python抓取需要扫微信登陆页面
一,抓取情况描述
1.抓取的页面需要登陆,以公司网页为例,登陆网址https://app-ticketsys.hezongyun.com/index.php ,(该网页登陆方式微信扫码登陆)
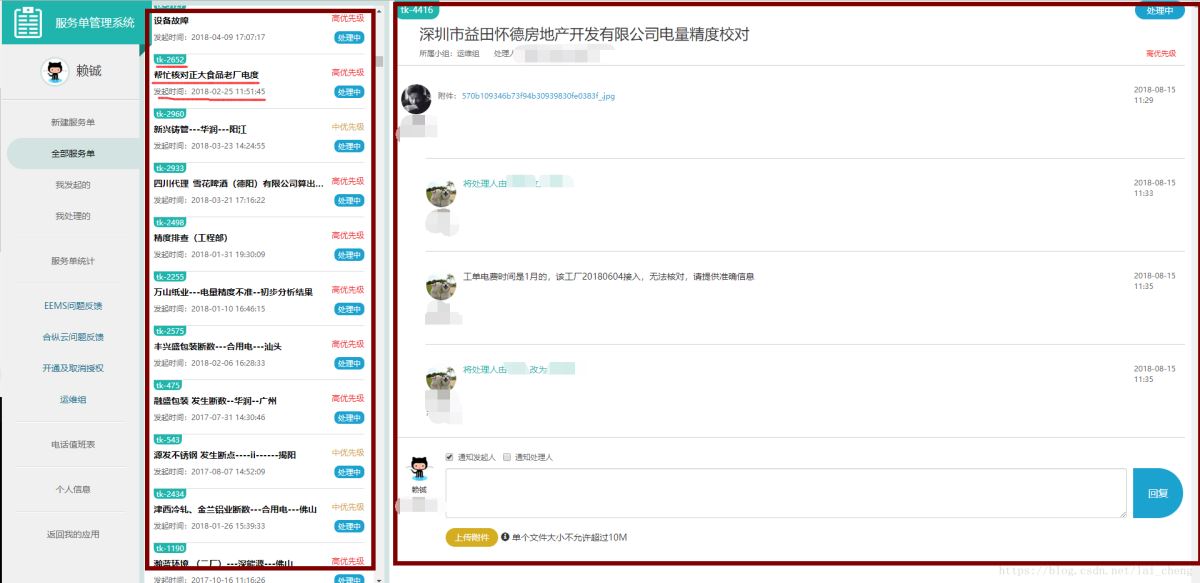
2.需要抓取的内容如下图所示:
需要提取
工单对应编号,如TK-2960
工单发起时间,如2018-08-17 11:12:13
工单标题内容,如设备故障
工单正文内容,如最红框所示
二,网页分析
1.按按Ctrl + Shift + I或者鼠标右键点击检查进入开发人员工具。
可以看到页面显示如下:
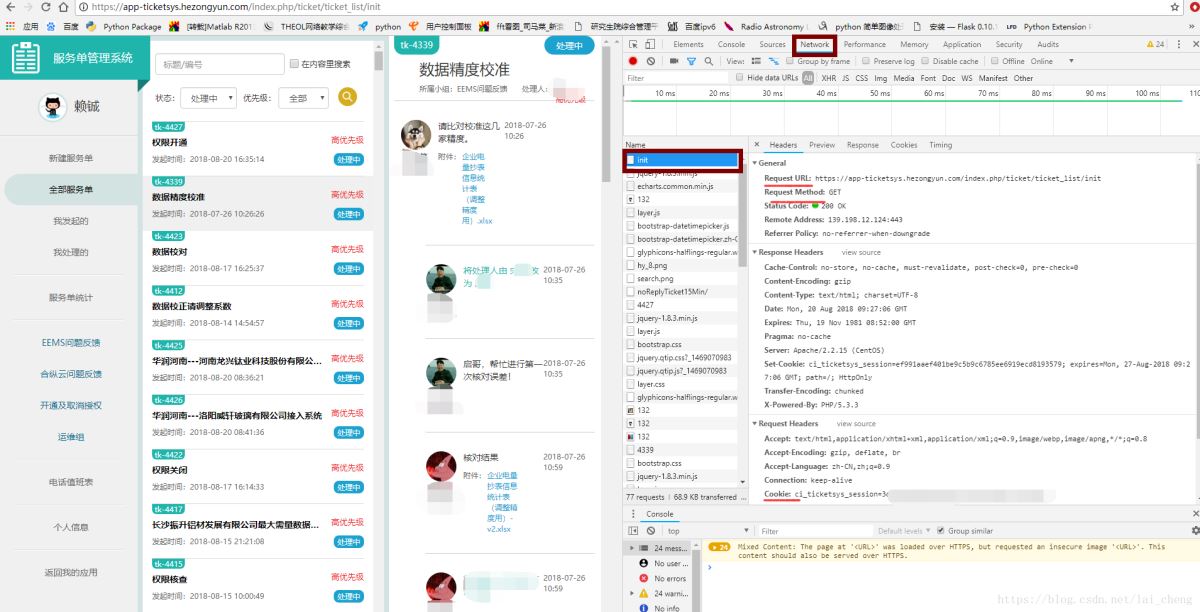
主要关注点如上图框住和划线处
首先点击网络,记住以下信息将用于代码修改处。
Resquest URL:https: //app-ticketsys.hezongyun.com/index.php/ticket/ticket_list/init这个是需要爬取页面的信息请求Menthod:GET饼干:用于需要登陆页面User-Agent:Mozilla / 5.0(Windows NT 10.0; Win64; x64)AppleWebKit / 537.36(KHTML,类似Gecko)Chrome / 67.0.3396.62 Safari / 537.36
记住以上信息后粗略了解网页树形结构用BeatifulSoup中SELEC怎么取出内容
示例:的H1M1一段代码如下:
html =“”“ <html> <head> <title>睡鼠的故事</ title> </ head> <body> <p class =”title“name =”dromouse“> <b>睡鼠的故事</ b > </ p> <p class =“story”>从前有三个小姐妹;他们的名字是 <a href =“http://example.com/elsie”class =“sister”id =“ link1“> <! - Elsie - > </a>, <a href="http://example.com/lacie" rel="external nofollow" class="sister" id="link2"> Lacie </a>和 <a href =“http://example.com/tillie”class =“sister”id =“link3”> Tillie </a>; 他们住在井底。</ p> <p class =“story”> ... </ p> “”“
如果我们喝汤得到了上面那段HTML的结构提取内容方法如下
1.通过标签名查找soup.select( '标题'),如需要取出含有一个标签的内容则soup.select( 'a')的
2.通过类名查找soup.select( 'CLASS_NAME ')如取出标题的内容则soup.select('。标题')
3.通过ID名字查找soup.select( '#ID_NAME')如取出ID = LINK2的内容则soup.select( '#LINK2')
上述元素名字可以利用左上角箭头取出,如下图

三,程序编写
# -*- coding:utf-8 -*-
import requests
import sys
import io
from bs4 import BeautifulSoup
import sys
import xlwt
import urllib,urllib2
import re
def get_text():
#登录后才能访问的网页,这个就是我们在network里查看到的Request URL
url = 'https://app-ticketsys.hezongyun.com/index.php/ticket/ticket_iframe/'
#浏览器登录后得到的cookie,这个就是我们在network里查看到的Coockie
cookie_str = r'ci_ticketsys_session=‘***********************************'
#把cookie字符串处理成字典
cookies = {}
for line in cookie_str.split(';'):
key, value = line.split('=', 1)
cookies[key] = value
#设置请求头
