算法详解之分支限界法的具体实现
首先我们来关注一个问题:
问题描述:
布线问题:印刷电路板将布线区域划分成n×m个方格阵列,要求确定连接方格阵列中的方格a的中点到方格b的中点的最短布线方案。在布线时,电路只能沿直线或直角布线,为了避免线路相交,已布了线的方格做了封锁标记,其他线路不允许穿过被封锁的方格。如下图所示:
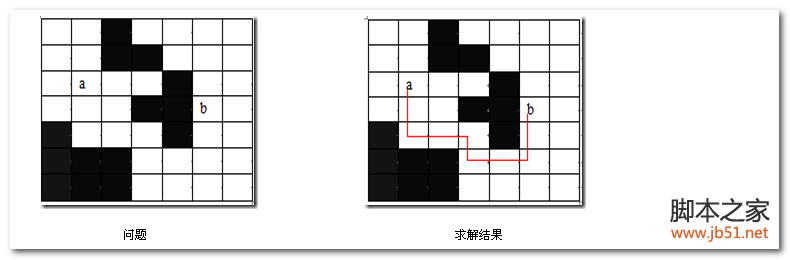
算法思路:
布线问题的解空间是一个图,则从起始位置a开始将它作为第一个扩展结点。与该扩展结点相邻并可达的方格成为可行结点被加入到活结点队列中,并且将这些方格标记为1,即从起始方格a到这些方格的距离为1。接着,从活结点队列中取出队首结点作为下一个扩展结点,并将与当前扩展结点相邻且未标记过的方格标记为2,并存入活结点队列。这个过程一直继续到算法搜索到目标方格b或活结点队列为空时为止。
在实现上述算法时,
(1) 定义一个表示电路板上方格位置的类Position。
它的2个成员row和col分别表示方格所在的行和列。在方格处,布线可沿右、下、左、上4个方向进行。沿这4个方向的移动分别记为0,1,2,3。下表中,offset[i].row和offset[i].col(i= 0,1,2,3)分别给出沿这4个方向前进1步相对于当前方格的相对位移。

(2) 用二维数组grid表示所给的方格阵列。
初始时,grid[i][j] = 0, 表示该方格允许布线,而grid[i][j] = 1表示该方格被封锁,不允许布线。
算法图解:
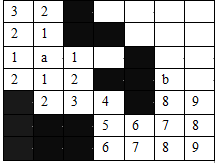
代码贴出来:
#include <stdio.h>
typedef struct {
int row;
int col;
}Position;
int FindPath (Position start, Position finish, int &PathLen, Position *&path)
{ //计算从起始位置start到目标位置finish的最短布线路径,找到返回1,否则,返回0
int i;
if ((start.row = = finish.row) && (start.col = = finish.col)) {
PathLen = 0; return 0; } //start = finish
//设置方格阵列”围墙”
for (i = 0; i <= m+1; i++)
grid[0][i] = grid[n+1][i] = 1; //顶部和底部
for (i = 0; i <= n+1; i++)
grid[i][0] = grid[i][m+1] = 1; //左翼和右翼
//初始化相对位移
int NumOfNbrs = 4; //相邻方格数
Position offset[4], here, nbr;
offset[0].row = 0; offset[0].col = 1; //右
offset[0].row = 1; offset[0].col = 0; //下
offset[0].row = 0; offset[0].col = -1; //左
offset[0].row = -1; offset[0].row = 0; //上
here.row = start.row;
here.col = start.col;
LinkedQueue <Position> Q; //标记可达方格位置
do {
for (i = 0; i< NumOfNbrs; i++) { //标记可达相邻方格
nbr.row = here.row + offset[i].row ;
nbr.col = here.col + offset[i].col;
if (grid[nbr.row][nbr.col] = = 0) { //该方格未标记
grid[nbr.row][nbr.col] = grid[here.row][here.col] + 1;
if ((nbr.row = = finish.row) && (nbr.col = = finish.col)) break;//完成布线
Q.Add(nbr);
}
}
if ((nbr.row = = finishi.row) && (nbr.col = = finish.col)) break;//完成布线
if (Q.IsEmpty()) //活队列是否为空
return 0; //无解
Q.delete(here); //取下一个扩展结点
}while (1);
//构造最短布线路径
PathLen = grid[finish.row][finish.col] - 2;
path = new Position[PathLen];
here = finish;
for (int j = PathLen – 1; j >= 0; j--) { //找前驱位置
path[j] = here;
for (i = 0; i< NumOfNbrs; i++) {
nbr.row = here.row + offset[i].row ;
nbr.col = here.col + offset[i].col;
if (grid[nbr.row][nbr.col] = = j+2) break;
}
here = nbr; //向前移动
}
return 1;
}
void main ()
{
int grid[8][8];
int PathLen, *path;
Position start, finish;
start.row = 3; start.col = 2;
finish.row = 4; finish.col = 6;
FindPath (start, finish, PathLen, path);
