keras.utils.to_categorical和one hot格式解析
keras.utils.to_categorical这个方法,源码中,它是这样写的:
Converts a class vector (integers) to binary class matrix.
E.g. for use with categorical_crossentropy.
也就是说它是对于一个类型的容器(整型)的转化为二元类型矩阵。比如用来计算多类别交叉熵来使用的。
其参数也很简单:
def to_categorical(y, num_classes=None): Arguments y: class vector to be converted into a matrix (integers from 0 to num_classes). num_classes: total number of classes.
说的很明白了,y就是待转换容器(其类型为从0到类型数目),而num_classes则是类型的总数。
这样这一句就比较容易理解了:
先通过np生成一个1000*1维的其值为0-9的矩阵,然后再通过keras.utils.to_categorical方法获取成一个1000*10维的二元矩阵。
y_train = keras.utils.to_categorical(np.random.randint(10, size=(1000, 1)), num_classes=10)
说了这么多,其实就是使用onehot对类型标签进行编码。下面的也都是这样解释。
one hot编码是将类别变量转换为机器学习算法易于利用的一种形式的过程。
通过例子可能更容易理解这个概念。
假设我们有一个迷你数据集:
公司名 类别值 价格
VW 1 20000
Acura 2 10011
Honda 3 50000
Honda 3 10000
其中,类别值是分配给数据集中条目的数值编号。比如,如果我们在数据集中新加入一个公司,那么我们会给这家公司一个新类别值4。当独特的条目增加时,类别值将成比例增加。
在上面的表格中,类别值从1开始,更符合日常生活中的习惯。实际项目中,类别值从0开始(因为大多数计算机系统计数),所以,如果有N个类别,类别值为0至N-1.
sklear的LabelEncoder可以帮我们完成这一类别值分配工作。
现在让我们继续讨论one hot编码,将以上数据集one hot编码后,我们得到的表示如下:
VW Acura Honda 价格
1 0 0 20000
0 1 0 10011
0 0 1 50000
0 0 1 10000
简单来说:**keras.utils.to_categorical函数是把类别标签转换为onehot编码(categorical就是类别标签的意思,表示现实世界中你分类的各类别),
而onehot编码是一种方便计算机处理的二元编码。**
补充知识:序列预处理:序列填充之pad_sequences()和one-hot转化之keras.utils.to_categorical()
tensorflow文本处理中,经常会将 padding 和 one-hot 操作共同出现,所以以下两种方法为有效且常用的方法:
一、keras.preprocessing.sequence.pad_sequences()
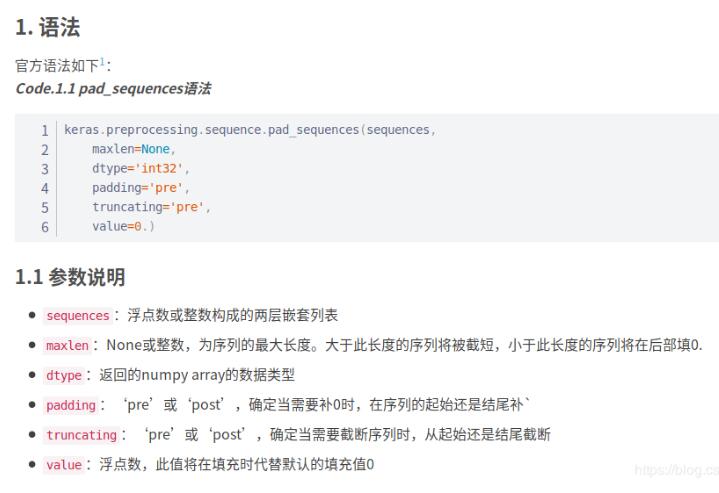
实例:
>>>list_1 = [[2,3,4]] >>>keras.preprocessing.sequence.pad_sequences(list_1, maxlen=10) array([[0, 0, 0, 0, 0, 0, 0, 2, 3, 4]], dtype=int32) >>>list_2 = [[1,2,3,4,5]] >>>keras.preprocessing.sequence.pad_sequences(list_2, maxlen=10) array([[0, 0, 0, 0, 0, 1, 2, 3, 4, 5]], dtype=int32)
二、keras.utils.to_categorical()
to_categorical(y, num_classes=None, dtype='float32')
将整型标签转为onehot。y为int数组,num_classes为标签类别总数,大于max(y)(标签从0开始的)。
返回:如果num_classes=None,返回len(y) * [max(y)+1](维度,m*n表示m行n列矩阵,下同),否则为len(y) * num_classes。说出来显得复杂,请看下面实例。
import keras ohl=keras.utils.to_categorical([1,3]) # ohl=keras.utils.to_categorical([[1],[3]]) print(ohl) """ [[0. 1. 0. 0.] [0. 0. 0. 1.]] """ ohl=keras.utils.to_categorical([1,3],num_classes=5) print(ohl) """ [[0. 1. 0. 0. 0.] [0. 0. 0. 1. 0.]] """
以上这篇keras.utils.to_categorical和one hot格式解析就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Keras中的多分类损失函数用法categorical_crossentropy
from keras.utils.np_utils import to_categorical 注意:当使用categorical_crossentropy损失函数时,你的标签应为多类模式,例如如果你有10个类别,每一个样本的标签应该是一个10维的向量,该向量在对应有值的索引位置为1其余为0. 可以使用这个方法进行转换: from keras.utils.np_utils import to_categorical categorical_labels = to_categorical(int_
-
使用Keras画神经网络准确性图教程
1.在搭建网络开始时,会调用到 keras.models的Sequential()方法,返回一个model参数表示模型 2.model参数里面有个fit()方法,用于把训练集传进网络.fit()返回一个参数,该参数包含训练集和验证集的准确性acc和错误值loss,用这些数据画成图表即可. 如: history=model.fit(x_train, y_train, batch_size=32, epochs=5, validation_split=0.25) #获取数据 #########画图
-
keras实现多种分类网络的方式