headers = {'User-Agent':'Mozilla/5.0(Windows NT 10.0; Win64;x64)AppleWebKit/537.36 (KHTML, like Gecko)Chrome/67.0.3396.62 Safari/537.36'}
#在发送get请求时带上请求头和cookies
resp = requests.get(url, cookies = cookies,headers = headers)
soup = BeautifulSoup(resp.text,"html.parser")
print soup
上述代码就能得到登陆网页的HTML源码,这个源码呈一个树形结构,接下来针对需求我们提取需要的内容进行提取
我们需要工单号,对应时间,对应标题

按箭头点击到对应工单大块,可以查询到,所有的工单号,工单发起时间,工单标题均在<ul id =“ticket-list”>这个id下面
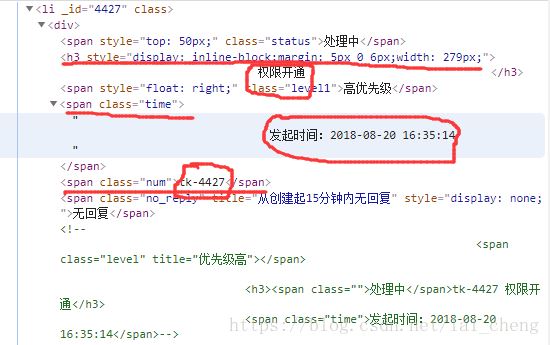
那么点开一个工单结构,例如工单号ID = “4427” 下面我们需要知道工单号,工单发起时间,工单内容可以看到
1.工单内容在H3标签下面
2.工单编号在类=“NUM”下面
3.工单发起时间在类= “时间” 下面
for soups in soup.select('#ticket-list'):
if len(soups.select('h3'))>0:
id_num = soups.select('.num')
star_time = soups.select('.time')
h3 = soups.select('h3')
print id_num,start_time,h3
总结
以上所述是小编给大家介绍的python抓取需要扫微信登陆页面,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
相关推荐
-
Python正则抓取新闻标题和链接的方法示例
本文实例讲述了Python正则抓取新闻标题和链接的方法.分享给大家供大家参考,具体如下: #-*-coding:utf-8-*- import re from urllib import urlretrieve from urllib import urlopen #获取网页信息 doc = urlopen("http://www.itongji.cn/news/").read() #自己找的一个大数据的新闻网站 #抓取新闻标题和链接 def extract_title(info):
-
python 3利用BeautifulSoup抓取div标签的方法示例
前言 本文主要介绍的是关于python 3用BeautifulSoup抓取div标签的方法示例,分享出来供大家参考学习,下面来看看详细的介绍: 示例代码: # -*- coding:utf-8 -*- #python 2.7 #XiaoDeng #http://tieba.baidu.com/p/2460150866 #标签操作 from bs4 import BeautifulSoup import urllib.request import re #如果是网址,可以用这个办法来读取网页 #h
-
Python简单实现网页内容抓取功能示例
本文实例讲述了Python简单实现网页内容抓取功能.分享给大家供大家参考,具体如下: 使用模块: import urllib2 import urllib 普通抓取实例: #!/usr/bin/python # -*- coding: UTF-8 -*- import urllib2 url = 'http://www.baidu.com' #创建request对象 request = urllib2.Request(url) #发送请求,获取结果 try: response = urllib2
-
Python爬虫实现网页信息抓取功能示例【URL与正则模块】
本文实例讲述了Python爬虫实现网页信息抓取功能.分享给大家供大家参考,具体如下: 首先实现关于网页解析.读取等操作我们要用到以下几个模块 import urllib import urllib2 import re 我们可以尝试一下用readline方法读某个网站,比如说百度 def test(): f=urllib.urlopen('http://www.baidu.com') while True: firstLine=f.readline() print firstLine 下面我们说
