Python采集大学教务系统成绩单实战示例
目录
- 前言
- 采集数据
- 发送请求
- 获取数据
- 保存数据
- 总结
前言
采集教务系统成绩单是一个非常有意义的项目。在现代教育中,教务系统已经成为了学校管理和教学工作的重要组成部分。然而,由于各种原因,教务系统的成绩单并不能下载的,这给我们带来了很多不必要的麻烦和困扰。因此,采集教务系统成绩单的项目具有非常重要的意义。
在本文中,我们将详细介绍采集教务系统成绩单的背景和目的,并阐述该项目实战所涉及的相关知识点和技术细节。
采集数据
我们上一篇介绍了,如何采集大家熟悉的百度贴吧的排行榜。今天,我们来学习采集教务系统里面的成绩单,把自己的成绩采集下来。
发送请求
我们首先确定我们的目标网址,对我们需要获取的数据。
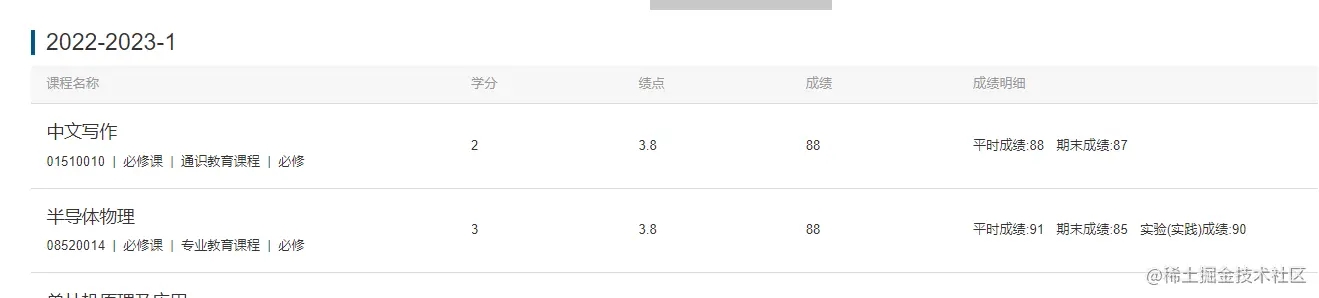
我们要把每一行的数据获取下来,我们接下来用到开发者工具。我们看成绩是在什么位置。是不是在网页源代码中。接下来,我们发送请求,获取网页源代码。
每个学校教务系统不一样,但是,原理都是一样的,我们通过抓包分析,看到,我们学校把成绩放到了一个数据包里面,一个学期一个数据包。
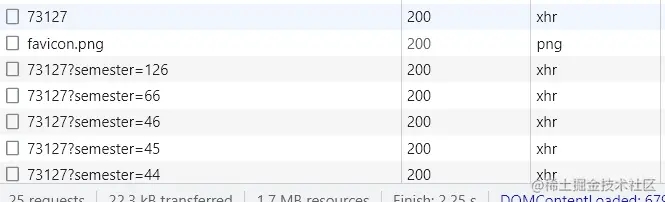
那么,接下来就简单了,我们只需要请求数据,当然,我们肯定要加上cookies,毕竟里面包含了我们的登录信息。
我们看看前面代码是怎么写的。
semesters = ["44", "45", "46", "66", "126", ]
for Semester in semesters:
url = f'http://jwxt.aqnu.edu.cn/student/for-std/grade/sheet/info/73127?semester={Semester}'
headers = {
'Cookie': 'cookies',
}
res = requests.get(url, headers=headers)
print(url, res)
我们这里直接多页遍历,我们学校只做了cookies检查,对请求头没有要求。
这段代码首先定义了一个包含多个元素的列表 semesters,其中每个元素表示一个学期的信息。然后,使用 for 循环遍历列表中的每个元素,并使用 requests.get() 函数向指定的 URL 发送 GET 请求。在请求中,我们设置了一些请求头信息,以确保我们能够正确地解析 URL 并获取正确的响应。最后,我们打印了 URL、响应和响应中的内容。
获取数据
id2semesters = res.json()['id2semesters']
semester = id2semesters[f'{Semester}']['nameZh']
semesterId2studentGrades = res.json()['semesterId2studentGrades'][f'{Semester}']
for semesterId2studentGrade in semesterId2studentGrades:
course = semesterId2studentGrade['course'] # 课程
course_nameZh = course['nameZh'] # 课程名称
credits = course['credits'] # 课程学分
try:
courseProperty = semesterId2studentGrade['courseProperty']
courseProperty_name = courseProperty['name']
except TypeError:
courseProperty_name = "NOLL"
gp = semesterId2studentGrade['gp'] # 绩点
gaGrade = semesterId2studentGrade['gaGrade'] # 成绩
gradeDetails = semesterId2studentGrade['gradeDetail'] # 明细原文
gradeDetail = re.findall('data-typeid=.*?>(.*?)</span>', gradeDetails)
