java中编码问题的处理方案
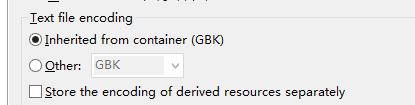
首先我使用的开发环境是Eclipse.创建一个Java Project默认的编码则为GBK,如图:
下面便是具体代码:
import java.io.UnsupportedEncodingException;
public class Demo1 {
public static void main(String[] args) throws UnsupportedEncodingException {
String s = "我爱ABC";
byte[] bytes1 = s.getBytes("gbk");//不写编码,则使用平台的默认字符集将此 String 编码为 byte序列,并返回byte[].
//s.getBytes(Charset charset) 使用给定的charset将此String编码到byte序列;
//返回的是一个byte[]字节数组
for(byte b: bytes1){
System.out.print(Integer.toHexString(b&0xff)+" ");
//Integer.toHexString(int i)以十六进制(基数 16)无符号整数形式返回一个整数参数的字符串表示形式
}
//gbk编码中文占有两个字节,英文占有一个字节
System.out.println();
byte[] bytes2 = s.getBytes("utf-8");
for(byte b: bytes2){
System.out.print(Integer.toHexString(b&0xff)+" ");
}
//utf-8编码 中文占有三个字节,英文占有一个字节
System.out.println();
//java是双字节编码 --->utf-16be >> 中文和英文都占有两个字节
byte[] bytes3 = s.getBytes("utf-16be");
for(byte b: bytes3){
System.out.print(Integer.toHexString(b&0xff)+" ");
}
/*当你的字节序列是某种编码时,这个时候想把字节序列变成
*字符串,也需要用这种编码方式,否则会出现乱码
* */
System.out.println();
String str1 = new String(bytes3);//用项目默认的编码即(GBK编码) ----->> bytes3在上面定义成“utf-16be”的编码了,所以会出现乱码
System.out.println(str1);
System.out.println();
String str2 = new String(bytes3,"utf-16be");
System.out.println(str2);
/*
* 文本文件就是字节序列
* 可以是任意编码的字节序列
* 如果我们在中文机器上直接创建文本文件,那么该文本文件只认识ansi编码
*
*/
}
}
打印的结果:
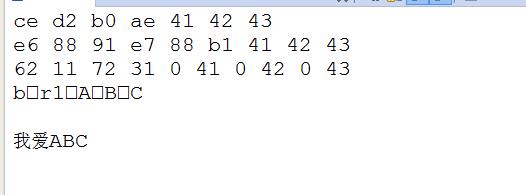
总的来说,编码必须对应,不然会出现乱码。
相关推荐
-
Java反转字符串和相关字符编码的问题解决
复制代码 代码如下: public String reverse(char[] value){ for (int i = (value.length - 1) >> 1; i >= 0; i--){ char temp = value[i]; value[i] = value[value.length - 1 - i]; value[value.length - 1 - i] = temp; }
-
JAVA及相关字符集编码问题研究分享
下面本文将针对以上几点问题进行描述讨论,我们就以"中文"两个字为例来说明,查找相关资料可知"中文"的GB2312编码是"d6d0 cec4",为Unicode编码为"4e2d 6587",UTF编码就是"e4b8ad e69687".(注意,"中文"这两个字没有iso8859-1编码,但可以用iso8859-1编码来"表示"). 一.编码基本知识: 最早的编码是iso
-

深入解析Java中的编码转换以及编码和解码操作
一.Java编码转换过程 我们总是用一个java类文件和用户进行最直接的交互(输入.输出),这些交互内容包含的文字可能会包含中文.无论这些java类是与数据库交互,还是与前端页面交互,他们的生命周期总是这样的: (1).程序员在操作系统上通过编辑器编写程序代码并且以.java的格式保存操作系统中,这些文件我们称之为源文件. (2).通过JDK中的javac.exe编译这些源文件形成.class类. (3).直接运行这些类或者部署在WEB容器中运行,得到输出结果. 这些过程是从宏观上面来
