正则表达式性能优化方法(高效正则表达式书写)
这里说的正则表达式优化,主要是针对目前常用的NFA模式正则表达式,详细可以参考:正则表达式匹配解析过程探讨分析(正则表达式匹配原理)。从上面例子,我们可以推断出,影响NFA类正则表达式(常见语言:GNU Emacs,Java,ergp,less,more,.NET语言,
PCRE library,Perl,PHP,Python,Ruby,sed,vi )其实主要是它的“回溯”,减少“回溯”次数(减少循环查找同一个字符次数),是提高性能的主要方法。 我们来看个例子:
源字符串:<script type="text/javascript">adsfadfsdasfsdafdsfsadfsa</script>
匹配要求,匹配<script….>….</script>标签里面所有内容,包括改标签
常见写法(1),因为<script后面可能出现字符、空白、特殊符号等,还有标签里面也可能出现各种js代码。我们简单方法是:
正则表达式:<script.*?>.*?</script> (测试工具使用了:regexBuddy)
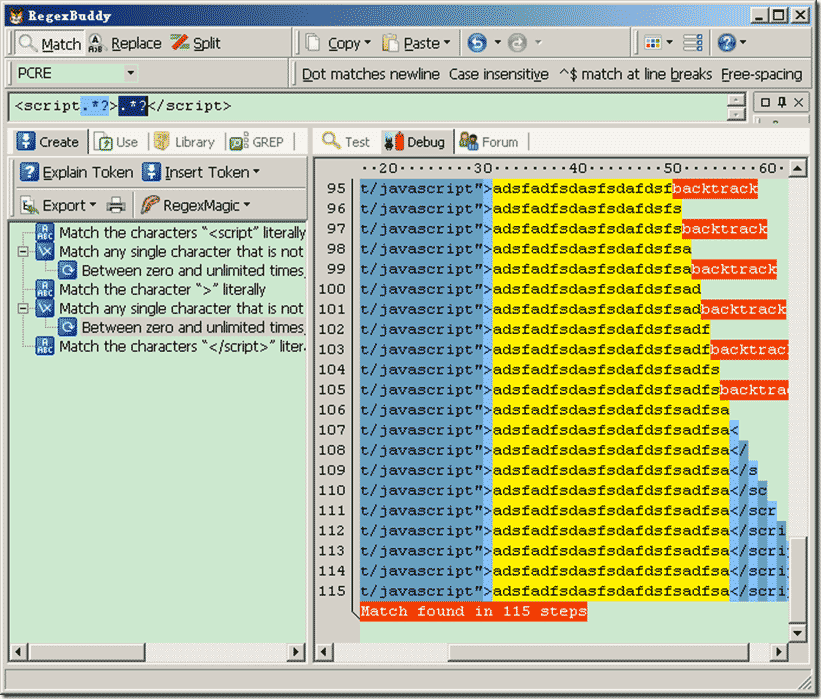
总共花费115步,回溯了:48次。 因为我们使用”.”字符,匹配默认情况下除了\n之外所有字符。
方法(2),我们分析特点发现,<script…>后面,应该是除了”>”之外都可以字符,然后一对<script>标签里面js内容。可以定义为除了”<”之外。(这里面我只是举例说明优化方法,实际网页中script标签里面,常见都会出现有”<”字符了)
正则表达式:<script[^?>]+>[^<]+</script>
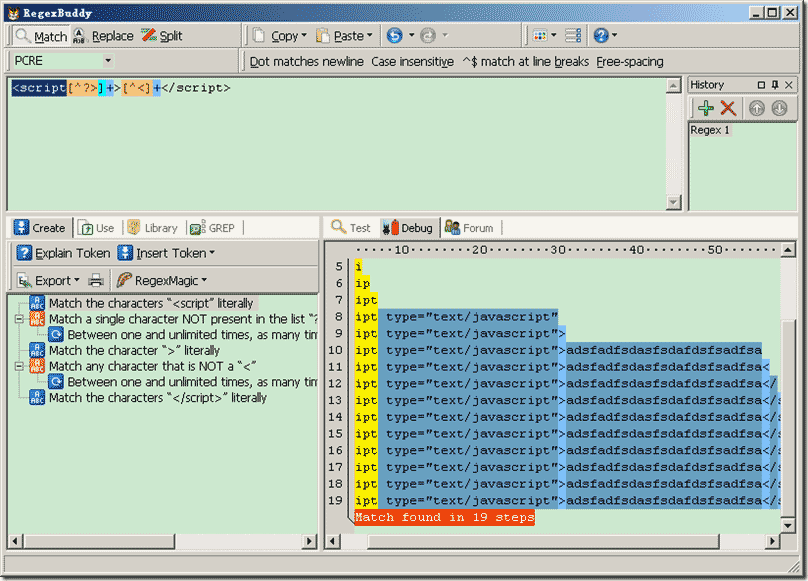
19步,0次回溯! ,步骤只有原先的15%左右,性能几倍的提升了!
从上面我们看到,不同正则表达式,对通用字符配平,性能相差会很大。减少“回溯”是最好的方法,减少回溯其中最主要的方法是:”用最小范围的元字符,尽量避免用过大的元字符!”。一般规律如下:
1、使用正确的边界匹配器(^、$、\b、\B等),限定搜索字符串位置
2、使用具体的元字符、字符类(\d、\w、\s等) ,少用”.”字符
3、使用正确的量词(+、*、?、{n,m}),如果能够限定长度,匹配最佳
4、使用非捕获组、原子组,减少没有必要的字匹配捕获用(?:)
如:我想匹配一些英文字母,它后面接的是数字。如:abc1234,我可以写 “\w+\d+”,也可以写”[a-zA-Z]+\d+” ,其中第一个\w+会先匹配所有abc1234,然后回溯,匹配满足\d+格式。一共4步,而后面这个只需要2步,步骤减少一半了!好了,今天就先到这里,欢迎大家讨论、交流!
