使用Python爬了4400条淘宝商品数据,竟发现了这些“潜规则”
本文记录了笔者用 Python 爬取淘宝某商品的全过程,并对商品数据进行了挖掘与分析,最终得出结论。
项目内容
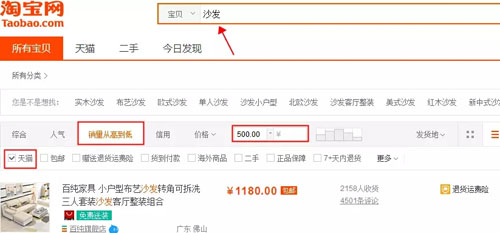
本案例选择>> 商品类目:沙发;
数量:共100页 4400个商品;
筛选条件:天猫、销量从高到低、价格500元以上。
项目目的
1. 对商品标题进行文本分析 词云可视化
2. 不同关键词word对应的sales的统计分析
3. 商品的价格分布情况分析
4. 商品的销量分布情况分析
5. 不同价格区间的商品的平均销量分布
6. 商品价格对销量的影响分析
7. 商品价格对销售额的影响分析
8. 不同省份或城市的商品数量分布
9.不同省份的商品平均销量分布
注:本项目仅以以上几项分析为例。
项目步骤
1. 数据采集:Python爬取淘宝网商品数据
2. 对数据进行清洗和处理
3. 文本分析:jieba分词、wordcloud可视化
4. 数据柱形图可视化 barh
5. 数据直方图可视化 hist
6. 数据散点图可视化 scatter
7. 数据回归分析可视化 regplot
工具&模块:
工具:本案例代码编辑工具 Anaconda的Spyder
模块:requests、retrying、missingno、jieba、matplotlib、wordcloud、imread、seaborn 等。
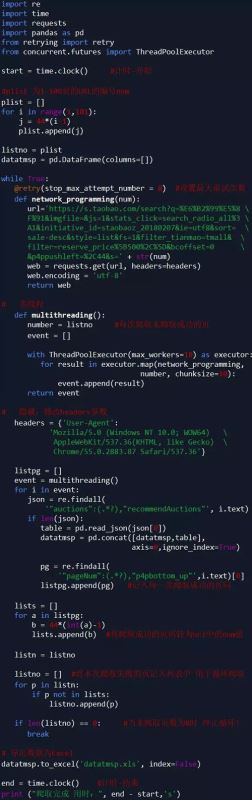
一、爬取数据
因淘宝网是反爬虫的,虽然使用多线程、修改headers参数,但仍然不能保证每次100%爬取,所以 我增加了循环爬取,每次循环爬取未爬取成功的页 直至所有页爬取成功停止。
说明:淘宝商品页为JSON格式 这里使用正则表达式进行解析;
代码如下:
二、数据清洗、处理:
(此步骤也可以在Excel中完成 再读入数据)
代码如下:
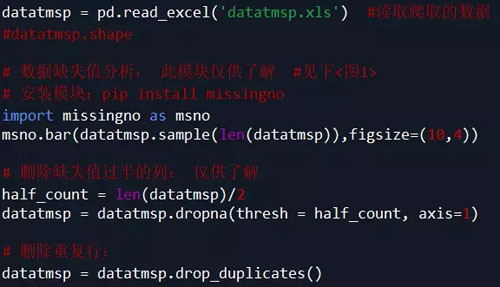
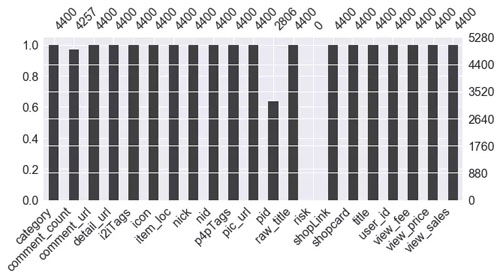
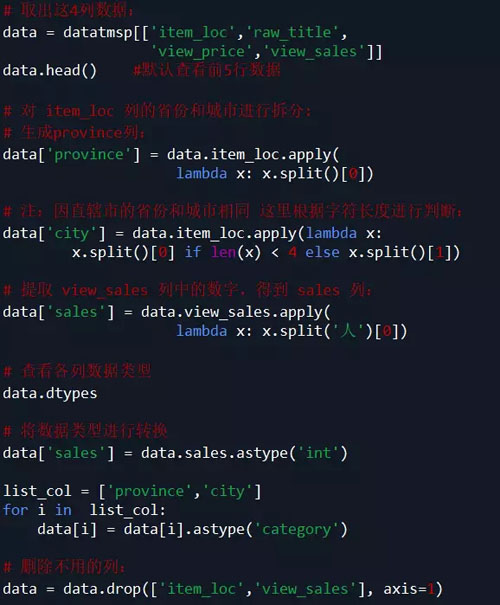
说明:根据需求,本案例中只取了 item_loc, raw_title, view_price, view_sales 这4列数据,主要对 标题、区域、价格、销量 进行分析。
代码如下:
三、数据挖掘与分析:
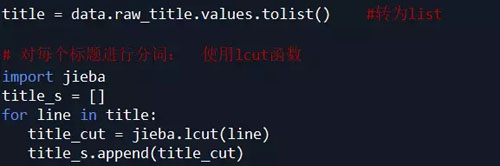
【1】. 对 raw_title 列标题进行文本分析:
使用结巴分词器,安装模块pip install jieba
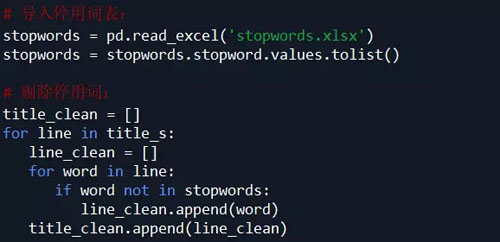
