使用python处理题库表格并转化为word形式的实现
前言
亲人工作考试,公司给的题库好像是直接从数据库导出的表格Excel形式,在移动端上非常难看,需要不断左右上下滑动,看不了多少题眼就瞎了,遂主动请缨编写python脚本解决之。
原本给的题库在手机上横屏显示是这样的↓↓↓(想象一下是在手机上)无比恶心

我的工作
公司给出的格式是.xlsx的(Excel表格的默认格式),盲猜是直接从答题数据库导出的,表名和属性名应该是稍微做了从英文到中文的改变,然后,就直接这样发给员工了…
表格有八个,放在一个文件夹下,由于不同工种的题表头是相同的,因此可以编写代码统一处理。
首先是获取题库存放路径,便于对指定路径文件处理:
to_path = r'D:\python_project\TableAfterProcessing' dir_path = r'D:\python_project\题库名\backup' name_list = [] for i in os.listdir(dir_path): name_list.append(i)
之前学过python库pandas的基本操作,由于一个月前数模美赛的时候使用过并使用博客记录,因此总体来说还不算生疏。
关于Excel表格的读取,作者首先手动将表格转换成了.csv格式(表格不多,因此没必要编写代码了,当然,如果愿意还是可以的)。
观察到表格中知识点一栏数据完全相同,选项个数一栏并没有什么参考价值,因此去掉这两行,只保留题型,题干,选项,答案。
然后就是采用pandas将缺失值null变为空字符串' ',这样的目的是避免将null这个字符写入到word。
for file_name in name_list: # 文件读取路径 from_path = os.path.join(dir_path, file_name) p_data = pd.read_csv(from_path, engine='python', usecols=['题型', '题干', '选项', '答案']) p_data = p_data.where(p_data.notnull(), '')
经过对数据的处理后预处理后,表格便只剩下了四列数据,清爽了很多。
然而光是这样还是不够的,毕竟涉及到手机端浏览表格就得放大,滑动,一不小心点到格子里去还要点出来,对用户很不友好。
因此,我决定将表格数据导入到word,变成常见的题型格式。
这就需要用到python的docx库,关于这个库的讲解就不在这里赘述了,笔者也是通过百度新学习的,这里主要说一下设计和逻辑。
1.题型归类
题型分为单选题,多选题,判断题。表格中对于每一个题都有其对应的类型描述,无外这三种。同时,同一类的数据是聚集在一起的,因此,可以设置标志位记录前一个题目所属的题型,如果当前类别和上一个相同,则只需要写入题号题干等;如果不同,就使用docx中的Document.add_heading()方法新建立一个标题。
2.正确答案标红
如果单纯的将答案写在每一个题的后面或者开头,这样固然可以,但显然不够直观。一种友好的方式是将正确答案标为红色,这样便能直观的看出。
如何实现呢?
