Kafka多节点分布式集群搭建实现过程详解
上一篇分享了单节点伪分布式集群搭建方法,本篇来分享一下多节点分布式集群搭建方法。多节点分布式集群结构如下图所示:
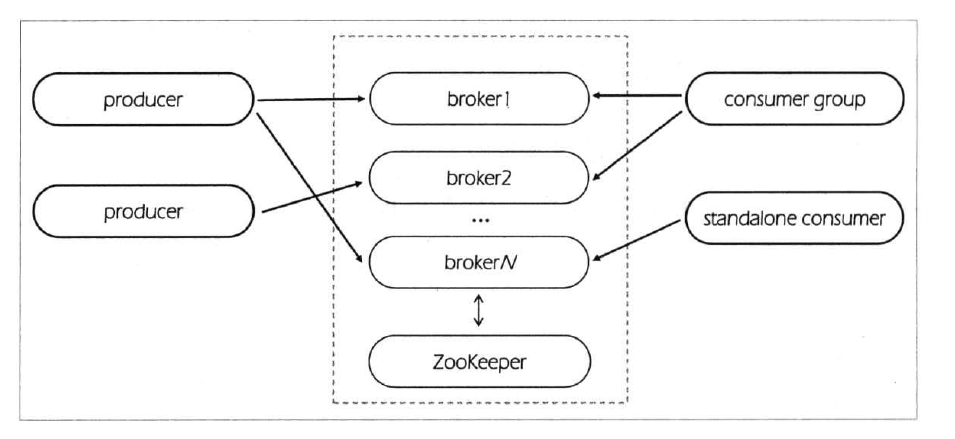
为了方便查阅,本篇将和上一篇一样从零开始一步一步进行集群搭建。
一、安装Jdk
具体安装步骤可参考linux安装jdk。
二、安装与配置zookeeper
下载地址:https://www-us.apache.org/dist/zookeeper/stable/
下载二进制压缩包zookeeper-3.4.14.tar.gz,然后上传到linux服务器指定目录下,本次上传目录为/software,然后执行如下命令安装:
cd /software
tar -zxvf zookeeper-3.4.14.tar.gz
mv zookeeper-3.4.14 /usr/local/zookeeper
cd /usr/local/zookeeper/conf
mv zoo_sample.cfg zoo1.cfg
编辑zoo1.cfg,配置相关参数如下:
tickTime=2000
initLimit=5
syncLimit=2
dataDir=/usr/local/zookeeper/data/zookeeper1
clientPort=2181
server.1=192.168.184.128:2888:3888
server.2=192.168.184.128:2889:3889
server.3=192.168.184.128:2890:3890
其中:
tickTime:Zookeeper最小的时间单位,用于丈量心跳和超时时间,一般设置默认值2秒;
initLimit:指定follower节点初始时连接leader节点的最大tick此处,设置为5,表示follower必须在5xtickTime即10秒内连接上leader,否则视为超时;
syncLimit:设定follower节点与leader节点进行同步的最大时间,设置为2,表示最大时间为2xtickTime即4秒时间;
dataDir:Zookeeper会在内存中保存系统快照,并定期写入该路径指定的文件夹中,生产环境需要特别注意该文件夹的磁盘占用情况;
clientPort:Zookeeper监听客户端连接的端口号,默认为2181,同一服务器上不同实例之间应该有所区别;
server.X=host:port1:port2:此处X的取值范围在1~255之间,必须是全局唯一的且和myid文件中的数字对应(myid文件后面说明),host是各个节点的主机名,port1通常是2888,用于使follower节点连接leader节点,port2通常是3888,用于leader选举,zookeeper在不同服务器上的时候,不同zookeeper服务器的端口号可以重复,在同一台服务器上的时候需要有所区别。
1.配置zoo.cfg文件
单节点安装zookeeper的时候,仅有一份zoo.cfg文件,多节点安装的时候,每个zookeeper服务器就应该有一个zoo.cfg配置文件。如果在一台服务器安装zookeeper多实例集群,则需要在conf目录下分别配置每个实例的zoo.cfg,同时创建每个zookeeper实例自己的数据存储目录。本次在一台服务器上配置多个zookeeper实例,执行如下命令创建数据存储目录并复制配置文件:
mkdir -p /usr/local/zookeeper/data/zookeeper1
mkdir -p /usr/local/zookeeper/data/zookeeper2
mkdir -p /usr/local/zookeeper/data/zookeeper3
cd /usr/local/zookeeper/conf/
cp zoo1.cfg zoo2.cfg
cp zoo1.cfg zoo3.cfg
复制后分别修改zoo2.cfg,zoo3.cfg中的配置,修改后的配置如下:
zoo1.cfg的配置如下:
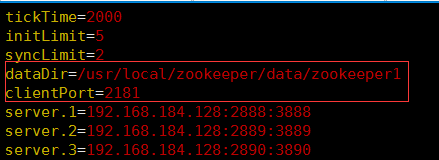
zoo2.cfg的配置如下:
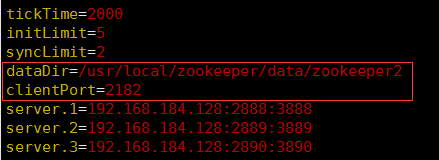
zoo3.cfg中的配置如下:

2.myid文件创建与配置
前面提到zoo.cfg文件中的server.X中的X应该与myid中的数字相对应。除此之外,myid文件必须存放在每个zookeeper实例的data目录下,对应本次安装应该位于/usr/local/zookeeper/data/zookeeper1,2,3目录下,执行如下命令进行配置:
echo '1' > /usr/local/zookeeper/data/zookeeper1/myid
echo '2' > /usr/local/zookeeper/data/zookeeper2/myid
echo '3' > /usr/local/zookeeper/data/zookeeper3/myid
3.启动zookeeper服务器
使用如下命令启动zookeeper集群:
cd /usr/local/zookeeper/bin/
./zkServer.sh start ../conf/zoo1.cfg
./zkServer.sh start ../conf/zoo2.cfg
./zkServer.sh start ../conf/zoo3.cfg
启动后,使用如下命令查看集群状态:
cd /usr/local/zookeeper/bin/
./zkServer.sh status ../conf/zoo1.cfg./zkServer.sh status ../conf/zoo2.cfg./zkServer.sh status ../conf/zoo3.cfg
回显信息如下:

可以看到有两个follower节点,一个leader节点。
三、安装与配置kafka集群
下载地址:http://kafka.apache.org/downloads.html
1.数据目录和配置文件创建
目前最新版本是2.2.0,本次下载2.1.1版本的安装包,然后上传压缩包到服务器指定目录,本次上传目录为/software,然后执行以下命令进行安装:
tar -zxvf kafka_2.12-2.1.1.tgz
mv kafka_2.12-2.1.1 /usr/local/kafka
mkdir -p /usr/local/kafka/logs/kafka1
mkdir -p /usr/local/kafka/logs/kafka2
mkdir -p /usr/local/kafka/logs/kafka3
cd /usr/local/kafka/config/
mv server.properties server1.properties
通过执行上面的命令,我们在/usr/local/kafka/logs文件夹中创建了kafka1,kafka2,kafka3三个文件夹用于存放三个kafka实例的数据,同时将/usr/local/kafka/config/文件夹下的server.properties重命名为server1.properties用于配置kafka的第一个实例。
2.配置属性文件
接下来配置server1.properties文件,主要配置参数如下:
broker.id=1:设置kafka broker的id,本次分别为1,2,3;
delete.topic.enable=true:开启删除topic的开关;
listeners=PLAINTEXT://192.168.184.128:9092:设置kafka的监听地址和端口号,本次分别设置为9092,9093,9094;
log.dirs=/usr/local/kafka/logs/kafka1:设置kafka日志数据存储路径;
zookeeper.connect=192.168.184.128:2181,192.168.184.128:2182,192.168.184.128:2183:设置kafka连接的zookeeper访问地址,集群环境需要配置所有zookeeper的访问地址;
unclean.leader.election.enable=false:为true则代表允许选用非isr列表的副本作为leader,那么此时就意味着数据可能丢失,为false的话,则表示不允许,直接抛出NoReplicaOnlineException异常,造成leader副本选举失败。
zookeeper.connection.timeout.ms=6000:设置连接zookeeper服务器超时时间为6秒。
配置完成后,复制server1.properties两份分别用于配置kafka的第二个,第三个节点:
cd /usr/local/kafka/config/cp server1.properties server2.propertiescp server1.properties server3.properties
修改修改其中的broker.id 以及listeners、log.dirs的配置为第二个,第三个节点的配置,最终各个配置文件配置如下:
server1.properties配置:

