Python实现机器学习算法的分类
Python算法的分类
对葡萄酒数据集进行测试,由于数据集是多分类且数据的样本分布不平衡,所以直接对数据测试,效果不理想。所以使用SMOTE过采样对数据进行处理,对数据去重,去空,处理后数据达到均衡,然后进行测试,与之前测试相比,准确率提升较高。
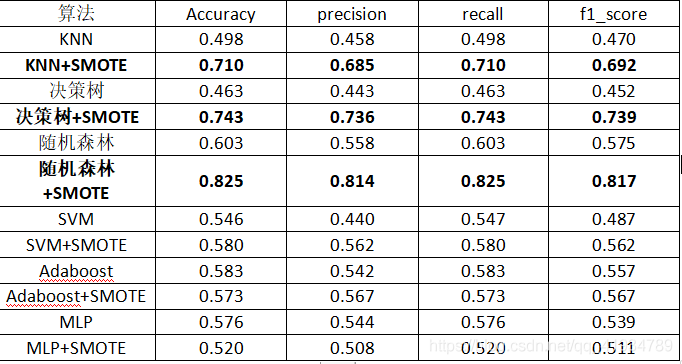
例如:决策树:
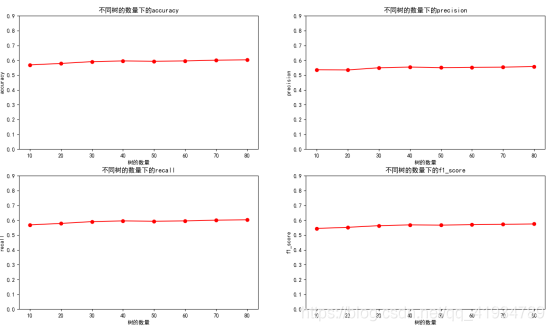
Smote处理前:
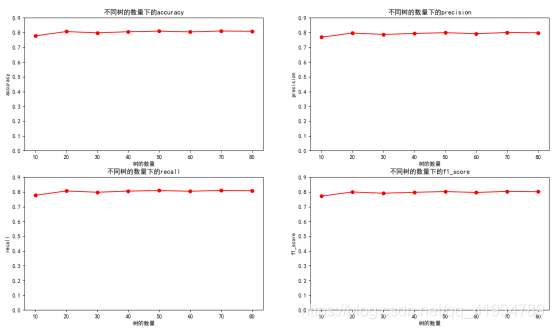
Smote处理后:
from typing import Counter
from matplotlib import colors, markers
import numpy as np
import pandas as pd
import operator
import matplotlib.pyplot as plt
from sklearn import tree
from sklearn.model_selection import train_test_split
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.neural_network import MLPClassifier
from sklearn.svm import SVC
# 判断模型预测准确率的模型
from sklearn.metrics import accuracy_score
from sklearn.metrics import roc_auc_score
from sklearn.metrics import f1_score
from sklearn.metrics import classification_report
#设置绘图内的文字
plt.rcParams['font.family'] = ['sans-serif']
plt.rcParams['font.sans-serif'] = ['SimHei']
path ="C:\\Users\\zt\\Desktop\\winequality\\myexcel.xls"
# path=r"C:\\Users\\zt\\Desktop\\winequality\\winequality-red.csv"#您要读取的文件路径
# exceldata = np.loadtxt(
# path,
# dtype=str,
# delimiter=";",#每列数据的隔开标志
# skiprows=1
# )
# print(Counter(exceldata[:,-1]))
exceldata = pd.read_excel(path)
print(exceldata)
print(exceldata[exceldata.duplicated()])
print(exceldata.duplicated().sum())
#去重
exceldata = exceldata.drop_duplicates()
#判空去空
print(exceldata.isnull())
print(exceldata.isnull().sum)
print(exceldata[~exceldata.isnull()])
exceldata = exceldata[~exceldata.isnull()]
print(Counter(exceldata["quality"]))
#smote
#使用imlbearn库中上采样方法中的SMOTE接口
from imblearn.over_sampling import SMOTE
#定义SMOTE模型,random_state相当于随机数种子的作用
X,y = np.split(exceldata,(11,),axis=1)
smo = SMOTE(random_state=10)
x_smo,y_smo = SMOTE().fit_resample(X.values,y.values)
print(Counter(y_smo))
x_smo = pd.DataFrame({"fixed acidity":x_smo[:,0], "volatile acidity":x_smo[:,1],"citric acid":x_smo[:,2] ,"residual sugar":x_smo[:,3] ,"chlorides":x_smo[:,4],"free sulfur dioxide":x_smo[:,5] ,"total sulfur dioxide":x_smo[:,6] ,"density":x_smo[:,7],"pH":x_smo[:,8] ,"sulphates":x_smo[:,9] ," alcohol":x_smo[:,10]})
y_smo = pd.DataFrame({"quality":y_smo})
print(x_smo.shape)
print(y_smo.shape)
#合并
exceldata = pd.concat([x_smo,y_smo],axis=1)
print(exceldata)
