基于一致性hash算法 C++语言的实现详解
一致性hash算法实现有两个关键问题需要解决,一个是用于结点存储和查找的数据结构的选择,另一个是结点hash算法的选择。
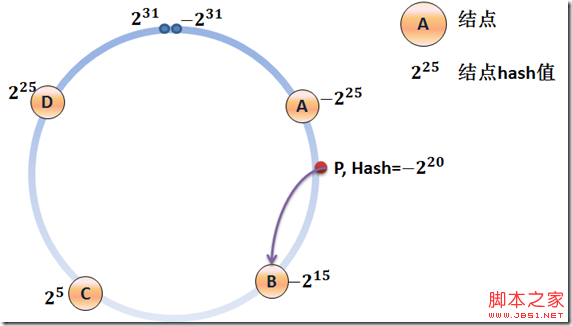
首先来谈一下一致性hash算法中用于存储结点的数据结构。通过了解一致性hash的原理,我们知道结点可以想象为是存储在一个环形的数据结构上(如下图),结点A、B、C、D按hash值在环形分布上是有序的,也就是说结点可以按hash值存储在一个有序的队列里。如下图所示,当一个hash值为-2^20的请求点P查找路由结点时,一致性hash算法会按hash值的顺时针方向路由到第一个结点上(B),也就是相当于要在存储结点的有序结构中,按查询的key值找到大于key值中的最小的那个结点。因此,我们应该选择一种数据结构,它应该高效地支持结点频繁地增删,也必须具有理想的查询效率。那么,红黑树可以满足这些要求。红黑树是一颗近似平衡的一颗二叉查找树,因为操作比如插入、删除和查找某个值的最坏情况时间都要求与树的高度成比例,这个在高度上的理论上限允许红黑树在最坏情况下都是高效的,而不同于普通的二叉查找树。 因此,我们选择使用红黑树作为结点的存储结构,除了需要实现红黑树基本的插入、删除、查找的基本功能,我们还应该增加另一个查询lookup函数,用于查找大于key中最小的结点。
接下来,我们来说hash算法的选择。一致性hash算法最初提出来,就是为了解决负载均衡的问题。每个实体结点会包含很多虚拟结点,虚拟结点是平衡负载的关键。我们希望虚拟结点可以均衡的散列在整个“环”上,这样不仅可以负载到不同hash值的路由请求,还可以当某个结点down掉,原来路由到down掉结点的请求也可以较均衡的路由到其他结点而不会对某个结点造成大量的负载请求。这里,我们选择使用MD5算法。通过MD5算法,可以将一个标示串(用于标示虚拟结点)转化得到一个16字节的字符数组,再对该数组进行处理,得到一个整形的hash值。由于MD5具有高度的离散性,所以生成的hash值也会具有很大的离散性,会均衡的散列到“环”上。
笔者用C++语言对一致性hash算法进行了实现,下面我将会描述下一些关键细节。
1、首先定义实体结点类、虚拟结点类。一个实体结点对应多个虚拟结点。
/*实体结点*/
class CNode_s
{
public:
/*构造函数*/
CNode_s();
CNode_s(char * pIden , int pVNodeCount , void * pData);
/*获取结点标示*/
const char * getIden();
/*获取实体结点的虚拟结点数量*/
int getVNodeCount();
/*设置实体结点数据值*/
void setData(void * data);
/*获取实体结点数据值*/
void * getData();
private:
void setCNode_s(char * pIden, int pVNodeCount , void * pData);
char iden[100];/*结点标示串*/
int vNodeCount; /*虚拟结点数目*/
void * data;/*数据结点*/
};
虚拟结点 CVirtualNode_s:虚拟结点有一指针指向实体结点
代码如下:
/*虚拟结点*/
class CVirtualNode_s
{
public:
/*构造函数*/
CVirtualNode_s();
CVirtualNode_s(CNode_s * pNode);
/*设置虚拟结点所指向的实体结点*/
void setNode_s(CNode_s * pNode);
/*获取虚拟结点所指向的实体结点*/
CNode_s * getNode_s();
/*设置虚拟结点hash值*/
void setHash(long pHash);
/*获取虚拟结点hash值*/
long getHash();
private:
long hash; /*hash值*/
CNode_s * node; /*虚拟结点所指向的实体结点*/
};
2、hash算法具有可选择性,定义一个hash算法接口,方便以后进行其他算法的扩展。
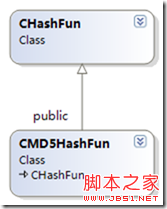
这里创建MD5hash类,并继承该接口,通过MD5算法求hash值。
类图:
/*定义Hash函数类接口,用于计算结点的hash值*/
class CHashFun
{
public:
virtual long getHashVal(const char *) = 0;
};
CMD5HashFun 类继承CHashFun接口,实现获取hash值的getHashVal函数:
代码如下:
/*用MD5算法计算结点的hash值,继承CHashFun父类*/
class CMD5HashFun : public CHashFun
{
public:
virtual long getHashVal (const char * );
};
long CMD5HashFun::getHashVal(const char * instr)
{
int i;
long hash = 0;
unsigned char digest[16];
/*调用MD5相关函数,生成instr的MD5码,存入digest*/
md5_state_t md5state;
md5_init(&md5state);
