浅谈Python实现Apriori算法介绍
导读:
随着大数据概念的火热,啤酒与尿布的故事广为人知。我们如何发现买啤酒的人往往也会买尿布这一规律?数据挖掘中的用于挖掘频繁项集和关联规则的Apriori算法可以告诉我们。本文首先对Apriori算法进行简介,而后进一步介绍相关的基本概念,之后详细的介绍Apriori算法的具体策略和步骤,最后给出Python实现代码。
1.Apriori算法简介
Apriori算法是经典的挖掘频繁项集和关联规则的数据挖掘算法。A priori在拉丁语中指"来自以前"。当定义问题时,通常会使用先验知识或者假设,这被称作"一个先验"(a priori)。Apriori算法的名字正是基于这样的事实:算法使用频繁项集性质的先验性质,即频繁项集的所有非空子集也一定是频繁的。Apriori算法使用一种称为逐层搜索的迭代方法,其中k项集用于探索(k+1)项集。首先,通过扫描数据库,累计每个项的计数,并收集满足最小支持度的项,找出频繁1项集的集合。该集合记为L1。然后,使用L1找出频繁2项集的集合L2,使用L2找出L3,如此下去,直到不能再找到频繁k项集。每找出一个Lk需要一次数据库的完整扫描。Apriori算法使用频繁项集的先验性质来压缩搜索空间。
2. 基本概念
- 项与项集:设itemset={item1, item_2, …, item_m}是所有项的集合,其中,item_k(k=1,2,…,m)成为项。项的集合称为项集(itemset),包含k个项的项集称为k项集(k-itemset)。
- 事务与事务集:一个事务T是一个项集,它是itemset的一个子集,每个事务均与一个唯一标识符Tid相联系。不同的事务一起组成了事务集D,它构成了关联规则发现的事务数据库。
- 关联规则:关联规则是形如A=>B的蕴涵式,其中A、B均为itemset的子集且均不为空集,而A交B为空。
- 支持度(support):关联规则的支持度定义如下:
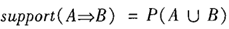
其中 表示事务包含集合A和B的并(即包含A和B中的每个项)的概率。注意与P(A or B)区别,后者表示事务包含A或B的概率。
表示事务包含集合A和B的并(即包含A和B中的每个项)的概率。注意与P(A or B)区别,后者表示事务包含A或B的概率。
置信度(confidence):关联规则的置信度定义如下:

项集的出现频度(support count):包含项集的事务数,简称为项集的频度、支持度计数或计数。
频繁项集(frequent itemset):如果项集I的相对支持度满足事先定义好的最小支持度阈值(即I的出现频度大于相应的最小出现频度(支持度计数)阈值),则I是频繁项集。
强关联规则:满足最小支持度和最小置信度的关联规则,即待挖掘的关联规则。
3. 实现步骤
一般而言,关联规则的挖掘是一个两步的过程:
- 找出所有的频繁项集
- 由频繁项集产生强关联规则
3.1挖掘频繁项集
3.1.1相关定义
连接步骤:频繁(k-1)项集Lk-1的自身连接产生候选k项集Ck
Apriori算法假定项集中的项按照字典序排序。如果Lk-1中某两个的元素(项集)itemset1和itemset2的前(k-2)个项是相同的,则称itemset1和itemset2是可连接的。所以itemset1与itemset2连接产生的结果项集是{itemset1[1], itemset1[2], …, itemset1[k-1], itemset2[k-1]}。连接步骤包含在下文代码中的create_Ck函数中。
剪枝策略
由于存在先验性质:任何非频繁的(k-1)项集都不是频繁k项集的子集。因此,如果一个候选k项集Ck的(k-1)项子集不在Lk-1中,则该候选也不可能是频繁的,从而可以从Ck中删除,获得压缩后的Ck。下文代码中的is_apriori函数用于判断是否满足先验性质,create_Ck函数中包含剪枝步骤,即若不满足先验性质,剪枝。
删除策略
基于压缩后的Ck,扫描所有事务,对Ck中的每个项进行计数,然后删除不满足最小支持度的项,从而获得频繁k项集。删除策略包含在下文代码中的generate_Lk_by_Ck函数中。
3.1.2 步骤
- 每个项都是候选1项集的集合C1的成员。算法扫描所有的事务,获得每个项,生成C1(见下文代码中的create_C1函数)。然后对每个项进行计数。然后根据最小支持度从C1中删除不满足的项,从而获得频繁1项集L1。
