Python内置数据类型中的集合详解
目录
- 1. 集合 set 简介
- 1.1 使用 { } 直接创建集合
- 1.2 使用 set() 函数创建集合
- 2. 集合没有切片功能!
- 3. 处理集合的常见内置函数
- 3.1 len 函数
- 3.2 map 函数
- 3.3 filter 函数
- 3.4 reduce 函数
- 3.5 sum 函数
- 3.6 max 函数
- 3.7 min 函数
- 3.8 sorted 函数
- 3.9 enumerate 函数
- 3.10 any 函数
- 3.11 all 函数
- 4. 集合的内置方法
- 4.1 .add(val)
- 4.2 .clear()
- 4.3 .copy()
- 4.4 .difference(set1,set2,...)
- 4.5 .difference_update(set1,set2,...)
- 4.6 .discard(val)
- 4.7 .intersection(set1,set2,...)
- 4.8 .intersection_update()
- 4.9 .isdisjoint()
- 4.10 .issubset(other_set)
- 4.11 .issuperset(other_set)
- 4.12 .pop()
- 4.13 .remove()
- 4.14 .symmetric_difference()
- 4.15 .symmetric_difference_update()
- 4.16 .union(other_set)
- 4.17 .update(other_set)
- 5. 集合和运算符
- 5.1 - 运算符
- 5.2 | 运算符
- 5.3 & 运算符
- 5.4 ^ 运算符
- 5.5 in 、not in 运算符
- 总结
1. 集合 set 简介
集合的最大特征是其每个元素都是唯一的,它可以删除、可以增加、也可以通过增删实现替换元素,但是它是没有下标的,你无法通过下标或者切片功能访问集合。因为集合就像一个袋子里面装着颜色不一样的玻璃球,你可以替换玻璃球,但是无法指定玻璃球存放的地点。
它最大的作用,就是它元素的唯一,它经常被用来清除多余的数据。
1.1 使用 { } 直接创建集合
可以使用 {} 直接创建集合,但是不能使用 {} 创建空集合,因为 {} 被用来创建空字典。你只能通过 set() 来创建空集合。
1.2 使用 set() 函数创建集合
使用内置函数 set,可以快速的将其他类型的可迭代对象转换成 集合 对象。这些可迭代对象,可以是字符串、列表、元组等等。
print("创建一个空集合")
print(set())
str1 = 'ABCDEF!'
s=set(str1)
print("*"*40)
print("一个由字符串转换的集合,每个元素即唯一的单独字符")
print(s)
list1 = [0,1,2,3,4,3,2,1]
s=set(list1)
print("*"*40)
print("一个由列表转换的集合,但是在列表中重复的元素只会出现一次")
print(s)
2. 集合没有切片功能!
请仔细理解,集合没有切片功能,这意味着什么,这意味着无法对它排序(当然可以转换成列表再排序),意味着无法用 while 循环配合下标依次获得元素,你可以用 for 循环获取。
3. 处理集合的常见内置函数
3.1 len 函数
len 函数返回集合的长度,即元素的个数。
3.2 map 函数
map 函数对集合中的每个元素进行相同的操作,然后返回一个 map 对象,再使用 set 函数可以得到集合。
>>> a
{'sdf', 'er'}
>>> set(map(lambda x:x+"-",a))
{'er-', 'sdf-'}
3.3 filter 函数
filter 函数对集合中的每个元素进行相同的操作,符合条件的元素才留下来,返回一个 filter 类型的对象。
>>> a
{'sdf', 'er'}
>>> set(filter(lambda x:len(x)==2,a))
{'er'}
3.4 reduce 函数