server2.properties配置:

server3.properties配置:

3.启动kafka
通过如下命令启动kafka集群:
cd /usr/local/kafka/bin/
./kafka-server-start.sh -daemon ../config/server1.properties
./kafka-server-start.sh -daemon ../config/server2.properties
./kafka-server-start.sh -daemon ../config/server3.properties
使用java的命令jps来查看kafka进程:jps |grep -i kafka

说明kafak启动正常,至此kafka集群搭建完成。本次使用一台服务器作为演示,如果需要在多个服务器上配置集群,配置方法和以上类似,只是不需要像上面那样配置多个数据目录和配置文件,每台服务器的配置保持相同,并且注意在防火墙配置端口号即可。
最后,如果需要远程访问kafka集群,则需要在防火墙中开通9092、9093、9094端口的访问权限。
四、测试
1.topic创建与删除
首先创建一个测试topic,名为testTopic,为了充分利用3个实例(服务器节点),创建3个分区,每个分区都分配3个副本,命令如下:
cd /usr/local/kafka/bin/
./kafka-topics.sh --zookeeper 192.168.184.128:2181 192.168.184.128:2182 192.168.184.128:2183 --create --topic testTopic --partitions 3 --replication-factor 3
回显Created topic "testTopic".则表明testTopic创建成功。执行如下命令进行验证并查看testTopic的信息:
./kafka-topics.sh --zookeeper 192.168.184.128:2181 192.168.184.128:2182 192.168.184.128:2183 --list testTopic
./kafka-topics.sh --zookeeper 192.168.184.128:2181 192.168.184.128:2182 192.168.184.128:2183 --describe --topic testTopic
以上几条命令回显信息如下:

接下来测试topic删除,使用如下命令进行删除:
./kafka-topics.sh --zookeeper 192.168.184.128:2181 192.168.184.128:2182 192.168.184.128:2183 --delete --topic testTopic
执行该条命令后,回显信息如下:

可以看到,testTopic已经被标记为删除,同时第二行提示表明当配置了delete.topic.enable属性为true的时候topic才会删除,否则将不会被删除,本次安装的时候该属性设置的值为true。
2.测试消息发送与消费
首先使用第一步topic创建命令,先创建testTopic这个topic,然后进行消息发送与消费测试。
控制台测试消息发送与消费需要使用kafka的安装目录/usr/local/kafka/bin下的kafka-console-producer.sh来发送消息,使用kafka-console-consumer.sh来消费消息。因此本次打开两个控制台,一个用于执行kafka-console-producer.sh来发送消息,另一个用于执行kafka-console-consumer.sh来消费消息。
消息发送端命令:
cd /usr/local/kafka/bin
./kafka-console-producer.sh --broker-list 192.168.184.128:9092,192.168.184.128:9093,192.168.184.128:9094 --topic testTopic
消息接收端命令:
cd /usr/local/kafka/bin
./kafka-console-consumer.sh --bootstrap-server 192.168.184.128:9092,192.168.184.128:9093,192.168.184.128:9094 --topic testTopic --from-beginning
当发送端和接收端都登录后,在发送端输入需要发送的消息并回车,在接收端可以看到刚才发送的消息:
发送端:

接收端:

以上就是简单地生产消息与消费消息的测试,在测试消费消息的时候时候,命令里边加了个参数--from-beginning表示接收该topic从创建开始的所有消息。
3.生产者吞吐量测试
对于任何一个消息引擎而言,吞吐量是一个至关重要的性能指标。对于Kafka而言,它的吞吐量指每秒能够处理的消息数或者字节数。kafka为了提高吞吐量,采用追加写入方式将消息写入操作系统的页缓存,读取的时候从页缓存读取,因此它不直接参与物理I/O操作,同时使用以sendfile为代表的零拷贝技术进行数据传输提高效率。
kafka提供了kafka-producer-perf-test.sh脚本用于测试生产者吞吐量,使用如下命令启动测试:
cd /usr/local/kafka/bin
./kafka-producer-perf-test.sh --topic testTopic --num-records 50000 --record-size 200 --throughput -1 --producer-props bootstrap.servers=192.168.184.128:9092,192.168.184.128:9093,192.168.184.128:9094 acks=-1

以上回显信息表明这台服务器上每个producer每秒能发送6518个消息,平均吞吐量是1.24MB/s,平均延迟2.035秒,最大延迟3.205秒,平均有50%的消息发送需要2.257秒,95%的消息发送需要3.076秒,99%的消息发送需要3.171秒,99.9%的消息发送需要3.205秒。
4.消费者吞吐量测试
与生产者吞吐量测试类似,kafka提供了kafka-consumer-perf-test.sh脚本用于消费者吞吐量测试,可以执行以下命令进行测试:
cd /usr/local/kafka/bin
./kafka-consumer-perf-test.sh --broker-list 192.168.184.128:9092,192.168.184.128:9093,192.168.184.128:9094 --messages 50000 --topic testTopic