md5_append(&md5state, (const unsigned char *)instr, strlen(instr));
md5_finish(&md5state, digest);
/* 每四个字节构成一个32位整数,
将四个32位整数相加得到instr的hash值(可能溢出) */
for(i = 0; i < 4; i++)
{
hash += ((long)(digest[i*4 + 3]&0xFF) << 24)
| ((long)(digest[i*4 + 2]&0xFF) << 16)
| ((long)(digest[i*4 + 1]&0xFF) << 8)
| ((long)(digest[i*4 + 0]&0xFF));
}
return hash;
}
3、扩展红黑树结构中的查找函数,用于查找红黑树中大于key值中最小的结点。
代码如下:
util_rbtree_node_t* util_rbtree_lookup(util_rbtree_t *rbtree, long key)
{
if((rbtree != NULL) && !util_rbtree_isempty(rbtree))
{
util_rbtree_node_t *node = NULL;
util_rbtree_node_t *temp = rbtree->root;
util_rbtree_node_t *null = _NULL(rbtree);
while(temp != null)
{
if(key <= temp->key)
{
node = temp; /* update node */
temp = temp->left;
}
else if(key > temp->key)
{
temp = temp->right;
}
}
/* if node==NULL return the minimum node */
return ((node != NULL) ? node : util_rbtree_min(rbtree));
}
return NULL;
}
4、创建一致性hash类。使其具有插入、删除、查找实体结点的功能。
class CConHash
{
public:
/*构造函数*/
CConHash(CHashFun * pFunc);
/*设置hash函数*/
void setFunc(CHashFun * pFunc);
/*增加实体结点 , 0代表成功 , -1代表失败*/
int addNode_s(CNode_s * pNode);
/*删除实体结点 , 0代表成功 , -1代表失败*/
int delNode_s(CNode_s * pNode);
/*查找实体结点*/
CNode_s * lookupNode_s(const char * object);
/*获取一致性hash结构的所有虚拟结点数量*/
int getVNodes();
private:
/*Hash函数*/
CHashFun * func;
/*虚拟结点总个数*/
int vNodes;
/*存储虚拟结点的红黑树*/
util_rbtree_t * vnode_tree;
};
/*辅助函数,虚拟结点转化为红黑树结点*/
util_rbtree_node_t * vNode2RBNode(CVirtualNode_s * vnode);
CConHash::CConHash(CHashFun * pFunc)
{
/*设置hash函数*/
assert(pFunc!=NULL);
this->func = pFunc;
this->vNodes = 0;
/*初始化红黑树*/
vnode_tree = new util_rbtree_s();
util_rbtree_init(vnode_tree);
}
int CConHash::addNode_s(CNode_s * pNode)
{
if(pNode==NULL) return -1;
int vCount = pNode->getVNodeCount();
if(vCount<=0) return -1;
CVirtualNode_s * virtualNode ;
util_rbtree_node_t * rbNode;
char str [100];
char num[10];
strcpy(str,pNode->getIden());
long hash = 0;
/*生成虚拟结点并插入到红黑树中*/
for(int i=0;i<vCount;i++)
{
virtualNode = new CVirtualNode_s(pNode);
/*采用str+“i”的方法产生不同的iden串,用于后面的hash值计算*/
itoa(i,num,10);
strcat(str,num);
hash = func->getHashVal(str);
virtualNode->setHash(hash);
if(!util_rbtree_search(vnode_tree,hash))
{
/*生成红黑树结点*/
rbNode = vNode2RBNode(virtualNode);
if(rbNode!=NULL)
{
/*将该结点插入到红黑树中*/
util_rbtree_insert(vnode_tree,rbNode);
this->vNodes++;
}
}
}
return 0;
}
int CConHash::delNode_s(CNode_s * pNode)
{
