PID原理与python的简单实现和调参
目录
- 一、前言
- 二、PID控制算法详解
- 2.1 比例控制算法
- 2.1.1 比例控制python简单示意
- 2.1.2 比例控制存在的一些问题
- 2.2 积分控制算法(消除稳态误差)
- 2.2.1 python简单实现
- 2.3 微分控制算法(减少控制中的震荡)
- 3.3.1 加入微分控制算法的python简单示意
- 2.4 PID算法总结
- 三、牛顿法调参
一、前言
近期在实际项目中使用到了PID控制算法,于是就该算法做一总结。
二、PID控制算法详解
2.1 比例控制算法
例子: 假设一个水缸,需要最终控制水缸的水位永远维持在1米的高度。
水位目标:T 当前水位:Tn 加水量:U 误差:error error=T-Tn 比例控制系数:kp U = k_p * errorU=kp∗error initial: T=1; Tn=0.2, error=1-0.2=0.8; kp=0.4
2.1.1 比例控制python简单示意
T=1
Tn=0.2
error=1-0.2
kp=0.4
for t in range(1, 10):
U = kp * error
Tn += U
error = T-Tn
print(f't={t} | add {U:.5f} => Tn={Tn:.5f} error={error:.5f}')
"""
t=1 | add 0.32000 => Tn=0.52000 error=0.48000
t=2 | add 0.19200 => Tn=0.71200 error=0.28800
t=3 | add 0.11520 => Tn=0.82720 error=0.17280
t=4 | add 0.06912 => Tn=0.89632 error=0.10368
t=5 | add 0.04147 => Tn=0.93779 error=0.06221
t=6 | add 0.02488 => Tn=0.96268 error=0.03732
t=7 | add 0.01493 => Tn=0.97761 error=0.02239
t=8 | add 0.00896 => Tn=0.98656 error=0.01344
t=9 | add 0.00537 => Tn=0.99194 error=0.00806
"""
2.1.2 比例控制存在的一些问题
根据kp取值不同,系统最后都会达到1米,只不过kp大了达到的更快。不会有稳态误差。 若存在漏水情况,在相同情况下,经过多次加水后,水位会保持在0.75不在再变化,因为当U和漏水量一致的时候将保持不变——即稳态误差 U=k_p*error=0.1 => error = 0.1/0.4 = 0.25U=kp∗error=0.1=>error=0.1/0.4=0.25,所以误差永远保持在0.25
T=1
Tn=0.2
error=1-0.2
kp=0.4
extra_drop = 0.1
for t in range(1, 100):
U = kp * error
Tn += U - extra_drop
error = T-Tn
print(f't={t} | add {U:.5f} => Tn={Tn:.5f} error={error:.5f}')
"""
t=95 | add 0.10000 => Tn=0.75000 error=0.25000
t=96 | add 0.10000 => Tn=0.75000 error=0.25000
t=97 | add 0.10000 => Tn=0.75000 error=0.25000
t=98 | add 0.10000 => Tn=0.75000 error=0.25000
t=99 | add 0.10000 => Tn=0.75000 error=0.25000
"""
实际情况中,这种类似水缸漏水的情况往往更加常见
- 比如控制汽车运动,摩擦阻力就相当于是"漏水"
- 控制机械臂、无人机的飞行,各类阻力和消耗相当于"漏水"
所以单独的比例控制,很多时候并不能满足要求
2.2 积分控制算法(消除稳态误差)
比例+积分控制算法: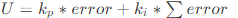
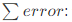 误差累计
误差累计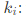 积分控制系数
积分控制系数
2.2.1 python简单实现
T=1
Tn=0.2
error=1-0.2
kp=0.4
extra_drop = 0.1
ki=0.2
sum_error = 0