以上是测试50万条消息的consumer吞吐量,结果表明该consumer在1秒总共消费了9.5366MB消息。
以上就是kafka集群的搭建以及测试,如有错误之处,烦请指正。
参考资料:《Apache kafka实战》
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Spring boot 整合KAFKA消息队列的示例
这里使用 spring-kafka 依赖和 KafkaTemplate 对象来操作 Kafka 服务. 一.添加依赖和添加配置项 1.1.在 Pom 文件中添加依赖 <dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka</artifactId> </dependency> 1.2.添加配置项 spring: kafka: b
-
docker-compose部署zk+kafka+storm集群的实现
集群部署总览 172.22.12.20 172.22.12.21 172.22.12.22 172.22.12.23 172.22.12.24 zoo1:2181 zoo2:2182 zoo3:2183 zkui:9090 (admin/manager) kafka1:9092 kafka2:9092 kafka3:9092 kafdrop:9000 influxdb:8086 grafana:3000 (admin/chanhu) storm-nimbus1 storm-nimbus2 sto
-
Kafka单节点伪分布式集群搭建实现过程详解
Kafka集群搭建分为单节点的伪分布式集群和多节点的分布式集群两种,首先来看一下单节点伪分布式集群安装.单节点伪分布式集群是指集群由一台ZooKeeper服务器和一台Kafka broker服务器组成,如下图所示: 为了搭建单节点Kafka集群,需要依次安装如下软件:安装Java-->安装ZooKeeper-->安装Kafka. 一.安装Java 可以参考linux安装jdk,来进行安装 二.安装ZooKeeper 下载地址:https://www-us.apache.org/dist/zoo
-
Python confluent kafka客户端配置kerberos认证流程详解
kafka的认证方式一般有如下3种: 1.SASL/GSSAPI 从版本0.9.0.0开始支持 2.SASL/PLAIN 从版本0.10.0.0开始支持 3.SASL/SCRAM-SHA-256 以及 SASL/SCRAM-SHA-512 从版本0.10.2.0开始支持 其中第一种SASL/GSSAPI的认证就是kerberos认证,对于java来说有原生的支持,但是对于python来说配置稍微麻烦一些,下面说一下具体的配置过程,confluent kafka模块底层依赖于librdkafka,
-
Springboot 1.5.7整合Kafka-client代码示例
在一次项目中,因甲方需要使用kafka消息队列推送数据,所以需要接入kafka,并且kafka的版本是2.11.但是我们项目使用的是Springboot 1.5.7的版本,对应的springboot.kafka.starter有冲突,所以就接入了kafka-client. Kafka 是一个分布式消息引擎与流处理平台,经常用做企业的消息总线.实时数据管道,有的还把它当做存储系统来使用. 早期 Kafka 的定位是一个高吞吐的分布式消息系统,目前则演变成了一个成熟的分布式消息引擎,以及流处理平台.
-
Kafka producer端开发代码实例
一.producer工作流程 producer使用用户启动producer的线程,将待发送的消息封装到一个ProducerRecord类实例,然后将其序列化之后发送给partitioner,再由后者确定目标分区后一同发送到位于producer程序中的一块内存缓冲区中.而producer的另外一个线程(Sender线程)则负责实时从该缓冲区中提取出准备就绪的消息封装进一个批次(batch),统一发送给对应的broker,具体流程如下图: 二.producer示例程序开发 首先引入kafka相关依赖
-
Springboot集成Kafka实现producer和consumer的示例代码
本文介绍如何在springboot项目中集成kafka收发message. Kafka是一种高吞吐量的分布式发布订阅消息系统,有如下特性: 通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能.高吞吐量:即使是非常普通的硬件Kafka也可以支持每秒数百万的消息.支持通过Kafka服务器和消费机集群来分区消息.支持Hadoop并行数据加载. 安装Kafka 因为安装kafka需要zookeeper的支持,所以Windows安装时需要将zookee
-
Kafka Java Producer代码实例详解
根据业务需要可以使用Kafka提供的Java Producer API进行产生数据,并将产生的数据发送到Kafka对应Topic的对应分区中,入口类为:Producer Kafka的Producer API主要提供下列三个方法: public void send(KeyedMessage<K,V> message) 发送单条数据到Kafka集群 public void send(List<KeyedMessage<K,V>> messages) 发送多条数据(数据集)到
-
Kafka多节点分布式集群搭建实现过程详解
上一篇分享了单节点伪分布式集群搭建方法,本篇来分享一下多节点分布式集群搭建方法.多节点分布式集群结构如下图所示: 为了方便查阅,本篇将和上一篇一样从零开始一步一步进行集群搭建. 一.安装Jdk 具体安装步骤可参考linux安装jdk. 二.安装与配置zookeeper 下载地址:https://www-us.apache.org/dist/zookeeper/stable/ 下载二进制压缩包zookeeper-3.4.14.tar.gz,然后上传到linux服务器指定目录下,本次上传目录为/so
-
Linux(Centos7)下redis5集群搭建和使用说明详解
1.简要说明 2018年十月 Redis 发布了稳定版本的 5.0 版本,推出了各种新特性,其中一点是放弃 Ruby的集群方式,改为 使用 C语言编写的 redis-cli的方式,是集群的构建方式复杂度大大降低.关于集群的更新可以在 Redis5 的版本说明中看到,如下: The cluster manager was ported from Ruby (redis-trib.rb) to C code inside redis-cli. check `redis-cli --cluster h
-