filter 函数依次对集合中的元素进行相同的迭代操作最后得到一个对象。
>>> import functools
>>> a
{'sdf', 'er'}
>>> functools.reduce(lambda x,y:x+"~"+y,a)
'sdf~er'
3.5 sum 函数
sum 函数,只对元素是数值的集合有效,返回列表中的元素总和,如果元素类型不是数值,则返回 TypeError。
3.6 max 函数
max 函数,返回集合中的元素最大值。
3.7 min 函数
min 函数,返回集合中的元素最小值。
>>> a={1,2,3}
>>> sum(a)
6
>>> min(a)
1
>>> max(a)
3
>>>
3.8 sorted 函数
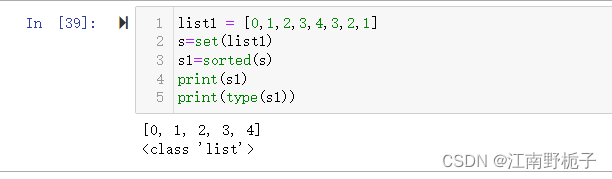
sorted 函数会对集合按照指定方式进行排序,请注意,使用 sorted 函数会得到一个排好序的列表,不是集合!!!原集合不会改变。
list1 = [0,1,2,3,4,3,2,1] s=set(list1) s1=sorted(s) print(s1) print(type(s1))
3.9 enumerate 函数
enumerate 函数可以将一个集合依次取出。
3.10 any 函数
any() 函数用于判断给定的集合的所有元素是否都为 False,则返回 False,如果有一个为 True,则返回 True。
3.11 all 函数
all() 函数用于判断给定的集合的所有元素是否都为 TRUE,如果是返回 True,否则返回 False。
4. 集合的内置方法
4.1 .add(val)
.add(val) 方法附加一个元素 val,如果 val 已经在集合中,那么原来的集合不变化。
4.2 .clear()
.clear() 方法将集合清空。
4.3 .copy()
.copy() 方法将返回集合的拷贝(而不是和原来的列表共用同一个地址)。
4.4 .difference(set1,set2,...)
difference() 方法用于返回集合的差集,即返回的集合元素包含在第一个集合中,但不包含在第二、三、N个集合(方法的参数)中。
4.5 .difference_update(set1,set2,...)
difference_update() 方法用于移除两个或者多个集合中都存在的元素。
difference_update() 方法与 difference() 方法的区别在于 difference() 方法返回一个移除相同元素的新集合,而 difference_update() 方法是直接在原来的集合中移除元素,没有返回值。
# 集合的使用
a={1,2,3,4,1}
b={4,5,6,7}
# 1.集合是不会有重复的元素的
print("1. ",a)
# 2.集合使用 add 方法加一个元素
a.add("6")
print("2. ",a)
# 3.集合使用 clear 方法清空
a.clear()
print("3. ",a)
a={1,2,3,4}
# 4.集合使用 copy 方法复制数据
c=a.copy()
print("4. ",c)
# 5.集合使用 difference 方法返回
# 和其他集合不一样的数据
print("5. ",a.difference(b))
# 6.集合使用 difference_update 方法删除
# 和其他集合一样的数据
# a={1,2,3,4}
# b={4,5,6,7}
a={1,2,3,4}
b={4,5,6,7}
print("6. ",a.difference_update(b))
print("6. ",a)
a={1,2,3,4}
c={1}
a.difference_update(b,c)
print("6. ",a)
# 7.集合使用 discard 方法删掉数据 val
a={1,2,3,4}
a.discard(2)
print("7. ",a)

4.6 .discard(val)
.discard 方法删除集合中指定的元素。
4.7 .intersection(set1,set2,...)