for t in range(1, 20):
sum_error += error
U = kp * error + ki * sum_error
Tn += U - extra_drop
error = T-Tn
print(f't={t} | add {U:.5f} => Tn={Tn:.5f} error={error:.5f}')
"""
t=14 | add 0.10930 => Tn=0.97665 error=0.02335
t=15 | add 0.11025 => Tn=0.98690 error=0.01310
t=16 | add 0.10877 => Tn=0.99567 error=0.00433
t=17 | add 0.10613 => Tn=1.00180 error=-0.00180
t=18 | add 0.10332 => Tn=1.00512 error=-0.00512
t=19 | add 0.10097 => Tn=1.00608 error=-0.00608
"""
2.3 微分控制算法(减少控制中的震荡)
在越靠近目标的时候则加的越少。 
- kd: 微分控制系数
- d_error/d_t ~= error_t - error_t_1:误差的变化
3.3.1 加入微分控制算法的python简单示意
令:kd=0.2; d_error = 当前时刻误差-前时刻误差
T=1
Tn=0.2
error=1-0.2
kp=0.4
extra_drop = 0.1
ki=0.2
sum_error = 0
kd=0.2
d_error = 0
error_n = 0
error_b = 0
for t in range(1, 20):
error_b = error_n
error_n = error
# print(error_b1, error_b2)
d_error = error_n - error_b if t >= 2 else 0
sum_error += error
U = kp * error + ki * sum_error + kd * d_error
Tn += U - extra_drop
error = T-Tn
print(f't={t} | add {U:.5f} => Tn={Tn:.5f} error={error:.5f} | d_error: {d_error:.5f}')
"""
t=14 | add 0.09690 => Tn=0.96053 error=0.03947 | d_error: 0.01319
t=15 | add 0.10402 => Tn=0.96455 error=0.03545 | d_error: 0.00310
t=16 | add 0.10808 => Tn=0.97263 error=0.02737 | d_error: -0.00402
t=17 | add 0.10951 => Tn=0.98214 error=0.01786 | d_error: -0.00808
t=18 | add 0.10899 => Tn=0.99113 error=0.00887 | d_error: -0.00951
t=19 | add 0.10727 => Tn=0.99840 error=0.00160 | d_error: -0.00899
"""
2.4 PID算法总结


for kp_i in np.linspace(0, 1, 10): pid_plot(kp=kp_i, ki=0.2, kd=0.2)
for ki_i in np.linspace(0, 1, 10): pid_plot(kp=0.5, ki=ki_i, kd=0.2)
for kd_i in np.linspace(0, 1, 10): pid_plot(kp=0.5, ki=0.2, kd=kd_i)
pid_plot(kp=0.65, ki=0.05, kd=0.5, print_flag=True)
三、牛顿法调参
损失函数采用:RMSE
from scipy import optimize
import matplotlib.pyplot as plt
import numpy as np
def pid_plot(args, plot_flag=True, print_flag=False):
kp, ki, kd = args
T=1
Tn=0.2
error=1-0.2
extra_drop = 0.1
sum_error = 0
d_error = 0
error_n = 0
error_b = 0
Tn_list = []
for t in range(1, 100):