对 title_s(list of list 格式)中的每个list的元素(str)进行过滤 剔除不需要的词语,即 把停用词表stopwords中有的词语都剔除掉:
因为下面要统计每个词语的个数,所以 为了准确性 这里对过滤后的数据 title_clean 中的每个list的元素进行去重,即 每个标题被分割后的词语唯一。
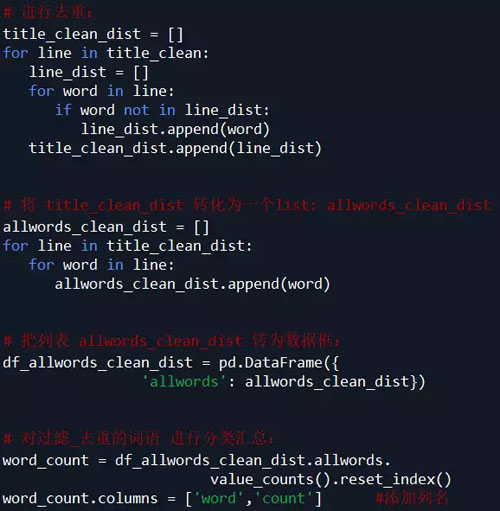
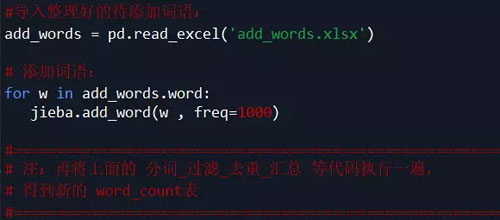
观察 word_count 表中的词语,发现jieba默认的词典 无法满足需求:
有的词语(如 可拆洗、不可拆洗等)却被cut,这里根据需求对词典加入新词(也可以直接在词典dict.txt里面增删,然后载入修改过的dict.txt)
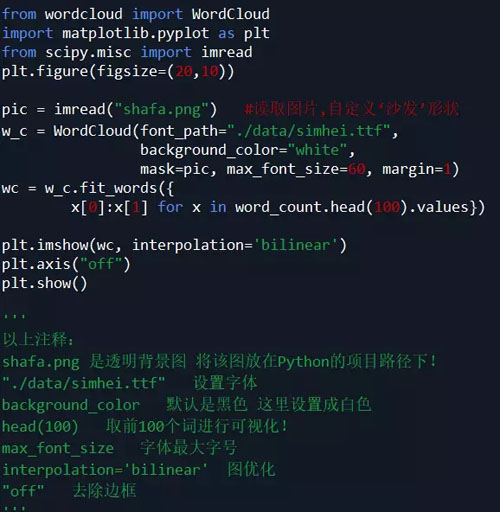
词云可视化:
安装模块 wordcloud:
方法1: pip install wordcloud
方法2: 下载Packages安装:pip install 软件包名称
软件包下载地址:https://www.lfd.uci.edu/~gohlke/pythonlibs/#wordcloud
注意:要把下载的软件包放在Python安装路径下。
代码如下:

分析结论:
1. 组合、整装商品占比很高;
2. 从沙发材质看:布艺沙发占比很高,比皮艺沙发多;
3. 从沙发风格看:简约风格最多,北欧风次之,其他风格排名依次是美式、中式、日式、法式 等;
4. 从户型看:小户型占比最高、大小户型次之,大户型最少。
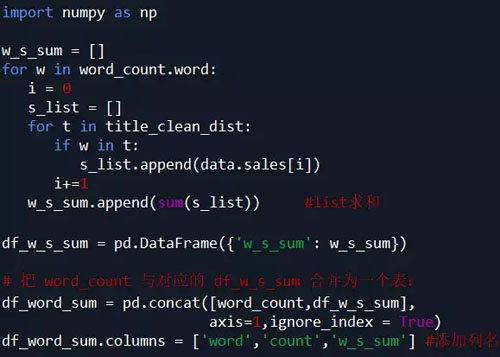
【2】. 不同关键词word对应的sales之和的统计分析:
(说明:例如 词语 ‘简约',则统计商品标题中含有‘简约'一词的商品的销量之和,即求出具有‘简约'风格的商品销量之和)
代码如下:
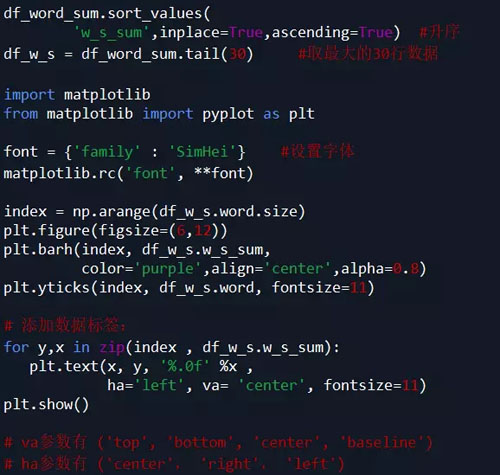
对表df_word_sum 中的 word 和 w_s_sum 两列数据进行可视化
(本例中取销量排名前30的词语进行绘图)
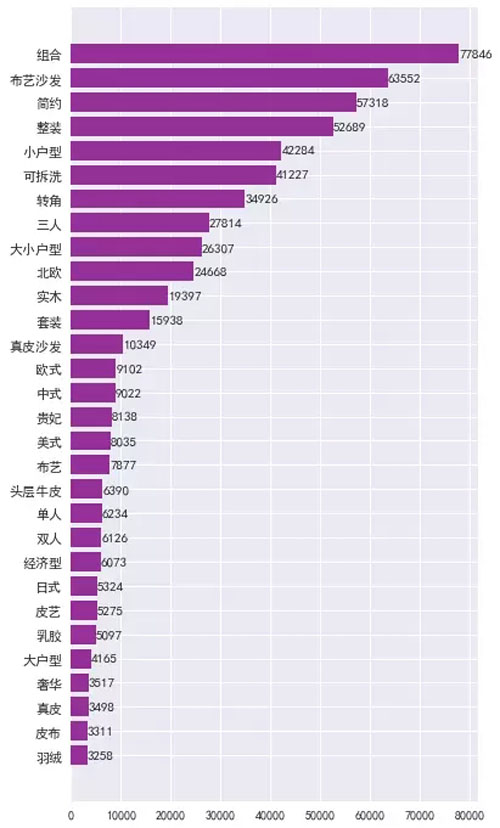
由图表可知:
1. 组合商品销量最高 ;
2. 从品类看:布艺沙发销量很高,远超过皮艺沙发;
3. 从户型看:小户型沙发销量最高,大小户型次之,大户型销量最少;
4. 从风格看:简约风销量最高,北欧风次之,其他依次是中式、美式、日式等;
5. 可拆洗、转角类沙发销量可观,也是颇受消费者青睐的。
【3】. 商品的价格分布情况分析:
分析发现,有一些值太大,为了使可视化效果更加直观,这里我们结合自身产品情况,选择价格小于20000的商品。