-
python3实现抓取网页资源的 N 种方法
这两天学习了python3实现抓取网页资源的方法,发现了很多种方法,所以,今天添加一点小笔记. 1.最简单 import urllib.request response = urllib.request.urlopen('http://python.org/') html = response.read() 2.使用 Request import urllib.request req = urllib.request.Request('http://python.org/') response
-

Python实现简单网页图片抓取完整代码实例
利用python抓取网络图片的步骤是: 1.根据给定的网址获取网页源代码 2.利用正则表达式把源代码中的图片地址过滤出来 3.根据过滤出来的图片地址下载网络图片 以下是比较简单的一个抓取某一个百度贴吧网页的图片的实现: # -*- coding: utf-8 -*- # feimengjuan import re import urllib import urllib2 #抓取网页图片 #根据给定的网址来获取网页详细信息,得到的html就是网页的源代码 def getHtml(url): pag
-
python抓取搜狗微信公众号文章
初学python,抓取搜狗微信公众号文章存入mysql mysql表: 代码: import requests import json import re import pymysql # 创建连接 conn = pymysql.connect(host='你的数据库地址', port=端口, user='用户名', passwd='密码', db='数据库名称', charset='utf8') # 创建游标 cursor = conn.cursor() cursor.execute("sel
-
python微信聊天机器人改进版(定时或触发抓取天气预报、励志语录等,向好友推送)
最近想着做一个微信机器人,主要想要实现能够每天定时推送天气预报或励志语录,励志语录要每天有自动更新,定时或当有好友回复时,能够随机推送不同的内容.于是开始了分析思路.博主是采用了多线程群发,因为微信对频繁发送消息过快还会出现发送失败的问题,因此还要加入time.sleep(1),当然时间根据自身情况自己定咯.本想把接入写诗机器人,想想自己的渣电脑于是便放弃了,感兴趣的可以尝试一下.做完会有不少收获希望对你有帮助. (1)我们要找个每天定时更新天气预报的网站,和一个更新励志语录的网站.当然如果你想
-
python抓取需要扫微信登陆页面
一,抓取情况描述 1.抓取的页面需要登陆,以公司网页为例,登陆网址https://app-ticketsys.hezongyun.com/index.php ,(该网页登陆方式微信扫码登陆) 2.需要抓取的内容如下图所示: 需要提取 工单对应编号,如TK-2960 工单发起时间,如2018-08-17 11:12:13 工单标题内容,如设备故障 工单正文内容,如最红框所示 二,网页分析 1.按按Ctrl + Shift + I或者鼠标右键点击检查进入开发人员工具. 可以看到页面显示如下: 主
-
Python 抓取微信公众号账号信息的方法
搜狗微信搜索提供两种类型的关键词搜索,一种是搜索公众号文章内容,另一种是直接搜索微信公众号.通过微信公众号搜索可以获取公众号的基本信息及最近发布的10条文章,今天来抓取一下微信公众号的账号信息 爬虫 首先通过首页进入,可以按照类别抓取,通过"查看更多"可以找出页面链接规则: import requests as req import re reTypes = r'id="pc_\d*" uigs="(pc_\d*)">([\s\S]*?)&
-
python抓取并保存html页面时乱码问题的解决方法
本文实例讲述了python抓取并保存html页面时乱码问题的解决方法.分享给大家供大家参考,具体如下: 在用Python抓取html页面并保存的时候,经常出现抓取下来的网页内容是乱码的问题.出现该问题的原因一方面是自己的代码中编码设置有问题,另一方面是在编码设置正确的情况下,网页的实际编码和标示的编码不符合造成的.html页面标示的编码在这里: 复制代码 代码如下: <meta http-equiv="Content-Type" content="text/html;