error_b = error_n
error_n = error
d_error = error_n - error_b if t >= 2 else 0
sum_error += error
U = kp * error + ki * sum_error + kd * d_error
Tn += U - extra_drop
error = T-Tn
Tn_list.append(Tn)
if print_flag:
print(f't={t} | add {U:.5f} => Tn={Tn:.5f} error={error:.5f} | d_error: {d_error:.5f}')
if plot_flag:
plt.plot(Tn_list)
plt.axhline(1, linestyle='--', color='darkred', alpha=0.8)
plt.title(f'$K_p$={kp:.3f} $K_i$={ki:.3f} $K_d$={kd:.3f}')
plt.ylim([0, max(Tn_list) + 0.2])
plt.show()
loss = np.sqrt(np.mean(np.square(np.ones_like(Tn_list) - np.array(Tn_list))))
return loss
boundaries=[(0, 2), (0, 2), (0, 2)]
res = optimize.fmin_l_bfgs_b(pid_plot, np.array([0.1, 0.1, 0.1]), args=(False, False), bounds = boundaries, approx_grad = True)
pid_plot(res[0].tolist(), print_flag=True)
pid_plot([0.65, 0.05, 0.5], print_flag=True)
牛顿法调参结果图示 :
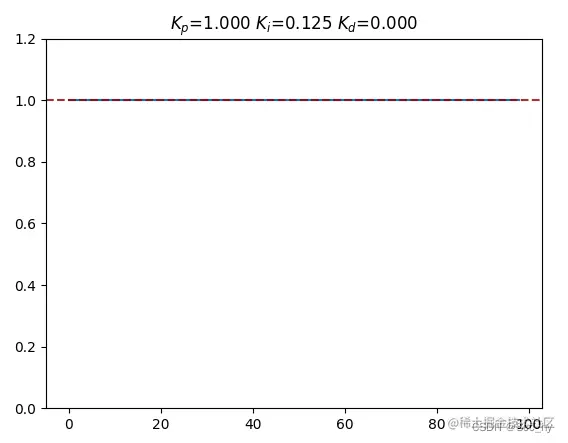
简单手动调参图示:
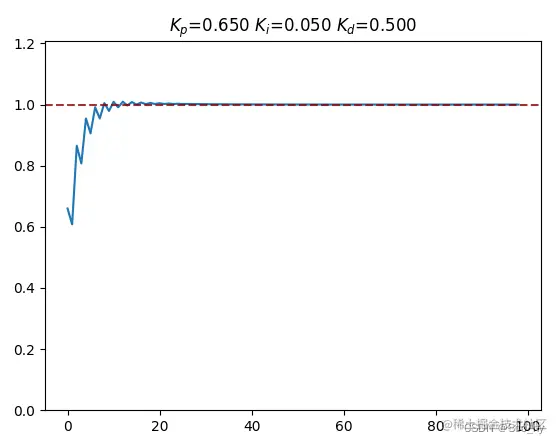
到此这篇关于PID原理与python的简单实现和调参的文章就介绍到这了,更多相关PID与python内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python中Pyspider爬虫框架的基本使用详解
1.pyspider介绍 一个国人编写的强大的网络爬虫系统并带有强大的WebUI.采用Python语言编写,分布式架构,支持多种数据库后端,强大的WebUI支持脚本编辑器,任务监视器,项目管理器以及结果查看器. 用Python编写脚本 功能强大的WebUI,包含脚本编辑器,任务监视器,项目管理器和结果查看器 MySQL,MongoDB,Redis,SQLite,Elasticsearch; PostgreSQL与SQLAlchemy作为数据库后端 RabbitMQ,Beanstalk,Redis
-
Python中rapidjson参数校验实现
目录 前言 rapidjson简介和安装 rapidjson基本使用 dumps() 方法 skipkeys ensure_ascii sort_keys dump()方法 Validator class 前言 在使用Django框架开发前后端分离的项目时,通常需要对前端传递过来的参数进行校验,校验的方式有多种,可以使用drf进行校验,也可以使用json进行校验,本文介绍在Python中rapidjson的基本使用以及如何进行参数校验. rapidjson简介和安装 rapidjson是一个性能
-
Python爬虫之Spider类用法简单介绍
一.网络爬虫 网络爬虫又被称为网络蜘蛛(
-
Python爬虫Scrapy框架CrawlSpider原理及使用案例
提问:如果想要通过爬虫程序去爬取"糗百"全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬去进行实现的(Request模块回调) 方法二:基于CrawlSpider的自动爬去进行实现(更加简洁和高效) 一.简单介绍CrawlSpider CrawlSpider其实是Spider的一个子类,除了继承到Spider的特性和功能外,还派生除了其自己独有的更加强大的特性和功能.其中最显著的功能就是"LinkExtractors链接提取器&qu
-
Python如何获取pid和进程名字
