Python 通过requests实现腾讯新闻抓取爬虫的方法
最近也是学习了一些爬虫方面的知识。以我自己的理解,通常我们用浏览器查看网页时,是通过浏览器向服务器发送请求,然后服务器响应以后返回一些代码数据,再经过浏览器解析后呈现出来。而爬虫则是通过程序向服务器发送请求,并且将服务器返回的信息,通过一些处理后,就能得到我们想要的数据了。
以下是前段时间我用python写的一个爬取TX新闻标题及其网址的一个简单爬虫:
首先需要用到python中requests(方便全面的http请求库)和 BeautifulSoup(html解析库)。
通过pip来安装这两个库,命令分别是:pip install requests 和 pip install bs4 (如下图)

先放上完整的代码
# coding:utf-8
import requests
from bs4 import BeautifulSoup
url = "http://news.qq.com/"
# 请求腾讯新闻的URL,获取其text文本
wbdata = requests.get(url).text
# 对获取到的文本进行解析
soup = BeautifulSoup(wbdata,'lxml')
# 从解析文件中通过select选择器定位指定的元素,返回一个列表
news_titles = soup.select("div.text > em.f14 > a.linkto")
# 对返回的列表进行遍历
for n in news_titles:
title = n.get_text()
link = n.get("href")
data = {
'标题':title,
'链接':link
}
print(data)
首先引入上述两个库
import requests from bs4 import BeautifulSoup
然后get请求腾讯新闻网url,返回的字符串实质上就是我们手动打开这个网站,然后查看网页源代码所看到的html代码。
wbdata = requests.get(url).text
我们需要的仅仅是某些特定标签里的内容:
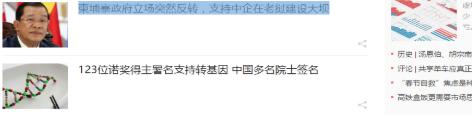

可以看出,每条新闻链接、标题都在<div class="text">标签的<em class="f14 124">标签下
之后我们将刚刚请求得到的html代码进行处理,这时候就需要用到BeautifulSoap库了
soup = BeautifulSoup(wbdata,'lxml')
这一行的意思是对获取的信息进行解析处理,也可以将lxml库换成html.parser库,效果是相同的
news_titles = soup.select("div.text > em.f14 > a.linkto")
这一行是利用刚刚经过解析获取的soup对象,选择我们需要的标签,返回值是一个列表。列表中存放了我们需要的所有标签内容。也可以使用BeautifulSoup中的find()方法或findall()方法来对标签进行选择。
最后用 for in 对列表进行遍历,分别取出标签中的内容(新闻标题)和标签中href的值(新闻网址),存放在data字典中
for n in news_titles:
title = n.get_text()
link = n.get("href")
data = {
'标题':title,
'链接':link
}
data存放的就是所有的新闻标题和链接了,下图是部分结果

这样一个爬虫就完成了,当然这只是一个最简单的爬虫。深入爬虫的话还有许多模拟浏览器行为、安全问题、效率优化、多线程等等需要考虑,不得不说爬虫是一个很深的坑。
python中爬虫可以通过各种库或者框架来完成,requests只是比较常用的一种而已。其他语言中也会有许多爬虫方面的库,例如php可以使用curl库。爬虫的原理都是一样的,只是用不同语言、不同库来实现的方法不一样。
以上这篇Python 通过requests实现腾讯新闻抓取爬虫的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Python3使用requests包抓取并保存网页源码的方法
本文实例讲述了Python3使用requests包抓取并保存网页源码的方法.分享给大家供大家参考,具体如下: 使用Python 3的requests模块抓取网页源码并保存到文件示例: import requests html = requests.get("http://www.baidu.com") with open('test.txt','w',encoding='utf-8') as f: f.write(html.text) 这是一个基本的文件保存操作,但这里有几个值得注意的
-
python采用requests库模拟登录和抓取数据的简单示例
如果你还在为python的各种urllib和urlibs,cookielib 头疼,或者还还在为python模拟登录和抓取数据而抓狂,那么来看看我们推荐的requests,python采集数据模拟登录必备利器! 这也是python推荐的HTTP客户端库: 本文就以一个模拟登录的例子来加以说明,至于采集大家就请自行发挥吧. 代码很简单,主要是展现python的requests库的简单至极,代码如下: s = requests.session() data = {'user':'用户名','pass
