Python pandas中apply函数简介以及用法详解
目录
- 1.基本信息
- 2.语法结构
- 3.使用案例
- 3.1 DataFrame使用apply
- 3.2 Series使用apply
- 3.3 其他案例
- 4.总结
- 参考链接:
1.基本信息
Pandas 的 apply() 方法是用来调用一个函数(Python method),让此函数对数据对象进行批量处理。Pandas 的很多对象都可以使用 apply() 来调用函数,如 Dataframe、Series、分组对象、各种时间序列等。
2.语法结构
apply() 使用时,通常放入一个 lambda 函数表达式、或一个函数作为操作运算,官方上给出DataFrame的 apply() 用法:
DataFrame.apply(self, func, axis=0, raw=False, result_type=None, args=(), **kwargs)
参数:
- func:函数或 lambda 表达式,应用于每行或者每列
- axis:{0 or ‘index’, 1 or ‘columns’}, 默认为0
- 0 or ‘index’: 表示函数处理的是每一列
- 1 or ‘columns’: 表示函数处理的是每一行
- raw:bool 类型,默认为 False;
- False ,表示把每一行或列作为 Series 传入函数中;
- True,表示接受的是 ndarray 数据类型;
- result_type:{‘expand’, ‘reduce’, ‘broadcast’, None}, default None
These only act when axis=1 (columns):
- ‘expand’ : 列表式的结果将被转化为列。
- ‘reduce’ : 如果可能的话,返回一个 Series,而不是展开类似列表的结果。这与 expand 相反。
- ‘broadcast’ : 结果将被广播到 DataFrame 的原始形状,原始索引和列将被保留。
- args: func 的位置参数
- **kwargs:要作为关键字参数传递给 func 的其他关键字参数,1.3.0 开始支持
返回值:
- Series 或者 DataFrame:沿数据的给定轴应用 func 的结果
Objects passed to the function are Series objects whose index is either the DataFrame's index (``axis=0``) or the DataFrame's columns(``axis=1``). 传递给函数的对象是Series对象,其索引是DataFrame的索引(axis=0)或DataFrame的列(axis=1)。 By default (``result_type=None``), the final return type is inferred from the return type of the applied function. Otherwise,it depends on the `result_type` argument. 默认情况下( result_type=None),最终的返回类型是从应用函数的返回类型推断出来的。否则,它取决于' result_type '参数。
注:DataFrame与Series的区别与联系:
区别:
- series,只是一个一维结构,它由index和value组成。
- dataframe,是一个二维结构,除了拥有index和value之外,还拥有column。
联系:
- dataframe由多个series组成,无论是行还是列,单独拆分出来都是一个series。
3.使用案例
3.1 DataFrame使用apply
官方使用案例
import pandas as pd
import numpy as np
df = pd.DataFrame([[4, 9]] * 3, columns=['A', 'B'])
df
A B
0 4 9
1 4 9
2 4 9
# 使用numpy通用函数 (如 np.sqrt(df)),
df.apply(np.sqrt)
'''
A B
0 2.0 3.0
1 2.0 3.0
2 2.0 3.0
'''
# 使用聚合功能
df.apply(np.sum, axis=0)
'''
A 12
B 27
dtype: int64
'''
df.apply(np.sum, axis=1)
'''
0 13
1 13
2 13
dtype: int64
'''
# 在每行上返回类似列表的内容
df.apply(lambda x: [1, 2], axis=1)
'''
0 [1, 2]
1 [1, 2]
2 [1, 2]
dtype: object
'''
# result_type='expand' 将类似列表的结果扩展到数据的列
df.apply(lambda x: [1, 2], axis=1, result_type='expand')