代码如下:
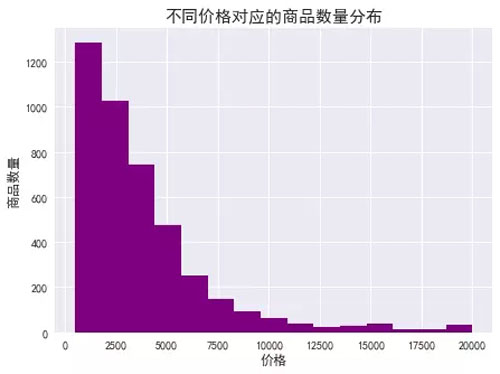
由图表可知:
1. 商品数量随着价格总体呈现下降阶梯形势,价格越高,在售的商品越少;
2. 低价位商品居多,价格在500-1500之间的商品最多,1500-3000之间的次之,价格1万以上的商品较少;
3. 价格1万元以上的商品,在售商品数量差异不大。
【4】. 商品的销量分布情况分析:

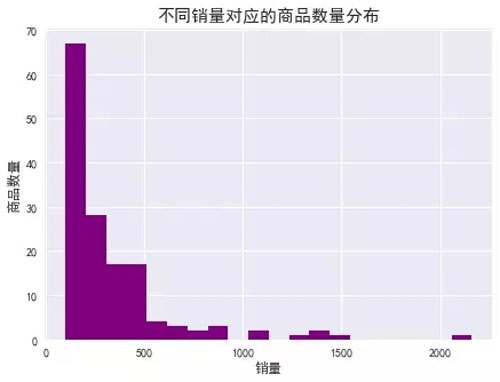
同样,为了使可视化效果更加直观,这里我们选择销量大于100的商品。
代码如下:
由图表及数据可知:
1. 销量100以上的商品仅占3.4% ,其中销量100-200之间的商品最多,200-300之间的次之;
2. 销量100-500之间,商品的数量随着销量呈现下降趋势,且趋势陡峭,低销量商品居多;
3. 销量500以上的商品很少。
【5】. 不同价格区间的商品的平均销量分布:
代码如下:

由图表可知:
1. 价格在1331-1680之间的商品平均销量最高,951-1331之间的次之,9684元以上的最低;
2. 总体呈现先增后减的趋势,但最高峰处于相对低价位阶段;
3. 说明广大消费者对购买沙发的需求更多处于低价位阶段,在1680元以上 价位越高 平均销量基本是越少。
【6】. 商品价格对销量的影响分析:
同上,为了使可视化效果更加直观,这里我们结合自身产品情况,选择价格小于20000的商品。
代码如下:
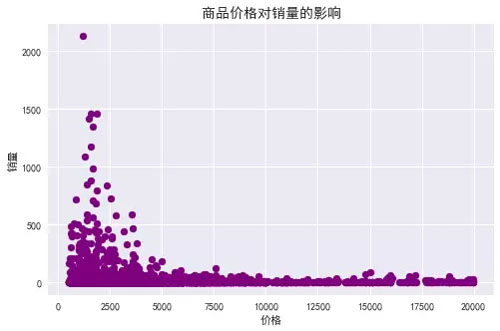
由图表可知:
1. 总体趋势:随着商品价格增多 其销量减少,商品价格对其销量影响很大;
2. 价格500-2500之间的少数商品销量冲的很高,价格2500-5000之间的商品多数销量偏低,少数相对较高,但价格5000以上的商品销量均很低 没有销量突出的商品。
【7】. 商品价格对销售额的影响分析:
代码如下:
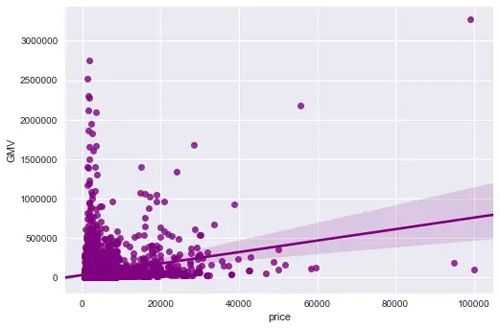
由图表可知:
1. 总体趋势:由线性回归拟合线可以看出,商品销售额随着价格增长呈现上升趋势;
2. 多数商品的价格偏低,销售额也偏低;
3. 价格在0-20000的商品只有少数销售额较高,价格2万-6万的商品只有3个销售额较高,价格6-10万的商品有1个销售额很高,而且是最大值。
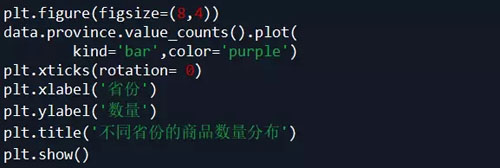
【8】. 不同省份的商品数量分布:
代码如下:
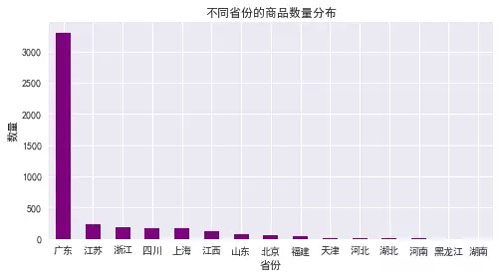
由图表可知:
1. 广东的最多,上海次之,江苏第三,尤其是广东的数量远超过江苏、浙江、上海等地,说明在沙发这个子类目,广东的店铺占主导地位;