-
Python抓取框架Scrapy爬虫入门:页面提取
前言 Scrapy是一个非常好的抓取框架,它不仅提供了一些开箱可用的基础组建,还能够根据自己的需求,进行强大的自定义.本文主要给大家介绍了关于Python抓取框架Scrapy之页面提取的相关内容,分享出来供大家参考学习,下面随着小编来一起学习学习吧. 在开始之前,关于scrapy框架的入门大家可以参考这篇文章:http://www.jb51.net/article/87820.htm 下面创建一个爬虫项目,以图虫网为例抓取图片. 一.内容分析 打开 图虫网,顶部菜单"发现" "
-
Python抓取聚划算商品分析页面获取商品信息并以XML格式保存到本地
本文实例为大家分享了Android九宫格图片展示的具体代码,供大家参考,具体内容如下 #!/user/bin/python # -*- coding: gbk -*- #Spider.py import urllib2 import httplib import StringIO import gzip import re import chardet import sys import os import datetime from xml.dom.minidom import Documen
-
python抓取多种类型的页面方法实例
与抓取预定义好的页面集合不同,抓取一个网站的所有内链会带来一个 挑战,即你不知道会获得什么.好在有几种基本的方法可以识别页面类型. 通过URL 一个网站中所有的博客文章可能都会包含一个 URL(例如 http://example.com/blog/title-of-post). 通过网站中存在或者缺失的特定字段 如果一个页面包含日期,但是不包含作者名字,那你可以将其归类 为新闻稿.如果它有标题.主图片.价格,但是没有主要内容,那么它 可能是一个产品页面. 通过页面中出现的特定标签识别页面 即使不
-
Python抓取框架 Scrapy的架构
最近在学Python,同时也在学如何使用python抓取数据,于是就被我发现了这个非常受欢迎的Python抓取框架Scrapy,下面一起学习下Scrapy的架构,便于更好的使用这个工具. 一.概述 下图显示了Scrapy的大体架构,其中包含了它的主要组件及系统的数据处理流程(绿色箭头所示).下面就来一个个解释每个组件的作用及数据的处理过程. 二.组件 1.Scrapy Engine(Scrapy引擎) Scrapy引擎是用来控制整个系统的数据处理流程,并进行事务处理的触发.更多的详细内容可以看下
-
python抓取网页中链接的静态图片
本文实例为大家分享了python抓取网页中链接的静态图片的具体代码,供大家参考,具体内容如下 # -*- coding:utf-8 -*- #http://tieba.baidu.com/p/2460150866 #抓取图片地址 from bs4 import BeautifulSoup import urllib.request from time import sleep html_doc = "http://tieba.baidu.com/p/2460150866" def ge
-
对python抓取需要登录网站数据的方法详解
scrapy.FormRequest login.py class LoginSpider(scrapy.Spider): name = 'login_spider' start_urls = ['http://www.login.com'] def parse(self, response): return [ scrapy.FormRequest.from_response( response, # username和password要根据实际页面的表单的name字段进行修改 formdat
-
python抓取网页内容并进行语音播报的方法
python2.7,下面是跑在window上的,稍作修改就可以跑在linux上. 实测win7和raspbian均可,且raspbian可以直接调用omxplayer命令进行播放. 利用百度的语音合成api进行语音播报,抓取的页面是北大未名BBS的十大. 先放抓取模块BDWM.py的代码: # -*- coding: utf-8 -*- import urllib2 import HTMLParser class MyParser(HTMLParser.HTMLParser): def __in