if(pNode==NULL) return -1;
util_rbtree_node_t * rbNode;
char str [100];
char num [10];
strcpy(str,pNode->getIden());
int vCount = pNode->getVNodeCount();
long hash = 0;
CVirtualNode_s * node = NULL;
/*将该实体结点产生的所有虚拟结点进行删除*/
for(int i=0;i<vCount;i++)
{
itoa(i,num,10);
strcat(str,num);/*采用该方法产生不同的iden串*/
hash = func->getHashVal(str);
rbNode = util_rbtree_search(vnode_tree,hash);
if(rbNode!=NULL)
{
node = (CVirtualNode_s *) rbNode->data;
if(node->getNode_s()==pNode && node->getHash()==hash)
{
this->vNodes--;
/*将该结点从红黑树中删除*/
util_rbtree_delete(vnode_tree,rbNode);
delete rbNode;
delete node;
}
}
}
return 0;
}
CNode_s * CConHash::lookupNode_s(const char * object)
{
if(object==NULL||this->vNodes==0) return NULL;
util_rbtree_node_t * rbNode;
int key = this->func->getHashVal(object);
/*在红黑树中查找key值比key大的最小的结点*/
rbNode = util_rbtree_lookup(vnode_tree,key);
if(rbNode!=NULL)
{
return ((CVirtualNode_s *) rbNode->data)->getNode_s();
}
return NULL;
}
int CConHash::getVNodes()
{
return this->vNodes;
}
util_rbtree_node_t * vNode2RBNode(CVirtualNode_s * vnode)
{
if(vnode==NULL) return NULL;
util_rbtree_node_t *rbNode = new util_rbtree_node_t();
rbNode->key = vnode->getHash();
rbNode->data = vnode;
return rbNode;
}
5、创建一个客户端类,对一致性hash算法进行测试。
写了一个getIP的函数,模拟随机产生的IP字符串。
代码如下:
#include<iostream>
#include"CNode_s.h"
#include"CVirtualNode_s.h"
#include"CHashFun.h"
#include"CMD5HashFun.h"
#include"CConHash.h"
#include<string.h>
#include<time.h>
using namespace std;
void getIP(char * IP)
{
int a=0, b=0 , c=0 , d=0;
a = rand()%256;
b = rand()%256;
c = rand()%256;
d = rand()%256;
char aa[4],bb[4],cc[4],dd[4];
itoa(a, aa, 10);
itoa(b, bb, 10);
itoa(c, cc, 10);
itoa(d, dd, 10);
strcpy(IP,aa);
strcat(IP,".");
strcat(IP,bb);
strcat(IP,".");
strcat(IP,cc);
strcat(IP,".");
strcat(IP,dd);
}
int main()
{
srand(time(0));
freopen("out.txt","r",stdin);
/*定义hash函数*/
CHashFun * func = new CMD5HashFun();
/*创建一致性hash对象*/
CConHash * conhash = new CConHash(func);
/*定义CNode*/
CNode_s * node1 = new CNode_s("machineA",50,"10.3.0.201");
CNode_s * node2 = new CNode_s("machineB",80,"10.3.0.202");
CNode_s * node3 = new CNode_s("machineC",20,"10.3.0.203");
CNode_s * node4 = new CNode_s("machineD",100,"10.3.0.204");
conhash->addNode_s(node1);
conhash->addNode_s(node2);
conhash->addNode_s(node3);
conhash->addNode_s(node4);
/*动态更改结点数据值*/
// node1->setData("99999999");
int ans1 ,ans2 ,ans3 ,ans4;