2. 江浙沪等地的数量差异不大,基本相当。
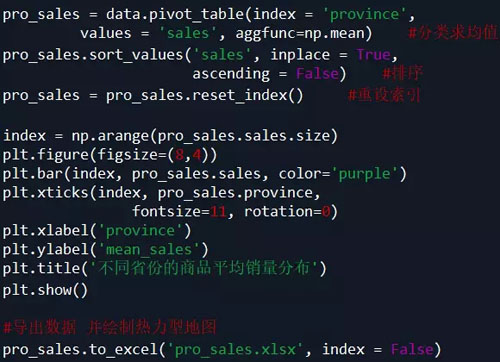
【9】. 不同省份的商品平均销量分布:
代码如下:
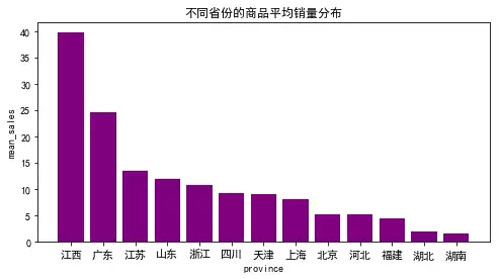
热力型地图
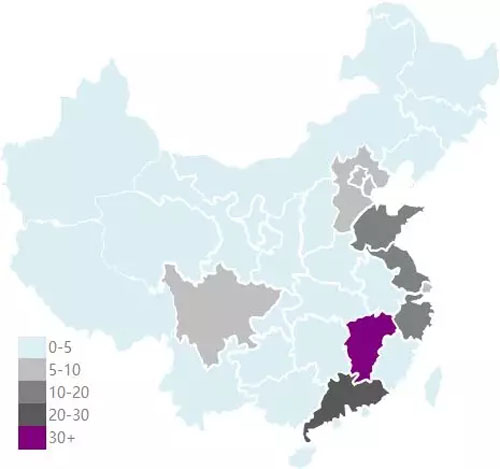
总结
以上所述是小编给大家介绍的使用Python爬了4400条淘宝商品数据,竟发现了这些“潜规则”,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
您可能感兴趣的文章:
- Python爬虫_城市公交、地铁站点和线路数据采集实例
- 一个月入门Python爬虫学习,轻松爬取大规模数据
- 基于python爬虫数据处理(详解)
- python实现爬虫数据存到 MongoDB
- Python爬虫抓取手机APP的传输数据
- python实现爬虫统计学校BBS男女比例之数据处理(三)
相关推荐
-

Python爬虫_城市公交、地铁站点和线路数据采集实例
城市公交.地铁数据反映了城市的公共交通,研究该数据可以挖掘城市的交通结构.路网规划.公交选址等.但是,这类数据往往掌握在特定部门中,很难获取.互联网地图上有大量的信息,包含公交.地铁等数据,解析其数据反馈方式,可以通过Python爬虫采集.闲言少叙,接下来将详细介绍如何使用Python爬虫爬取城市公交.地铁站点和数据. 首先,爬取研究城市的所有公交和地铁线路名称,即XX路,地铁X号线.可以通过图吧公交.公交网.8684.本地宝等网站获取,该类网站提供了按数字和字母划分类别的公交线路名称.Pyth
-
一个月入门Python爬虫学习,轻松爬取大规模数据
Python爬虫为什么受欢迎 如果你仔细观察,就不难发现,懂爬虫.学习爬虫的人越来越多,一方面,互联网可以获取的数据越来越多,另一方面,像 Python这样的编程语言提供越来越多的优秀工具,让爬虫变得简单.容易上手. 利用爬虫我们可以获取大量的价值数据,从而获得感性认识中不能得到的信息,比如: 知乎:爬取优质答案,为你筛选出各话题下最优质的内容. 淘宝.京东:抓取商品.评论及销量数据,对各种商品及用户的消费场景进行分析. 安居客.链家:抓取房产买卖及租售信息,分析房价变化趋势.做不同区域的房价分
-
Python爬虫抓取手机APP的传输数据
大多数APP里面返回的是json格式数据,或者一堆加密过的数据 .这里以超级课程表APP为例,抓取超级课程表里用户发的话题. 1.抓取APP数据包 方法详细可以参考这篇博文:Fiddler如何抓取手机APP数据包 得到超级课程表登录的地址:http://120.55.151.61/V2/StudentSkip/loginCheckV4.action 表单: 表单中包括了用户名和密码,当然都是加密过了的,还有一个设备信息,直接post过去就是. 另外必须加header,一开始我没有加header得
