JVM Tomcat性能实战(推荐)
本节只是介绍实战部分,具体的理论参数,请自行百度。
所需工具:linux服务器 Jmeter测试工具 xshell 一个web应用
Tomcat的JVM参数可以配置在catalina.sh,如果是在window上可以配置.bat文件
配置1:
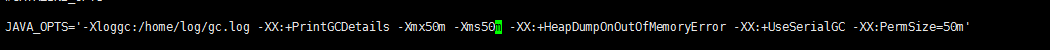
这里 我配置了一个gc日志路径为/home/log/gc.log ,打印gc的日志,初始堆和最大堆内存设置为50M,输出Dump文件在内存溢出的时候 ,使用串行垃圾收集器,永久代大小为50m。
将web应用放到对应的目录,配置好server.xml(这里不作配置介绍),sh start.sh启动tomcat.
使用压测工具(Jmeter)进行吞吐量的测试。没用过的同学可以上官网下载学习一下http://jmeter.apache.org/
建立用户组(10个线程,每个线程请求1000次),设置好Http请求的信息,生成一个聚合报告和一个gc日志
先来看一下gc日志吧:
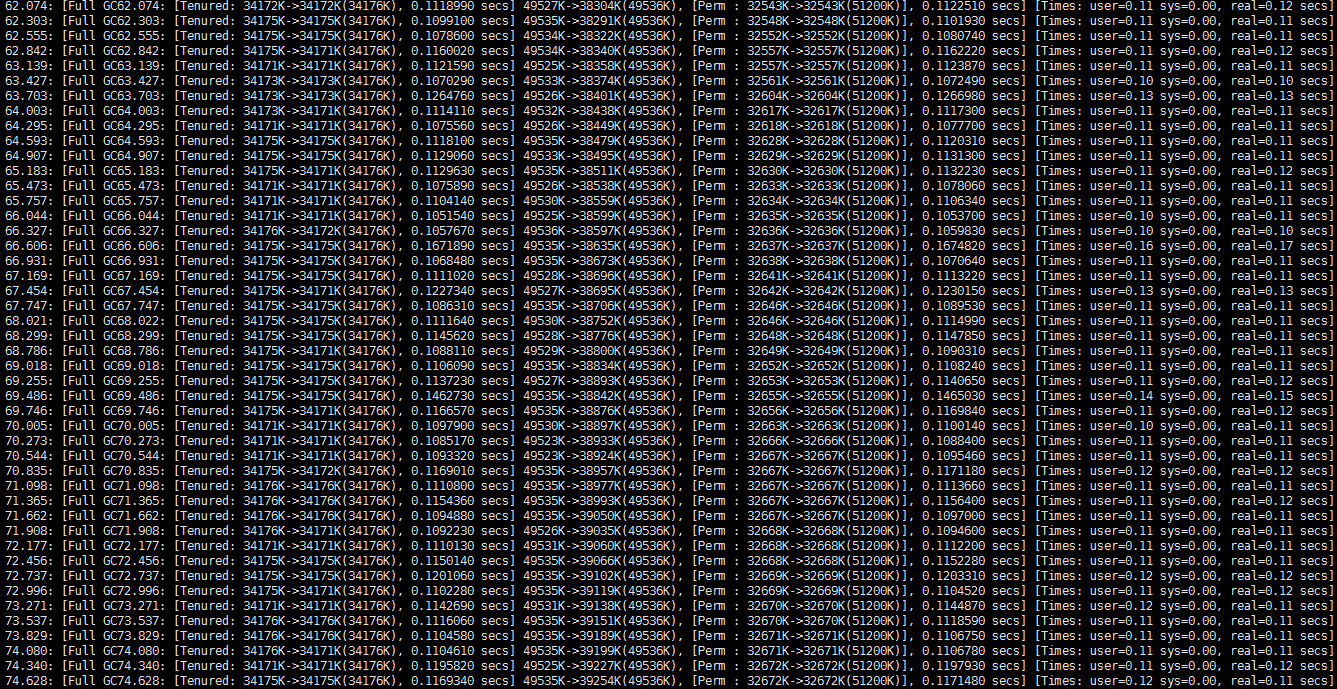
满屏幕的Full GC啊,最后查看聚合报告:

吞吐量维持在122.7每秒。从这个案例中我们可以看到老年代34176k基本已经满了,经过FUllGC之后新生代会有一点剩余的空间。总的来说Full GC的停顿时间是最长的,而且发生的这么频繁,显然这样的配置是不合理的。
配置2:

这次配置主要是增大了最大堆内存。以便虚拟机自动扩容,得到稳定的堆内存大小。

只需要关注一点 最大堆内存为82924k 80M左右,也就是说虚拟机对堆内存自动扩容到80M,并且稳定下来。这个配置测试只是为了找到一个稳定的堆内存,以便接下来的测试。
配置三:

设置堆的初始内存128m。
由配置2的结果可知,堆内存最终稳定在80m左右,因此小于80m的堆内存,很有可能会引起大量的GC反应,所以这里我把堆内存设置为128M,可以减少GC次数。

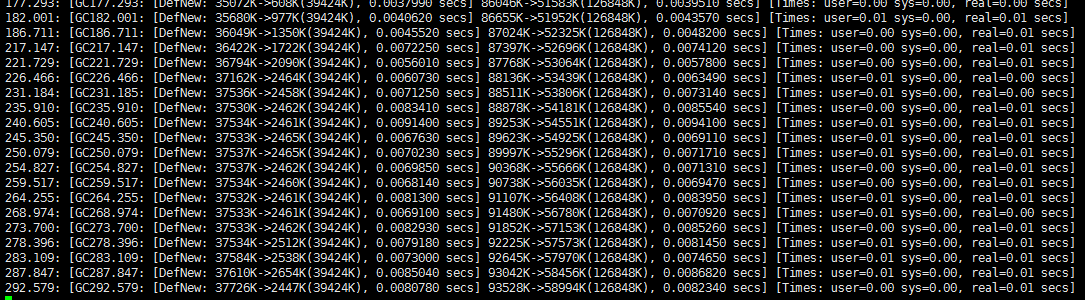
可以看到吞吐量略微有所提升,GC次数大量减少,并且GC的时间间隔变得更长。
配置四:

当前使用ParallalGC回收器,这是一个多线程并行回收器。

使用多线程并行的GC回收器吞吐量有略微有提升。(在没有GC压力的情况下,ParallalGC和serialGC对吞吐量影响不大。)
配置五:


配置六:
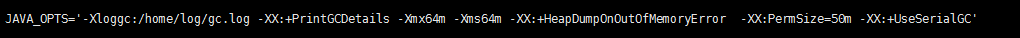

根据配置三的结论在80M以下的堆内存会发生频繁的GC,再结合配置四中得到的结论在有一定GC压力的时候,ParallelGC和serialGC的吞吐量会表现出一定的差异性。配置五和配置六的堆内存64M<80M ,会发生频繁的GC,采用不同的GC回收器的时候,理论上会在在吞吐量上有较大的差异性,但是我的实验为什么差距不是很大,到底为什么呢? 诶, 家里穷,我用的是单核的CPU,在单核的情况下ParallelGC改变性能并不明显。在单核或者并行能力较弱的情况下还是推荐使用serialGC。有条件的同学可以用多核的服务器试一下哦!
配置七:
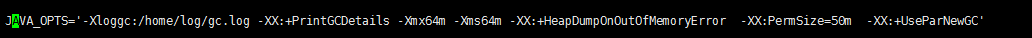
用ParNewGC试试,新生代使用ParNewGC回收,老年代依旧使用SerialGC回收。看看性能如何?