- 对L1的自身连接生成的集合执行剪枝策略产生候选2项集的集合C2,然后,扫描所有事务,对C2中每个项进行计数。同样的,根据最小支持度从C2中删除不满足的项,从而获得频繁2项集L2。
- 对L2的自身连接生成的集合执行剪枝策略产生候选3项集的集合C3,然后,扫描所有事务,对C3每个项进行计数。同样的,根据最小支持度从C3中删除不满足的项,从而获得频繁3项集L3。
- 以此类推,对Lk-1的自身连接生成的集合执行剪枝策略产生候选k项集Ck,然后,扫描所有事务,对Ck中的每个项进行计数。然后根据最小支持度从Ck中删除不满足的项,从而获得频繁k项集。
3.2 由频繁项集产生关联规则
一旦找出了频繁项集,就可以直接由它们产生强关联规则。产生步骤如下:
对于每个频繁项集itemset,产生itemset的所有非空子集(这些非空子集一定是频繁项集);
对于itemset的每个非空子集s,如果 ,则输出
,则输出 ,其中min_conf是最小置信度阈值。
,其中min_conf是最小置信度阈值。
4. 样例以及Python实现代码
下图是《数据挖掘:概念与技术》(第三版)中挖掘频繁项集的样例图解。

本文基于该样例的数据编写Python代码实现Apriori算法。代码需要注意如下两点:
- 由于Apriori算法假定项集中的项是按字典序排序的,而集合本身是无序的,所以我们在必要时需要进行set和list的转换;
- 由于要使用字典(support_data)记录项集的支持度,需要用项集作为key,而可变集合无法作为字典的key,因此在合适时机应将项集转为固定集合frozenset。
"""
# Python 2.7
# Filename: apriori.py
# Author: llhthinker
# Email: hangliu56[AT]gmail[DOT]com
# Blog: http://www.cnblogs.com/llhthinker/p/6719779.html
# Date: 2017-04-16
"""
def load_data_set():
"""
Load a sample data set (From Data Mining: Concepts and Techniques, 3th Edition)
Returns:
A data set: A list of transactions. Each transaction contains several items.
"""
data_set = [['l1', 'l2', 'l5'], ['l2', 'l4'], ['l2', 'l3'],
['l1', 'l2', 'l4'], ['l1', 'l3'], ['l2', 'l3'],
['l1', 'l3'], ['l1', 'l2', 'l3', 'l5'], ['l1', 'l2', 'l3']]
return data_set
def create_C1(data_set):
"""
Create frequent candidate 1-itemset C1 by scaning data set.
Args:
data_set: A list of transactions. Each transaction contains several items.
Returns:
C1: A set which contains all frequent candidate 1-itemsets
"""
C1 = set()
for t in data_set:
for item in t:
item_set = frozenset([item])
C1.add(item_set)
return C1
def is_apriori(Ck_item, Lksub1):
"""
Judge whether a frequent candidate k-itemset satisfy Apriori property.
Args:
Ck_item: a frequent candidate k-itemset in Ck which contains all frequent
candidate k-itemsets.
Lksub1: Lk-1, a set which contains all frequent candidate (k-1)-itemsets.
Returns:
True: satisfying Apriori property.
False: Not satisfying Apriori property.