}
代码贴出来:
#include <stdio.h>
typedef struct {
int row;
int col;
}Position;
int FindPath (Position start, Position finish, int &PathLen, Position *&path)
{ //计算从起始位置start到目标位置finish的最短布线路径,找到返回1,否则,返回0
int i;
if ((start.row = = finish.row) && (start.col = = finish.col)) {
PathLen = 0; return 0; } //start = finish
//设置方格阵列”围墙”
for (i = 0; i <= m+1; i++)
grid[0][i] = grid[n+1][i] = 1; //顶部和底部
for (i = 0; i <= n+1; i++)
grid[i][0] = grid[i][m+1] = 1; //左翼和右翼
//初始化相对位移
int NumOfNbrs = 4; //相邻方格数
Position offset[4], here, nbr;
offset[0].row = 0; offset[0].col = 1; //右
offset[0].row = 1; offset[0].col = 0; //下
offset[0].row = 0; offset[0].col = -1; //左
offset[0].row = -1; offset[0].row = 0; //上
here.row = start.row;
here.col = start.col;
LinkedQueue <Position> Q; //标记可达方格位置
do {
for (i = 0; i< NumOfNbrs; i++) { //标记可达相邻方格
nbr.row = here.row + offset[i].row ;
nbr.col = here.col + offset[i].col;
if (grid[nbr.row][nbr.col] = = 0) { //该方格未标记
grid[nbr.row][nbr.col] = grid[here.row][here.col] + 1;
if ((nbr.row = = finish.row) && (nbr.col = = finish.col)) break;//完成布线
Q.Add(nbr);
}
}
if ((nbr.row = = finishi.row) && (nbr.col = = finish.col)) break;//完成布线
if (Q.IsEmpty()) //活队列是否为空
return 0; //无解
Q.delete(here); //取下一个扩展结点
}while (1);
//构造最短布线路径
PathLen = grid[finish.row][finish.col] - 2;
path = new Position[PathLen];
here = finish;
for (int j = PathLen – 1; j >= 0; j--) { //找前驱位置
path[j] = here;
for (i = 0; i< NumOfNbrs; i++) {
nbr.row = here.row + offset[i].row ;
nbr.col = here.col + offset[i].col;
if (grid[nbr.row][nbr.col] = = j+2) break;
}
here = nbr; //向前移动
}
return 1;
}
void main ()
{
int grid[8][8];
int PathLen, *path;
Position start, finish;
start.row = 3; start.col = 2;
finish.row = 4; finish.col = 6;
FindPath (start, finish, PathLen, path);
}
好了,问题解出来了。咦,我们用的是什么方法呢?呵呵,对,这就是分支限界算法。
算法总结:
分支限界法基本思想:
• 分支限界法常以广度优先或以最小耗费(最大效益)优先的方式搜索问题的解空间树。
• 在分支限界法中,每一个活结点只有一次机会成为扩展结点。活结点一旦成为扩展结点,就一次性产生其所有儿子结点。
• 在这些儿子结点中,导致不可行解或导致非最优解的儿子结点被舍弃,其余儿子结点被加入活结点表中。
• 此后,从活结点表中取下一结点成为当前扩展结点,并重复上述结点扩展过程。这个过程一直持续到找到所需的解或活结点表为空时为止。
分支限界法与回溯法的不同:
(1)求解目标不同:回溯法的求解目标是找出解空间树中满足约束条件的所有解,而分支限界法的求解目标则是找出满足约束条件的一个解,或是在满足约束条件的解中找出在某种意义下的最优解。
(2)搜索方式的不同:回溯法以深度优先的方式搜索解空间树,而分支限界法则以广度优先或以最小耗费优先的方式搜索解空间树。
相关推荐
-

算法详解之分支限界法的具体实现
首先我们来关注一个问题: 问题描述: 布线问题:印刷电路板将布线区域划分成n×m个方格阵列,要求确定连接方格阵列中的方格a的中点到方格b的中点的最短布线方案.在布线时,电路只能沿直线或直角布线,为了避免线路相交,已布了线的方格做了封锁标记,其他线路不允许穿过被封锁的方格.如下图所示: 算法思路: 布线问题的解空间是一个图,则从起始位置a开始将它作为第一个扩展结点.与该扩展结点相邻并可达的方格成为可行结点被加入到活结点队列中,并且将这些方格标记为1,即从起始方格a到这些方格的距离为1.接着,从活结