比全部使用串行回收器的性能好,但是比全部使用并行回收器的性能差些。
另外JDK版本的升级可能也会使得性能有一点的提升,但是JDK版本升级伴随着一定的风险,也许在新版本的JDK中引入某些未知的BUG.
最后我列出一些常用的JVM配置参数供参考:
1. 与串行回收期相关的参数
•-XX:+UseSerialGC:在新生代和老年代使用串行的收集器
•-XX:SurvivorRatio:设置eden区的大小和survivor区的比例
•-XX:PretenureSizeThreshold:设置大对象直接进入老年代的阀值。当对象的大小超过这个值,将直接在老年代分配
•-XX:MaxTenuringThreshold:设置对象进入老年代的年龄的最大值。每一次Minor GC后,对象年龄就加1.任何大于这个年龄的对象,一定会进入老年代。
2. 与并行GC相关的参数
•-XX:+UseParNewGC:在新生代使用并行收集器。
•-XX:+UseParallelOldGC:在老年代使用并行收集器
•-XX:+ParallelGCThreads:设置用于垃圾回收的线程数,通常可以设置成和CPU数相等。CPU数量较多的情况下,设置相对小的数值也可。
•-XX:+MaxGCPauseMillis:设置最大垃圾收集停顿时间。它的值是一个大于0的整数。收集器在工作时,会调整java堆的大小或其他的一些参数,尽可能把停顿时间控制在MaxGCPauseMillis以内。
•-XX:+UseAdaptiveSizePolicy:打开自适应GC策略,在这种模式下,新生代的大小和survivior的比例,晋升老年代的对象年龄等参数会被自动的调整,以达到堆大小,吞吐量和停顿之间的平衡点。
•-XX:+GCTimeRatio:设置吞吐量大小。它的值是一个0到100之间的证书。假设GCTimeRatio的值为n,那么系统将花费不超过1/(1+n)的时间用于垃圾收集。
3. 与CMS收集器相关的参数
•-XX:+UseConcMarkSweepGC:新生代使用并行收集器,老年代使用CMS+串行收集器。
•-XX:ParallelCMSThreads:设置CMS的线程数量。
•-XX:CMSInitiatingOccupancyFraction:设置CMS收集器在老年代空间被使用多少后触发,默认68%
•-XX:UseCMSCompactAtFullCollection:设置CMS在完成垃圾收集后是否要进行一次碎片整理
•-XX:CMSFullGCBeforeCompaction:设定进行多少次CMS垃圾回收后,进行一次内存压缩。
•-XX:+CMSClassUnloadingEnabled:允许对类元数据进行回收
•-XX:CMSInitiatingPermOccupancyFraction:当永久代占有率达到这一百分比时,启动CMS回收(前提是-XX:+CMSClassUnloadingEnabled被激活了)
•-XX:UseCMSInitiatingOccupancyOnly:表示只有在到达阀值的时候才进行CMS回收。
•-XX:+CMSIncrementalMode:使用增量模式,比较适合单CPU.增量模式在中标记为废弃,jdk9中将彻底移除
4. 与G1回收期相关的参数
•-XX:+UseG1GC:使用G1回收器
•-XX:+MaxGCPauseMillis:设置最大的垃圾收集停顿时间
•-XX:+GcPauseIntervalMillis:设置停顿时间间隔。
5. TLAB相关
•-XX:+UseTLAB:开启TLAB分配。
•-XX:+PrintTLAB:打印TLAB相关分配信息
•-XX:TLABSize:设置TLAB大小
•-XX:+ResizeTLAB:自动调整TLAB大小
6. 其他一些参数
•-XX:+DisableExplicitGC:禁用显式GC
•-XX:+ExplicitGCInvokesConcurrent:使用并发方式处理显式GC
以上这篇JVM Tomcat性能实战(推荐)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
tomcat性能优化(性能总览)
1.增加JVM堆内存大小 1)JVM通常不去调用垃圾回收器,所以服务器可以更多关注处理web请求,并要求尽快完成. 2)更改文件(catalina.sh) JAVA_OPTS="-Djava.awt.headless=true -Dfile.encoding=UTF-8 -server -Xms1024m -Xmx1024m -XX:NewSize=512m -XX:MaxNewSize=512m -XX:PermSize=512m -XX:MaxPermSize=512m -XX:+Disab
-

