Java源码解析重写锁的设计结构和细节
目录
- 引导语
- 1、需求
- 2、详细设计
- 2.1、定义锁
- 2.2、定义同步器Sync
- 2.3、通过能否获得锁来决定能否得到链接
- 3、测试
- 4、总结
引导语
有的面试官喜欢让同学在说完锁的原理之后,让你重写一个新的锁,要求现场在白板上写出大概的思路和代码逻辑,这种面试题目,蛮难的,我个人觉得其侧重点主要是两个部分:
考察一下你对锁原理的理解是如何来的,如果你对源码没有解读过的话,只是看看网上的文章,或者背面试题,也是能够说出大概的原理,但你很难现场写出一个锁的实现代码,除非你真的看过源码,或者有和锁相关的项目经验;
我们不需要创造,我们只需要模仿 Java 锁中现有的 API 进行重写即可。
如果你看过源码,这道题真的很简单,你可以挑选一个你熟悉的锁进行模仿。
在锁章节中我们之前说的都是排它锁,这小节我们以共享锁作为案列,自定义一个共享锁。
1、需求
一般自定义锁的时候,我们都是根据需求来进行定义的,不可能凭空定义出锁来,说到共享锁,大家可能会想到很多场景,比如说对于共享资源的读锁可以是共享的,比如对于数据库链接的共享访问,比如对于 Socket 服务端的链接数是可以共享的,场景有很多,我们选择共享访问数据库链接这个场景来定义一个锁。
2、详细设计
假定(以下设想都为假定)我们的数据库是单机 mysql,只能承受 10 个链接,创建数据库链接时,我们是通过最原始 JDBC 的方式,我们用一个接口把用 JDBC 创建链接的过程进行了封装,这个接口我们命名为:创建链接接口。
共享访问数据库链接的整体要求如下:所有请求加在一起的 mysql 链接数,最大不能超过 10(包含 10),一旦超过 10,直接报错。
在这个背景下,我们进行了下图的设计:
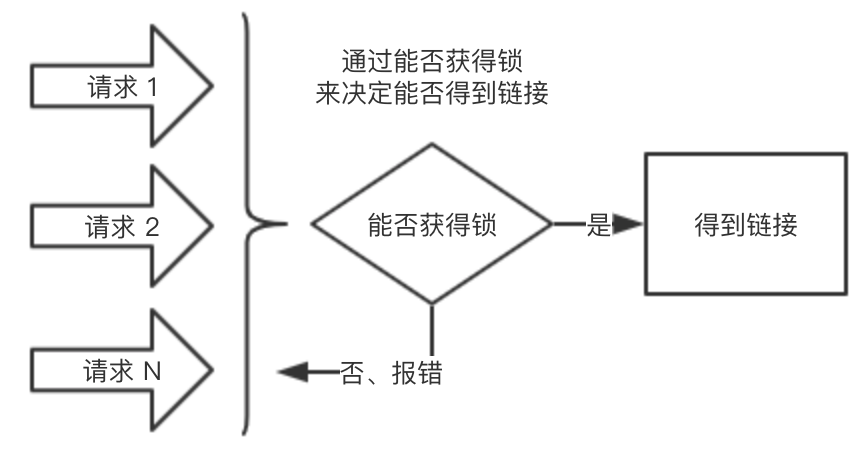
这个设计最最关键的地方,就是我们通过能否获得锁,来决定是否可以得到 mysql 链接,如果能获得锁,那么就能得到链接,否则直接报错。
接着我们一起来看下落地的代码:
2.1、定义锁
首先我们需要定义一个锁出来,定义时需要有两个元素:
锁的定义:同步器 Sync;锁对外提供的加锁和解锁的方法。
共享锁的代码实现如下:
// 共享不公平锁
public class ShareLock implements Serializable{
// 同步器
private final Sync sync;
// 用于确保不能超过最大值
private final int maxCount;
/**
* 初始化时给同步器 sync 赋值
* count 代表可以获得共享锁的最大值
*/
public ShareLock(int count) {
this.sync = new Sync(count);
maxCount = count;
}
/**
* 获得锁
* @return true 表示成功获得锁,false 表示失败
*/
public boolean lock(){
return sync.acquireByShared(1);
}
/**
* 释放锁
* @return true 表示成功释放锁,false 表示失败
*/
public boolean unLock(){
return sync.releaseShared(1);
}
}
从上述代码中可以看出,加锁和释放锁的实现,都依靠同步器 Sync 的底层实现。
唯一需要注意的是,锁需要规定好 API 的规范,主要是两方面:
API 需要什么,就是锁在初始化的时候,你需要传哪些参数给我,在 ShareLock 初始化时,需要传最大可共享锁的数目;
需要定义自身的能力,即定义每个方法的入参和出参。在 ShareLock 的实现中,加锁和释放锁的入参都没有,是方法里面写死的 1,表示每次方法执行,只能加锁一次或释放锁一次,出参是布尔值,true 表示加锁或释放锁成功,false 表示失败,底层使用的都是 Sync 非公平锁。
以上这种思考方式是有方法论的,就是我们在思考一个问题时,可以从两个方面出发:API 是什么?API 有什么能力?