.intersection 方法返回集合的交集,自身不受影响。
4.8 .intersection_update()
.intersection 方法原地改变自身为两个或者多个集合的交集。
>>> a={1,2,3,4,5}
>>> b={2,3,4,5,6,7}
>>> a.intersection(b)
{2, 3, 4, 5}
>>> a
{1, 2, 3, 4, 5}
>>> b
{2, 3, 4, 5, 6, 7}
>>> a.intersection_update(b)
>>> a
{2, 3, 4, 5}
>>> b
{2, 3, 4, 5, 6, 7}
4.9 .isdisjoint()
.isdisjoint 方法判断两个集合是否包含相同的元素,如果没有返回 True,否则返回 False。
>>> a={1,2,3,4,5}
>>> b={2,3,4,5,6,7}
>>> c={"a","b"}
>>> a.isdisjoint(b)
False
>>> a.isdisjoint(c)
True
4.10 .issubset(other_set)
.issubset 方法判断自身集合是否为该方法参数集合 other_set 的子集。
>>> a={1,2,3,4,5}
>>> b={2,3,4,5,6,7}
>>> c={1}
>>> a.issubset(b)
False
>>> a.issubset(c)
False
>>> c.issubset(a)
True
4.11 .issuperset(other_set)
.issuperset 方法判断该方法参数集合 other_set 是否为自身集合的子集。
>>> a={1,2,3,4,5}
>>> b={2,3,4,5,6,7}
>>> c={1}
>>> a.issuperset(b)
False
>>> a.issuperset(c)
True
4.12 .pop()
.pop() 方法将返回集合中的一个元素,原集合将删除该元素。
请注意,集合中的 pop 方法是没有 index 参数!如果像使用列表中的 pop 方法输入 index 参数,则返回 TypeError: pop() takes no arguments (1 given) 错误。
4.13 .remove()
.remove(val) 方法将删除集合中的 val 元素,返回为空。如果 val 不在集合中,则返回 KeyError 错误。
4.14 .symmetric_difference()
返回两个集合中不重复的元素集合,而不改变自身集合。
4.15 .symmetric_difference_update()
移除当前集合中在另外一个指定集合相同的元素,并将另外一个指定集合中不同的元素插入到当前集合中。
# 10.集合使用 ^ 操作符返回
# 两个集合中不一样的数据
# 等同于 symmetric_difference方法
a={1,2,3,4}
b={4,5,6,7}
tmp=a^b
print("10. ",tmp)
print("a==>",a)
print("b==>",b)
print("使用 ^ 操作符 原来的集合不受影响")
print("*"*60)
print("a.symmetric_difference(b)==>",a.symmetric_difference(b))
print("a==>",a)
print("b==>",b)
print("使用 symmetric_difference方法 原来的集合不受影响")
print("*"*60)
print("a.symmetric_difference_update(b)==>",a.symmetric_difference_update(b))
print("使用 symmetric_difference_update 原来的集合会改变")
print("a==>",a)
print("b==>",b)
print("*"*60)

4.16 .union(other_set)
.union 方法返回两个集合的并集,而不改变自身集合。
4.17 .update(other_set)
.update 方法给自身集合集合添加元素。
>>> a={0,1}
>>> b={3,4}
>>> c={5,6}
>>> a.union(b)
{0, 1, 3, 4}
>>> a
{0, 1}
>>> b
{3, 4}
>>> a.update(b)
>>> a
{0, 1, 3, 4}
>>> b
{3, 4}
5. 集合和运算符
5.1 - 运算符
a 、b 是两个集合;a - b类似于 a.difference(b) 方法,即返回集合a中包含而集合b中不包含的元素,自身不受改变。
>>> a={0,1,2,3}
>>> b={2,3,4,5}
>>> a-b
{0, 1}
>>> a.difference(b)
{0, 1}
5.2 | 运算符
a 、b 是两个集合;a | b类似于 a.union(b) 方法,即返回集合a和b中所有的元素,自身不受改变。
>>> a={0,1,2,3}
>>> b={2,3,4,5}
>>> a|b
{0, 1, 2, 3, 4, 5}
>>> a.union(b)
{0, 1, 2, 3, 4, 5}
5.3 & 运算符