#分割X,y
X,y = np.split(exceldata,(11,),axis=1)
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=10,train_size=0.7)
print("训练集大小:%d"%(X_train.shape[0]))
print("测试集大小:%d"%(X_test.shape[0]))
def func_mlp(X_train,X_test,y_train,y_test):
print("神经网络MLP:")
kk = [i for i in range(200,500,50) ] #迭代次数
t_precision = []
t_recall = []
t_accuracy = []
t_f1_score = []
for n in kk:
method = MLPClassifier(activation="tanh",solver='lbfgs', alpha=1e-5,
hidden_layer_sizes=(5, 2), random_state=1,max_iter=n)
method.fit(X_train,y_train)
MLPClassifier(activation='relu', alpha=1e-05, batch_size='auto', beta_1=0.9,
beta_2=0.999, early_stopping=False, epsilon=1e-08,
hidden_layer_sizes=(5, 2), learning_rate='constant',
learning_rate_init=0.001, max_iter=n, momentum=0.9,
nesterovs_momentum=True, power_t=0.5, random_state=1, shuffle=True,
solver='lbfgs', tol=0.0001, validation_fraction=0.1, verbose=False,
warm_start=False)
y_predict = method.predict(X_test)
t =classification_report(y_test, y_predict, target_names=['3','4','5','6','7','8'],output_dict=True)
print(t)
t_accuracy.append(t["accuracy"])
t_precision.append(t["weighted avg"]["precision"])
t_recall.append(t["weighted avg"]["recall"])
t_f1_score.append(t["weighted avg"]["f1-score"])
plt.figure("数据未处理MLP")
plt.subplot(2,2,1)
#添加文本 #x轴文本
plt.xlabel('迭代次数')
#y轴文本
plt.ylabel('accuracy')
#标题
plt.title('不同迭代次数下的accuracy')
plt.plot(kk,t_accuracy,color="r",marker="o",lineStyle="-")
plt.yticks(np.arange(0,1,0.1))
plt.subplot(2,2,2)
#添加文本 #x轴文本
plt.xlabel('迭代次数')
#y轴文本
plt.ylabel('precision')
#标题
plt.title('不同迭代次数下的precision')
plt.plot(kk,t_precision,color="r",marker="o",lineStyle="-")
plt.yticks(np.arange(0,1,0.1))
plt.subplot(2,2,3)
#添加文本 #x轴文本
plt.xlabel('迭代次数')
#y轴文本
plt.ylabel('recall')
#标题
plt.title('不同迭代次数下的recall')
plt.plot(kk,t_recall,color="r",marker="o",lineStyle="-")
plt.yticks(np.arange(0,1,0.1))
plt.subplot(2,2,4)
#添加文本 #x轴文本
plt.xlabel('迭代次数')
#y轴文本
plt.ylabel('f1_score')
#标题
plt.title('不同迭代次数下的f1_score')
plt.plot(kk,t_f1_score,color="r",marker="o",lineStyle="-")
plt.yticks(np.arange(0,1,0.1))
plt.show()
def func_svc(X_train,X_test,y_train,y_test):
print("向量机:")
kk = ["linear","poly","rbf"] #核函数类型
t_precision = []
t_recall = []
t_accuracy = []
t_f1_score = []
for n in kk:
method = SVC(kernel=n, random_state=0)
method = method.fit(X_train, y_train)
y_predic = method.predict(X_test)
t =classification_report(y_test, y_predic, target_names=['3','4','5','6','7','8'],output_dict=True)
print(t)
t_accuracy.append(t["accuracy"])
t_precision.append(t["weighted avg"]["precision"])
t_recall.append(t["weighted avg"]["recall"])
t_f1_score.append(t["weighted avg"]["f1-score"])
plt.figure("数据未处理向量机")
plt.subplot(2,2,1)
#添加文本 #x轴文本
plt.xlabel('核函数类型')
#y轴文本
plt.ylabel('accuracy')
#标题
plt.title('不同核函数类型下的accuracy')
plt.plot(kk,t_accuracy,color="r",marker="o",lineStyle="-")
plt.yticks(np.arange(0,1,0.1))
plt.subplot(2,2,2)
#添加文本 #x轴文本
plt.xlabel('核函数类型')
#y轴文本
plt.ylabel('precision')
#标题
plt.title('不同核函数类型下的precision')
plt.plot(kk,t_precision,color="r",marker="o",lineStyle="-")
plt.yticks(np.arange(0,1,0.1))
plt.subplot(2,2,3)
#添加文本 #x轴文本
plt.xlabel('核函数类型')
#y轴文本
plt.ylabel('recall')
#标题
plt.title('不同核函数类型下的recall')
plt.plot(kk,t_recall,color="r",marker="o",lineStyle="-")
plt.yticks(np.arange(0,1,0.1))
plt.subplot(2,2,4)
#添加文本 #x轴文本
plt.xlabel('核函数类型')
#y轴文本
plt.ylabel('f1_score')
#标题
plt.title('不同核函数类型下的f1_score')
plt.plot(kk,t_f1_score,color="r",marker="o",lineStyle="-")
plt.yticks(np.arange(0,1,0.1))
plt.show()
def func_classtree(X_train,X_test,y_train,y_test):
print("决策树:")
kk = [10,20,30,40,50,60,70,80,90,100] #决策树最大深度
t_precision = []
t_recall = []
t_accuracy = []
t_f1_score = []
for n in kk:
method = tree.DecisionTreeClassifier(criterion="gini",max_depth=n)
method.fit(X_train,y_train)
predic = method.predict(X_test)
print("method.predict:%f"%method.score(X_test,y_test))
t =classification_report(y_test, predic, target_names=['3','4','5','6','7','8'],output_dict=True)
print(t)
t_accuracy.append(t["accuracy"])
t_precision.append(t["weighted avg"]["precision"])
t_recall.append(t["weighted avg"]["recall"])
t_f1_score.append(t["weighted avg"]["f1-score"])
plt.figure("数据未处理决策树")
plt.subplot(2,2,1)
#添加文本 #x轴文本
plt.xlabel('决策树最大深度')
#y轴文本
plt.ylabel('accuracy')
#标题
plt.title('不同决策树最大深度下的accuracy')
plt.plot(kk,t_accuracy,color="r",marker="o",lineStyle="-")
plt.yticks(np.arange(0,1,0.1))
plt.subplot(2,2,2)
#添加文本 #x轴文本
plt.xlabel('决策树最大深度')
#y轴文本
plt.ylabel('precision')
#标题
plt.title('不同决策树最大深度下的precision')