相关推荐
-

正则表达式性能优化方法(高效正则表达式书写)
这里说的正则表达式优化,主要是针对目前常用的NFA模式正则表达式,详细可以参考:正则表达式匹配解析过程探讨分析(正则表达式匹配原理).从上面例子,我们可以推断出,影响NFA类正则表达式(常见语言:GNU Emacs,Java,ergp,less,more,.NET语言, PCRE library,Perl,PHP,Python,Ruby,sed,vi )其实主要是它的"回溯",减少"回溯"次数(减少循环查找同一个字符次数),是提高性能的主要方法. 我们来看个例子:
-
React 性能优化方法总结
目录 前言 为什么页面会出现卡顿的现象? React 到底是在哪里出现了卡顿? React 有哪些场景会需要性能优化? 一:父组件刷新,而不波及子组件. 第一种:使用 PureComponent 第三种:函数组件如何判断props的变化的更新呢? 使用 React.memo函数 使用 React.useMemo来实现对子组件的缓冲 一:组件自己控制自己是否刷新 三:减少波及范围,无关刷新数据不存入state中 场景一:无意义重复调用setState,合并相关的state 场景二:和页面刷新没有相
-
SQL性能优化方法及性能测试
目录 笛卡尔连接 分页limit的sql优化的几种方法 count 优化方案 笛卡尔连接 例1: 没有携带on的条件字句,此条slq查询的结构集等价于,a表包含的条数*b表包含的乘积: select * from table a cross join table b; 例2:拥有携带on字句的sql,等价于inner join: select * from table a cross join table b on a.id=b.id; 分页limit的sql优化的几种方法 规则;表包含的数据较
-
MySQL Index Condition Pushdown(ICP)性能优化方法实例
一 概念介绍 Index Condition Pushdown (ICP)是MySQL 5.6 版本中的新特性,是一种在存储引擎层使用索引过滤数据的一种优化方式. a 当关闭ICP时,index 仅仅是data access 的一种访问方式,存储引擎通过索引回表获取的数据会传递到MySQL Server 层进行where条件过滤. b 当打开ICP时,如果部分where条件能使用索引中的字段,MySQL Server 会把这部分下推到引擎层,可以利用index过滤的where条件在存储引擎层进行
-
Android性能优化方法
GPU过度绘制 •打开开发者选型,"调试GPU过度绘制",蓝.绿.粉红.红,过度绘制依次加深 •粉红色尽量优化,界面尽量保持蓝绿颜色 •红色肯定是有问题的,不能忍受 使用HierarchyView分析布局层级 •删除多个全屏背景:应用中不可见的背景,将其删除掉 •优化ImageView:对于先绘制了一个背景,然后在其上绘制了图片的,9-patch格式的背景图中间拉伸部分设置为透明的,Android 2D渲染引擎会优化9-patch图中的透明像素.这个简单的修改可以消除头像上的过度
-
django_orm查询性能优化方法
查询操作和性能优化 1.基本操作 增 models.Tb1.objects.create(c1='xx', c2='oo') 增加一条数据,可以接受字典类型数据 **kwargs obj = models.Tb1(c1='xx', c2='oo') obj.save() 查 models.Tb1.objects.get(id=123) # 获取单条数据,不存在则报错(不建议) models.Tb1.objects.all() # 获取全部 models.Tb1.objects.filter(na
-
iOS开发中UITableview控件的基本使用及性能优化方法
UITableview控件基本使用 一.一个简单的英雄展示程序 NJHero.h文件代码(字典转模型) 复制代码 代码如下: #import <Foundation/Foundation.h> @interface NJHero : NSObject /** * 头像 */ @property (nonatomic, copy) NSString *icon; /** * 名称 */ @property (nonatomic, copy) NSString *name; /**
-
MySQL延迟关联性能优化方法
[背景] 某业务数据库load 报警异常,cpu usr 达到30-40 ,居高不下.使用工具查看数据库正在执行的sql ,排在前面的大部分是: 复制代码 代码如下: SELECT id, cu_id, name, info, biz_type, gmt_create, gmt_modified,start_time, end_time, market_type, back_leaf_category,item_status,picuture_url FROM relation where bi
-
数据库中identity字段不必是系统产生的唯一值 性能优化方法(新招)
但是,具有identity特性的字段,不需要具有唯一性,更不必须是主键. 可以通过,set identity_insert tablename (on|off),在运行时控制,是否可以在identity字段中指定值,而不是由系统自动的插入值. 那么,这有什么用处呢.举个例子来说,两个用户之间的聊天,可以有多次,这个用一个chatsession来表示.在数据库中,我们需要三个表: user, chatsession(sessionid identity,...), user_chatsession
-
Wins2003系统中Apache性能优化方法
为了满足网站高负荷的要求,在调整Apache参数时发现进程经常占用内存过多导致当机.经过不断的优化和修改参数组合,终于让服务器稳定 下来,可以满足大量访问的考验和应用要求.笔者总结了调试过程中的问题和解决办法如下,以供有类似需求的网管员参考(系统环境为Windows Server 2003和apache2.2.8): 1.http-mpm.conf设置 Apache的线程数控制文件为http-mpm.conf,在conf/exrtra目录下面,要使该配置文件起作用需要在httpd.conf 中将