2.2、定义同步器 Sync
Sync 直接继承 AQS ,代码如下:
class Sync extends AbstractQueuedSynchronizer {
// 表示最多有 count 个共享锁可以获得
public Sync(int count) {
setState(count);
}
// 获得 i 个锁
public boolean acquireByShared(int i) {
// 自旋保证 CAS 一定可以成功
for(;;){
if(i<=0){
return false;
}
int state = getState();
// 如果没有锁可以获得,直接返回 false
if(state <=0 ){
return false;
}
int expectState = state - i;
// 如果要得到的锁不够了,直接返回 false
if(expectState < 0 ){
return false;
}
// CAS 尝试得到锁,CAS 成功获得锁,失败继续 for 循环
if(compareAndSetState(state,expectState)){
return true;
}
}
}
// 释放 i 个锁
@Override
protected boolean tryReleaseShared(int arg) {
for(;;){
if(arg<=0){
return false;
}
int state = getState();
int expectState = state + arg;
// 超过了 int 的最大值,或者 expectState 超过了我们的最大预期
if(expectState < 0 || expectState > maxCount){
log.error("state 超过预期,当前 state is {},计算出的 state is {}",state
,expectState);
return false;
}
if(compareAndSetState(state, expectState)){
return true;
}
}
}
}
整个代码比较清晰,我们需要注意的是:
边界的判断,比如入参是否非法,释放锁时,会不会出现预期的 state 非法等边界问题,对于此类问题我们都需要加以判断,体现出思维的严谨性;
加锁和释放锁,需要用 for 自旋 + CAS 的形式,来保证当并发加锁或释放锁时,可以重试成功。写 for 自旋时,我们需要注意在适当的时机要 return,不要造成死循环,CAS 的方法 AQS 已经提供了,不要自己写,我们自己写的 CAS 方法是无法保证原子性的。
2.3、通过能否获得锁来决定能否得到链接
锁定义好了,我们需要把锁和获取 Mysql 链接结合起来,我们写了一个 Mysql 链接的工具类,叫做 MysqlConnection,其主要负责两大功能:
通过 JDBC 建立和 Mysql 的链接;
结合锁,来防止请求过大时,Mysql 的总链接数不能超过 10 个。
首先我们看下 MysqlConnection 初始化的代码:
public class MysqlConnection {
private final ShareLock lock;
// maxConnectionSize 表示最大链接数
public MysqlConnection(int maxConnectionSize) {
lock = new ShareLock(maxConnectionSize);
}
}
我们可以看到,在初始化时,需要制定最大的链接数是多少,然后把这个数值传递给锁,因为最大的链接数就是 ShareLock 锁的 state 值。