plt.plot(kk,t_precision,color="r",marker="o",lineStyle="-")
plt.yticks(np.arange(0,1,0.1))
plt.subplot(2,2,3)
#添加文本 #x轴文本
plt.xlabel('决策树最大深度')
#y轴文本
plt.ylabel('recall')
#标题
plt.title('不同决策树最大深度下的recall')
plt.plot(kk,t_recall,color="r",marker="o",lineStyle="-")
plt.yticks(np.arange(0,1,0.1))
plt.subplot(2,2,4)
#添加文本 #x轴文本
plt.xlabel('决策树最大深度')
#y轴文本
plt.ylabel('f1_score')
#标题
plt.title('不同决策树最大深度下的f1_score')
plt.plot(kk,t_f1_score,color="r",marker="o",lineStyle="-")
plt.yticks(np.arange(0,1,0.1))
plt.show()
def func_adaboost(X_train,X_test,y_train,y_test):
print("提升树:")
kk = [0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8]
t_precision = []
t_recall = []
t_accuracy = []
t_f1_score = []
for n in range(100,200,200):
for k in kk:
print("迭代次数为:%d\n学习率:%.2f"%(n,k))
bdt = AdaBoostClassifier(tree.DecisionTreeClassifier(max_depth=2, min_samples_split=20),
algorithm="SAMME",
n_estimators=n, learning_rate=k)
bdt.fit(X_train, y_train)
#迭代100次 ,学习率为0.1
y_pred = bdt.predict(X_test)
print("训练集score:%lf"%(bdt.score(X_train,y_train)))
print("测试集score:%lf"%(bdt.score(X_test,y_test)))
print(bdt.feature_importances_)
t =classification_report(y_test, y_pred, target_names=['3','4','5','6','7','8'],output_dict=True)
print(t)
t_accuracy.append(t["accuracy"])
t_precision.append(t["weighted avg"]["precision"])
t_recall.append(t["weighted avg"]["recall"])
t_f1_score.append(t["weighted avg"]["f1-score"])
plt.figure("数据未处理迭代100次(adaboost)")
plt.subplot(2,2,1)
#添加文本 #x轴文本
plt.xlabel('学习率')
#y轴文本
plt.ylabel('accuracy')
#标题
plt.title('不同学习率下的accuracy')
plt.plot(kk,t_accuracy,color="r",marker="o",lineStyle="-")
plt.yticks(np.arange(0,1,0.1))
plt.subplot(2,2,2)
#添加文本 #x轴文本
plt.xlabel('学习率')
#y轴文本
plt.ylabel('precision')
#标题
plt.title('不同学习率下的precision')
plt.plot(kk,t_precision,color="r",marker="o",lineStyle="-")
plt.yticks(np.arange(0,1,0.1))
plt.subplot(2,2,3)
#添加文本 #x轴文本
plt.xlabel('学习率')
#y轴文本
plt.ylabel('recall')
#标题
plt.title('不同学习率下的recall')
plt.plot(kk,t_recall,color="r",marker="o",lineStyle="-")
plt.yticks(np.arange(0,1,0.1))
plt.subplot(2,2,4)
#添加文本 #x轴文本
plt.xlabel('学习率')
#y轴文本
plt.ylabel('f1_score')
#标题
plt.title('不同学习率下的f1_score')
plt.plot(kk,t_f1_score,color="r",marker="o",lineStyle="-")
plt.yticks(np.arange(0,1,0.1))