原本表格中的答案是以'ABC'这样的方式给出的,python中自带关键字in可以用来判断A串是否连续存在于B中,例如'as' in 'asda',返回值是True,而'sa' in 'asda'返回值则是False。
故而拿到了选项后,只需要使用str.split()方法切分字符串,再依次判断每个字符串的首个字符是否存在于正确答案字符串中就可以了。
拿这组数据举例:
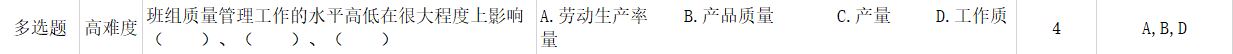
给定选项有:A.劳动生产率 B.产品质量 C.产量 D.工作质量
因此切分后的字符串列表是这样的['A.劳动生产率', 'B.产品质量', 'C.产量',' D.工作质量']
正确答案字符串为'A,B,D'
取其中第一个字符串'A.劳动生产率',首个字符为'A',A存在于'A,B,D'中,证明这条答案是正确的,因此调用docx库自带的方法将字符串写入到word并标记为红色。
# 若为判断题则将答案写入
if q_type == '判断题':
document.add_paragraph(u'答案:' + str(r_ans) + '\n')
# 否则只标红正确选项
else:
res_list = (str(r_choose)).split()
# print(res_list)
p.add_run('\n')
for res in res_list:
run = p.add_run(str(res) + ' ')
# print(res[0])
if res[0] in r_ans:
run.font.color.rgb = RGBColor(255,0,0)
p.add_run('\n')
经过我一通操作后变成了这样↓↓↓
单选题

多选题

判断题

代码
这里放上整个代码,若有需要的同学可以作为参考。
# *-* encoding:utf-8 *-*
import os
import pandas as pd
from docx import Document
from docx.oxml.ns import qn
from docx.shared import RGBColor
to_path = r'D:\python_project\TableAfterProcessing'
dir_path = r'D:\python_project\XXXX\backup'
name_list = []
for i in os.listdir(dir_path):
name_list.append(i)
print(name_list)
# ['D:\\python_project\\XXX考试题库\\backup\\ssss.csv']
for file_name in name_list:
# 文件读取路径
from_path = os.path.join(dir_path, file_name)
# 创建文档对象,设置字体
document = Document()
document.styles['Normal'].font.name = u'宋体'
document.styles['Normal']._element.rPr.rFonts.set(qn('w:eastAsia'), u'宋体')
print((file_name))
p_data = pd.read_csv(from_path, engine='python', usecols=['题型', '题干', '选项', '答案'])
p_data = p_data.where(p_data.notnull(), '')
# 读取指定几列
q_type = ''
for index in range(len(p_data)):
r_type = p_data['题型'][index]
r_cont = p_data['题干'][index]
r_choose = p_data['选项'][index]
r_ans = p_data['答案'][index]
# print(str(r_choose))
# 判断当前题型,确定是否创建对应类别标题
if r_type is not q_type:
q_type = r_type
document.add_heading(q_type)
# 将题号以及题干写入文档
p = document.add_paragraph(str(index+1) + r'.' + str(r_cont))
# 写入选项
# if str(r_choose).strip() is not '':
# document.add_paragraph(str(r_choose))
# 若为判断题则将答案写入
if q_type == '判断题':
document.add_paragraph(u'答案:' + str(r_ans) + '\n')
# 否则只标红正确选项
else:
res_list = (str(r_choose)).split()
# print(res_list)
p.add_run('\n')
for res in res_list:
run = p.add_run(str(res) + ' ')
# print(res[0])
if res[0] in r_ans:
run.font.color.rgb = RGBColor(255,0,0)
p.add_run('\n')
# p.add_run('')
# 切分答案字符串
# pass
# 写入对应路径
document.save(os.path.join(to_path, file_name[0:-4]+'.docx'))