JVM Tomcat性能实战(推荐)
本节只是介绍实战部分,具体的理论参数,请自行百度. 所需工具:linux服务器 Jmeter测试工具 xshell 一个web应用 Tomcat的JVM参数可以配置在catalina.sh,如果是在window上可以配置.bat文件 配置1: 这里 我配置了一个gc日志路径为/home/log/gc.log ,打印gc的日志,初始堆和最大堆内存设置为50M,输出Dump文件在内存溢出的时候 ,使用串行垃圾收集器,永久代大小为50m. 将web应用放到对应的目录,配置好server.xml
-
JavaScript 总结几个提高性能知识点(推荐)
前段时间花时间看了大半的<High Performance JavaScript>这本书啊,然后就开始忙项目了,庆幸最忙的一周已经熬过去了.由于空不出时间,这个月写的学习笔记也不多,忙完最苦X的一周,这两天晚上也算是挑灯夜读了...终于是在残血之际将这本书shut down了... 既然读完了,总归是要学到些什么的.说说对这本书的看法先吧,整体的来说,内容还是不错的,就是感觉有点老了(作为前端小白,也可能是自身水平有限,未能体会到其中真意).看这本书的过程中也是写了挺多代码用以测试的,并且对本
-
JVM上高性能数据格式库包Apache Arrow入门和架构详解(Gkatziouras)
Apache Arrow是是各种大数据工具(包括BigQuery)使用的一种流行格式,它是平面和分层数据的存储格式.它是一种加快应用程序内存密集型. 数据处理和数据科学领域中的常用库: Apache Arrow.诸如Apache Parquet,Apache Spark,pandas之类的开放源代码项目以及许多商业或封闭源代码服务都使用Arrow.它提供以下功能: 内存计算 标准化的柱状存储格式 一个IPC和RPC框架,分别用于进程和节点之间的数据交换 让我们看一看在Arrow出现之前事物是如何
-
tomcat性能优化方式简单整理
Tomcat本身优化 Tomcat内存优化 启动时告诉JVM我要一块大内存(调优内存是最直接的方式) 我们可以在 tomcat 的启动脚本 catalina.sh 中设置 java_OPTS 参数 JAVA_OPTS参数说明 server 启用jdk 的 server 版 Xms java虚拟机初始化时的最小内存 Xmx java虚拟机可使用的最大内存 XX: PermSize 内存永久保留区域 XX:MaxPermSize 内存最大永久保留区域 配置示例: JAVA_OPTS='-Xms102
-
IIS6+TOMCAT整合,实战实例!
搞定了IIS6和Tomcat的整合.现在把步骤贴出来给各位一点参考,也免去了新手在Google上暴走和一次次的调试.开始吧! 首先先说明我的系统,Windows 2003 Server中文版+IIS6+Tomcat5.5.17,JDK 1.5安装目录为D:\JDK1.5,Tomcat安装目录为D:\Tomcat5.5, 环境变量JAVA_HOME和TOMCAT_HOME都已设置好并指向其各自的安装目录.(注意,接下来所有文件中涉及到tomcat路径的请自行修改为自己的Tomcat路径)
-
tomcat性能优化之如何搭建Apr模块
前言 tomcat是一个被广泛使用的java web容器,各种调优数不胜数,由于tomcat主要运行jsp等动态页面,所以其设计主要是针对动态页面进行优化,而对静态文件的处理效率并不高. 很多时候工程师更愿意使用nginx或者apache服务器来辅助tomcat处理静态文件来提高服务器运行效率,但其实tomcat本身可以调用apache的方法来处理静态文件,极大的提高处理效率. tomcat服务器的三种模式bio (消息阻塞模式),nio(非阻塞模式) ,apr(使用apache静态文件处理库处
-
33个Python爬虫项目实战(推荐)
今天为大家整理了32个Python爬虫项目. 整理的原因是,爬虫入门简单快速,也非常适合新入门的小伙伴培养信心.所有链接指向GitHub,祝大家玩的愉快~O(∩_∩)O WechatSogou [1]- 微信公众号爬虫.基于搜狗微信搜索的微信公众号爬虫接口,可以扩展成基于搜狗搜索的爬虫,返回结果是列表,每一项均是公众号具体信息字典. DouBanSpider [2]- 豆瓣读书爬虫.可以爬下豆瓣读书标签下的所有图书,按评分排名依次存储,存储到Excel中,可方便大家筛选搜罗,比如筛选评价人数>1
-
Java虚拟机JVM性能优化(一):JVM知识总结
Java应用程序是运行在JVM上的,但是你对JVM技术了解吗?这篇文章(这个系列的第一部分)讲述了经典Java虚拟机是怎么样工作的,例如:Java一次编写的利弊,跨平台引擎,垃圾回收基础知识,经典的GC算法和编译优化.之后的文章会讲JVM性能优化,包括最新的JVM设计--支持当今高并发Java应用的性能和扩展. 如果你是一个开发人员,你肯定遇到过这样的特殊感觉,你突然灵光一现,所有的思路连接起来了,你能以一个新的视角来回想起你以前的想法.我个人很喜欢学习新知识带来的这种感觉.我已经有过很多次这样
-
深入解析JVM之内存结构及字符串常量池(推荐)
前言 Java作为一种平台无关性的语言,其主要依靠于Java虚拟机--JVM,我们写好的代码会被编译成class文件,再由JVM进行加载.解析.执行,而JVM有统一的规范,所以我们不需要像C++那样需要程序员自己关注平台,大大方便了我们的开发.另外,能够运行在JVM上的并只有Java,只要能够编译生成合乎规范的class文件的语言都是可以跑在JVM上的.而作为一名Java开发,JVM是我们必须要学习了解的基础,也是通向高级及更高层次的必修课:但JVM的体系非常庞大,且术语非常多,所以初学者对此非