-
基于python爬虫数据处理(详解)
一.首先理解下面几个函数 设置变量 length()函数 char_length() replace() 函数 max() 函数 1.1.设置变量 set @变量名=值 set @address='中国-山东省-聊城市-莘县'; select @address 1.2 .length()函数 char_length()函数区别 select length('a') ,char_length('a') ,length('中') ,char_length('中') 1.3. replace() 函数
-
python实现爬虫统计学校BBS男女比例之数据处理(三)
本文主要介绍了数据处理方面的内容,希望大家仔细阅读. 一.数据分析 得到了以下列字符串开头的文本数据,我们需要进行处理 二.回滚 我们需要对httperror的数据进行再处理 因为代码的原因,具体可见本系列文章(二),会导致文本里面同一个id连续出现几次httperror记录: //httperror265001_266001.txt 265002 httperror 265002 httperror 265002 httperror 265002 httperror 265003 httper
-
python实现爬虫数据存到 MongoDB
在以上两篇文章中已经介绍到了 Python 爬虫和 MongoDB , 那么下面我就将爬虫爬下来的数据存到 MongoDB 中去,首先来介绍一下我们将要爬取的网站, readfree 网站,这个网站非常的好,我们只需要每天签到就可以免费下载三本书,良心网站,下面我就将该网站上的每日推荐书籍爬下来. 利用上面几篇文章介绍的方法,我们很容易的就可以在网页的源代码中寻找到书籍的姓名和书籍作者的信息. 找到之后我们复制 XPath ,然后进行提取即可.源代码如下所示 # coding=utf-8 imp
-
使用Python爬了4400条淘宝商品数据,竟发现了这些“潜规则”
本文记录了笔者用 Python 爬取淘宝某商品的全过程,并对商品数据进行了挖掘与分析,最终得出结论. 项目内容 本案例选择>> 商品类目:沙发: 数量:共100页 4400个商品: 筛选条件:天猫.销量从高到低.价格500元以上. 项目目的 1. 对商品标题进行文本分析 词云可视化 2. 不同关键词word对应的sales的统计分析 3. 商品的价格分布情况分析 4. 商品的销量分布情况分析 5. 不同价格区间的商品的平均销量分布 6. 商品价格对销量的影响分析 7. 商品价格对销售额的影响