到此这篇关于使用python处理题库表格并转化为word形式的实现的文章就介绍到这了,更多相关python表格转化为word内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python 时间戳与格式化时间的转化实现代码
python 里面与时间有关的模块主要是 time 和 datetime 如果想获取系统当前时间戳:time.time() ,是一个float型的数据 获取系统当前的时间信息 : time.ctime() 是一个str类型的时间字符串,一般比较少用与开发中 如果想获得当前的普通日期字符串,可以简单的用str(datetime.date.today()) 还有就是时间和时间戳之间的相互转化(很常用): 日期到时间戳上的转换: import datetime import time t = date
-
python将秒数转化为时间格式的实例
1.转化成时间格式 seconds =35400 m, s = divmod(seconds, 60) h, m = divmod(m, 60) print("%d:%02d:%02d" % (h, m, s)) 结果:9:50:00 2.转化成日期时间格式 import time timeArray = time.localtime(1462482700)#秒数 otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S",
-
python字符串str和字节数组相互转化方法
实例如下: # bytes object b = b"example" # str object s = "example" # str to bytes bytes(s, encoding = "utf8") # bytes to str str(b, encoding = "utf-8") # an alternative method # str to bytes str.encode(s) # bytes to str
-
python 把列表转化为字符串的方法
如下所示: >>> list1=['ak','uk',4] >>> list2=[str(i) for i in list1] #使用列表推导式把列表中的单个元素全部转化为str类型 >>> list2 #查看转化后的列表 ['ak', 'uk', '4'] >>> list3=' '.join(list2) #把列表中的元素放在空串中,元素间用空格隔开 >>> list3 #查看生成的长串 'ak uk 4' 用p
-
Python实现小数转化为百分数的格式化输出方法示例
本文实例讲述了Python实现小数转化为百分数的格式化输出方法.分享给大家供大家参考,具体如下: 比如将 0.1234 转化为 12.34% 的形式: rate = .1234 print('%.2f%%' % (rate * 100)) 第一个百分号和 .2f 相连,表示浮点数类型保留小数点后两位格式化输出: 然后的两个连续的%%,则最终会输出一个%号出来,有对%进行转义的含义: 将小数(数值)转化为字符串,并赋给其他变量: rate = .1 res = format(res, '.0%')
-
Python处理json字符串转化为字典的简单实现
今天一个朋友给个需求: 来来 {'isOK': 1, 'isRunning': None, 'isError': None} 怎么转换成字典 好,一看就是json转化很简单,开始: import json a = "{'isOK': 1, 'isRunning': None, 'isError': None}" print json.loads(a) 死活出不来结果,还报错,查了两个小时的百度,没搞明白. 最后,直接复制网上的代码,OK,运行成功,可是把我的a变量填进去,不行,报错:开
-
python编程-将Python程序转化为可执行程序[整理]
工欲善其事,必先利其器.python是解释型的语言,但是在windows下如果要执行程序的话还得加个python shell的话,未免也太麻烦了.而这里所说的东西就是将python程序转换为exe文件.下面是一些常用的工具,不过似乎py2exe应用的更加广泛一些. py2exe http://py2exe.sf.net 只支持windows平台,应该是大家听到最多的一个名字了,用户不少,所以有问题的话在它的mail list里面很容易找到答案.文档中提到了"无法找到某某code&quo
-
python 读文件,然后转化为矩阵的实例
代码流程: 1. 从文件中读入数据. 2. 将数据转化成矩阵的形式. 3. 对于矩阵进行处理. 具体的python代码如下: - 文件路径需要设置正确. - 字符串处理. - 字符串数组到 整型数组的转化.( nums = [int(x) for x in nums ]) - 矩阵的构造.(matrix = np.array(nums)) - numpy模块在矩阵处理上很有优势. 列表内容 # -*- coding: utf-8 -*- import numpy as np def readFi
-
使用python处理题库表格并转化为word形式的实现
前言 亲人工作考试,公司给的题库好像是直接从数据库导出的表格Excel形式,在移动端上非常难看,需要不断左右上下滑动,看不了多少题眼就瞎了,遂主动请缨编写python脚本解决之. 原本给的题库在手机上横屏显示是这样的↓↓↓(想象一下是在手机上)无比恶心 我的工作 公司给出的格式是.xlsx的(Excel表格的默认格式),盲猜是直接从答题数据库导出的,表名和属性名应该是稍微做了从英文到中文的改变,然后,就直接这样发给员工了- 表格有八个,放在一个文件夹下,由于不同工种的题表头是相同的,因此可以编写
-