目录 Python获取pid和进程名字 1.安装psutil 2.获取信息代码 Python 自定义进程名 安装方法 Python获取pid和进程名字 1.安装psutil pip install psutil 如果pip不识别,就进入下载的python目录下面执行:...Python36\Scripts 2.获取信息代码 import psutil; for proc in psutil.process_iter(): print("pid-%d,name:%s" % (proc.p
-
python爬虫scrapy基于CrawlSpider类的全站数据爬取示例解析
一.CrawlSpider类介绍 1.1 引入 使用scrapy框架进行全站数据爬取可以基于Spider类,也可以使用接下来用到的CrawlSpider类.基于Spider类的全站数据爬取之前举过栗子,感兴趣的可以康康 scrapy基于CrawlSpider类的全站数据爬取 1.2 介绍和使用 1.2.1 介绍 CrawlSpider是Spider的一个子类,因此CrawlSpider除了继承Spider的特性和功能外,还有自己特有的功能,主要用到的是 LinkExtractor()和rules
-
python scrapy项目下spiders内多个爬虫同时运行的实现
一般创建了scrapy文件夹后,可能需要写多个爬虫,如果想让它们同时运行而不是顺次运行的话,得怎么做? a.在spiders目录的同级目录下创建一个commands目录,并在该目录中创建一个crawlall.py,将scrapy源代码里的commands文件夹里的crawl.py源码复制过来,只修改run()方法即可! import os from scrapy.commands import ScrapyCommand from scrapy.utils.conf import arglist
-
python scrapy拆解查看Spider类爬取优设网极细讲解
目录 拆解 scrapy.Spider scrapy.Spider 属性值 scrapy.Spider 实例方法与类方法 爬取优设网 Field 字段的两个参数: 拆解 scrapy.Spider 本次采集的目标站点为:优设网 每次创建一个 spider 文件之后,都会默认生成如下代码: import scrapy class UiSpider(scrapy.Spider): name = 'ui' allowed_domains = ['www.uisdc.com'] start_urls =
-
Python爬虫框架之Scrapy中Spider的用法
Spider类定义了如何爬取某个(或某些)网站.包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item).换句话说,Spider就是您定义爬取的动作及分析某个网页(或者是有些网页)的地方. 对spider来说,爬取的循环类似下文: 1.以初始的URL初始化Request,并设置回调函数.当该request下载完毕并返回时,将生成response,并作为参数传给该回调函数.spider中初始的request是通过调用start_requests()来获取的.sta
-
PID原理与python的简单实现和调参
目录 一.前言 二.PID控制算法详解 2.1 比例控制算法 2.1.1 比例控制python简单示意 2.1.2 比例控制存在的一些问题 2.2 积分控制算法(消除稳态误差) 2.2.1 python简单实现 2.3 微分控制算法(减少控制中的震荡) 3.3.1 加入微分控制算法的python简单示意 2.4 PID算法总结 三.牛顿法调参 一.前言 近期在实际项目中使用到了PID控制算法,于是就该算法做一总结. 二.PID控制算法详解 2.1 比例控制算法 例子: 假设一个水缸,需要最终控制
-
Python实现简单的"导弹" 自动追踪原理解析
自动追踪算法,在我们设计2D射击类游戏时经常会用到,这个听起来很高大上的东西,其实也并不是军事学的专利,在数学上解决的话需要去解微分方程, 这个没有点数学基础是很难算出来的.但是我们有了计算机就不一样了,依靠计算机极快速的运算速度,我们利用微分的思想,加上一点简单的三角学知识,就可以实现它. 好,话不多说,我们来看看它的算法原理,看图: 由于待会要用pygame演示,他的坐标系是y轴向下,所以这里我们也用y向下的坐标系. 算法总的思想就是根据上图,把时间t分割成足够小的片段(比如1/1000,这
-
使用Python实现简单的服务器功能
socket接口是实际上是操作系统提供的系统调用.socket的使用并不局限于Python语言,你可以用C或者Java来写出同样的socket服务器,而所有语言使用socket的方式都类似(Apache就是使用C实现的服务器) Web框架就是提前写好了服务器.不能跨语言的使用框架.框架的好处在于帮你处理了一些细节,从而实现快速开发,但同时受到python本身性能的限制.我们已经看到,许多成功的网站都是利用动态语言(比如Python, Ruby或者PHP,比如twitter和facebook)快速
