如何通过雪花算法用Python实现一个简单的发号器
实现一个简单的发号器
根据snowflake算法的原理实现一个简单的发号器,产生不重复、自增的id。
1.snowflake算法的简单描述
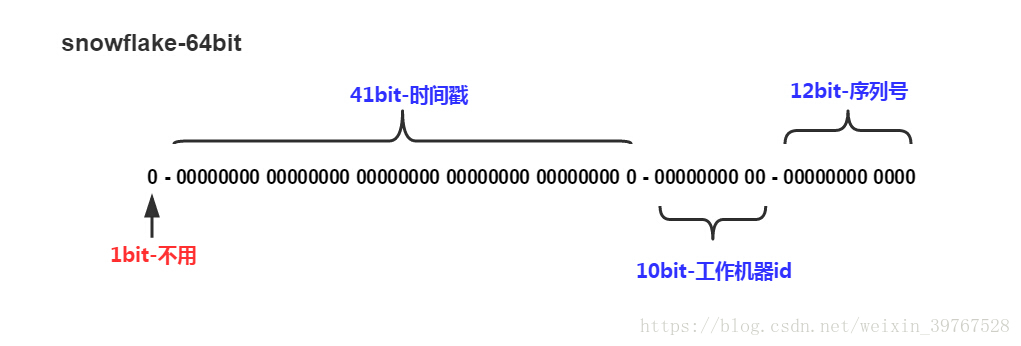
这里的snowflake算法是用二进制的,有64位。其中41位的时间戳表示:当前时间戳减去某个设定的起始时间,10位标识表示:不同的机器、数据库的标识ID等等,序列号为每秒或每毫秒内自增的id。
我做的时候没有用位运算去实现,而是做了一个十进制的,16位的(当时项目要求是16位的)。但是实现发号器的基本策略是一样的,通过时间戳和标识来防止重复,通过序列号实现自增。当然啦,重点不是发号器多少位,而是根据项目的实际情况,利用snowflake算法的原理,实现一个适合自己项目的发号器。
2.Python实现
时间戳:9位,起始时间为2018-01-01 00:00:00 ,时间戳为当前时间减去起始时间。时间戳有9为,可用时间为 999999999/(606024*365)≈31(年)。
标识ID:2位,我用的时候比较简单,只是涉及一个数据库的情况,所以用一张数据表对应一个标识ID,可用100张表。
序列号:5位,我时间戳用的是秒级的,但是5位是10万个序列号,经过测试在一秒内是完全够用的。
所以时间戳、标识ID、序列号的位数也没规定说一定要多少,根据自己项目的实际来即可。
代码如下:
import time
class MySnow:
def __init__(self,dataID):
self.start = int(time.mktime(time.strptime('2018-01-01 00:00:00', "%Y-%m-%d %H:%M:%S")))
self.last = int(time.time())
self.countID = 0
self.dataID = dataID # 数据ID,这个自定义或是映射
def get_id(self):
# 时间差部分
now = int(time.time())
temp = now-self.start
if len(str(temp)) < 9: # 时间差不够9位的在前面补0
length = len(str(temp))
s = "0" * (9-length)
temp = s + str(temp)
if now == self.last:
self.countID += 1 # 同一时间差,序列号自增
else:
self.countID = 0 # 不同时间差,序列号重新置为0
self.last = now
# 标识ID部分
if len(str(self.dataID)) < 2:
length = len(str(self.dataID))
s = "0" * (2-length)
self.dataID = s + str(self.dataID)
# 自增序列号部分
if self.countID == 99999: # 序列号自增5位满了,睡眠一秒钟
time.sleep(1)
countIDdata = str(self.countID)
if len(countIDdata) < 5: # 序列号不够5位的在前面补0
length = len(countIDdata)
s = "0"*(5-length)
countIDdata = s + countIDdata
id = str(temp) + str(self.dataID) + countIDdata
return id
使用方法:
snow = MySnow(dataID="00") print(snow.get_id())
其中dataID即为标识ID,countID为自增序列号。dataID可以一个通过自定义的映射表获得,这个视实际的项目情况而定。
3.关于并发
首先,直接用这个发号器是不能进行并发操作,会产生重复的id。如果真的要进行并发,那么就要权衡一下并发和位数的哪个更重要了!
