降中,权值更新的每一步对多个样例求和,需要更多的计算
sum_m = np.zeros(2)
for i in range(m):
dif = (np.dot(theta, input_data[i]) - target_data[i]) * input_data[i]
sum_m = sum_m + dif # 当alpha取值过大时,sum_m会在迭代过程中会溢出
theta = theta - alpha * sum_m # 注意步长alpha的取值,过大会导致振荡
# theta = theta - 0.005 * sum_m # alpha取0.005时产生振荡,需要将alpha调小
# 判断是否已收敛
if np.linalg.norm(theta - error) < epsilon:
finish = 1
break
else:
error = theta
print 'loop count = %d' % count, '\tw:',theta
print 'loop count = %d' % count, '\tw:',theta
# check with scipy linear regression
slope, intercept, r_value, p_value, slope_std_error = stats.linregress(x, target_data)
print 'intercept = %s slope = %s' % (intercept, slope)
plt.plot(x, target_data, 'g*')
plt.plot(x, theta[1] * x + theta[0], 'r')
plt.show()
运行结果截图:

随机梯度下降算法
#!/usr/bin/python
#coding=utf-8
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
# 构造训练数据
x = np.arange(0., 10., 0.2)
m = len(x) # 训练数据点数目
x0 = np.full(m, 1.0)
input_data = np.vstack([x0, x]).T # 将偏置b作为权向量的第一个分量
target_data = 2 * x + 5 + np.random.randn(m)
# 两种终止条件
loop_max = 10000 # 最大迭代次数(防止死循环)
epsilon = 1e-3
# 初始化权值
np.random.seed(0)
theta = np.random.randn(2)
# w = np.zeros(2)
alpha = 0.001 # 步长(注意取值过大会导致振荡,过小收敛速度变慢)
diff = 0.
error = np.zeros(2)
count = 0 # 循环次数
finish = 0 # 终止标志
######-随机梯度下降算法
while count < loop_max:
count += 1
# 遍历训练数据集,不断更新权值
for i in range(m):
diff = np.dot(theta, input_data[i]) - target_data[i] # 训练集代入,计算误差值
# 采用随机梯度下降算法,更新一次权值只使用一组训练数据
theta = theta - alpha * diff * input_data[i]
# ------------------------------终止条件判断-----------------------------------------
# 若没终止,则继续读取样本进行处理,如果所有样本都读取完毕了,则循环重新从头开始读取样本进行处理。
# ----------------------------------终止条件判断-----------------------------------------
# 注意:有多种迭代终止条件,和判断语句的位置。终止判断可以放在权值向量更新一次后,也可以放在更新m次后。
if np.linalg.norm(theta - error) < epsilon: # 终止条件:前后两次计算出的权向量的绝对误差充分小
finish = 1
break
else:
error = theta
print 'loop count = %d' % count, '\tw:',theta
# check with scipy linear regression
slope, intercept, r_value, p_value, slope_std_error = stats.linregress(x, target_data)
print 'intercept = %s slope = %s' % (intercept, slope)
plt.plot(x, target_data, 'g*')
plt.plot(x, theta[1] * x + theta[0], 'r')
plt.show()
运行结果截图:

Mini-batch梯度下降
#!/usr/bin/python
#coding=utf-8
import numpy as np
from scipy importstats
import matplotlib.pyplot as plt
# 构造训练数据
x = np.arange(0.,10.,0.2)
m = len(x) # 训练数据点数目
print m
x0 = np.full(m, 1.0)
input_data = np.vstack([x0, x]).T # 将偏置b作为权向量的第一个分量
target_data = 2 *x + 5 +np.random.randn(m)
# 两种终止条件
loop_max = 10000 #最大迭代次数(防止死循环)
epsilon = 1e-3
# 初始化权值
np.random.seed(0)
theta = np.random.randn(2)
alpha = 0.001 #步长(注意取值过大会导致振荡即不收敛,过小收敛速度变慢)
diff = 0.