plt.show()
# inX 用于分类的输入向量
# dataSet表示训练样本集
# 标签向量为labels,标签向量的元素数目和矩阵dataSet的行数相同
# 参数k表示选择最近邻居的数目
def classify0(inx, data_set, labels, k):
"""实现k近邻"""
data_set_size = data_set.shape[0] # 数据集个数,即行数
diff_mat = np.tile(inx, (data_set_size, 1)) - data_set # 各个属性特征做差
sq_diff_mat = diff_mat**2 # 各个差值求平方
sq_distances = sq_diff_mat.sum(axis=1) # 按行求和
distances = sq_distances**0.5 # 开方
sorted_dist_indicies = distances.argsort() # 按照从小到大排序,并输出相应的索引值
class_count = {} # 创建一个字典,存储k个距离中的不同标签的数量
for i in range(k):
vote_label = labels[sorted_dist_indicies[i]] # 求出第i个标签
# 访问字典中值为vote_label标签的数值再加1,
#class_count.get(vote_label, 0)中的0表示当为查询到vote_label时的默认值
class_count[vote_label[0]] = class_count.get(vote_label[0], 0) + 1
# 将获取的k个近邻的标签类进行排序
sorted_class_count = sorted(class_count.items(),
key=operator.itemgetter(1), reverse=True)
# 标签类最多的就是未知数据的类
return sorted_class_count[0][0]
def func_knn(X_train,X_test,y_train,y_test):
print("k近邻:")
kk = [i for i in range(3,30,5)] #k的取值
t_precision = []
t_recall = []
t_accuracy = []
t_f1_score = []
for n in kk:
y_predict = []
for x in X_test.values:
a = classify0(x, X_train.values, y_train.values, n) # 调用k近邻分类
y_predict.append(a)
t =classification_report(y_test, y_predict, target_names=['3','4','5','6','7','8'],output_dict=True)
print(t)
t_accuracy.append(t["accuracy"])
t_precision.append(t["weighted avg"]["precision"])
t_recall.append(t["weighted avg"]["recall"])
t_f1_score.append(t["weighted avg"]["f1-score"])
plt.figure("数据未处理k近邻")
plt.subplot(2,2,1)
#添加文本 #x轴文本
plt.xlabel('k值')
#y轴文本
plt.ylabel('accuracy')
#标题
plt.title('不同k值下的accuracy')
plt.plot(kk,t_accuracy,color="r",marker="o",lineStyle="-")
plt.yticks(np.arange(0,1,0.1))
plt.subplot(2,2,2)
#添加文本 #x轴文本
plt.xlabel('k值')
#y轴文本
plt.ylabel('precision')
#标题
plt.title('不同k值下的precision')
plt.plot(kk,t_precision,color="r",marker="o",lineStyle="-")
plt.yticks(np.arange(0,1,0.1))
plt.subplot(2,2,3)
#添加文本 #x轴文本
plt.xlabel('k值')
#y轴文本
plt.ylabel('recall')
#标题
plt.title('不同k值下的recall')
plt.plot(kk,t_recall,color="r",marker="o",lineStyle="-")
plt.yticks(np.arange(0,1,0.1))
plt.subplot(2,2,4)
#添加文本 #x轴文本
plt.xlabel('k值')
#y轴文本
plt.ylabel('f1_score')
#标题
plt.title('不同k值下的f1_score')
plt.plot(kk,t_f1_score,color="r",marker="o",lineStyle="-")