-
php爬取天猫和淘宝商品数据
一.思路 最近做了一个网站用到了从网址爬取天猫和淘宝的商品信息,首先看了下手机端的网页发现用的react,不太了解没法搞,所以就考虑从PC入口爬取数据,但是当爬取URL获取数据时并没有获取价格,库存等的信息,仔细研究了下发现是异步请求了另一个接口,但是接口要使用refer才能获取数据,于是就通过以下方式写了一个简单的爬虫,用于爬取商品预览图和商品的第一个分类的价格.库存等. 二.实现 代码如下: function crawlUrl($url){ import('PhpQuery.Curl');
-
python实现爬取千万淘宝商品的方法
本文实例讲述了python实现爬取千万淘宝商品的方法.分享给大家供大家参考.具体实现方法如下: import time import leveldb from urllib.parse import quote_plus import re import json import itertools import sys import requests from queue import Queue from threading import Thread URL_BASE = 'http://s
-
python爬虫爬取淘宝商品信息
本文实例为大家分享了python爬取淘宝商品的具体代码,供大家参考,具体内容如下 import requests as req import re def getHTMLText(url): try: r = req.get(url, timeout=30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "" def parasePage(ilt, html): tr
-
python爬虫爬取淘宝商品信息(selenum+phontomjs)
本文实例为大家分享了python爬虫爬取淘宝商品的具体代码,供大家参考,具体内容如下 1.需求目标 : 进去淘宝页面,搜索耐克关键词,抓取 商品的标题,链接,价格,城市,旺旺号,付款人数,进去第二层,抓取商品的销售量,款号等. 2.结果展示 3.源代码 # encoding: utf-8 import sys reload(sys) sys.setdefaultencoding('utf-8') import time import pandas as pd time1=time.time()
-
Python进阶之使用selenium爬取淘宝商品信息功能示例