'''
0 1
0 1 2
1 1 2
2 1 2
'''
# 在函数中返回一个序列,生成的列名将是序列索引。
df.apply(lambda x: pd.Series([1, 2], index=['foo', 'bar']), axis=1)
'''
foo bar
0 1 2
1 1 2
2 1 2
'''
# result_type='broadcast' 将确保函数返回相同的形状结果
# 无论是 list-like 还是 scalar,并沿轴进行广播
# 生成的列名将是原始列名。
df.apply(lambda x: [1, 2], axis=1, result_type='broadcast')
'''
A B
0 1 2
1 1 2
2 1 2
'''
其他案例:
import numpy as np
import pandas as pd
df = pd.DataFrame({'A': [1, 2, 3],
'B': [4, 5, 6],
'C': [7, 8, 9]},
index=['a', 'b', 'c'])
df
A B C
a 1 4 7
b 2 5 8
c 3 6 9
# 对各列应用函数 axis=0
df.apply(lambda x: np.sum(x))
A 6
B 15
C 24
dtype: int64
# 对各行应用函数
df.apply(lambda x: np.sum(x), axis=1)
a 12
b 15
c 18
dtype: int64
3.2 Series使用apply
官网案例
s = pd.Series([20, 21, 12],index=['London', 'New York', 'Helsinki'])
s
'''
London 20
New York 21
Helsinki 12
dtype: int64
'''
# 定义函数并将其作为参数传递给 apply,求值平方化。
def square(x):
return x ** 2
s.apply(square)
'''
London 400
New York 441
Helsinki 144
dtype: int64
'''
# 通过将匿名函数作为参数传递给 apply
s.apply(lambda x: x ** 2)
'''
London 400
New York 441
Helsinki 144
dtype: int64
'''
# 定义一个需要附加位置参数的自定义函数
# 并使用args关键字传递这些附加参数。
def subtract_custom_value(x, custom_value):
return x - custom_value
s.apply(subtract_custom_value, args=(5,))
'''
London 15
New York 16
Helsinki 7
dtype: int64
'''
# 定义一个接受关键字参数并将这些参数传递
# 给 apply 的自定义函数。
def add_custom_values(x, **kwargs):
for month in kwargs:
x += kwargs[month]
return x
s.apply(add_custom_values, june=30, july=20, august=25)
'''
London 95
New York 96
Helsinki 87
dtype: int64
'''
# 使用Numpy库中的函数
s.apply(np.log)
'''
London 2.995732
New York 3.044522
Helsinki 2.484907
dtype: float64
'''
3.3 其他案例
import pandas as pd
# 显示所有列
pd.set_option('display.max_columns', None)
# 显示所有行
pd.set_option('display.max_rows', None)
# 设置value的显示长度为100,默认为50
pd.set_option('max_colwidth', 100)
# 用来计算日期差的包
import datetime
def dataInterval(data1, data2):
"""
Args:
:param data1: datetime
:param data2: datetime
:return: delta days
"""
d1 = datetime.datetime.strptime(data1, '%Y-%m-%d')
d2 = datetime.datetime.strptime(data2, '%Y-%m-%d')
delta = d1 - d2
return delta.days
def getInterval(arrLike):
"""
Args:
:param arrLike: DataFrame
:return: delta days