-
python实现简单的单变量线性回归方法
线性回归是机器学习中的基础算法之一,属于监督学习中的回归问题,算法的关键在于如何最小化代价函数,通常使用梯度下降或者正规方程(最小二乘法),在这里对算法原理不过多赘述,建议看吴恩达发布在斯坦福大学上的课程进行入门学习. 这里主要使用python的sklearn实现一个简单的单变量线性回归. sklearn对机器学习方法封装的十分好,基本使用fit,predict,score,来训练,预测,评价模型, 一个简单的事例如下: from pandas import DataFrame from pan
-
Python实现简单的文本相似度分析操作详解
本文实例讲述了Python实现简单的文本相似度分析操作.分享给大家供大家参考,具体如下: 学习目标: 1.利用gensim包分析文档相似度 2.使用jieba进行中文分词 3.了解TF-IDF模型 环境: Python 3.6.0 |Anaconda 4.3.1 (64-bit) 工具: jupyter notebook 注:为了简化问题,本文没有剔除停用词"stop-word".实际应用中应该要剔除停用词. 首先引入分词API库jieba.文本相似度库gensim import ji
-
机器学习之KNN算法原理及Python实现方法详解
本文实例讲述了机器学习之KNN算法原理及Python实现方法.分享给大家供大家参考,具体如下: 文中代码出自<机器学习实战>CH02,可参考本站: 机器学习实战 (Peter Harrington著) 中文版 机器学习实战 (Peter Harrington著) 英文原版 [附源代码] KNN算法介绍 KNN是一种监督学习算法,通过计算新数据与训练数据特征值之间的距离,然后选取K(K>=1)个距离最近的邻居进行分类判(投票法)或者回归.若K=1,新数据被简单分配给其近邻的类. KNN算法
-
python实现简单图片物体标注工具
本文实例为大家分享了python实现简单图片物体标注工具的具体代码,供大家参考,具体内容如下 # coding: utf-8 """ 物体检测标注小工具 基本思路: 对要标注的图像建立一个窗口循环,然后每次循环的时候对图像进行一次复制, 鼠标在画面上画框的操作.画好的框的相关信息在全局变量中保存, 并且在每个循环中根据这些信息,在复制的图像上重新画一遍,然后显示这份复制的图像. 简化的设计过程: 1.输入是一个文件夹的路径,包含了所需标注物体框的图片. 如果图片中标注了物体,
-
朴素贝叶斯分类算法原理与Python实现与使用方法案例
本文实例讲述了朴素贝叶斯分类算法原理与Python实现与使用方法.分享给大家供大家参考,具体如下: 朴素贝叶斯分类算法 1.朴素贝叶斯分类算法原理 1.1.概述 贝叶斯分类算法是一大类分类算法的总称 贝叶斯分类算法以样本可能属于某类的概率来作为分类依据 朴素贝叶斯分类算法是贝叶斯分类算法中最简单的一种 注:朴素的意思是条件概率独立性 P(A|x1x2x3x4)=p(A|x1)*p(A|x2)p(A|x3)p(A|x4)则为条件概率独立 P(xy|z)=p(xyz)/p(z)=p(xz)/p(z)
-
python实现简单的学生管理系统
本文实例为大家分享了python实现简单学生管理系统的具体代码,供大家参考,具体内容如下 学生管理系统 相信大家学各种语言的时候,练习总是会写各种管理系统吧,管理系统主要有对数据的增删查改操作,原理不难,适合作为练手的小程序 数据的结构 要保存数据就需要数据结构,比如c里面的结构体啊,python里面的列表,字典,还有类都是常用的数据类型 在这里,我使用了链表来作为学生数据的数据结构, 即 Node类 和 Student_LinkList类,来实现链表 数据的持久化 我们在程序中产生的数据是保存
-
详解Bagging算法的原理及Python实现
目录 一.什么是集成学习 二.Bagging算法 三.Bagging用于分类 四.Bagging用于回归 一.什么是集成学习 集成学习是一种技术框架,它本身不是一个单独的机器学习算法,而是通过构建并结合多个机器学习器来完成学习任务,一般结构是:先产生一组"个体学习器",再用某种策略将它们结合起来,目前,有三种常见的集成学习框架(策略):bagging,boosting和stacking 也就是说,集成学习有两个主要的问题需要解决,第一是如何得到若干个个体学习器,第二是如何选择一种结合策