本文实例讲述了Python进阶之使用selenium爬取淘宝商品信息功能.分享给大家供大家参考,具体如下: # encoding=utf-8 __author__ = 'Jonny' __location__ = '西安' __date__ = '2018-05-14' ''' 需要的基本开发库文件: requests,pymongo,pyquery,selenium 开发流程: 搜索关键字:利用selenium驱动浏览器搜索关键字,得到查询后的商品列表 分析页码并翻页:得到商品页码数,模拟翻页
-
python爬取淘宝商品详情页数据
在讲爬取淘宝详情页数据之前,先来介绍一款 Chrome 插件:Toggle JavaScript (它可以选择让网页是否显示 js 动态加载的内容),如下图所示: 当这个插件处于关闭状态时,待爬取的页面显示的数据如下: 当这个插件处于打开状态时,待爬取的页面显示的数据如下: 可以看到,页面上很多数据都不显示了,比如商品价格变成了划线价格,而且累计评论也变成了0,说明这些数据都是动态加载的,以下演示真实价格的找法(评论内容找法类似),首先检查页面元素,然后点击Network选项卡,刷新页面,可
-
python爬取淘宝商品销量信息
python爬取淘宝商品销量的程序,运行程序,输入想要爬取的商品关键词,在代码中的'###'可以进一步约束商品的属性,比如某某作者的书籍,可以在###处输入作者名字,以及时期等等.最后可以得到所要商品的总销量 import requests import bs4 import re import json def open(keywords, page): headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64)
-
Python通过正则库爬取淘宝商品信息代码实例
使用正则库爬取淘宝商品的商品信息,首先我们需要确定想要爬取的对象 我们在淘宝里搜索"python",出来的结果 从url连接中可以得到搜索商品的关键字是"q=",所以我们要用的起始url为:https://s.taobao.com/search?q=python 然后翻页,经过对比发现,翻页后,变化的关键字是s,每次翻页,s便以44的倍数增长(可以数一下每页显示的商品数量,刚好是44) 所以可以根据关键字"s=",来设置爬取的深度(爬取多少页)
-
Python 爬取淘宝商品信息栏目的实现
一.相关知识点 1.1.Selenium Selenium是一个强大的开源Web功能测试工具系列,可进行读入测试套件.执行测试和记录测试结果,模拟真实用户操作,包括浏览页面.点击链接.输入文字.提交表单.触发鼠标事件等操作,并且能够对页面结果进行种种验证.也就是说,只要在测试用例中把预期的用户行为与结果都描述出来,我们就得到了一个可以自动化运行的功能测试套件. 1.2.ActionChains Actionchains是selenium里面专门处理鼠标相关的操作如:鼠标移动,鼠标按钮操作,按键和