"""
PublishedTime = arrLike['PublishedTime']
ReceivedTime = arrLike['ReceivedTime']
days = dataInterval(PublishedTime.strip(), ReceivedTime.strip())
return days
def getInterval_new(arrLike, before, after):
"""
Args:
:param arrLike: DataFrame
:param before: forward time
:param after: backwar time
:return: delta days
"""
before = arrLike[before]
after = arrLike[after]
days = dataInterval(after.strip(), before.strip())
return days
if __name__ == '__main__':
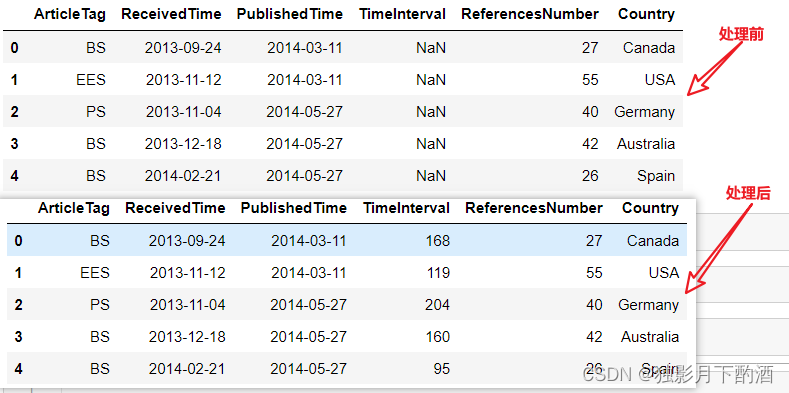
df = pd.read_excel('./data/NS_info.xls')
print(df.head())
# method 1
df['TimeInterval'] = df.apply(getInterval, axis=1)
print(df.head())
# method 2
df['TimeInterval'] = df.apply(getInterval_new,axis=1,
args=('ReceivedTime', 'PublishedTime'))
# method 3
df['TimeInterval'] = df.apply(getInterval_new,axis=1,
**{'before': 'ReceivedTime', 'after': 'PublishedTime'})
# method 4
df['TimeInterval'] = df.apply(getInterval_new,axis=1, before='ReceivedTime', after='PublishedTime')
4.总结
1.apply方法都是通过传入一个函数或者lambda表达式对数据进行批量处理
2.apply方法处理的都是一个Series对象
参考链接:
1.https://blog.csdn.net/missyougoon/article/details/83301712
2.https://blog.csdn.net/qq_19528953/article/details/79348929
到此这篇关于Python pandas中apply函数简介以及用法详解的文章就介绍到这了,更多相关pandas apply函数用法内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
解析pandas apply() 函数用法(推荐)
目录 Series.apply() apply 函数接收带有参数的函数 DataFrame.apply() apply() 计算日期相减示例 参考 理解 pandas 的函数,要对函数式编程有一定的概念和理解.函数式编程,包括函数式编程思维,当然是一个很复杂的话题,但对今天介绍的 apply() 函数,只需要理解:函数作为一个对象,能作为参数传递给其它函数,也能作为函数的返回值. 函数作为对象能带来代码风格的巨大改变.举一个例子,有一个类型为 list 的变量,包含 从 1 到 10 的数据,需
-
详谈pandas中agg函数和apply函数的区别
在利用python进行数据分析 这本书中其实没有明确表明这两个函数的却别,而是说apply更一般化. 其实在这本书的第九章'数组及运算和转换'点到了两者的一点点区别:agg是用来聚合运算的,所谓的聚合当然是合成的成分比较大些,这一节开头就点到了:聚合只不过是分组运算的其中一种而已.它是数据转换的一个特例,也就是说,它接受能够将一维数组简化为标量值的函数. 当然这两个函数都是作用在groupby对象上的,也就是分完组的对象上的,分完组之后针对某一组,如果值是一维数组,在利用完特定的函数之后,能做到
-
对pandas中apply函数的用法详解
最近在使用apply函数,总结一下用法. apply函数可以对DataFrame对象进行操作,既可以作用于一行或者一列的元素,也可以作用于单个元素. 例:列元素 行元素 列 行 以上这篇对pandas中apply函数的用法详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们. 您可能感兴趣的文章: 浅谈Pandas中map, applymap and apply的区别
-
Pandas中Apply函数加速百倍的技巧分享
