Python数据分析库pandas高级接口dt的使用详解
Series对象和DataFrame的列数据提供了cat、dt、str三种属性接口(accessors),分别对应分类数据、日期时间数据和字符串数据,通过这几个接口可以快速实现特定的功能,非常快捷。
今天翻阅pandas官方文档总结了以下几个常用的api。
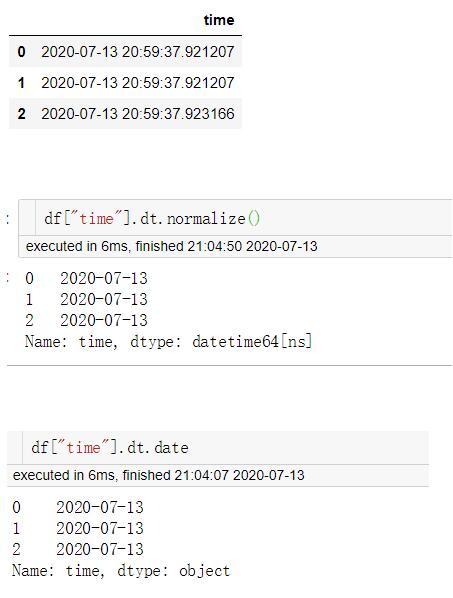
1.dt.date 和 dt.normalize(),他们都返回一个日期的 日期部分,即只包含年月日。但不同的是date返回的Series是object类型的,normalize()返回的Series是datetime64类型的。
这里先简单创建一个dataframe。
2.dt.year、dt.month、dt.day、dt.hour、dt.minute、dt.second、dt.week (dt.weekofyear和dt.week一样)分别返回日期的年、月、日、小时、分、秒及一年中的第几周

3.dt.weekday(dt.dayofweek一样)返回一周中的星期几,0代表星期一,6代表星期天,dt.weekday_name返回星期几的英文。

4.dt.dayofyear 返回一年的第几天,dt.quarter得到每个日期分别是第几个季度。

5.dt.is_month_start和dt.is_month_end 判断日期是否是每月的第一天或最后一天,可以将month换成year和quarter相应的判断日期是否是每年或季度的第一天或最后一天.

6.dt.is_leap_year 判断是否是闰年

7.dt.month_name() 返回月份的英文名称.

补充知识:pandas字符串与时间序列的处理 str 与 dt
一、str属性
pandas里的Series有一个str属性,通个这个属性可以调用一些对字符串处理的通用函数,
如:df['road'].str.contains('康庄大道') 会返回字符串里包含'康庄大道'的数据。
二、dt属性
pandas里对时间序列的处理,使用dt属性,如
df['datetime'].dt.time > time(10,0)
两个series的and比较 是使用 &运算符,如
(df['datetime'].dt.time > time(10,0) ) & (df['datetime'].dt.time < time(12,0)),
返回10点到12点之间的数据。
三、apply 函数示例
df['time'] = df['datetime'].apply(lambda x: x.time())
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
Python数据分析模块pandas用法详解
本文实例讲述了Python数据分析模块pandas用法.分享给大家供大家参考,具体如下: 一 介绍 pandas(Python Data Analysis Library)是基于numpy的数据分析模块,提供了大量标准数据模型和高效操作大型数据集所需要的工具,可以说pandas是使得Python能够成为高效且强大的数据分析环境的重要因素之一. pandas主要提供了3种数据结构: 1)Series,带标签的一维数组. 2)DataFrame,带标签且大小可变的二维表格结构. 3)Panel,带标
-