接着为了完成 1,我们写了一个 private 的方法:
// 得到一个 mysql 链接,底层实现省略
private Connection getConnection(){}
然后我们实现 2,代码如下:
// 对外获取 mysql 链接的接口
// 这里不用try finally 的结构,获得锁实现底层不会有异常
// 即使出现未知异常,也无需释放锁
public Connection getLimitConnection() {
if (lock.lock()) {
return getConnection();
}
return null;
}
// 对外释放 mysql 链接的接口
public boolean releaseLimitConnection() {
return lock.unLock();
}
逻辑也比较简单,加锁时,如果获得了锁,就能返回 Mysql 的链接,释放锁时,在链接关闭成功之后,调用 releaseLimitConnection 方法即可,此方法会把锁的 state 状态加一,表示链接被释放了。
以上步骤,针对 Mysql 链接限制的场景锁就完成了。
3、测试
锁写好了,接着我们来测试一下,我们写了一个测试的 demo,代码如下:
public static void main(String[] args) {
log.info("模仿开始获得 mysql 链接");
MysqlConnection mysqlConnection = new MysqlConnection(10);
log.info("初始化 Mysql 链接最大只能获取 10 个");
for(int i =0 ;i<12;i++){
if(null != mysqlConnection.getLimitConnection()){
log.info("获得第{}个数据库链接成功",i+1);
}else {
log.info("获得第{}个数据库链接失败:数据库连接池已满",i+1);
}
}
log.info("模仿开始释放 mysql 链接");
for(int i =0 ;i<12;i++){
if(mysqlConnection.releaseLimitConnection()){
log.info("释放第{}个数据库链接成功",i+1);
}else {
log.info("释放第{}个数据库链接失败",i+1);
}
}
log.info("模仿结束");
}
以上代码逻辑如下:
获得 Mysql 链接逻辑:for 循环获取链接,1~10 都可以获得链接,11~12 获取不到链接,因为链接被用完了;释放锁逻辑:for 循环释放链接,1~10 都可以释放成功,11~12 释放失败。
我们看下运行结果,如下图:
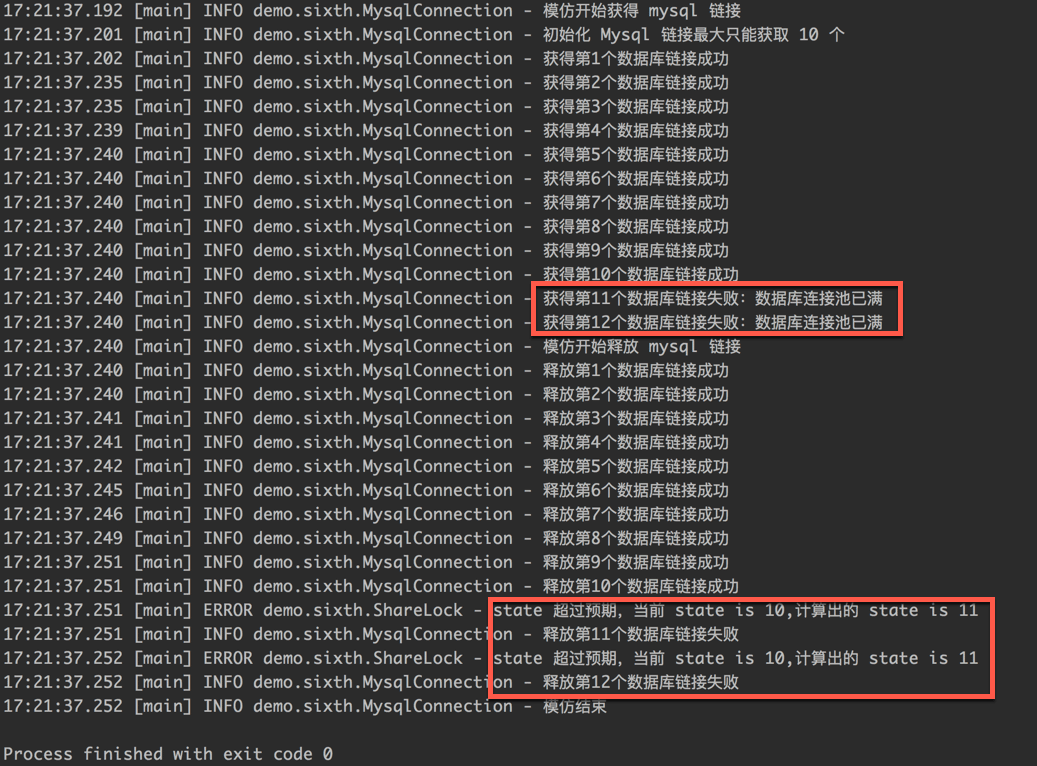
从运行的结果,可以看出,我们实现的 ShareLock 锁已经完成了 Mysql 链接共享的场景了。
4、总结
同学们阅读到这里不知道有没有两点感受:
重写锁真的很简单,最关键的是要和场景完美贴合,能满足业务场景的锁才是好锁;
锁其实只是来满足业务场景的,本质都是 AQS,所以只要 AQS 学会了,在了解清楚场景的情况下,重写锁都不难的。
锁章节最核心的就是 AQS 源码解析的两章,只要我们把 AQS 弄懂了,其余锁的实现,只要稍微看下源码实现,几乎马上就能知道其底层实现的原理,大多数都是通过操作 state 来完成不同的场景需求,所以还是建议大家多看 AQS 源码,多 debug AQS 源码,只要 AQS 弄清楚了,锁都很简单。
以上就是Java源码解析重写锁的设计结构和细节的详细内容,更多关于Java重写锁设计结构和细节解析的资料请关注我们其它相关文章!