a 、b 是两个集合;a & b类似于 a.intersection(b) 方法,即返回集合a和b中都包含了的元素,自身不受改变。
# 9.集合使用 & 选出集合重叠的部分
# 等同于 insection 方法
a={1,2,3,4}
b={4,5,6,7}
print("********* 初始数据 ***********")
print("a==>",a)
print("b==>",b)
print("8. a & b==>",a & b)
print("执行 a & b 后")
print("a==>",a)
print("b==>",b)
print("使用 & 操作符 原来的集合不受影响")
print("*"*60)
print("8. a.intersection(b)==>",a.intersection(b))
print("使用 intersection 方法 原来的集合不受影响")
print("a==>",a)
print("b==>",b)
print("*"*60)
print("8. a.intersection_update(b)==>",a.intersection_update(b))
print("使用 intersection_update 方法 原来的集合会改变")
print("a==>",a)
print("b==>",b)
print("*"*60)

5.4 ^ 运算符
a 、b 是两个集合;a ^ b类似于 a.symmetric_difference(b) 方法,即返回不同时包含于a和b的元素,自身不受改变。
>>> a={0,1,2,3}
>>> b={2,3,4,5}
>>> a.symmetric_difference(b)
{0, 1, 4, 5}
>>> a^b
{0, 1, 4, 5}
5.5 in 、not in 运算符
in 运算符判断某个元素属于某个集合
not in 运算符判断某个元素不属于某个集合
>>> a={0,1,2,3}
>>> 0 in a
True
>>> "0" in a
False
总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注我们的更多内容!
相关推荐
-
Python 一篇文章看懂Python集合与字典数据类型
目录 前言 一.集合类型
-

Python 数据类型--集合set
目录 一.定义 二.操作 三.运算 一.定义 集合中的元素是无序的.唯一的.不可变的类型.集合是一个特殊的列表,可以对数据去重. lists = [1,3,5,7,3,4,6,2,7,9] print(set(lists)) 使用大括号{}或set()函数吧数据集合在一起. set()中的参数可以是元组.字符串.列表,还可以是一个集合.这个参数只要是一个序列即可. 创建一个空集合必须用set(),不能使用大括号.{}是用来定义空字典的. 二.操作 add(),把要传入的元素作为一个整体添加到集合
-
Python中基础数据类型 set集合知识点总结
集合的简介 集合是一个无序.不重复的序列 它的基本用法包括成员检测和消除重复元素 集合对象也支持像 联合,交集,差集,对称差分等数学运算 集合中所有的元素放在 {} 中间,并用逗号分开 集合的例子 这里会有个重点知识 # 声明 basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'} print(basket) set_ = {1, 1, 1, 1, 2} print(set_) # 输出结果 {'orange', 'pe
-
Python数据类型之Set集合实例详解
本文实例讲述了Python数据类型之Set集合.分享给大家供大家参考,具体如下: set集合 1.概述 set与dict类似,但set是一组key的集合,与dict的区别在于set不存储value. 本质:无序且无重复元素的集合(具有自动去重的功能). 2.set的创建 语法: set1 = set([1, 2, 3, 4, 5]) 注意:创建set需要一个list或者tuple或者dist作为输入集合,重复的元素在set中会被自动的过滤 s1 = set([1, 2, 3, 4, 5]) pr
-
Python内置数据类型中的集合详解
目录 1. 集合 set 简介 1.1 使用 { } 直接创建集合 1.2 使用 set() 函数创建集合 2. 集合没有切片功能! 3. 处理集合的常见内置函数 3.1 len 函数 3.2 map 函数 3.3 filter 函数 3.4 reduce 函数 3.5 sum 函数 3.6 max 函数 3.7 min 函数 3.8 sorted 函数 3.9 enumerate 函数 3.10 any 函数 3.11 all 函数 4. 集合的内置方法 4.1 .add(v
-
Python内置数据类型详解
通常来说Python在编程语言中的定位为脚本语言--scripting language 高阶动态编程语言. Python是以数据为主,变量的值改变是指变量去指到一个地址. 即:Id(变量)->展示变量的地址. 因此一个具体的值,会有不同的变量名. Python的数据类型: 数字.字符串.列表.元组.字典 数字和字符串其实是很基本的数据类型,在Python中和其他语言相差不是很大的,在这里就不细讲了. Dictionary介绍: Dictionary是Python的内置数据类型之一,它定义了键和