ans1=ans2=ans3=ans4=0;
char object[100];
CNode_s * node ;
/*动态删除结点*/
//conhash->delNode_s(node2);
for(int i =0;i<30;i++)
{
// getIP(object);
// cout<<object<<endl;
cin>>object;
node = conhash->lookupNode_s(object);
if(node!=NULL)
{
cout<<object<<"----->\t"<<node->getIden()<<" \t "<<(char *)node->getData()<<endl;
if(strcmp(node->getIden(),"machineA")==0) ans1++;
if(strcmp(node->getIden(),"machineB")==0) ans2++;
if(strcmp(node->getIden(),"machineC")==0) ans3++;
if(strcmp(node->getIden(),"machineD")==0) ans4++;
}
}
cout<<"Total test cases : "<<ans1+ans2+ans3+ans4<<endl;
cout<<"Map to MachineA : "<<ans1<<endl;
cout<<"Map to MachineB : "<<ans2<<endl;
cout<<"Map to MachineC : "<<ans3<<endl;
cout<<"Map to MachineD : "<<ans4<<endl;
fclose(stdin);
return 0;
}
6、删除结点对hash路由的影响测试

测试结果截图:

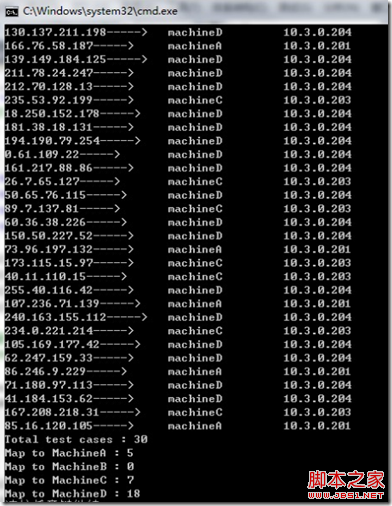
分析:上面两幅图,左边为原始四个实体结点的路由情况,后面为删除结点2(Node2)之后的路由情况。不难发现,MachineB down之后,原先的路由请求,较均衡地负载到了其他机器结点,而且对原先路由到其他结点的请求没有影响。比如139.149.184.125这个请求仍会路由到MachineD,并不会因为结点的减少而造成影响。但是,如果是增加实体结点,可能会造成增加前后路由情况不一致的现象,因为路由区间的更加狭小,但是不会有特别大的影响。 另一方面,可以发现实体结点的虚拟结点个数比例分配情况很大程度影响了结点的负载路由情况,比例大致与虚拟结点个数相一致。
总结:
本文首先通过介绍实现一致性hash算法的关键算法和数据结构的选择分析,选择了红黑树作为虚拟结点的存储结构,以及MD5算法作为Hash函数用于计算结点的hash值。并使用C++语言,对一致性hash算法进行了实现,实现了一致性hash实体结点的增加、删除、查找等基本功能,并进行了测试分析。由于笔者水平有限,存在很多有待改进的地方,因此本文仅供大家参考、讨论学习。
相关推荐
-
c++实现MD5算法实现代码
测试结果和百度百科测试例子一致. 实现过程中需要注意事项:最后把四个变量A B C D 链接成结果时 ,注意变量高低位的先后顺序,具体参考 LinkResult()方法. md5.h #ifndef _MD5_H_ #define _MD5_H_ #include <iostream> #include <string> using namespace std; class MD5 { public: typedef unsigned char uchar8; //make sur
-

基于C++的农夫过河问题算法设计与实现方法
本文实例讲述了基于C++的农夫过河问题算法设计与实现方法.分享给大家供大家参考,具体如下: 问题描述: 一个农夫带着-只狼.一只羊和-棵白菜,身处河的南岸.他要把这些东西全部运到北岸.他面前只有一条小船,船只能容下他和-件物品,另外只有农夫才能撑船.如果农夫在场,则狼不能吃羊,羊不能吃白菜,否则狼会吃羊,羊会吃白菜,所以农夫不能留下羊和白菜自己离开,也不能留下狼和羊自己离开,而狼不吃白菜.请求出农夫将所有的东西运过河的方案. 实现上述求解的搜索过程可以采用两种不同的策略:一种广度优先搜索,另一种
-
C++实现简单遗传算法
本文实例讲述了C++实现简单遗传算法.分享给大家供大家参考.具体实现方法如下: //遗传算法 GA #include<iostream> #include <cstdlib> #include<bitset> using namespace std; const int L=5; //定义编码的长度 int f(int x) //定义测设函数f(x) { int result; result=x*x*x-60*x*x+900*x+100; return result;
-
C++三色球问题描述与算法分析
本文实例讲述了C++三色球问题.分享给大家供大家参考,具体如下: /* * 作 者:刘同宾 * 完成日期:2012 年 11 月 15 日 * 版 本 号:v1.0 * * 输入描述: * 问题描述:三色球问题:若一个口袋中放有12个球,其中有3个红的.3个白的和6个黒的,问从中任取8个共有多少种不同的颜色搭配? * 提示: 设任取的红球个数为i,白球个数为j,则黒球个数为8-i-j,根据题意红球和白球个数的取值范围是0~3, * 在红球和白球个数确定的条件下,黒球个数取值应为8-i-j<=6.