这段代码首先从 JSON 响应中获取了学期和学生的绩点信息,并将其存储在变量 semester 和 semesterId2studentGrades 中。然后,使用 for 循环遍历 semesterId2studentGrades 中的每个元素,并使用 course 属性获取该学期的课程信息。接着,使用 course_nameZh 属性获取课程名称,使用 credits 属性获取课程学分,使用 courseProperty_name 属性获取课程属性名称,如果不存在则返回 "NOLL"。最后,使用 gp 属性获取绩点,使用 gaGrade 属性获取成绩,使用 gradeDetail 属性获取明细原文,使用 gradeDetail 属性获取明细原文中的数据类型标识符。
这里就是json取值,没有什么难度,只要写好这些,就可以获取到我们想的内容,我们看看效果。

保存数据
保存数据就简单了,我们已经练习了很多次。
f = open('个人成绩单.csv', mode='a', encoding='utf-8_sig', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['学期','课程名称', '课程学分', '课程类型', '成绩', '学分绩点',
'成绩明细'])
这段代码首先打开一个名为 personal_scores.csv 的文件,并指定使用 a 模式打开文件。然后,使用 csv.DictWriter() 函数创建一个 CSV 写入器,并指定要写入的列名。在这个例子中,我们指定了 fieldnames 参数,它包含了我们要写入的列名。
接下来,我们使用 csv_writer.writeheader() 方法写入列名。这个方法会将列名写入文件的第一行。
最后,我们使用 csv_writer.writerow() 方法写入数据。在这个例子中,我们写入了一个包含学期、课程名称、课程学分、课程类型、成绩、学分绩点和成绩明细的列表。
接下来就是写入字典,保存下来。
dit = {
'学期': semester,
'课程名称': course_nameZh,
'课程学分': credits,
'课程类型': courseProperty_name,
'成绩': gaGrade,
'学分绩点': gp,
'成绩明细': gradeDetail,
}
csv_writer.writerow(dit)
这段代码使用 csv_writer.writerow() 方法将 dit 字典写入 CSV 文件中。fieldnames 参数指定了要写入的列名。在这个例子中,我们指定了 ['学期','课程名称', '课程学分', '课程类型', '成绩', '学分绩点', '成绩明细']。
总结
总之,采集教务系统成绩单是一个非常有意义的项目实战,它不仅可以采集成绩单,还可以提升我们采集数据的能力。在实现过程中,我们需要注意数据的准确性和完整性,并采取必要的措施来保证项目的安全性和可靠性。
以上就是Python采集大学教务系统成绩单实战示例的详细内容,更多关于Python采集教务系统成绩单的资料请关注我们其它相关文章!
相关推荐
-
Python采集二手车数据的超详细讲解
目录 数据采集 发送请求 明确需求: 解析数据 保存数据 总结 数据采集 XPath,XML路径语言的简称.XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言.XPath主要用于解析XML文档,可以用来获取XML文档中某个元素的位置.属性值等信息.XPath可以用于XML文档解析.XML数据抽取.XML路径匹配等方面. 发送请求 首先,我们要进行数据来源分析,知道我们的需求是什么? 明确需求: 明确采集网站是什么? 明确采集数据是什么
-
Python采集C站热榜数据实战示例
目录 前言 功能实现 解析数据 保存数据 总结 前言 大家好,我们今天来爬取c站的热搜榜,把其文章名称,链接和作者获取下来,我们保存到本地,我们通过测试,发现其实很简单,我们只要简单获取数据就可以.没有加密的东西. 功能实现 我们话不多说,我们先找到url,也就是请求地址.我们代码如下: url = 'https://blog.csdn.net/phoenix/web/blog/hot-rank?page=0&pageSize=25&type=' headers = { 'user-age
-
Python采集情感音频的实现示例
目录 前言 发送请求 获取数据 解析数据 保存数据 总结 前言 我最近喜欢去听情感类的节目,比如说,婚姻类,我可能老了吧.我就想着怎么把音乐下载下来了,保存到手机上,方便我们业余时间去听. 发送请求 首先,我们要确定我们的目标网址,我们想要获取到每一个音频的地址. 我们发送请求,获取网页源代码.我们相信大家这里的代码都会写了. url = 'https://www.ximalaya.com/album/37453303' headers = { 'User-Agent': 'Mozilla/5.
