关于Shell脚本效率优化的一些个人想法
一、先说一下Shell脚本语言自身的局限性
作为解释型的脚本语言,天生就有效率上边的缺陷。尽管它调用的其他命令可能效率上是不错的。
Shell脚本程序的执行是顺序执行,而非并行执行的。这很大程度上浪费了可能能利用上的系统资源。
Shell每执行一个命令就创建一个新的进程,如果脚本编写者没有这方面意识,编写脚本不当的话,是非常浪费系统资源的。
二、我们在Shell脚本语言的局限性上尽可能的通过我们有经验的编码来提高脚本的效率。
1、比如我想做一个循环处理数据,可能是简单的处理一下数据,这样会让人比较容易就想到Shell里的循环类似这样:
代码如下:
sum=0
for((i=0;i<100000;i++))
do
sum=$(($sum+$i))
done
echo $sum
我们可以使用time这个脚本来测试一下十万次循环的三次执行耗时:
real 0m2.115s
user 0m1.975s
sys 0m0.138s
real 0m2.493s
user 0m2.173s
sys 0m0.254s
real 0m2.085s
user 0m1.886s
sys 0m0.195s
平均耗时2.2s,如果你知道awk命令里的循环的话,那更好了,我们来测试一下同数据规模的循环三次执行耗时:
代码如下:
awk 'BEGIN{
sum=0;
for(i=0;i<100000;i++)
sum=sum+i;
print sum;
}'
real 0m0.023s
user 0m0.018s
sys 0m0.005s
real 0m0.020s
user 0m0.018s
sys 0m0.002s
real 0m0.021s
user 0m0.019s
sys 0m0.003s
你都不敢想象平均时间仅0.022s,基本上纯循环的效率已经比Shell高出两位数量级了。事实上你再跑百万次的循环你会发现Shell已经比较吃力了,千万级的更是艰难。所以你应该注意你的程序尽量使用awk来做循环操作。
2、关于正则,经常写Shell的同学都明白它的重要性,但是你真的能高效使用它吗?
下边举个例子:现在我有一个1694617行的日志文件 action.log,它的内容类似:
2012_02_07 00:00:04 1977575701 183.10.69.47 login 500004 1977575701 old /***/port/***.php?…
我现在想获取//之间的port的字符串,我可以这样:
awk -F'/' ‘{print $3}' < 7action.log > /dev/null
但是你不会想知道它的效率:
real 0m12.296s
user 0m12.033s
sys 0m0.262s
相信我,我不会再想看着光标闪12秒的。但是如果这样执行:
awk ‘{print $9}' < 7action.log | awk -F'/' '{print $3}' > /dev/null
这句的效率三次分别是:
real 0m3.691s
user 0m5.219s
sys 0m0.630s
real 0m3.660s
user 0m5.169s
sys 0m0.618s
real 0m3.660s
user 0m5.150s
sys 0m0.612s
平均时间大概3.6秒,这前后效率大概有4倍的差距,虽然不像上一个有百倍的差距,但是也足够让4小时变成1小时了。我想你懂这个差距的。
其实这个正则实例你可以尝试推测其他的情况,因为正则每次运行都是需要启动字符串匹配的,而且默认的分隔符会较快的按字段区分出。所以我们在知道一些数据规律之后可以尝试大幅度的缩短我们将要进行复杂正则匹配的字符串,这样会根据你缩减数据规模有一个非常明显的效率提升,上边还是验证的比较简单的正则匹配情况,只有一个单字符“\”,你可以试想如果正则表达式是这样:
$7!~/\.jpg$/&&$7~/\.[s]?html|\.php|\.xml|\/$/&&($9==200||$9==304)&&$1!~/^103\.108|^224\.215|^127\.0|^122\.110\.5/
我想你可以想象的出一个目标匹配字符串从500个字符缩减到50个字符的时候的巨大意义!