-
Python的内置数据类型中的数字
目录 Python的内置数据类型中的数字 1.变量 2.数据类型总览 3.Python是弱类型的语言 4.各数据类型的详细介绍 4.1 整数(int) 4.2 浮点数/小数(float) 5.复数(complex) 6.布尔类型(bool) Python的内置数据类型中的数字 1.变量 说数据类型之前,我们要先思考一下下面几个问题: 数据是怎么存的呢? 数据类型有啥作用呢? 各种数据类型有啥区别呢? 要想回答这些问题,首先还是要先了解一下变量的概念.那么何为变量呢? 变量(Variable)可以
-
python内置数据类型之列表操作
数据类型是一种值的集合以及定义在这种值上的一组操作.一切语言的基础都是数据结构,所以打好基础对于后面的学习会有百利而无一害的作用. python内置的常用数据类型有:数字.字符串.Bytes.列表.元组.字典.集合.布尔等 1.什么是列表 lst[#] 通过下标访问,从0开始. ps:如果#超过下标的范围时候会出现IndexError的错误. 如果#为负号,则索引从右边开始,#无论为正负均有范围,超过范围会报错. lst = list(range(0,9)) #生产列表 l1 = lst[3]
-
Python内置数据类型list各方法的性能测试过程解析
这篇文章主要介绍了Python内置数据类型list各方法的性能测试过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 测试环境 本文所涉及的代码均在MacOS系统与CentOS7下测试,使用的Python版本为3.6.8. 测试模块 测试用的模块是Python内置的timeit模块: timeit模块可以用来测试一小段Python代码的执行速度. Timer类 class timeit.Timer(stmt='pass', setup='p
-
python内置数据类型使用方法和继承关系
目录 1.python包含的内置序列 2.使用内置的数据类型 2.1创建 2.2索引 2.3使用for遍历 3.可变与不可变 4.小练习题 前言: python之父Guido van Rossum曾经参与过ABC语言的开发(不是参加了A语言.B语言和C语言的开发,ABC是一门单独的编程语言),后来他认为这门语言存在很多缺点,就创立了python语言.因此,python很多风格和ABC语言是有相似之处的. 今天笔记内容是流畅的python书籍的第二章,主要记录python内置序列类型的相关知识 本
-
基于python内置函数与匿名函数详解
内置函数 Built-in Functions abs() dict() help() min() setattr() all() dir() hex() next() slice() any() divmod() id() object() sorted() ascii() enumerate() input() oct() staticmethod() bin() eval() int() open() str() bool() exec() isinstance() pow() super
-
对Python 2.7 pandas 中的read_excel详解
导入pandas模块: import pandas as pd 使用import读入pandas模块,并且为了方便使用其缩写pd指代. 读入待处理的excel文件: df = pd.read_excel('log.xls') 通过使用read_excel函数读入excel文件,后面需要替换成excel文件所在的路径.读入之后变为pandas的DataFrame对象.DataFrame是一个面向列(column-oriented)的二维表结构,且含有列表和行标,对excel文件的操作就转换为对Da
-
python内置函数之slice案例详解
英文文档: class slice(stop) class slice(start, stop[, step]) Return a slice object representing the set of indices specified by range(start, stop, step). The start and step arguments default to None. Slice objects have read-only data attributes start, st
-
表格梳理python内置数学模块math分析详解
python内置数学模块math 提供了一些基础的计算功能,下列表达式默认 from math import * 默认输入输出均为一个数字.大部分函数都很直观,望文生义即可. 其他函数 isclose(a, b, *, rel_tol=1e-09, abs_tol=0.0) 若 a 和 b 的值比较接近则返回True,否则False. rel_tol 是相对容差,表示a, b之间允许的最大差值.例如,要设置5%的容差,rel_tol=0.05.rel_tol 必须大于0. abs_tol 是最小