plt.yticks(np.arange(0,1,0.1))
plt.show()
def func_randomforest(X_train,X_test,y_train,y_test):
print("随机森林:")
t_precision = []
t_recall = []
t_accuracy = []
t_f1_score = []
kk = [10,20,30,40,50,60,70,80] #默认树的数量
for n in kk:
clf = RandomForestClassifier(n_estimators=n, max_depth=100,min_samples_split=2, random_state=10,verbose=True)
clf.fit(X_train,y_train)
predic = clf.predict(X_test)
print("特征重要性:",clf.feature_importances_)
print("acc:",clf.score(X_test,y_test))
t =classification_report(y_test, predic, target_names=['3','4','5','6','7','8'],output_dict=True)
print(t)
t_accuracy.append(t["accuracy"])
t_precision.append(t["weighted avg"]["precision"])
t_recall.append(t["weighted avg"]["recall"])
t_f1_score.append(t["weighted avg"]["f1-score"])
plt.figure("数据未处理深度100(随机森林)")
plt.subplot(2,2,1)
#添加文本 #x轴文本
plt.xlabel('树的数量')
#y轴文本
plt.ylabel('accuracy')
#标题
plt.title('不同树的数量下的accuracy')
plt.plot(kk,t_accuracy,color="r",marker="o",lineStyle="-")
plt.yticks(np.arange(0,1,0.1))
plt.subplot(2,2,2)
#添加文本 #x轴文本
plt.xlabel('树的数量')
#y轴文本
plt.ylabel('precision')
#标题
plt.title('不同树的数量下的precision')
plt.plot(kk,t_precision,color="r",marker="o",lineStyle="-")
plt.yticks(np.arange(0,1,0.1))
plt.subplot(2,2,3)
#添加文本 #x轴文本
plt.xlabel('树的数量')
#y轴文本
plt.ylabel('recall')
#标题
plt.title('不同树的数量下的recall')
plt.plot(kk,t_recall,color="r",marker="o",lineStyle="-")
plt.yticks(np.arange(0,1,0.1))
plt.subplot(2,2,4)
#添加文本 #x轴文本
plt.xlabel('树的数量')
#y轴文本
plt.ylabel('f1_score')
#标题
plt.title('不同树的数量下的f1_score')
plt.plot(kk,t_f1_score,color="r",marker="o",lineStyle="-")
plt.yticks(np.arange(0,1,0.1))
plt.show()
if __name__ == '__main__':
#神经网络
print(func_mlp(X_train,X_test,y_train,y_test))
#向量机
print(func_svc(X_train,X_test,y_train,y_test))
#决策树
print(func_classtree(X_train,X_test,y_train,y_test))
#提升树
print(func_adaboost(X_train,X_test,y_train,y_test))
#knn
print(func_knn(X_train,X_test,y_train,y_test))
#randomforest
print(func_randomforest(X_train,X_test,y_train,y_test))
到此这篇关于Python实现机器学习算法的分类的文章就介绍到这了,更多相关Python算法分类内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python实现K-means聚类算法并可视化生成动图步骤详解
K-means算法介绍 简单来说,K-means算法是一种无监督算法,不需要事先对数据集打上标签,即ground-truth,也可以对数据集进行分类,并且可以指定类别数目 牧师-村民模型 K-means 有一个著名的解释:牧师-村民模型: 有四个牧师去郊区布道,一开始牧师们随意选了几个布道点,并且把这几个布道点的情况公告给了郊区所有的村民,于是每个村民到离自己家最近的布道点去听课. 听课之后,大家觉得距离太远了,于是每个牧师统计了一下自己的课上所有的村民的地址,搬到了所有地址的中心地带,并且在海