error = np.zeros(2)
count = 0 #循环次数
finish = 0 #终止标志
minibatch_size = 5 #每次更新的样本数
while count < loop_max:
count += 1
# minibatch梯度下降是在权值更新前对所有样例汇总误差,而随机梯度下降的权值是通过考查某个训练样例来更新的
# 在minibatch梯度下降中,权值更新的每一步对多个样例求和,需要更多的计算
for i inrange(1,m,minibatch_size):
sum_m = np.zeros(2)
for k inrange(i-1,i+minibatch_size-1,1):
dif = (np.dot(theta, input_data[k]) - target_data[k]) *input_data[k]
sum_m = sum_m + dif #当alpha取值过大时,sum_m会在迭代过程中会溢出
theta = theta- alpha * (1.0/minibatch_size) * sum_m #注意步长alpha的取值,过大会导致振荡
# 判断是否已收敛
if np.linalg.norm(theta- error) < epsilon:
finish = 1
break
else:
error = theta
print 'loopcount = %d'% count, '\tw:',theta
print 'loop count = %d'% count, '\tw:',theta
# check with scipy linear regression
slope, intercept, r_value, p_value,slope_std_error = stats.linregress(x, target_data)
print 'intercept = %s slope = %s'% (intercept, slope)
plt.plot(x, target_data, 'g*')
plt.plot(x, theta[1]* x +theta[0],'r')
plt.show()
运行结果:

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
python实现随机漫步算法
本文实例为大家分享了python实现随机漫步的具体代码,供大家参考,具体内容如下 编写randomwalk类 from random import choice class randomwalk(): def __init__(self,num_points=5000): self.num_points=num_points self.x_values=[0] self.y_values=[0] def fill_walk(self): while len(self.x_values)<self
-
解读python如何实现决策树算法
数据描述 每条数据项储存在列表中,最后一列储存结果 多条数据项形成数据集 data=[[d1,d2,d3...dn,result], [d1,d2,d3...dn,result], . . [d1,d2,d3...dn,result]] 决策树数据结构 class DecisionNode: '''决策树节点 ''' def __init__(self,col=-1,value=None,results=None,tb=None,fb=None): '''初始化决策树节点 args: col -
-
Python数据结构与算法之图的最短路径(Dijkstra算法)完整实例
本文实例讲述了Python数据结构与算法之图的最短路径(Dijkstra算法).分享给大家供大家参考,具体如下: # coding:utf-8 # Dijkstra算法--通过边实现松弛 # 指定一个点到其他各顶点的路径--单源最短路径 # 初始化图参数 G = {1:{1:0, 2:1, 3:12}, 2:{2:0, 3:9, 4:3}, 3:{3:0, 5:5}, 4:{3:4, 4:0, 5:13, 6:15}, 5:{5:0, 6:4}, 6:{6:0}} # 每次找到离源点最近的一个顶
-
用python实现k近邻算法的示例代码
K近邻算法(或简称kNN)是易于理解和实现的算法,而且是你解决问题的强大工具. 什么是kNN kNN算法的模型就是整个训练数据集.当需要对一个未知数据实例进行预测时,kNN算法会在训练数据集中搜寻k个最相似实例.对k个最相似实例的属性进行归纳,将其作为对未知实例的预测. 相似性度量依赖于数据类型.对于实数,可以使用欧式距离来计算.其他类型的数据,如分类数据或二进制数据,可以用汉明距离. 对于回归问题,会返回k个最相似实例属性的平均值.对于分类问题,会返回k个最相似实例属性出现最多的属性. kNN
-