"""
for item in Ck_item:
sub_Ck = Ck_item - frozenset([item])
if sub_Ck not in Lksub1:
return False
return True
def create_Ck(Lksub1, k):
"""
Create Ck, a set which contains all all frequent candidate k-itemsets
by Lk-1's own connection operation.
Args:
Lksub1: Lk-1, a set which contains all frequent candidate (k-1)-itemsets.
k: the item number of a frequent itemset.
Return:
Ck: a set which contains all all frequent candidate k-itemsets.
"""
Ck = set()
len_Lksub1 = len(Lksub1)
list_Lksub1 = list(Lksub1)
for i in range(len_Lksub1):
for j in range(1, len_Lksub1):
l1 = list(list_Lksub1[i])
l2 = list(list_Lksub1[j])
l1.sort()
l2.sort()
if l1[0:k-2] == l2[0:k-2]:
Ck_item = list_Lksub1[i] | list_Lksub1[j]
# pruning
if is_apriori(Ck_item, Lksub1):
Ck.add(Ck_item)
return Ck
def generate_Lk_by_Ck(data_set, Ck, min_support, support_data):
"""
Generate Lk by executing a delete policy from Ck.
Args:
data_set: A list of transactions. Each transaction contains several items.
Ck: A set which contains all all frequent candidate k-itemsets.
min_support: The minimum support.
support_data: A dictionary. The key is frequent itemset and the value is support.
Returns:
Lk: A set which contains all all frequent k-itemsets.
"""
Lk = set()
item_count = {}
for t in data_set:
for item in Ck:
if item.issubset(t):
if item not in item_count:
item_count[item] = 1
else:
item_count[item] += 1
t_num = float(len(data_set))
for item in item_count:
if (item_count[item] / t_num) >= min_support:
Lk.add(item)
support_data[item] = item_count[item] / t_num
return Lk
def generate_L(data_set, k, min_support):
"""
Generate all frequent itemsets.
Args:
data_set: A list of transactions. Each transaction contains several items.
k: Maximum number of items for all frequent itemsets.
min_support: The minimum support.
Returns:
L: The list of Lk.
support_data: A dictionary. The key is frequent itemset and the value is support.
"""
support_data = {}
C1 = create_C1(data_set)
L1 = generate_Lk_by_Ck(data_set, C1, min_support, support_data)
Lksub1 = L1.copy()
L = []
L.append(Lksub1)
for i in range(2, k+1):
Ci = create_Ck(Lksub1, i)
Li = generate_Lk_by_Ck(data_set, Ci, min_support, support_data)
Lksub1 = Li.copy()
L.append(Lksub1)
return L, support_data
def generate_big_rules(L, support_data, min_conf):
"""
Generate big rules from frequent itemsets.
Args:
L: The list of Lk.
support_data: A dictionary. The key is frequent itemset and the value is support.
min_conf: Minimal confidence.
Returns:
big_rule_list: A list which contains all big rules. Each big rule is represented
as a 3-tuple.