-
C++实现DES加密算法实例解析
本文所述实例是一个实现DES加密算法的程序代码,在C++中,DES加密是比较常用的加密算法了,且应用非常广泛.本CPP类文件可满足你的DES加密需要,代码中附带了丰富的注释,相信对于大家理解DES可以起到很大的帮助. 具体实现代码如下: #include "memory.h" #include "stdio.h" enum {encrypt,decrypt};//ENCRYPT:加密,DECRYPT:解密 void des_run(char out[8],char
-
采用C++实现区间图着色问题(贪心算法)实例详解
本文所述算法即假设要用很多个教室对一组活动进行调度.我们希望使用尽可能少的教室来调度所有活动.采用C++的贪心算法,来确定哪一个活动使用哪一间教室. 对于这个问题也常被称为区间图着色问题,即相容的活动着同色,不相容的着不同颜色,使得所用颜色数最少. 具体实现代码如下: //贪心算法 #include "stdafx.h" #include<iostream> #define N 100 using namespace std; struct Activity { int n
-
海量数据处理系列之:用C++实现Bitmap算法
bitmap是一个十分有用的结构.所谓的Bit-map就是用一个bit位来标记某个元素对应的Value, 而Key即是该元素.由于采用了Bit为单位来存储数据,因此在存储空间方面,可以大大节省. 适用范围:可进行数据的快速查找,判重,删除,一般来说数据范围是int的10倍以下基本原理及要点:使用bit数组来表示某些元素是否存在,比如8位电话号码扩展:bloom filter可以看做是对bit-map的扩展问题实例:1)已知某个文件内包含一些电话号码,每个号码为8位数字,统计不同号码的个数.8位最
-
C++实现矩阵原地转置算法
本文实例描述了C++实现矩阵原地转置算法,是一个非常经典的算法,相信对于学习C++算法的朋友有很大的帮助.具体如下: 一.问题描述 微软面试题:将一个MxN的矩阵存储在一个一维数组中,编程实现矩阵的转置. 要求:空间复杂度为O(1) 二.思路分析 下面以一个4x2的矩阵A={1,2,3,4,5,6,7,8}进行分析,转置过程如下图: 图中右下角的红色数字表示在一维数组中的下标.矩阵的转置其实就是数组中元素的移动,具体的移动过程如下图: 我们发现,这些移动的元素的下标是一个个环,下标1的元素移动到
-
C++归并排序算法实例
归并排序 归并排序算法是采用分治法的一个非常典型的应用.归并排序的思想是将一个数组中的数都分成单个的:对于单独的一个数,它肯定是有序的,然后,我们将这些有序的单个数在合并起来,组成一个有序的数列.这就是归并排序的思想.它的时间复杂度为O(N*logN). 代码实现 复制代码 代码如下: #include <iostream> using namespace std; //将有二个有序数列a[first...mid]和a[mid...last]合并. void mergearray(int
-
C++堆排序算法的实现方法
本文实例讲述了C++实现堆排序算法的方法,相信对于大家学习数据结构与算法会起到一定的帮助作用.具体内容如下: 首先,由于堆排序算法说起来比较长,所以在这里单独讲一下.堆排序是一种树形选择排序方法,它的特点是:在排序过程中,将L[n]看成是一棵完全二叉树的顺序存储结构,利用完全二叉树中双亲节点和孩子节点之间的内在关系,在当前无序区中选择关键字最大(或最小)的元素. 一.堆的定义 堆的定义如下:n个关键字序列L[n]成为堆,当且仅当该序列满足: ①L(i) <= L(2i)且L(i) <= L(2
-
C++实现迷宫算法实例解析
本文以实例形式描述了C++实现迷宫算法.本例中的迷宫是一个矩形区域,它有一个入口和一个出口.在迷宫的内部包含不能穿越的墙或障碍.障碍物沿着行和列放置,它们与迷宫的矩形边界平行.迷宫的入口在左上角,出口在右下角 本实例迷宫算法的功能主要有: 1.自动生成10*10迷宫图 2.判断是否有迷宫出口,并且画出路线图 具体实现代码如下: # include <iostream> # include <list> # include <sys/timeb.h> # include