拿实际例子来说吧,比如我并发的目的是为了节省时间,让程序更快的跑完,这时候为了并发,我把dataID中拿出一位来,标识不同的子进程,这样可以防止产生重复的id。但是实际上这用了位数去换取时间,如果是id位数比较少的情况,比如16位的,dataID比较少,我个人认为这样是不值得的,有些奢侈。这时候便是位数比并发重要啦。
当时如果位数充裕,比如20位的,需要并发就并发啦。
还有一种实现并发的方法,就是给发号器加锁,发号的时候加锁,发完了解锁。这个我没有试过,有兴趣的可以试一下哈哈。但是我有个疑惑啊,就是不断加锁和解锁切换,带来的时间和资源开销会不会很大呢。
相关推荐
-
基于python绘制科赫雪花
什么是科赫曲线 科赫曲线是de Rham曲线的特例.给定线段AB,科赫曲线可以由以下步骤生成: 将线段分成三等份(AC,CD,DB) 以CD为底,向外(内外随意)画一个等边三角形DMC 将线段CD移去 分别对AC,CM,MD,DB重复1~3. 什么是科赫雪花 三段科赫曲线组成的图形 实现的效果 < #KocheDraw1 import turtle def koch(size,n): if n==1: turtle.fd(size) else: for i in [0,60,-120,60]:
-
如何通过雪花算法用Python实现一个简单的发号器
实现一个简单的发号器 根据snowflake算法的原理实现一个简单的发号器,产生不重复.自增的id. 1.snowflake算法的简单描述 这里的snowflake算法是用二进制的,有64位.其中41位的时间戳表示:当前时间戳减去某个设定的起始时间,10位标识表示:不同的机器.数据库的标识ID等等,序列号为每秒或每毫秒内自增的id. 我做的时候没有用位运算去实现,而是做了一个十进制的,16位的(当时项目要求是16位的).但是实现发号器的基本策略是一样的,通过时间戳和标识来防止重复,通过序列号实现
-
Python实现一个简单的验证码程序
老师讲完random函数,自己写的,虽然和老师示例的不那么美观,智能,但是也自己想出来的,所以记录一下,代码就需要自己不断的自己练习,实战,才能提高啊!不然就像我们这些大部分靠自学的人,何时能学会.还有就是,这次听老师的,把自己的代码添加注释,所以这次把很简单的代码都写上了注释,而且很大白话,不管有没有接触过python的,我相信仔细看了,肯定能看懂.如果看完,再自己尝试着默写出来,那就是更好到了,好了进入正题: 自己写的: __Author__ = "Zhang Peng" impo
-
Python实现一个简单的递归下降分析器
问题 你想根据一组语法规则解析文本并执行命令,或者构造一个代表输入的抽象语法树. 如果语法非常简单,你可以不去使用一些框架,而是自己写这个解析器. 解决方案 在这个问题中,我们集中讨论根据特殊语法去解析文本的问题. 为了这样做,你首先要以BNF或者EBNF形式指定一个标准语法. 比如,一个简单数学表达式语法可能像下面这样: expr ::= expr + term | expr - term | term term ::= term * factor | te
-

Python实现一个简单三层神经网络的搭建及测试 代码解析
目录 1.初始化 2.预测 3.训练 4.测试 废话不多说了,直接步入正题,一个完整的神经网络一般由三层构成:输入层,隐藏层(可以有多层)和输出层.本文所构建的神经网络隐藏层只有一层.一个神经网络主要由三部分构成(代码结构上):初始化,训练,和预测.首先我们先来初始化这个神经网络吧! 1.初始化 我们所要初始化的内容包括:神经网络每层上的神经元个数(这个是根据实际问题输入输出而得到的,我们将它设置为一个可自定义量). 不同层间数据互相传送的权重值. 激活函数(模拟自然界的神经元,刺激信号需要达到
-
Python实现一个简单的MySQL类
本文实例讲述了Python实现一个简单的MySQL类.分享给大家供大家参考. 具体实现方法如下: 复制代码 代码如下: #!/usr/bin/env python # -*- coding:utf-8 -*- # Created on 2011-2-19 # @author: xiaoxiao import MySQLdb import sys __all__ = ['MySQL'] class MySQL(object): ''' MySQL ''' conn
-
python实现一个简单的并查集的示例代码
并查集是一种树型的数据结构,用于处理一些不相交集合的合并及查询问题.常常在使用中以森林来表示. 并查集有三种基本操作,获得根节点,判断两节点是否连通,以及将两不连通的节点相连(相当于将两节点各自的集合合并) 用UnionFind类来表示一个并查集,在构造函数中,初始化一个数组parent,parent[i]表示的含义为,索引为i的节点,它的直接父节点为parent[i].初始化时各个节点都不相连,因此初始化parent[i]=i,让自己成为自己的父节点,从而实现各节点不互连. def __ini
-
如何利用Python开发一个简单的猜数字游戏
前言 本文介绍如何使用Python制作一个简单的猜数字游戏. 游戏规则 玩家将猜测一个数字.如果猜测是正确的,玩家赢.如果不正确,程序会提示玩家所猜的数字与实际数字相比是"大(high)"还是"小(low)",如此往复直到玩家猜对数字. 准备好Python3 首先,需要在计算机上安装Python.可以从Python官网下载并安装.本教程需要使用最新版的Python 3(版本3.x.x). 确保选中将Python添加到PATH变量的框.如果不这样做,将很难运行该程序.
-
python实现一个简单的ping工具方法
继上一篇计算checksum校验和,本章通过socket套接字,struct字节打包成二进制,select返回套接字的文件描述符的结合,实现一个简单的ping工具. #!/usr/bin/python3.6.4 #!coding:utf-8 __author__ = 'Rosefinch' __date__ = '2018/5/31 22:27' import time import struct import socket import select import sys def chesks
-
Python实现一个简单的毕业生信息管理系统的示例代码
写在前面: 从昨晚的梦里回忆起数据管理的作业: 实现一个自己的选题---- 毕业生信息管理系统,实现学生个人信息基本的增删改查, 我想了想前段时间刚学习的列表,这个简单啊 ,设计一个学生信息列表,然后列表里面再存每个学生详细信息的列表,然后来实现一个基本的增删查改,这个不难啊!直接开始撸代码! 上代码! def Menu():##菜单主界面 print('*'*22) print("* 查看毕业生列表输入: 1 *") print("* 添加毕业生信息输入: 2 *"
-
python实现一个简单RPC框架的示例
本文需要一点Python socket基础. 回顾RPC 客户端(Client):服务调用方. 客户端存根(Client Stub):存放服务端地址信息,将客户端的请求参数数据信息打包成网络消息,再通过网络传输发送给服务端. 服务端存根(Server Stub):接收客户端发送过来的请求消息并进行解包,然后再调用本地服务进行处理. 服务端(Server):服务的真正提供者. Network Service:底层传输,可以是 TCP 或 HTTP. 实现jsonrpc 在实现前,简单理一下整体思路