目录 前言 实验对比 01 Apply(Baseline) 02 Swift加速 03 向量化 04 类别转化+向量化 05 转化为values处理 实验汇总 前言 虽然目前dask,cudf等包的出现,使得我们的数据处理大大得到了加速,但是并不是每个人都有比较好的gpu,非常多的朋友仍然还在使用pandas工具包,但有时候真的很无奈,pandas的许多问题我们都需要使用apply函数来进行处理,而apply函数是非常慢的,本文我们就介绍如何加速apply函数600倍的技巧. 实验对比 01 A
-
pandas apply 函数 实现多进程的示例讲解
前言: 在进行数据处理的时候,我们经常会用到 pandas .但是 pandas 本身好像并没有提供多进程的机制.本文将介绍如何来自己实现 pandas (apply 函数)的多进程执行.其中,我们主要借助 joblib库,这个库为python 提供了一个非常简洁方便的多进程实现方法. 所以,本文将按照下面的安排展开,前面可能比较啰嗦,若只是想知道怎么用可直接看第三部分: - 首先简单介绍 pandas 中的分组聚合操作 groupby. - 然后简单介绍 joblib 的使用方法. - 最后,
-
pandas使用函数批量处理数据(map、apply、applymap)
前言 在我们对DataFrame对象进行处理时候,下意识的会想到对DataFrame进行遍历,然后将处理后的值再填入DataFrame中,这样做比较繁琐,且处理大量数据时耗时较长.Pandas内置了一个可以对DataFrame批量进行函数处理的工具:map.apply和applymap. 提示:为方便快捷地解决问题,本文仅介绍函数的主要用法,并非全面介绍 一.pandas.Series.map()是什么? 把Series中的值进行逐一映射,带入进函数.字典或Series中得出的另一个值. Ser
-

Pandas groupby apply agg 的区别 运行自定义函数说明
agg 方法将一个函数使用在一个数列上,然后返回一个标量的值.也就是说agg每次传入的是一列数据,对其聚合后返回标量. 对一列使用三个函数: 对不同列使用不同函数 apply 是一个更一般化的方法:将一个数据分拆-应用-汇总.而apply会将当前分组后的数据一起传入,可以返回多维数据. 实例: 1.数据如下: lawsuit2[['EID','LAWAMOUNT','LAWDATE']] 2.groupby后应用apply传入函数数据如下: lawsuit2[['EID','LAWAMOUNT'
-
Pandas的Apply函数具体使用
Pandas最好用的函数 Pandas是Python语言中非常好用的一种数据结构包,包含了许多有用的数据操作方法.而且很多算法相关的库函数的输入数据结构都要求是pandas数据,或者有该数据的接口. 仔细看pandas的API说明文档,就会发现有好多有用的函数,比如非常常用的文件的读写函数就包括如下函数: Format Type Data Description Reader Writer text CSV read_csv to_csv text JSON read_json to_json
-
Pandas对每个分组应用apply函数的实现
Pandas的apply函数概念(图解) 实例1:怎样对数值按分组的归一化 实例2:怎样取每个分组的TOPN数据 到此这篇关于Pandas对每个分组应用apply函数的实现的文章就介绍到这了,更多相关Pandas 应用apply函数内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
-
Python pandas中apply函数简介以及用法详解
目录 1.基本信息 2.语法结构 3.使用案例 3.1 DataFrame使用apply 3.2 Series使用apply 3.3 其他案例 4.总结 参考链接: 1.基本信息 Pandas 的 apply() 方法是用来调用一个函数(Python method),让此函数对数据对象进行批量处理.Pandas 的很多对象都可以使用 apply() 来调用函数,如 Dataframe.Series.分组对象.各种时间序列等. 2.语法结构 apply() 使用时,通常放入一个 lambd
-
基于Python中求和函数sum的用法详解
基于Python中求和函数sum的用法详解 今天在看<集体编程智慧>这本书的时候,看到一段Python代码,当时是百思不得其解,总觉得是书中排版出错了,后来去了解了一下sum的用法,看了一些Python大神写的代码后才发现是自己浅薄了!特在此记录一下.书中代码段摘录如下: from math import sqrt def sim_distance(prefs, person1, person2): # 得到shared_items的列表 si = {} for item in prefs[p
-
python3中numpy函数tile的用法详解