Python 数据处理库 pandas 入门教程基本操作
pandas是一个Python语言的软件包,在我们使用Python语言进行机器学习编程的时候,这是一个非常常用的基础编程库.本文是对它的一个入门教程. pandas提供了快速,灵活和富有表现力的数据结构,目的是使"关系"或"标记"数据的工作既简单又直观.它旨在成为在Python中进行实际数据分析的高级构建块. 入门介绍 pandas适合于许多不同类型的数据,包括: 具有异构类型列的表格数据,例如SQL表格或Excel数据 有序和无序(不一定是固定频率)时间序列数据.
-
Python使用Pandas库常见操作详解
本文实例讲述了Python使用Pandas库常见操作.分享给大家供大家参考,具体如下: 1.概述 Pandas 是Python的核心数据分析支持库,提供了快速.灵活.明确的数据结构,旨在简单.直观地处理关系型.标记型数据.Pandas常用于处理带行列标签的矩阵数据.与 SQL 或 Excel 表类似的表格数据,应用于金融.统计.社会科学.工程等领域里的数据整理与清洗.数据分析与建模.数据可视化与制表等工作. 数据类型:Pandas 不改变原始的输入数据,而是复制数据生成新的对象,有普通对象构成的
-
Python pandas用法最全整理
1.首先导入pandas库,一般都会用到numpy库,所以我们先导入备用: import numpy as npimport pandas as pd 2.导入CSV或者xlsx文件: df = pd.DataFrame(pd.read_csv('name.csv',header=1))df = pd.DataFrame(pd.read_excel('name.xlsx')) 3.用pandas创建数据表: df = pd.DataFrame({"id":[1001,1002,1003
-
Python数据分析库pandas高级接口dt的使用详解
Series对象和DataFrame的列数据提供了cat.dt.str三种属性接口(accessors),分别对应分类数据.日期时间数据和字符串数据,通过这几个接口可以快速实现特定的功能,非常快捷. 今天翻阅pandas官方文档总结了以下几个常用的api. 1.dt.date 和 dt.normalize(),他们都返回一个日期的 日期部分,即只包含年月日.但不同的是date返回的Series是object类型的,normalize()返回的Series是datetime64类型的. 这里先简单
-
Python数据分析库pandas基本操作方法
pandas是什么? 是它吗? ....很显然pandas没有这个家伙那么可爱.... 我们来看看pandas的官网是怎么来定义自己的: pandas is an open source, easy-to-use data structures and data analysis tools for the Python programming language. 很显然,pandas是python的一个非常强大的数据分析库! 让我们来学习一下它吧! 1.pandas序列 import nump
-
用python标准库difflib比较两份文件的异同详解
[需求背景] 有时候我们要对比两份配置文件是不是一样,或者比较两个文本是否异样,可以使用linux命令行工具diff a_file b_file,但是输出的结果读起来不是很友好.这时候使用python的标准库difflib就能满足我们的需求. 下面这个脚本使用了difflib和argparse,argparse用于解析我们给此脚本传入的两个参数(即两份待比较的文件),由difflib执行比较,比较的结果放到了一个html里面,只要找个浏览器打开此html文件,就能直观地看到比较结果,两份文件有差
-
python sklearn与pandas实现缺失值数据预处理流程详解
注:代码用 jupyter notebook跑的,分割线线上为代码,分割线下为运行结果 1.导入库生成缺失值 通过pandas生成一个6行4列的矩阵,列名分别为'col1','col2','col3','col4',同时增加两个缺失值数据. import numpy as np import pandas as pd from sklearn.impute import SimpleImputer #生成缺失数据 df=pd.DataFrame(np.random.randn(6,4),colu
-
python 第三方库的安装及pip的使用详解
python是一款简单易用的编程语言,特别是其第三方库,能够方便我们快速进入工作,但其第三方库的安装困扰很多人. 现在安装python时,已经能自动安装pip了 安装成功后,我们可以在Scripts 文件夹下看到pip 使用pip 安装类库也比较简单 pip install ... 即可 以上这篇python 第三方库的安装及pip的使用详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
Python标准库datetime之datetime模块用法分析详解
目录 1.日期时间对象 2.创建日期时间对象 2.1.通过datetime.datetime.utcnow()创建 2.2.通过datetime.datetime.today()函数创建 2.3.通过datetime.datetime.now()创建 2.4.通过datetime.datetime()创建 2.5.查看创建的对象 2.6.查看datetime可以处理的最大的日期时间对象及最小的日期时间对象 3.日期事件对象的属性 4.日期时间对象转换为时间元组 5.将日期时间对象转化为公元历开始
-
Python标准库json模块和pickle模块使用详解
将Python数据类型转换为其他代码格式叫做(序列化),而json就是在各个代码实现转换的中间件. 序列化要求: 1. 只能有int,str,bool,list,dict,tuple的类型支持序列化. 2. json序列化是以字符串形式出现.那么:lis= "[11,22,33]" 这样的也能称为序列化. 3. 必须将数据类型包裹在list或dict内进行转换. 4. json内部的str格式,必须以双引号来进行包裹. 5. bool值转换为小写的首字母 json.dumps 将py转
-
Python 第三方库 Pandas 数据分析教程
目录 Pandas导入 Pandas与numpy的比较 Pandas的Series类型 Pandas的Series类型的创建 Pandas的Series类型的基本操作 pandas的DataFrame类型 pandas的DataFrame类型创建 Pandas的Dataframe类型的基本操作 pandas索引操作 pandas重新索引 pandas删除索引 pandas数据运算 算术运算 Pandas数据分析 pandas导入与导出数据 导入数据 导出数据 Pandas查看.检查数据 Pand
-
Python 数据处理库 pandas进阶教程
前言 本文紧接着前一篇的入门教程,会介绍一些关于pandas的进阶知识.建议读者在阅读本文之前先看完pandas入门教程. 同样的,本文的测试数据和源码可以在这里获取: Github:pandas_tutorial. 数据访问 在入门教程中,我们已经使用过访问数据的方法.这里我们再集中看一下. 注:这里的数据访问方法既适用于Series,也适用于DataFrame. 基础方法:[]和. 这是两种最直观的方法,任何有面向对象编程经验的人应该都很容易理解.下面是一个代码示例: # select_da