浅析Hadoop完全分布式集群搭建问题
目录 一.Hadoop是什么 二.Hadoop组成 1.Hadoop1.x 2.Hadoop2.x 三.Hadoop集群搭建所需工具(链接如下,自行下载) 四.Hadoop集群配置前期准备 五.Hadoop运行环境搭建 六.Hadoop完全分布式集群环境正式搭建 1.编写集群分发脚本xsync 2.集群配置 3.SSH无密登录配置 4.群起集群 5.集群启动/停止方式总结 6.集群时间同步(必须root用户) 一.Hadoop是什么 Hadoop是一个由Apache基金会所开发的分布式系统基础架
-
Centos7.3 RabbitMQ分布式集群搭建示例
本文介绍了Centos7.3 RabbitMQ分布式集群搭建示例,分享给大家,具体如下: 注意事项 centos 7.x 关闭firewall 三台机器: 172.17.250.97 rabbiMQ01 172.17.250.98 rabbiMQ03 172.17.250.99 rabbiMQ02 配置 hosts 172.17.250.97 fz-rabbitMQ01 172.17.250.99 fz-rabbitMQ02 172.17.250.98 fz-rabbitMQ03 $ syste
-
docker swarm 集群故障与异常详解
本文介绍了docker swarm 集群故障与异常详解,分享给大家,具体如下: 在上次遭遇 docker swarm 集群故障后,我们将 docker 由 17.10.0-ce 升级为最新稳定版 docker 17.12.0-ce . 前天晚上22:00之后集群中的2个节点突然出现CPU波动,在CPU波动之后,在凌晨夜深人静.访问量极低的时候,整个集群出现了故障,访问集群上的所有站点都出现了502,过了一段时间后自动恢复正常. ECS实例:swarm1-node5,CPU百分比于00:52发生告
-
Nginx+Tomcat负载均衡集群安装配置案例详解
目录 前言 一.Nginx+Tomcat 二.配置Nginx服务器 三.部署Tomcat应用服务器 总结 前言 介绍Tomcat及Nginx+Tomcat负载均衡集群,Tomcat的应用场景,然后重点介绍Tomcat的安装配置.Nginx+Tomcat负载均衡集案列是应用于生产环境的一套可靠的Web站点解决方案. 一.Nginx+Tomcat 通常情况下,一个Tomcat站点由于可能出现单点故障及无法应付过多客户复杂多样的请求等问题,不能单独应用于生产环境下,所以我们需要一套更可靠的解决方案来完
-
mysql的集群模式 galera-cluster部署详解
一: galera-cluster 的介绍 Galera Cluster是Codership公司开发的一套免费开源的高可用方案,官网为http://galeracluster.com.Galera Cluster即为安装了Galera的Mariadb集群(本文只介绍Mariadb Garela集群).其本身具有multi-master特性,支持多点写入.Galera Cluster的三个(或多个)节点是对等关系,每个节点均支持写入,集群内部会保证写入数据的一致性与完整性,具体实现原理会在本篇中做
-
Java应用服务器之tomcat会话复制集群配置的示例详解
会话是识别用户,跟踪用户访问行为的一个手段,通过cookie(存在客户端)或session(存在服务端)来判断本次请求是那个客户端发送过来:常用的会话保持有绑定会话,就是前边我们聊的在代理上通过算法或通过给客户端响应首部加cookie这种方式来保持同一cookie或同一ip地址的请求始终发送到同一后端server进行响应:但是这样的会话绑定的方式存在一个问题,就是当后端某一server宕机,那么之前上面的所有会话信息将消失,那么后续的客户端来请求,代理是否要把请求调度到后端宕机的server呢?
-
Java Rabbitmq中四种集群架构的区别详解
目录 主备模式 远程模式 镜像模式 多活模式 Federation插件 总结 Rabbitmq 四种集群架构 1. 主备模式 2. 远程模式3. 镜像模式 4. 多活模式 主备模式 主备模式: warren 兔子窝 一个主.一个备方案 主节点如果挂了 从节点提供服务 和Activemq 利用zk 做主/备一样 主备模式 ----------------------->HaProxy 配置 listen rabbitmq_cluster bind 0.0.0.0:5682 # 配置tcp 模式