"""
big_rule_list = []
sub_set_list = []
for i in range(0, len(L)):
for freq_set in L[i]:
for sub_set in sub_set_list:
if sub_set.issubset(freq_set):
conf = support_data[freq_set] / support_data[freq_set - sub_set]
big_rule = (freq_set - sub_set, sub_set, conf)
if conf >= min_conf and big_rule not in big_rule_list:
# print freq_set-sub_set, " => ", sub_set, "conf: ", conf
big_rule_list.append(big_rule)
sub_set_list.append(freq_set)
return big_rule_list
if __name__ == "__main__":
"""
Test
"""
data_set = load_data_set()
L, support_data = generate_L(data_set, k=3, min_support=0.2)
big_rules_list = generate_big_rules(L, support_data, min_conf=0.7)
for Lk in L:
print "="*50
print "frequent " + str(len(list(Lk)[0])) + "-itemsets\t\tsupport"
print "="*50
for freq_set in Lk:
print freq_set, support_data[freq_set]
print
print "Big Rules"
for item in big_rules_list:
print item[0], "=>", item[1], "conf: ", item[2]
代码运行结果截图如下:

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

数据挖掘之Apriori算法详解和Python实现代码分享
关联规则挖掘(Association rule mining)是数据挖掘中最活跃的研究方法之一,可以用来发现事情之间的联系,最早是为了发现超市交易数据库中不同的商品之间的关系.(啤酒与尿布) 基本概念 1.支持度的定义:support(X-->Y) = |X交Y|/N=集合X与集合Y中的项在一条记录中同时出现的次数/数据记录的个数.例如:support({啤酒}-->{尿布}) = 啤酒和尿布同时出现的次数/数据记录数 = 3/5=60%. 2.自信度的定义:confidence(X-->
-
python中Apriori算法实现讲解
本文主要给大家讲解了Apriori算法的基础知识以及Apriori算法python中的实现过程,以下是所有内容: 1. Apriori算法简介 Apriori算法是挖掘布尔关联规则频繁项集的算法.Apriori算法利用频繁项集性质的先验知识,通过逐层搜索的迭代方法,即将K-项集用于探察(k+1)项集,来穷尽数据集中的所有频繁项集.先找到频繁项集1-项集集合L1, 然后用L1找到频繁2-项集集合L2,接着用L2找L3,知道找不到频繁K-项集,找到每个Lk需要一次数据库扫描.注意:频繁项集的所有非空
-
python使用Apriori算法进行关联性解析
从大规模数据集中寻找物品间的隐含关系被称作关联分析或关联规则学习.过程分为两步:1.提取频繁项集.2.从频繁项集中抽取出关联规则. 频繁项集是指经常出现在一块的物品的集合. 关联规则是暗示两种物品之间可能存在很强的关系. 一个项集的支持度被定义为数据集中包含该项集的记录所占的比例,用来表示项集的频繁程度.支持度定义在项集上. 可信度或置信度是针对一条诸如{尿布}->{葡萄酒}的关联规则来定义的.这条规则的可信度被定义为"支持度({尿布,葡萄酒})/支持度({尿布})". 寻找频繁
-
浅谈Python实现Apriori算法介绍
导读: 随着大数据概念的火热,啤酒与尿布的故事广为人知.我们如何发现买啤酒的人往往也会买尿布这一规律?数据挖掘中的用于挖掘频繁项集和关联规则的Apriori算法可以告诉我们.本文首先对Apriori算法进行简介,而后进一步介绍相关的基本概念,之后详细的介绍Apriori算法的具体策略和步骤,最后给出Python实现代码. 1.Apriori算法简介 Apriori算法是经典的挖掘频繁项集和关联规则的数据挖掘算法.A priori在拉丁语中指"来自以前".当定义问题时,通常会使用先验知识
-
浅谈python常用程序算法
一.冒泡排序: 1.冒泡排序是将无序的数字排列成从小到大的有序组合: 过程:对相邻的两个元素进行比较,对不符合要求的数据进行交换,最后达到数据有序的过程. 规律: 1.冒泡排序的趟数时固定的:n-1 2.冒泡排序比较的次数时固定的:n*(n-1)/2 3.冒泡排序交换的次数时不固定的:但是最大值为:n*(n-1)/2 注意:n = 数据个数,排序过程中需要临时变量存储要交换的数据 eg: l=[688, 888, 711,999,1,4,6] for i in range(len(l)-1):