-

用python的requests第三方模块抓取王者荣耀所有英雄的皮肤实例
本文使用python的第三方模块requests爬取王者荣耀所有英雄的图片,并将图片按每个英雄为一个目录存入文件夹中,方便用作桌面壁纸 下面时具体的代码,已通过python3.6测试,可以成功运行: 对于所要爬取的网页连接可以通过王者荣耀官网找到, # -*- coding: utf-8 -*- """ Created on Wed Dec 13 13:49:52 2017 @author:KillerTwo """ import request
-
python使用requests.session模拟登录
最近开发一套接口,写个Python脚本,使用requests.session模拟一下登录. 因为每次需要获取用户信息,登录需要带着session信息,所以所有请求需要带着session. 请求使用post方式,请求参数类型为raw方式,参数为json类型. 登录接口参数和结果如下: 脚本如下: 1. 引入需要的第三方包 #! /usr/bin/env python3 # -*- coding: utf-8 -*- import requests # import re import json #
-
python requests证书问题解决
用requests包请求https的网站时,我们偶尔会遇到证书问题.也就是常见的SSLerror,遇到这种问题莫慌莫慌. 这里没有找到合适的网站去报SSL证书的错误,所以就假装请求了一个https的网站,然后给报了SSLerror了,然后下面是解决方法 可以直接关闭验证ssl证书 import requests ''' :param proxies: (optional) Dictionary mapping protocol to the URL of the proxy. :param ve
-
Python使用grequests(gevent+requests)并发发送请求过程解析
前言 requests是Python发送接口请求非常好用的一个三方库,由K神编写,简单,方便上手快.但是requests发送请求是串行的,即阻塞的.发送完一条请求才能发送另一条请求. 为了提升测试效率,一般我们需要并行发送请求.这里可以使用多线程,或者协程,gevent或者aiohttp,然而使用起来,都相对麻烦. grequests是K神基于gevent+requests编写的一个并发发送请求的库,使用起来非常简单. 安装方法: pip install gevent grequests 项目地
-
Python使用lxml模块和Requests模块抓取HTML页面的教程
Web抓取 Web站点使用HTML描述,这意味着每个web页面是一个结构化的文档.有时从中 获取数据同时保持它的结构是有用的.web站点不总是以容易处理的格式, 如 csv 或者 json 提供它们的数据. 这正是web抓取出场的时机.Web抓取是使用计算机程序将web页面数据进行收集 并整理成所需格式,同时保存其结构的实践. lxml和Requests lxml(http://lxml.de/)是一个优美的扩展库,用来快速解析XML以及HTML文档 即使所处理的标签非常混乱.我们也将使用 Re
-
python requests抓取one推送文字和图片代码实例
这篇文章主要介绍了python requests抓取one推送文字和图片代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 requests是Python中一个第三方库,基于 urllib,采用 Apache2 Licensed 开源协议的 HTTP 库.它比 urllib 更加方便,可以节约我们大量的工作,完全满足 HTTP 测试需求.接下来将记录一下requests的使用: from bs4 import BeautifulSoup f
-
Python3+Requests+Excel完整接口自动化测试框架的实现
框架整体使用Python3+Requests+Excel:包含对实时token的获取 1.------base -------runmethond.py runmethond:对不同的请求方式进行封装 import json import requests requests.packages.urllib3.disable_warnings() class RunMethod: def post_main(self, url, data, header=None): res = None if
-
Python 通过requests实现腾讯新闻抓取爬虫的方法