ps:另外详细的正则优化请看这个日期之后发的一篇博文。
3、再说一下shell的重定向和管道。这个条目我不会再举例子,只是说一下我个人的理解。
周所周知,很多程序或者语言都有一个比较突出的效率瓶颈就是IO,Shell也不例外(个人这么考虑)。所以建议尽可能的少用重定向来进行输入输出这样的操作或者创建临时文件来供后续使用,当然,如果必须这么干的时候那就这么干吧,我只是讲一个尽量的过程。
我们可以用Shell提供的管道来实现命令间数据的传递。如果进行连续的对数据进行过滤性命令的时候,尽量把一次性过滤较多的命令放在前边,这个原因都懂吧?减少数据传递规模。
最后我想说的连管道也尽量的少用的,虽然管道比正常的同定向IO快几个数量级的样子,但是那也是需要消耗额外的资源的,好好设计你的代码来减少这个开销吧。比如sort | uniq 命令,完全可以使用 sort -u 来实现。
4、再说一下Shell脚本程序的顺序执行。这块的优化取决于你的系统负载是否达到了极限,如果你的系统连命令的顺序执行负载都到了一个较高的线的话,你就没有必要进行Shell脚本程序的并行改造了。下边给出一个例子,如果你要模仿这个优化,请保证你的系统还能有负载空间。比如现在有这样一个程序:
supportdatacommand1
supportdatacommand2
supportdatacommand3
supportdatacommand4
supportdatacommand5
supportdatacommand6
need13datacommand
need24datacommand
need56datacommand
大意就是有6个提供数据的命令在前边,后面有3个需要数据的命令,第一个需要数据的命令需要数据13,第二个需要24,第三个需要56。但是正常情况下Shell会顺序的执行这些命令,从supportdatacommand1,一条一条执行到need56datacommand。这样的过程你看着是不是也很蛋疼?明明可以更好的做这一块的,蛋疼的程序可以这样改造:
代码如下:
supportdatacommand1 &
supportdatacommand2 &
supportdatacommand3 &
supportdatacommand4 &
supportdatacommand5 &
supportdatacommand6 &
#2012-02-22 ps:这里的循环判断后台命令是否执行完毕是有问题的,pidnum循#环减到最后也还是1不会得到0值,具体解决办法看附录,因为还有解释,就不在这#里添加和修改了。
while true
do
sleep 10s
pidnum=`jobs -p | wc -l`
if [ $pidnum -le 0 ]
then
echo "run over"
break
fi
done
need13datacommand &
need24datacommand &
need56datacommand &
wait
...
可以类似上边的改造。这样改造之后蛋疼之感就纾解的多了。但还是感觉不是很畅快,那好吧,我们可以再畅快一点(我是指程序。。。),可以类似这样:
代码如下:
for((i=0;i<1;i++));do
{
command1
command2
}&
done
for((i=0;i<1;i++));do
{
command3&
command4&
}&
done
for((i=0;i<1;i++));do
{
command5 &
command6 &
if 5 6执行完毕...
command7
}&
done
这样类似这样的改造,让有前后关系的命令放在一个for循环里让他们一起执行去,这样三个for循环其实是并行执行了。然后for循环内部的命令你还可以类似改造1的那种方式改造或者内嵌改造2这个的并行for循环,都是可以的,关键看你想象力了。恩?哦,不对,关键是看这些个命令之间是一种什么样的基友关系了。有关联的放一个屋里就行了,剩下的你就不用操心了。嘿嘿~~
其实这个优化真的需要看系统负载。
5、关于对shell命令的理解。这个条目就靠经验了,因为貌似没有相关的书籍可看,如果谁知道有,请推荐给我,我会灰常感谢的啊。
比如:sed -n '45,50p' 和 sed -n '51q;45,50p' ,前者也是读取45到50行,后者也是,但是后者到51行就执行了退出sed命令,避免了后续的操作读取。如果这个目标文件的规模巨大的话,剩下的你懂的。
还有类似sed ‘s/foo/bar/g' 和sed ‘/foo/ s/foo/bar/g'
sed支持采用正则进行匹配和替换,考虑字符串替换的需求中,不防加上地址以提高速度。实例中通过增加一个判断逻辑,采用“事先匹配”代替“直接替换”,由于sed会保留前一次的正则匹配环境,不会产生冗余的正则匹配,因此后者具有更高的效率。关于sed命令的这两点优化,我也在sed命令详解里有提到。
还有类似sort 如果数字尽量用 -n选项;还有统计文件行数,如果每行的数据在占用字节数一样的情况时就可以ls查文件大小然后除以每行的数据大小的出行数,而避免直接使用wc -l这样的命令;还有find出来的数据,别直接就-exec选项了,如果数据规模小很好,但是如果你find出来上千条数据或更多,你会疯掉的,不,系统会疯掉的,因为每行数据都会产生新的进程,你可以这样find …. | xargs ….;还有…(如果你也知道类似的提效率情况请你告诉我共同进步!)