-
python使用ProjectQ生成量子算法指令集
输出算法操作 首先介绍一个最基本的使用方法,就是使用ProjectQ来打印量子算法中所输入的量子门操作,这里使用到了ProjectQ中的DummyEngine后端用于保存操作的指令.比如最简单的一个Bell State的制备,可以通过如下代码实现,并且打印出所保存的基本操作: from projectq import MainEngine from projectq.cengines import DummyEngine from projectq.ops import H, CX, All,
-
Python自然语言处理之切分算法详解
一.前言 我们需要分析某句话,就必须检测该条语句中的词语. 一般来说,一句话肯定包含多个词语,它们互相重叠,具体输出哪一个由自然语言的切分算法决定.常用的切分算法有完全切分.正向最长匹配.逆向最长匹配以及双向最长匹配. 本篇博文将一一介绍这些常用的切分算法. 二.完全切分 完全切分是指,找出一段文本中的所有单词. 不考虑效率的话,完全切分算法其实非常简单.只要遍历文本中的连续序列,查询该序列是否在词典中即可.上一篇我们获取了词典的所有词语dic,这里我们直接用代码遍历某段文本,完全切分出所有的词
-
python3实现Dijkstra算法最短路径的实现
问题描述 现有一个有向赋权图.如下图所示: 问题:根据每条边的权值,求出从起点s到其他每个顶点的最短路径和最短路径的长度. 说明:不考虑权值为负的情况,否则会出现负值圈问题. s:起点 v:算法当前分析处理的顶点 w:与v邻接的顶点 d v d_v dv:从s到v的距离 d w d_w dw:从s到w的距离 c v , w c_{v,w} cv,w:顶点v到顶点w的边的权值 问题分析 Dijkstra算法按阶段进行,同无权最短路径算法(先对距离为0的顶点处理,再对距离为1的顶点处理,以此类
-
Python集成学习之Blending算法详解
一.前言 普通机器学习:从训练数据中学习一个假设. 集成方法:试图构建一组假设并将它们组合起来,集成学习是一种机器学习范式,多个学习器被训练来解决同一个问题. 集成方法分类为: Bagging(并行训练):随机森林 Boosting(串行训练):Adaboost; GBDT; XgBoost Stacking: Blending: 或者分类为串行集成方法和并行集成方法 1.串行模型:通过基础模型之间的依赖,给错误分类样本一个较大的权重来提升模型的性能. 2.并行模型的原理:利用基础模型的独立性,
-
python 算法题——快乐数的多种解法
题目描述: 编写一个算法来确定一个数字是否"快乐". 快乐的数字按照如下方式确定:从一个正整数开始,用其每位数的平方之和取代该数,并重复这个过程,直到最后数字要么收敛等于1且一直等于1,要么将无休止地循环下去且最终不会收敛等于1.能够最终收敛等于1的数就是快乐的数字. 例如:19是一个快乐数字,计算过程如下: 1^2+9^2=82 8^2+2^2=68 6^2+8^2=100 1^2+0^2+0^2=1 要求:当输入快乐的数字时,输出True,否则输出False. 思路: 1. 当输入
-
Python机器学习算法之决策树算法的实现与优缺点
1.算法概述 决策树算法是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法. 分类算法是利用训练样本集获得分类函数即分类模型(分类器),从而实现将数据集中的样本划分到各个类中.分类模型通过学习训练样本中属性集与类别之间的潜在关系,并以此为依据对新样本属于哪一类进行预测. 决策树算法是直观运用概率分析的一种图解法,是一种十分常用的分类方法,属于有监督学习. 决策树是一种树形结构,其中每个内部结点表示在一个属性上的测试,每个
-
python入门之算法学习
前言 参考学习书籍:<算法图解>[美]Aditya Bhargava,袁国忠(译)北京人民邮电出版社,2017 二分查找 binary_search 实现二分查找的python代码如下: def binary_search(list, item): low = 0 #最低位索引位置为0 high = len(list)- 1 #最高位索引位置为总长度-1 while low <= high: mid = (low + high)//2 #检查中间的元素,书上是一条斜杠,我试过加两条斜杠才
-
Python实现机器学习算法的分类
Python算法的分类 对葡萄酒数据集进行测试,由于数据集是多分类且数据的样本分布不平衡,所以直接对数据测试,效果不理想.所以使用SMOTE过采样对数据进行处理,对数据去重,去空,处理后数据达到均衡,然后进行测试,与之前测试相比,准确率提升较高. 例如:决策树: Smote处理前: Smote处理后: from typing import Counter from matplotlib import colors, markers import numpy as np import pandas