-
Python采集某评论区内容的实现示例
目录 前言 发送请求 解析数据 总结 前言 我们知道在这个互联网时代,评论已经在我们的生活到处可见,评论区里面的信息是一个非常有趣和有争议的地方.我们今天,就来获取某技术平台的评论,和大家分享一下,我获取数据的过程,也是一个尝试的过程. 发送请求 我们首先,确定我们要获取哪一个文章下面的评论区.我们先使用开发者工具,定位到我们要的数据. 我们通过数据抓取,我们发现,这个平台的评论区数据,放在了一个叫getlist数据包里面了. 我们就不难明白,我们只要请求这个url,在传一个关于文章的参数,我们
-
python爬虫爬取监控教务系统的思路详解
这几天考了大大小小几门课,教务系统又没有成绩通知功能,为了急切想知道自己挂了多少门,于是我写下这个脚本. 设计思路: 设计思路很简单,首先对已有的成绩进行处理,变为list集合,然后定时爬取教务系统查成绩的页面,对爬取的成绩也处理成list集合,如果newList的长度增加了,就找出增加的部分,并通过邮件通知我. 脚本运行效果: 服务器: 发送邮件通知: 代码如下: import datetime import time from email.header import Header impor
-
python 录制系统声音的示例
环境准备 python wave pyaudio wave 可以通过pip直接install,在安装pyaudio时,通过正常的pip install 直接安装一直处于报错阶段,后来想到可以通过轮子直接安装. 在pypi提供的安装包中有对应的安装包,注意,不仅仅是python2和python3的区别,python3的小版本也有点差别.可杯具的是,小主电脑里装的是python3.8,后来想到还有一个网站可以安装pythonlibs,找到对应的版本后,下载下来.直接在文件所在目录,或者在安装中指定文
-
python自动统计zabbix系统监控覆盖率的示例代码
脚本主要功能: 1)通过zabbix api接口采集所有监控主机ip地址: 2)通过cmdb系统(蓝鲸)接口采集所有生产主机IP地址.主机名.操作系统.电源状态: 3)以上2步返回数据对比,找出未监控主机ip地址,生成csv文件: 4)发送邮件. 脚本如下: #!/usr/bin/python #coding:utf-8 import requests import json import re import time import csv from collections import Cou
-

Python使用psutil对系统数据进行采集监控
目录 psutil库 获取系统cpu信息 获取系统网卡信息 今天给大家介绍一个可以获取当前系统信息的库--psutil 利用psutil库可以获取系统的一些信息,如cpu,内存等使用率,从而可以查看当前系统的使用情况,实时采集这些信息可以达到实时监控系统的目的. psutil库 psutil的安装很简单 pip install psutil psutil库可以获取哪些系统信息? psutil有哪些作用 1.内存使用情况 2.磁盘使用情况 3.cpu使用率 4.网络接口发送接收流量 5.获取当前网
-
基于Python实现随机点名系统的示例代码
目录 效果展示 代码展示 导入模块 子线程调用 应用初始化信息 姓名信息布局 开始信息布局 数据信息布局 整体布局 运行 大家好,我是了不起! 在某些难以抉择得时候,我们经常要用外力来帮助我们做出选择 比如,梁山出征方腊前沙场点兵,挑选先锋的场景 这个时候,有一个随机点名系统就非常好啦,毕竟我水泊梁山的名号~ 效果展示 创建一个这样的文件夹,然后把要随机点名的名字写在里面 导入后,这里就显示你导入了多少人员信息 点击开始点名后,会随机从导入名字里挑选一位幸运儿~ 效果大概就是这样,下面我们来看看
-
Opencv 图片的OCR识别的实战示例
一.图片变换 0.导入模块 导入相关函数,遇到报错的话,直接pip install 函数名. import numpy as np import argparse import cv2 参数初始化 ap = argparse.ArgumentParser() ap.add_argument("-i", "--image", required = True, help = "Path to the image to be scanned") arg
-
Python调用C# Com dll组件实战教程
之前公司有套C# AES加解密方案,但是方案加密用的是Rijndael类,而非AES的四种模式(ECB.CBC.CFB.OFB,这四种用的是RijndaelManaged类),Python下Crypto库AES也只有这四种模式,进而Python下无法实现C# AES Rijndael类加密效果了. 类似于这种C# 能实现的功能而在Python下实现不了的,搜集资料有两种解决方案,第一种方式,使用IronPython 直接调用C# dll文件,教程网上很多,不在赘述了,这种方式有个缺点,用的是ir
-
php实现模拟登陆方正教务系统抓取课表
课程格子和超级课程表这两个应用,想必大学生都很熟悉,使用自己的学号和教务系统的密码,就可以将自己的课表导入,随时随地都可以在手机上查看. 其实稍微了解一点php的话,我们也可以做一个类似这样的web 应用. 1,解决掉验证码 其实这是正方的一个小bug,当我们进入登陆界面时,浏览器会去请求服务器,服务器会生成一个验证码图片.如果我们不去请求这个图片,那么正方后台也不会生成相应的 验证码,于是这样我们就有了可乘之机,让我高兴会儿~这时,我们在不填写验证码的情况下,可以很流畅的进入.大
-
python shell根据ip获取主机名代码示例
这篇文章里我们主要分享了python中shell 根据 ip 获取 hostname 或根据 hostname 获取 ip的代码,具体介绍如下. 笔者有时候需要根据hostname获取ip 比如根据machine.company.com 获得ip 10.173.14.117 方法1:利用 socket 模块 里的 gethostbyname 函数 代码如下,使用socket模块 >>> import socket >>> socket.gethostbyname(&qu
-
python采集百度搜索结果带有特定URL的链接代码实例
这篇文章主要介绍了python采集百度搜索结果带有特定URL的链接代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 #coding utf-8 import requests from bs4 import BeautifulSoup as bs import re from Queue import Queue import threading from argparse import ArgumentParser arg = Argu