三、关于优化更好的一些选择
一个比较好的提升Shell脚本的效率方法就是…… 就是…… 就是…… 好吧,就是尽量少用Shell(别打我啊!!!)下边给出一些debian官方统计的一些在linux系统上边的各个语言的效率图,咱都以C++为比较基准(系统规格:x64 Ubuntu™ Intel® Q6600® quad-core):
这些图的查看方法,比如第一个图java和c++的程序效率比较图,总共分三个部分,分别是time、memory、code的比较,如果是c++/java ,就是说 c++做比较的分子,java做比较的分母,如果图上的长条在哪边,说明所在的那边的程序使用的时间或者内存或者代码较多,具体多多少就看长条长了多少。每一部分有多个长条图形,每个长条图案表示针对程序处理不同方面的任务时进行的测试。比如第一幅,c++和java在该环境下大部分情况下time上是差不多的,甚至java-server还有稍微的优势,内存方面c++就有很大优势,能够使用比java少的多的内容做相同的事情,但是编码量c++就稍微多一点点。以下的图类似。 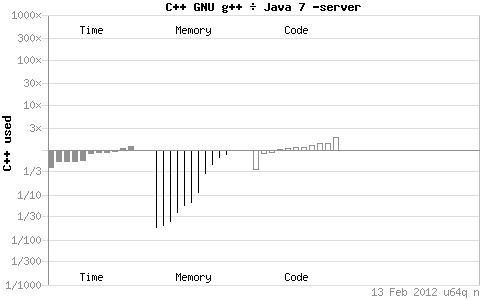
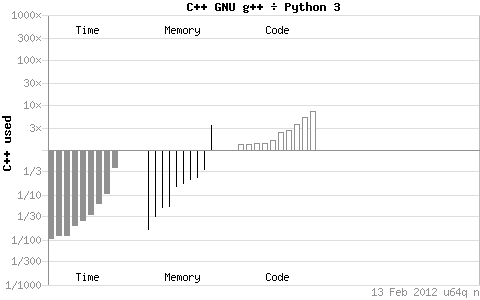
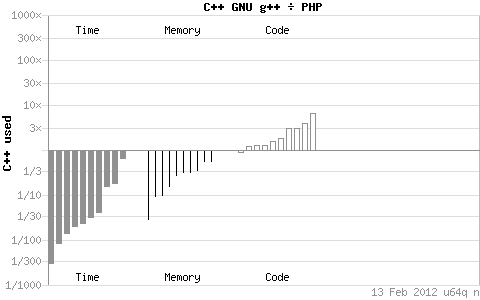
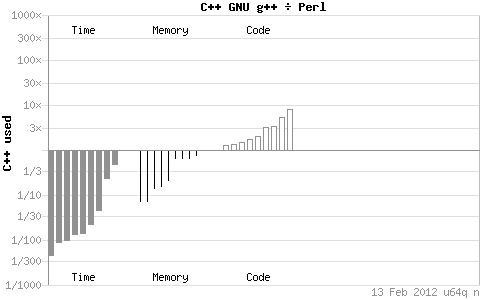
通过上边的图我看可以知道C++在时间和空间上对Python、Perl、PHP有着绝对压倒性的优势,但是相对的编码量较高。同java比只有内存使用上的优势。但是我们这篇主要是针对Shell的,但是,又是但是,debian官网没有把shell脚本纳入效率比较的统计范围啊!!!还是但是,我们知道Python、Perl、PHP都是号称对Shell在效率方面有着明显的优势,所以你如果不满意你通过以上提供的种种优化途径后的Shell脚本程序的话,那你就可以尝试换一种语言了。
但是我们往往不那么容易舍弃这么好用方便而且简单的处理数据方式,也可以有个折中的方法,你先用time测试各个Shell脚本命令的耗时,针对特别耗时,特别让人不能忍受的命令的效率使用C++程序处理,让你的Shell脚本来调用这个针对局部数据处理的C++程序,这样折中貌似还是能让人接受吧?