最近也是学习了一些爬虫方面的知识.以我自己的理解,通常我们用浏览器查看网页时,是通过浏览器向服务器发送请求,然后服务器响应以后返回一些代码数据,再经过浏览器解析后呈现出来.而爬虫则是通过程序向服务器发送请求,并且将服务器返回的信息,通过一些处理后,就能得到我们想要的数据了. 以下是前段时间我用python写的一个爬取TX新闻标题及其网址的一个简单爬虫: 首先需要用到python中requests(方便全面的http请求库)和 BeautifulSoup(html解析库). 通过pip来安装这两个
-
Python开发中爬虫使用代理proxy抓取网页的方法示例
本文实例讲述了Python开发中爬虫使用代理proxy抓取网页的方法.分享给大家供大家参考,具体如下: 代理类型(proxy):透明代理 匿名代理 混淆代理和高匿代理. 这里写一些python爬虫使用代理的知识, 还有一个代理池的类. 方便大家应对工作中各种复杂的抓取问题. urllib 模块使用代理 urllib/urllib2使用代理比较麻烦, 需要先构建一个ProxyHandler的类, 随后将该类用于构建网页打开的opener的类,再在request中安装该opener. 代理格式是"h
-
Python打印scrapy蜘蛛抓取树结构的方法
本文实例讲述了Python打印scrapy蜘蛛抓取树结构的方法.分享给大家供大家参考.具体如下: 通过下面这段代码可以一目了然的知道scrapy的抓取页面结构,调用也非常简单 #!/usr/bin/env python import fileinput, re from collections import defaultdict def print_urls(allurls, referer, indent=0): urls = allurls[referer] for url in urls
-
Python实现登录人人网并抓取新鲜事的方法
本文实例讲述了Python实现登录人人网并抓取新鲜事的方法.分享给大家供大家参考.具体如下: 这里演示了Python登录人人网并抓取新鲜事的方法(抓取后的排版不太美观~~) from sgmllib import SGMLParser import sys,urllib2,urllib,cookielib class spider(SGMLParser): def __init__(self,email,password): SGMLParser.__init__(self) self.h3=F
-
Python实现周期性抓取网页内容的方法
本文实例讲述了Python实现周期性抓取网页内容的方法.分享给大家供大家参考,具体如下: 1.使用sched模块可以周期性地执行指定函数 2.在周期性执行指定函数中抓取指定网页,并解析出想要的网页内容,代码中是六维论坛的在线人数 论坛在线人数统计代码: #coding=utf-8 import time,sched,os,urllib2,re,string #初始化sched模块的scheduler类 #第一个参数是一个可以返回时间戳的函数,第二个参数可以在定时未到达之前阻塞. s = sche
-
python使用自定义user-agent抓取网页的方法
本文实例讲述了python使用自定义user-agent抓取网页的方法.分享给大家供大家参考.具体如下: 下面python代码通过urllib2抓取指定的url的内容,并且使用自定义的user-agent,可防止网站屏蔽采集器 import urllib2 req = urllib2.Request('http://192.168.1.2/') req.add_header('User-agent', 'Mozilla 5.10') res = urllib2.urlopen(req) html
-
Python使用Selenium模块实现模拟浏览器抓取淘宝商品美食信息功能示例
本文实例讲述了Python使用Selenium模块实现模拟浏览器抓取淘宝商品美食信息功能.分享给大家供大家参考,具体如下: import re from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected
-
Python数据抓取爬虫代理防封IP方法
爬虫:一段自动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息,一般来说,Python爬虫程序很多时候都要使用(飞猪IP)代理的IP地址来爬取程序,但是默认的urlopen是无法使用代理的IP的,我就来分享一下Python爬虫怎样使用代理IP的经验.(推荐飞猪代理IP注册可免费使用,浏览器搜索可找到) 1.划重点,小编我用的是Python3哦,所以要导入urllib的request,然后我们调用ProxyHandler,它可以接收代理IP的参数.代理可以根据自己需要选择,当然免费的也是有
-
Python使用requests xpath 并开启多线程爬取西刺代理ip实例
我就废话不多说啦,大家还是直接看代码吧! import requests,random from lxml import etree import threading import time angents = [ "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)", "Mozilla/4.0 (compati