python使用openpyxl库修改excel表格数据方法
1.openpyxl库可以读写xlsx格式的文件,对于xls旧格式的文件只能用xlrd读,xlwt写来完成了. 简单封装类: from openpyxl import load_workbook from openpyxl import Workbook from openpyxl.chart import BarChart, Series, Reference, BarChart3D from openpyxl.styles import Color, Font, Alignment from
-
Python 使用 prettytable 库打印表格美化输出功能
pip install prettytable 每次添加一行 from prettytable import PrettyTable # 默认表头:Field 1.Field 2... # 添加表头 table = PrettyTable(["URL", "参数", "值"]) # add_row 添加一行数据 table.add_row(["http://aaa.com", "raskv", "
-

python使用openpyxl库读写Excel表格的方法(增删改查操作)
一.前言 嗨,大家好,我是新发. 最近需要做个小工具,可以通过python来读写Excel,实现增删改查操作.以前用的是xlrd和xlwt这两个python库,今天我要讲的是openpyxl库,我觉得openpyxl比xlrd和xlwt更强大更好用,话不多说,开始吧. 二.安装openpyxl 可以直接通过命令行安装 pip install openpyxl 如果你是内网环境,则可以先在外网下载openpyxl库然后转到内网再安装. openpyxl下载地址:https://pypi.org/p
-
Python利用prettytable库输出好看的表格
目录 1.前言 2.安装 3.示例 4.添加数据 5.表格输出格式 6.选择性输出 7.表格的样式 1.前言 最近在用 Python 写一个小工具,这个工具主要就是用来管理各种资源的信息,比如阿里云的 ECS 等信息,因为我工作的电脑使用的是 LINUX,所以就想着用 python 写一个命令行的管理工具,基本的功能就是同步阿里云的资源的信息到数据库,然后可以使用命令行查询. 因为信息是展现在命令行中的,众所周知,命令行展现复杂的文本看起来着实累人,于是就想着能像表格那样展示,那看起来就舒服多了
-
Python实现自动整理表格的示例代码
目录 前言 原理 目标实现 运行效果 前言 今天,在工作的时候,我的美女同事问我有没有办法自动生成一个这样的表格: 第一列是院校+科目,第二列是年份,第三列是数量. 这张表格是基于这一文件夹填充的,之前要一个文件夹一个文件夹打开然后手动填写年份和数量 手动整理需要耗费较长时间,于是我便开发了一个 Python 程序用来自动生成归纳表格 利用正则表达式+OS库+openpyxl生成真题年份归纳表格 原理 第一步,遍历文件夹下的所有文件和子文件夹的名称,并获取子文件夹下的文件的年份信息和数量信息 第
-
Python利用openpyxl库遍历Sheet的实例
方法一,利用 sheet.iter_rows() 获取 Sheet1 表中的所有行,然后遍历 import openpyxl wb = openpyxl.load_workbook('example.xlsx') sheet = wb.get_sheet_by_name('Sheet1') for row in sheet.iter_rows(): for cell in row: print(cell.coordinate, cell.value) print('--- END OF ROW
-
python Pandas 读取txt表格的实例
运行环境 Python 2.7 操作实例 1.原始文本格式:空格分隔的txt,例如 2016-03-22 00:06:24.4463094 中文测试字符 2016-03-22 00:06:32.4565680 需要编辑encoding 2016-03-22 00:06:32.6835965 abc 2016-03-22 00:06:32.8041945 egb 2.pandas 读取数据 import pandas as pd data = pd.read_table('Z:/test.txt'
-
零基础使用Python读写处理Excel表格的方法
引 由于需要解决大批量Excel处理的事情,与其手工操作还不如写个简单的代码来处理,大致选了一下感觉还是Python最容易操作. 安装库Python环境 首先当然是配环境,不过选Python的一个重要原因就是Mac内是自带Python环境的,不需要额外的配置环境,省下了一笔工作,如果你用的是Windows系统,那就还需要配置一下Python的环境了,我Mac的Python版本是2.7. 第三方库 Python自己是不支持直接操作Excel的,但是Python强大之处就在于有大量好用的第三方库,这
-
详解Python绘图Turtle库
Turtle库是Python语言中一个很流行的绘制图像的函数库,想象一个小乌龟,在一个横轴为x.纵轴为y的坐标系原点,(0,0)位置开始,它根据一组函数指令的控制,在这个平面坐标系中移动,从而在它爬行的路径上绘制了图形. turtle绘图的基础知识: 1. 画布(canvas) 画布就是turtle为我们展开用于绘图区域,我们可以设置它的大小和初始位置. 设置画布大小 turtle.screensize(canvwidth=None, canvheight=None, bg=None),参数分别