相关推荐
-
Java基于注解实现的锁实例解析
背景 某些场景下,有可能一个方法不能被并发执行,有可能一个方法的特定参数不能被并发执行.比如不能将一个消息发送多次,创建缓存最好只创建一次等等.为了实现上面的目标我们就需要采用同步机制来完成,但同步的逻辑如何实现呢,是否会影响到原有逻辑呢? 嵌入式 这里讲的嵌入式是说获取锁以及释放锁的逻辑与业务代码耦合在一起,又分分布式与单机两种不同场景的不同实现. 单机版本 下面方法,每个productId不允许并发访问,所以这里可以直接用synchronized来锁定不同的参数. @Service publ
-
Java可重入锁的实现原理与应用场景
可重入锁,从字面来理解,就是可以重复进入的锁. 可重入锁,也叫做递归锁,指的是同一线程外层函数获得锁之后,内层递归函数仍然有获取该锁的代码,但不受影响. 在JAVA环境下ReentrantLock和synchronized都是可重入锁. synchronized是一个可重入锁.在一个类中,如果synchronized方法1调用了synchronized方法2,方法2是可以正常执行的,这说明synchronized是可重入锁.否则,在执行方法2想获取锁的时候,该锁已经在执行方法1时获取了,那么方法
-
Java 读写锁实现原理浅析
最近做的一个小项目中有这样的需求:整个项目有一份config.json保存着项目的一些配置,是存储在本地文件的一个资源,并且应用中存在读写(读>>写)更新问题.既然读写并发操作,那么就涉及到操作互斥,这里自然想到了读写锁,本文对读写锁方面的知识做个梳理. 为什么需要读写锁? 与传统锁不同的是读写锁的规则是可以共享读,但只能一个写,总结起来为:读读不互斥,读写互斥,写写互斥,而一般的独占锁是:读读互斥,读写互斥,写写互斥,而场景中往往读远远大于写,读写锁就是为了这种优化而创建出来的一种机制. 注
-
Java锁升级的实现过程
对象内存布局 Java对象在内存中存储的布局可以分为3块区域: 对象头.实例数据.对齐填充. 对象头,分为两个部分,第一个部分存储对象自身的运行时数据,又称为Mark Word,32位虚拟机占32bit,64位虚拟机占64bit.如图所示,不同锁状态下,Mark Word的结构,理解下面要介绍的各种锁,和锁升级过程,都需要先充分了解Mark Word的结构. 第二部分是类型指针,指向类元数据指针,虚拟机通过此指针,确定该对象属于那个类的实例. 轻量级锁 轻量级锁是相对于重量级锁(Synchrno
-

Java源码解析重写锁的设计结构和细节
目录 引导语 1.需求 2.详细设计 2.1.定义锁 2.2.定义同步器Sync 2.3.通过能否获得锁来决定能否得到链接 3.测试 4.总结 引导语 有的面试官喜欢让同学在说完锁的原理之后,让你重写一个新的锁,要求现场在白板上写出大概的思路和代码逻辑,这种面试题目,蛮难的,我个人觉得其侧重点主要是两个部分: 考察一下你对锁原理的理解是如何来的,如果你对源码没有解读过的话,只是看看网上的文章,或者背面试题,也是能够说出大概的原理,但你很难现场写出一个锁的实现代码,除非你真的看过源码,或者有和锁相
-
Java源码解析之详解ReentrantLock
ReentrantLock ReentrantLock是一种可重入的互斥锁,它的行为和作用与关键字synchronized有些类似,在并发场景下可以让多个线程按照一定的顺序访问同一资源.相比synchronized,ReentrantLock多了可扩展的能力,比如我们可以创建一个名为MyReentrantLock的类继承ReentrantLock,并重写部分方法使其更加高效. 当一个线程调用ReentrantLock.lock()方法时,如果ReentrantLock没有被其他线程持有,且不存在
-
Java源码解析之GenericDeclaration详解
学习别人实现某个功能的设计思路,来提高自己的编程水平.话不多说,下面进入正题. GenericDeclaration 可以声明类型变量的实体的公共接口,也就是说,只有实现了该接口才能在对应的实体上声明(定义)类型变量,这些实体目前只有三个:Class(类).Construstor(构造器).Method(方法)(详见:Java源码解析之TypeVariable详解 源码 public interface GenericDeclaration { //获得声明列表上的类型变量数组 public T