四、最后说一下这篇是不敢称为全面或者详解的文章,是我对这一段Shell学习和实践的一些心得,希望能有高手指点。也希望能帮到新踏入这一领域的新同学。以后有新的心得再添加吧。
感谢这篇文章的作者的博文指点。
2012-02-22 ps:循环检测后台命令是否结束的判断修改:
解决方法暂时有两个(具体没有解释,不太清楚原因):
1、
代码如下:
sleep 8 &
sleep 16 &
while true
do
echo `jobs -p | wc -l`
jobs -l >> res
sleep 4
done
2、 检查剩余个数的语句改成 jobs -l |grep -v “Done”|wc -l
第一个方案的解决是多执行一次jobs,可以解释成为了消除最后的Done结果,但是这种解释也是行不通的,因为循环是一直执行的,在echo里已经执行很多次jobs了,何止一次。
第二个方案是过滤掉jobs最后的输出结果Done这条语句。算是绕过问题得到了期待的结果。
个人感觉bash解释器优化掉了没有后台命令执行的jobs查询命令,如果是优化掉了那也应该有个空的返回,wc依然可以得到0的结果啊。所以这个问题找不到具体原因,如果你知道请告诉我,非常感谢。。。 这里先感谢just do shell群里的Eric 沉默的土匪 GS 三人,非常感谢你们的帮助。
这里两个方法不算好方法,只是奇怪这样为什么不行,行的又该如何解释。后来知道用wait命令就全解决了,耽误那么多时间还是用的不明智的方法。
转载请注明:三江小渡厚道喔!
相关推荐
-

关于Shell脚本效率优化的一些个人想法
一.先说一下Shell脚本语言自身的局限性 作为解释型的脚本语言,天生就有效率上边的缺陷.尽管它调用的其他命令可能效率上是不错的. Shell脚本程序的执行是顺序执行,而非并行执行的.这很大程度上浪费了可能能利用上的系统资源. Shell每执行一个命令就创建一个新的进程,如果脚本编写者没有这方面意识,编写脚本不当的话,是非常浪费系统资源的. 二.我们在Shell脚本语言的局限性上尽可能的通过我们有经验的编码来提高脚本的效率. 1.比如我想做一个循环处理数据,可能是简单的处理一下数据,这样会让人比
-
实现MySQL定时批量检查表repair和优化表optimize table的shell脚本
本文介绍mysql定时批量检查表repair和优化表optimize table的shell脚本,对于MySQL数据库的定期维护相当有用!如下所示: #!/bin/bash host_name=192.168.0.123 user_name=jincon.com user_pwd=jincon.com database=my_db_name need_optmize_table=true tables=$(mysql -h$host_name -u$user_name -p$user_pwd $
-
shell脚本学习指南[五](Arnold Robbins & Nelson H.F. Beebe著)
作者告诉我们:到目前为止基础已经搞定,可以将前边所学结合shell变成进军中等难度的任务了.激动的要哭了,终于看到本书结束的曙光了 T T .码字比码代码还辛苦.不过令人兴奋的是立刻就学以致用了,花了一天半的时间处理了一个3.8G的服务器日志文件,你妹啊,破电脑内存才2G.不过切割化小然后写了几个awk文件和sh文件按规则处理合并,算是搞定了! 第十一章扩展实例:合并用户数据库 问题描述就是有两台UNIX的计算机系统,这两个系统现在要合并,用户群同样需要合并.有许多用户两台系统上都有帐号.现在合
-
shell脚本学习指南[二](Arnold Robbins & Nelson H.F. Beebe著)
该进入第四章了,刚才看到一个帖子标题:我空有一身泡妞的好本领,但可惜自己是个妞.汗-这个...音乐无国界嘛,这个不应该也没性别界么? 第四章文本处理工具 书中先说明了以下排序的规则,数值的就不用说了,该大就大该小就小,但是字符型很多时候是区分声调或者重音的.在命令行中输入locale查看自己系统的编码配置.默认的是系统配置里的,但是可以自己设置排序的编码.如: 复制代码 代码如下: $ LC_ALL=C sort french-english #以传统ASCII码顺序排序 下边介绍以下排序命令s
-
Nodejs中调用系统命令、Shell脚本和Python脚本的方法和实例
每种语言都有自己的优势,互相结合起来各取所长程序执行起来效率更高或者说哪种实现方式较简单就用哪个,nodejs是利用子进程来调用系统命令或者文件,文档见http://nodejs.org/api/child_process.html,NodeJS子进程提供了与系统交互的重要接口,其主要API有: 标准输入.标准输出及标准错误输出的接口. NodeJS 子进程提供了与系统交互的重要接口,其主要 API 有: 标准输入.标准输出及标准错误输出的接口 child.stdin 获取标准输入 child.