-
浅谈Python实现贪心算法与活动安排问题
贪心算法 原理:在对问题求解时,总是做出在当前看来是最好的选择.也就是说,不从整体最优上加以考虑,他所做出的仅是在某种意义上的局部最优解.贪心算法不是对所有问题都能得到整体最优解,但对范围相当广泛的许多问题他能产生整体最优解或者是整体最优解的近似解. 特性:贪心算法采用自顶向下,以迭代的方法做出相继的贪心选择,每做一次贪心选择就将所求问题简化为一个规模更小的子问题,通过每一步贪心选择,可得到问题的一个最优解,虽然每一步上都要保证能获得局部最优解,但由此产生的全局解有时不一定是最优的,所以贪婪法不
-
浅谈python多线程和多线程变量共享问题介绍
1.demo 第一个代码是多线程的简单使用,编写了线程如何执行函数和类. import threading import time class ClassName(threading.Thread): """创建类,通过多线程执行""" def run(self): for i in range(5): print(i) time.sleep(1) def sing(): for i in range(1,11): print("唱歌第
-
浅谈python中copy和deepcopy中的区别
在下是个编程爱好者,最近将魔爪伸向了Python编程.....遇到copy和deepcopy感到很困惑,现在针对这两个方法进行区分,一种是浅复制(copy),一种是深度复制(deepcopy). 首先说一下deepcopy,所谓的深度复制,在这里我理解的是完全复制然后变成一个新的对象,复制的对象和被复制的对象没有任何关系,彼此之间无论怎么改变都相互不影响. 然后说一下copy,在这里我分为两类来说,一种是字典数据类型的copy函数,一种是copy包的copy函数. 一.字典数据类型的copy函数
-
浅谈python中的数字类型与处理工具
python中的数字类型工具 python中为更高级的工作提供很多高级数字编程支持和对象,其中数字类型的完整工具包括: 1.整数与浮点型, 2.复数, 3.固定精度十进制数, 4.有理分数, 5.集合, 6.布尔类型 7.无穷的整数精度 8.各种数字内置函数及模块. 基本数字类型 python中提供了两种基本类型:整数(正整数金额负整数)和浮点数(注:带有小数部分的数字),其中python中我们可以使用多种进制的整数.并且整数可以用有无穷精度. 整数的表现形式以十进制数字字符串写法出现,浮点数带
-
浅谈Python对内存的使用(深浅拷贝)
本文主要研究的是Python对内存的使用(深浅拷贝)的相关问题,具体介绍如下. 浅拷贝就是对引用的拷贝(只拷贝父对象) 深拷贝就是对对象的资源的拷贝 >>> a=[1,2,3,'a','b'] >>> b=a >>> b [1, 2, 3, 'a', 'b'] >>> a [1, 2, 3, 'a', 'b'] >>> id(a) 3021737547592 >>> id(b) 3021737547
-
浅谈Python中的私有变量
私有变量表示方法 在变量前加上两个下划线的是私有变量. class Teacher(): def __init__(self,name,level): self.__name=name self.__level=level #获取老师的等级 def get_level(self): return self.__level #获取名字 def get_in_name(self): return self.__name 动态方法无法读取私有变量 即使是动态方法也无法读取私有变量,强行读取会报错. #
-
浅谈Python数学建模之线性规划
目录 一.求解方法.算法和编程方案 1.1.线性规划问题的求解方法 1.2.线性规划的最快算法 1.3.选择适合自己的编程方案 二.PuLP库求解线性规划问题 2.1.线性规划问题的描述 2.2.PuLP 求解线性规划问题的步骤 2.3.Python例程:线性规划问题 三.小结 一.求解方法.算法和编程方案 线性规划 (Linear Programming,LP) 是很多数模培训讲的第一个算法,算法很简单,思想很深刻. 线性规划问题是中学数学的内容,鸡兔同笼就是一个线性规划问题.数学规划的题目在
-
浅谈Python数学建模之固定费用问题
目录 一.固定费用问题案例解析 1.1.固定费用问题(Fixed cost problem) 1.2.案例问题描述 1.3.建模过程分析 1.4.PuLP 求解固定费用问题的编程 1.5.Python 例程:固定费用问题 1.6.Python 例程运行结果 二.PuLP 求解规划问题的快捷方法 2.1.PuLP 求解固定费用问题的编程 2.2.Python 例程:PuLP 快捷方法 2.3.Python 例程运行结果 一.固定费用问题案例解析 1.1.固定费用问题(Fixed cost prob