Keras应该是最简单的一种深度学习框架了,入门非常的简单. 简单记录一下keras实现多种分类网络:如AlexNet.Vgg.ResNet 采用kaggle猫狗大战的数据作为数据集. 由于AlexNet采用的是LRN标准化,Keras没有内置函数实现,这里用batchNormalization代替 收件建立一个model.py的文件,里面存放着alexnet,vgg两种模型,直接导入就可以了 #coding=utf-8 from keras.models import Sequential f
-
使用Keras构造简单的CNN网络实例
1. 导入各种模块 基本形式为: import 模块名 from 某个文件 import 某个模块 2. 导入数据(以两类分类问题为例,即numClass = 2) 训练集数据data 可以看到,data是一个四维的ndarray 训练集的标签 3. 将导入的数据转化我keras可以接受的数据格式 keras要求的label格式应该为binary class matrices,所以,需要对输入的label数据进行转化,利用keras提高的to_categorical函数 label = np_u
-
keras.utils.to_categorical和one hot格式解析
keras.utils.to_categorical这个方法,源码中,它是这样写的: Converts a class vector (integers) to binary class matrix. E.g. for use with categorical_crossentropy. 也就是说它是对于一个类型的容器(整型)的转化为二元类型矩阵.比如用来计算多类别交叉熵来使用的. 其参数也很简单: def to_categorical(y, num_classes=None): Argume
-
浅谈keras中的keras.utils.to_categorical用法
如下所示: to_categorical(y, num_classes=None, dtype='float32') 将整型标签转为onehot.y为int数组,num_classes为标签类别总数,大于max(y)(标签从0开始的). 返回:如果num_classes=None,返回len(y) * [max(y)+1](维度,m*n表示m行n列矩阵,下同),否则为len(y) * num_classes.说出来显得复杂,请看下面实例. import keras ohl=keras.utils
-

json格式解析和libjson的用法介绍(关于cjson的使用方法)
在阅读本文之前,请先阅读下<Rss Reader实例开发之系统设计>一文. Rss Reader实例开发中,进行网络数据交换时主要使用到了两种数据格式:JSON与XML.本文主要介绍JSON格式的简单概念及JSON在Rss Reader中的应用,XML格式的使用将在下一篇文章做介绍. JSON简介: JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,可以把JSON的结构理解成无序的.可嵌套的key-value键值对集合,这些key-value键值对是
-
C++针对bmp格式解析实例
本文实例讲述了C++针对bmp格式解析的方法,分享给大家供大家参考.具体方法如下: 写这代码时,容易出现如下错误: 1. 忘了on_wm_paint() 一直在界面上画不出来 2. 正确写法 复制代码 代码如下: BYTE* pBits = (BYTE*)lpBase + pbitmapFileHeader->bfOffBits; 写成了 复制代码 代码如下: BYTE* pBits = pbitmapFileHeader->bfOffBits; 这里主要是用了前面一篇中的CWnd框架.
-
python对url格式解析的方法
本文实例讲述了python对url格式解析的方法.分享给大家供大家参考.具体分析如下: python针对url格式的解析,可根据指定的完整URL解析出url地址的各个部分 from urlparse import urlparse url_str = "http://www.163.com/mail/index.htm" url = urlparse(url_str) print 'protocol:',url.scheme print 'hostname:',url.hostname
-
java 如何将多种字符串格式 解析为Date格式
目录 将多种字符串格式 解析为Date格式 如何解析这些字符串呢? 还有一个更简便的方法: Java String格式的标准时间字符串转换为Date格式 场景 实现 将多种字符串格式 解析为Date格式 现在有多种日期格式,比如"2018/01/01"."2018-01-01"."2018 01 01"."2018-01-01 12:12:12"."2018年1月1日" 如何解析这些字符串呢? 之前也是被困
-
JPA like 模糊查询 语法格式解析
目录 JPA like 模糊查询 语法格式 模糊查询:Spring Data JPA 如何进行模糊查询(LIKE) ? 一. 方法一 二. 方法二 JPA like 模糊查询 语法格式 public List<InstitutionInfo> getAllInstitution(final Application app){ String zdGljg = null; Sysuser user = (Sysuser) app.getUser(); String userGljg = user.
-
keras的三种模型实现与区别说明
前言 一.keras提供了三种定义模型的方式 1. 序列式(Sequential) API 序贯(sequential)API允许你为大多数问题逐层堆叠创建模型.虽然说对很多的应用来说,这样的一个手法很简单也解决了很多深度学习网络结构的构建,但是它也有限制-它不允许你创建模型有共享层或有多个输入或输出的网络. 2. 函数式(Functional) API Keras函数式(functional)API为构建网络模型提供了更为灵活的方式. 它允许你定义多个输入或输出模型以及共享图层的模型.除此之外
-
使用keras做SQL注入攻击的判断(实例讲解)
本文是通过深度学习框架keras来做SQL注入特征识别, 不过虽然用了keras,但是大部分还是普通的神经网络,只是外加了一些规则化.dropout层(随着深度学习出现的层). 基本思路就是喂入一堆数据(INT型).通过神经网络计算(正向.反向).SOFTMAX多分类概率计算得出各个类的概率,注意:这里只要2个类别:0-正常的文本:1-包含SQL注入的文本 文件分割上,做成了4个python文件: util类,用来将char转换成int(NN要的都是数字类型的,其他任何类型都要转换成int/fl