-
编码实现从无序链表中移除重复项(C和JAVA实例)
如果不能使用临时缓存,你怎么编码实现? 复制代码 代码如下: 方法一:不使用额外的存储空间,直接在原始链表上进行操作.首先用一个指针指向链表头节点开始,然后遍历其后面的节点,将与该指针所指节点数据相同的节点删除.然后将该指针后移一位,继续上述操作.直到该指针移到链表. void delete_duplicate1(node* head){ node*pPos=head->next; node*p,*q; while(pPos!=NULL){//用pPos指针来指示当前移动到什么
-
Java IO文件编码转换实现代码
对IO操作真心不是很懂...对编码.乱码也是一知半解...今天遇到了一个需求,要求将一个文件进行编码转换,并且返回编码后的字符串,如原本的GBK编码,转换为UTF-8 其中这个BytesEncodingDetect 类就不贴了.主要用了里面的获取文件编码格式. 刚开始试了直接在源文件修改编码方式,采用URLEncoder和URLDecoder进行转换,却迟迟不行.出现了中文奇数最后一个字乱码 百度找了解决方法,都未果,只好采用我的思路是:先读取源文件的内容,存放到StringBuffer里面,然
-
java实现哈弗曼编码与反编码实例分享(哈弗曼算法)
复制代码 代码如下: //哈弗曼编码的实现类public class HffmanCoding { private int charsAndWeight[][];// [][0]是 字符,[][1]存放的是字符的权值(次数) private int hfmcoding[][];// 存放哈弗曼树 private int i = 0;// 循环变量 private String hcs[]; public HffmanCoding(int[][] chars) {
-
解析关于java,php以及html的所有文件编码与乱码的处理方法汇总
php文件中在乱码(如a.php文件在浏览器乱码):header("Content-Type:text/html;charset=utf-8")是设置网页的.mysql_query("set names utf-8")设置数据库的. java中的struts:中文乱码问题一般是指当请求参数有中文时,无法在Action中得到正确的中文.Struts2中有2种办法可以解决这个问题:设置JSP页面的pageEncoding="utf-8",就不会出现中
-
基于Java字符编码的使用详解
1,什么是字符编码? 字符(Character)是文字与符号的总称,包括文字.图形符号.数学符号等.一组抽象字符的集合就是字符集(Charset).字符集的出现是为了信息进行传播储存提供方便.目前常用到字符集有:ASCII,ISO 8859-1,Unicode,GB2312 2,各种编码集有哪些特点? ASCII: ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统. 包含内容:
-
Java在web页面上的编码解码处理及中文URL乱码解决
编码&解码 通过下图我们可以了解在javaWeb中有哪些地方有转码: 用户想服务器发送一个HTTP请求,需要编码的地方有url.cookie.parameter,经过编码后服务器接受HTTP请求,解析HTTP请求,然后对url.cookie.parameter进行解码.在服务器进行业务逻辑处理过程中可能需要读取数据库.本地文件或者网络中的其他文件等等,这些过程都需要进行编码解码.当处理完成后,服务器将数据进行编码后发送给客户端,浏览器经过解码后显示给用户.在这个整个过程中涉及的编码解码的地方较
-
简洁实用的Java Base64编码加密异常处理类代码
本文所述为Java Base64加密.解密编码异常处理类,代码虽然很简短,但是可以有效避免在采用Base64加解密时候执行出错的问题,这里使用了com.gootrip.util包,并引入了java.io的所有方法. 具体功能代码如下: package com.gootrip.util; import java.io.*; public class Base64DecodingException extends IOException { private char c; public Base64
-
java自动根据文件内容的编码来读取避免乱码
通过cpdetector这个开源的jar包可以自动判断当前文件的内容编码,从而在读取的时候选择正确的编码读取,避免乱码问题. 测试结果,提供截图: GBK文件内容