-
Java源码解析之object类
在源码的阅读过程中,可以了解别人实现某个功能的涉及思路,看看他们是怎么想,怎么做的.接下来,我们看看这篇Java源码解析之object的详细内容. Java基类Object java.lang.Object,Java所有类的父类,在你编写一个类的时候,若无指定父类(没有显式extends一个父类)编译器(一般编译器完成该步骤)会默认的添加Object为该类的父类(可以将该类反编译看其字节码,不过貌似Java7自带的反编译javap现在看不到了). 再说的详细点:假如类A,没有显式继承其他类,编译
-
Java源码解析之超级接口Map
前言 我们在前面说到的无论是链表还是数组,都有自己的优缺点,数组查询速度很快而插入很慢,链表在插入时表现优秀但查询无力.哈希表则整合了数组与链表的优点,能在插入和查找等方面都有不错的速度.我们之后要分析的HashMap就是基于哈希表实现的,不过在JDK1.8中还引入了红黑树,其性能进一步提升了. 今天我们来说一说超级接口Map. 一.接口Map Map是基于Key-Value的数据格式,并且key值不能重复,每个key对应的value值唯一.Map的key也可以为null,但不可重复. 在看Ma
-
Java源码解析之详解ImmutableMap
一.案例场景 遇到过这样的场景,在定义一个static修饰的Map时,使用了大量的put()方法赋值,就类似这样-- public static final Map<String,String> dayMap= new HashMap<>(); static { dayMap.put("Monday","今天上英语课"); dayMap.put("Tuesday","今天上语文课"); dayMap.p
-
Java源码解析之TypeVariable详解
TypeVariable,类型变量,描述类型,表示泛指任意或相关一类类型,也可以说狭义上的泛型(泛指某一类类型),一般用大写字母作为变量,比如K.V.E等. 源码 public interface TypeVariable<D extends GenericDeclaration> extends Type { //获得泛型的上限,若未明确声明上边界则默认为Object Type[] getBounds(); //获取声明该类型变量实体(即获得类.方法或构造器名) D getGenericDe
-
Java源码解析之HashMap的put、resize方法详解
一.HashMap 简介 HashMap 底层采用哈希表结构 数组加链表加红黑树实现,允许储存null键和null值 数组优点:通过数组下标可以快速实现对数组元素的访问,效率高 链表优点:插入或删除数据不需要移动元素,只需要修改节点引用效率高 二.源码分析 2.1 继承和实现 public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable {
-
Java源码解析之接口Collection
一.图示 二.方法定义 我们先想一想,公司如果要我们自己去封装一些操作数组或者链表的工具类,我么需要封装哪些功能呢?不妨就是统计其 大小,增删改查.清空或者是查看否含有某条数据等等.而collection接口就是把这些通常操作提取出来,使其更全面.更通用,那现在我们就来看看其源码都有哪些方法. //返回集合的长度,如果长度大于Integer.MAX_VALUE,返回Integer.MAX_VALUE int size(); //如果集合元素总数为0,返回true boolean isEmpty(
-
Java源码解析之平衡二叉树
一.平衡二叉树的定义 平衡二叉树是一种二叉排序树,其中每一个节点的左子树和右子树的高度差至多等于1 .它是一种高度平衡的二叉排序树.意思是说,要么它是一棵空树,要么它的左子树和右子树都是平衡二叉树,且左子树和右子树的深度之差的绝对值不超过1 .我们将二叉树上结点的左子树深度减去右子树深度的值称为平衡因子BF (Balance Factor),那么平衡二叉树上所有结点的平衡因子只可能是-1 .0 和1. 这里举个栗子: 仔细看图中值为18的节点,18的节点的深度为2 .而它的右子树的深度为0,其差