-
shell脚本测试某网段内主机连通性
1. 测试192.168.4.0/24整个网段的连通性(while版本) #!/bin/bash #Author:丁丁历险(Jacob) #定义变量i控制循环次数,i从1开始循环,每循环一次,i自加1,直到i等于254循环退出 #在每次循环中对一个IP进行ping测试,如果ping通,提示主机是UP的 #如果无法ping同,则提示主机是down的 #ping命令的-c选项控制ping测试的次数,-c2表示对目标主机执行2次ping测试 #ping命令的-i选项,控制多次ping测试的间隔时间默认
-
Shell脚本生成随机密码的若干种可能
1.生成随机密码(urandom版本) #!/bin/bash #Author:丁丁历险(Jacob) #/dev/urandom文件是Linux内置的随机设备文件 #cat /dev/urandom可以看看里面的内容,ctrl+c退出查看 #查看该文件内容后,发现内容有些太随机,包括很多特殊符号,我们需要的密码不希望使用这些符号 #tr -dc '_A-Za-z0-9' </dev/urandom #该命令可以将随机文件中其他的字符删除,仅保留大小写字母,数字,下划线,但是内容还是太多 #我们
-
Apache下通过shell脚本提交网站404死链的方法
网站运营人员对于死链这个概念一定不陌生,网站的一些数据删除或页面改版等都容易制造死链,影响用户体验不说,过多的死链还会影响到网站的整体权重或排名. 百度站长平台提供的死链提交工具,可将网站存在的死链(协议死链.404页面)进行提交,可快速删除死链,帮助网站SEO优化.在提交死链的文件中逐个手动填写死链的话太麻烦,工作中我们提倡复杂自动化,所以本文我们一起交流分享Apache服务中通过shell脚本整理网站死链,便于我们提交. . 1.配置Apache记录搜索引擎 Apache是目前网站建设最为主
-
什么是Shell?Shell脚本基础知识详细介绍
Shell本身是一个用C语言编写的程序,它是用户使用Linux的桥梁.Shell既是一种命令语言,又是一种程序设计语言.作为命令语言,它交互式地解释和执行用户输入的命令:作为程序设计语言,它定义了各种变量和参数,并提供了许多在高级语言中才具有的控制结构,包括循环和分支. 它虽然不是Linux系统核心的一部分,但它调用了系统核心的大部分功能来执行程序.建立文件并以并行的方式协调各个程序的运行.因此,对于用户来说,shell是最重要的实用程序,深入了解和熟练掌握shell的特性极其使用方法,是用好L
-
Shell脚本实现把进程负载均衡到多核CPU中
有时候,由于架构设计或其他业务本身特点原因,导致有些应用使用CPU很不均衡,所以业务处理集中在一个CPU上,而其它CPU闲得在睡觉.这里有个简单的优化方案实现将各个线程绑定到到多个CPU,从而实现性能的提高. 虽然CPU是一个不错的思路,但是不是杀手锏,其性能能提高多少依赖于各个线程的性能分布是否均匀:所以最好的办法是优化你的程序架构. 在这里分享一个Shell脚本(脚本名为bindcpu2p.sh),通过该脚本可将该进程均匀负载到各个CPU上. 复制代码 代码如下: #!/bin/sh pid