-
Python利用机器学习算法实现垃圾邮件的识别
开发工具 **Python版本:**3.6.4 相关模块: scikit-learn模块: jieba模块: numpy模块: 以及一些Python自带的模块. 环境搭建 安装Python并添加到环境变量,pip安装需要的相关模块即可. 逐步实现 (1)划分数据集 网上用于垃圾邮件识别的数据集大多是英文邮件,所以为了表示诚意,我花了点时间找了一份中文邮件的数据集.数据集划分如下: 训练数据集: 7063封正常邮件(data/normal文件夹下): 7775封垃圾邮件(data/spam文件夹下
-
python机器学习之KNN分类算法
本文为大家分享了python机器学习之KNN分类算法,供大家参考,具体内容如下 1.KNN分类算法 KNN分类算法(K-Nearest-Neighbors Classification),又叫K近邻算法,是一个概念极其简单,而分类效果又很优秀的分类算法. 他的核心思想就是,要确定测试样本属于哪一类,就寻找所有训练样本中与该测试样本"距离"最近的前K个样本,然后看这K个样本大部分属于哪一类,那么就认为这个测试样本也属于哪一类.简单的说就是让最相似的K个样本来投票决定. 这里所说的距离,一
-
Python机器学习算法之k均值聚类(k-means)
一开始的目的是学习十大挖掘算法(机器学习算法),并用编码实现一遍,但越往后学习,越往后实现编码,越发现自己的编码水平低下,学习能力低.这一个k-means算法用Python实现竟用了三天时间,可见编码水平之低,而且在编码的过程中看了别人的编码,才发现自己对numpy认识和运用的不足,在自己的代码中有很多可以优化的地方,比如求均值的地方可以用mean直接对数组求均值,再比如去最小值的下标,我用的是argsort排序再取列表第一个,但是有argmin可以直接用啊.下面的代码中这些可以优化的并没有改,
-
纯python实现机器学习之kNN算法示例
前面文章分别简单介绍了线性回归,逻辑回归,贝叶斯分类,并且用python简单实现.这篇文章介绍更简单的 knn, k-近邻算法(kNN,k-NearestNeighbor). k-近邻算法(kNN,k-NearestNeighbor),是最简单的机器学习分类算法之一,其核心思想在于用距离目标最近的k个样本数据的分类来代表目标的分类(这k个样本数据和目标数据最为相似). 原理 kNN算法的核心思想是用距离最近(多种衡量距离的方式)的k个样本数据来代表目标数据的分类. 具体讲,存在训练样本集, 每个
-
Python机器学习算法库scikit-learn学习之决策树实现方法详解
本文实例讲述了Python机器学习算法库scikit-learn学习之决策树实现方法.分享给大家供大家参考,具体如下: 决策树 决策树(DTs)是一种用于分类和回归的非参数监督学习方法.目标是创建一个模型,通过从数据特性中推导出简单的决策规则来预测目标变量的值. 例如,在下面的例子中,决策树通过一组if-then-else决策规则从数据中学习到近似正弦曲线的情况.树越深,决策规则越复杂,模型也越合适. 决策树的一些优势是: 便于说明和理解,树可以可视化表达: 需要很少的数据准备.其他技术通常需要
-
Python基于sklearn库的分类算法简单应用示例
本文实例讲述了Python基于sklearn库的分类算法简单应用.分享给大家供大家参考,具体如下: scikit-learn已经包含在Anaconda中.也可以在官方下载源码包进行安装.本文代码里封装了如下机器学习算法,我们修改数据加载函数,即可一键测试: # coding=gbk ''' Created on 2016年6月4日 @author: bryan ''' import time from sklearn import metrics import pickle as pickle
-
python机器学习算法与数据降维分析详解
目录 一.数据降维 1.特征选择 2.主成分分析(PCA) 3.降维方法使用流程 二.机器学习开发流程 1.机器学习算法分类 2.机器学习开发流程 三.转换器与估计器 1.转换器 2.估计器 一.数据降维 机器学习中的维度就是特征的数量,降维即减少特征数量.降维方式有:特征选择.主成分分析. 1.特征选择 当出现以下情况时,可选择该方式降维: ①冗余:部分特征的相关度高,容易消耗计算性能 ②噪声:部分特征对预测结果有影响 特征选择主要方法:过滤式(VarianceThreshold).嵌入式(正
-
Python机器学习算法之k均值聚类(k-means)
一开始的目的是学习十大挖掘算法(机器学习算法),并用编码实现一遍,但越往后学习,越往后实现编码,越发现自己的编码水平低下,学习能力低.这一个k-means算法用Python实现竟用了三天时间,可见编码水平之低,而且在编码的过程中看了别人的编码,才发现自己对numpy认识和运用的不足,在自己的代码中有很多可以优化的地方,比如求均值的地方可以用mean直接对数组求均值,再比如去最小值的下标,我用的是argsort排序再取列表第一个,但是有argmin可以直接用啊.下面的代码中这些可以优化的并没有改,