-
python算法演练_One Rule 算法(详解)
这样某一个特征只有0和1两种取值,数据集有三个类别.当取0的时候,假如类别A有20个这样的个体,类别B有60个这样的个体,类别C有20个这样的个体.所以,这个特征为0时,最有可能的是类别B,但是,还是有40个个体不在B类别中,所以,将这个特征为0分到类别B中的错误率是40%.然后,将所有的特征统计完,计算所有的特征错误率,再选择错误率最低的特征作为唯一的分类准则--这就是OneR. 现在用代码来实现算法. # OneR算法实现 import numpy as np from sklearn.da
-
python实现决策树C4.5算法详解(在ID3基础上改进)
一.概论 C4.5主要是在ID3的基础上改进,ID3选择(属性)树节点是选择信息增益值最大的属性作为节点.而C4.5引入了新概念"信息增益率",C4.5是选择信息增益率最大的属性作为树节点. 二.信息增益 以上公式是求信息增益率(ID3的知识点) 三.信息增益率 信息增益率是在求出信息增益值在除以. 例如下面公式为求属性为"outlook"的值: 四.C4.5的完整代码 from numpy import * from scipy import * from mat
-
java 中归并排序算法详解
java 中归并排序算法详解 归并排序算法,顾名思义,是一种先分再合的算法,其算法思想是将要排序的数组分解为单个的元素,每个元素就是一个单个的个体,然后将相邻的两个元素进行从小到大或从大到小的顺序排序组成一个整体,每个整体包含一到两个元素,然后对相邻的整体继续"合"并,因为每个整体都是排过序的,因而可以采用一定的算法对其进行合并,合并之后每个整体包含三到四个元素,继续对相邻的整体进行合并,直到所有的整体都合并为一个整体,最终得到的整体就是将原数组进行排序之后的结果. 对于相邻的整体,其
-
python中实现k-means聚类算法详解
算法优缺点: 优点:容易实现 缺点:可能收敛到局部最小值,在大规模数据集上收敛较慢 使用数据类型:数值型数据 算法思想 k-means算法实际上就是通过计算不同样本间的距离来判断他们的相近关系的,相近的就会放到同一个类别中去. 1.首先我们需要选择一个k值,也就是我们希望把数据分成多少类,这里k值的选择对结果的影响很大,Ng的课说的选择方法有两种一种是elbow method,简单的说就是根据聚类的结果和k的函数关系判断k为多少的时候效果最好.另一种则是根据具体的需求确定,比如说进行衬衫尺寸的聚
-
Python编程实现蚁群算法详解
简介 蚁群算法(ant colony optimization, ACO),又称蚂蚁算法,是一种用来在图中寻找优化路径的机率型算法.它由Marco Dorigo于1992年在他的博士论文中提出,其灵感来源于蚂蚁在寻找食物过程中发现路径的行为.蚁群算法是一种模拟进化算法,初步的研究表明该算法具有许多优良的性质.针对PID控制器参数优化设计问题,将蚁群算法设计的结果与遗传算法设计的结果进行了比较,数值仿真结果表明,蚁群算法具有一种新的模拟进化优化方法的有效性和应用价值. 定义 各个蚂蚁在没有事先告诉
-
Java语言实现快速幂取模算法详解
快速幂取模算法的引入是从大数的小数取模的朴素算法的局限性所提出的,在朴素的方法中我们计算一个数比如5^1003%31是非常消耗我们的计算资源的,在整个计算过程中最麻烦的就是我们的5^1003这个过程 缺点1:在我们在之后计算指数的过程中,计算的数字不都拿得增大,非常的占用我们的计算资源(主要是时间,还有空间) 缺点2:我们计算的中间过程数字大的恐怖,我们现有的计算机是没有办法记录这么长的数据的,所以说我们必须要想一个更加高效的方法来解决这个问题 当我们计算AB%C的时候,最便捷的方法就是调用Ma
-
Java垃圾回收之分代收集算法详解
概述 这种算法,根据对象的存活周期的不同将内存划分成几块,新生代和老年代,这样就可以根据各个年代的特点采用最适当的收集算法.可以用抓重点的思路来理解这个算法. 新生代对象朝生夕死,对象数量多,只要重点扫描这个区域,那么就可以大大提高垃圾收集的效率.另外老年代对象存储久,无需经常扫描老年代,避免扫描导致的开销. 新生代 在新生代,每次垃圾收集器都发现有大批对象死去,只有少量存活,采用复制算法,只需要付出少量存活对象的复制成本就可以完成收集:可以参看我之前写的Java垃圾回收之复制算法详解 老年代
-
Js面试算法详解
素数 Q:你将如何验证一个素数? A:一个素数只能被它自己和1整除.所以,我将运行一个while循环并加1.(看代码示例,如果你无法理解,那这不是你的菜.先回去学习javaScript基础知识然后再回来吧.) 方法1 function isPrime(n){ var divisor = 2; while (n > divisor){ if(n % divisor == 0){ return false; } else divisor++; } return true; } isPrime(137
-
Java垃圾回收之复制算法详解
之前的Java垃圾回收之标记清除算法详解 会导致内存碎片.下文的介绍的coping算法可以解决内存碎片问题. 概述 如果jvm使用了coping算法,一开始就会将可用内存分为两块,from域和to域, 每次只是使用from域,to域则空闲着.当from域内存不够了,开始执行GC操作,这个时候,会把from域存活的对象拷贝到to域,然后直接把from域进行内存清理. 应用场景 coping算法一般是使用在新生代中,因为新生代中的对象一般都是朝生夕死的,存活对象的数量并不多,这样使用coping算法