tile函数位于python模块 numpy.lib.shape_base中,他的功能是重复某个数组.比如tile(A,n),功能是将数组A重复n次,构成一个新的数组,我们还是使用具体的例子来说明问题:(至于为什么是在numpy.lib.shape_base中,我还是不太清楚.) 其实tile就是重复的意思,把一个数组a,当做模板,重复几次,生成另一个数组b 至于矩阵可以不以这样,还没有试过. 例子: 创建一个a,使用tile来创建b from numpy import * a=[0,1,2]
-
python爬虫中的url下载器用法详解
前期的入库筛选工作已经由url管理器完成了,整理的工作自然要由url下载器接手.当我们需要爬取的数据已经去重后,下载器的主要任务的是这些数据下载下来.所以它的使用也并不复杂,不过需要借助到我们之前所学过的一个库进行操作,相信之前的基础大家都学的很牢固.下面小编就来为大家介绍url下载器及其使用的方法. 下载器的作用就是接受URL管理器传递给它的一个url,然后把该网页的内容下载下来.python自带有urllib和urllib2等库(这两个库在python3中合并为urllib),它们的作用就是
-
Python正则表达式中group与groups的用法详解
目录 1 .group函数 1.1 返回整个匹配结果 1.2 返回指定分组的匹配结果 1.3 处理没有匹配结果的情况 2. groups函数 3. group和groups的使用场景 在Python中,正则表达式的group和groups方法是非常有用的函数,用于处理匹配结果的分组信息.group方法是re.MatchObject类中的一个函数,用于返回匹配对象的整个匹配结果或特定的分组匹配结果.而groups方法同样是re.MatchObject类中的函数,它返回的是所有分组匹配结果组成的元组
-
对python模块中多个类的用法详解
如下所示: import wuhan.wuhan11 class Han: def __init__(self, config): self.batch_size = config.batch_size self.num_steps = config.num_steps class config: batch_size = 10 num_steps = 50 if __name__ == '__main__': han = Han(config) print(han.batch_size) pr
-
python列表中remove()函数的使用方法详解
目录 1. 基本使用 2. 删除普通类型元素 3. 删除对象类型元素 4. 一次只删一个元素 5.Python列表的remove方法的注意事项 总结 1. 基本使用 remove() 函数可以删除列表中的指定元素 语法 list.remove( element ) 参数 element:任意数据类型(数字.字符串.列表等) 2. 删除普通类型元素 删除一个列表中「存在」的数字或字符串 list1 = ['zhangsan', 'lisi', 1, 2] list1.remove(1) # 删除数
-
Python Pandas中DataFrame.drop_duplicates()删除重复值详解
目录 语法 参数 结果展示 扩展:识别重复值 总结 语法 df.drop_duplicates(subset = None, keep = 'first', inplace = False, ignore_index = False) 参数 1.subset:指定的标签或标签序列,仅删除这些列重复值,默认情况为所有列 2.keep:确定要保留的重复值,有以下可选项: first:保留第一次出现的重复值,默认 last:保留最后一次出现的重复值 False:删除所有重复值 3.inplace:是否
-
Python中scatter函数参数及用法详解
最近开始学习Python编程,遇到scatter函数,感觉里面的参数不知道什么意思于是查资料,最后总结如下: 1.scatter函数原型 2.其中散点的形状参数marker如下: 3.其中颜色参数c如下: 4.基本的使用方法如下: #导入必要的模块 import numpy as np import matplotlib.pyplot as plt #产生测试数据 x = np.arange(1,10) y = x fig = plt.figure() ax1 = fig.add_subplot
-
js中apply与call简单用法详解
你可以直接看例子,也可以先读一下介绍: call和apply是为了动态改变this而出现的,当一个object没有某个方法,但是其他的有,我们可以借助call或apply用其它对象的方法来操作. call, apply都属于Function.prototype的一个方法,它是JavaScript引擎内在实现的,因为属于Function.prototype,所以每个Function对象实例,也就是每个方法都有call, apply属性.既然作为方法的属性,那它们的使用就当然是针对方法的了.这两个方