基于随机梯度下降的矩阵分解推荐算法(python)
SVD是矩阵分解常用的方法,其原理为:矩阵M可以写成矩阵A.B与C相乘得到,而B可以与A或者C合并,就变成了两个元素M1与M2的矩阵相乘可以得到M. 矩阵分解推荐的思想就是基于此,将每个user和item的内在feature构成的矩阵分别表示为M1与M2,则内在feature的乘积得到M:因此我们可以利用已有数据(user对item的打分)通过随机梯度下降的方法计算出现有user和item最可能的feature对应到的M1与M2(相当于得到每个user和每个item的内在属性),这样就可以得到通
-
Python使用Dijkstra算法实现求解图中最短路径距离问题详解
本文实例讲述了Python使用Dijkstra算法实现求解图中最短路径距离问题.分享给大家供大家参考,具体如下: 这里继续前面一篇<Python基于Floyd算法求解最短路径距离问题>的内容,这里要做的是Dijkstra算法,与Floyd算法类似,二者的用途均为求解最短路径距离,在图中有着广泛的应用,二者的原理都是老生常谈了,毕竟本科学习数据结构的同学是不可能不学习这两个算法的,所以在这里我也不再累赘,只简单概述一下这个算法的核心思想: Dijkstra算法的输入有两个参数,一个是原始的数据矩
-
python实现汉诺塔算法
题目: 汉诺塔给出最优解,如果对汉诺塔的定义有不了解,请翻看数据结构教材. 除了最基本的之外,还有一题,给定一个数组,arr=[2,3,1,2,3],其含义是这是一个有5个圆盘的汉诺塔,每一个数字代表这个圆盘所在的位置,1代表左边的柱子,2代表中间,3代表右边.给出这个序列代表了汉诺塔移动的第几步,如果该步骤是错误的,则返回-1,所谓错误,是指该步骤不是最简便的得到汉诺塔序列的操作步骤. 分析: 1. 算法当然还是递归解了,即把n个汉诺塔盘子分解成 n - 1 个盘子的移动和一个底层盘子的移动,
-
Python实现Dijkstra算法
Dijkstra算法 迪杰斯特拉算法是由荷兰计算机科学家狄克斯特拉于1959 年提出的,因此又叫狄克斯特拉算法.是从一个顶点到其余各顶点的最短路径算法,解决的是有向图中最短路径问题.迪杰斯特拉算法主要特点是以起始点为中心向外层层扩展,直到扩展到终点为止. 迪杰斯特拉算法是求从某一个起点到其余所有结点的最短路径,是一对多的映射关系,是一种贪婪算法 示例: 算法 算法实现流程思路: 迪杰斯特拉算法每次只找离起点最近的一个结点,并将之并入已经访问过结点的集合(以防重复访问,陷入死循环),然后将刚找到的
-
python实现排序算法解析
本文实例为大家分享了python实现排序算法的具体代码,供大家参考,具体内容如下 一.冒泡排序 def bububle_sort(alist): """冒泡排序(稳定|n^2m)""" n = len(alist) for j in range(n-1): count = 0 for i in range(0,n-1-j): if alist[i]>alist[i+1]: count +=1 alist[i], alist[i+1] = a
-
Python实现的多叉树寻找最短路径算法示例
本文实例讲述了Python实现的多叉树寻找最短路径算法.分享给大家供大家参考,具体如下: 多叉树的最短路径: 思想: 传入start 和 end 两个 目标值 1 找到从根节点到目标节点的路径 2 从所在路径,寻找最近的公共祖先节点, 3 对最近公共祖先根节点 拼接路径 Python代码: # -*- coding:utf-8 -*- import copy #节点数据结构 class Node(object): # 初始化一个节点 def __init__(self,v
-
python实现换位加密算法的示例
如下所示: def translationCipher(msg,key): result = [""]*key for i in range(key):#把每一列元素按照顺序相加组成新的字符序列 pointer = i while i<len(msg): result[pointer]+=msg[i] i+=key return ''.join(result) def main(): print translationCipher("hello,world",
-
python 实现A*算法的示例代码
A*作为最常用的路径搜索算法,值得我们去深刻的研究.路径规划项目.先看一下维基百科给的算法解释:https://en.wikipedia.org/wiki/A*_search_algorithm A *是最佳优先搜索它通过在解决方案的所有可能路径(目标)中搜索导致成本最小(行进距离最短,时间最短等)的问题来解决问题. ),并且在这些路径中,它首先考虑那些似乎最快速地引导到解决方案的路径.它是根据加权图制定的:从图的特定节点开始,它构造从该节点开始的路径树,一次一步地扩展路径,直到其一个路径在预定