kaggle数据分析家庭电力消耗过程详解
目录
- 一、家庭电力消耗分析
- 1.背景描述
- 数据说明
- 2.数据来源
- 3.问题描述
- 二、数据加载
- 三、预测
- 1.Prophet介绍
- 2.模型介绍
- 3.Prophet优点
一、家庭电力消耗分析
1.背景描述
本数据集包含了一个家庭6个月的用电数据,收集于2007年1月至2007年6月。
这些数据包括全球有功功率、全球无功功率、电压、全球强度、分项计量1(厨房)、分项计量2(洗衣房)和分项计量3(电热水器和空调)等信息。该数据集共有260,640个测量值,可以为了解家庭用电情况提供重要的见解。
我们要感谢databeats团队提供这个数据集。如果你在你的研究中使用这个数据集,请注明原作者:Georges Hébrail 和 Alice Bérard
数据说明
| 列名 | 说明 |
|---|---|
| Date | 日期 |
| Time | 时间 |
| Globalactivepower | 该家庭所消耗的总有功功率(千瓦) |
| Globalreactivepower | 该家庭消耗的总无功功率(千瓦) |
| Voltage | 向家庭输送电力的电压(伏特) |
| Global_intensity | 输送到家庭的平均电流强度(安培) |
| Submetering1 | 厨房消耗的有功功率(千瓦) |
| Submetering2 | 洗衣房所消耗的有功功率(千瓦) |
| Submetering3 | 电热水器和空调所消耗的有功功率(千瓦) |
2.数据来源
3.问题描述
本数据集可以用于机器学习的目的,如预测性建模或时间序列分析。例如,人们可以使用这个数据集,根据过去的数据来预测未来的家庭用电量。
分析不同类型的电气设备对耗电量的影响
研究电力消耗如何随时间和地点而变化
构建一个预测模型来预测未来的电力消耗
二、数据加载
!pip install prophet -i https://pypi.tuna.tsinghua.edu.cn/simple
data_path="/home/mw/input/Household_Electricity4767/household_power_consumption.csv"
import pandas as pd import seaborn as sns import numpy as np from tqdm.auto import tqdm from prophet import Prophet
df=pd.read_csv(data_path)
df.head()
.dataframe tbody tr th:only-of-type { vertical-align: middle; } .dataframe tbody tr th { vertical-align: top; } .dataframe thead th { text-align: right; }
| index | Date | Time | Global_active_power | Global_reactive_power | Voltage | Global_intensity | Sub_metering_1 | Sub_metering_2 | Sub_metering_3 |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1/1/07 | 0:00:00 | 2.58 | 0.136 | 241.97 | 10.6 | 0 | 0 | 0.0 |
| 1 | 1/1/07 | 0:01:00 | 2.552 | 0.1 | 241.75 | 10.4 | 0 | 0 | 0.0 |
| 2 | 1/1/07 | 0:02:00 | 2.55 | 0.1 | 241.64 | 10.4 | 0 | 0 | 0.0 |
| 3 | 1/1/07 | 0:03:00 | 2.55 | 0.1 | 241.71 | 10.4 | 0 | 0 | 0.0 |
| 4 | 1/1/07 | 0:04:00 | 2.554 | 0.1 | 241.98 | 10.4 | 0 | 0 | 0.0 |
df.describe()
.dataframe tbody tr th:only-of-type { vertical-align: middle; } .dataframe tbody tr th { vertical-align: top; } .dataframe thead th { text-align: right; }
| index | Sub_metering_3 | |
|---|---|---|
| count | 260640.000000 | 256869.000000 |
| mean | 130319.500000 | 5.831825 |
| std | 75240.431418 | 8.186709 |
| min | 0.000000 | 0.000000 |
| 25% | 65159.750000 | 0.000000 |
| 50% | 130319.500000 | 0.000000 |
| 75% | 195479.250000 | 17.000000 |
| max | 260639.000000 | 20.000000 |
df.dtypes
index int64 Date object Time object Global_active_power object Global_reactive_power object Voltage object Global_intensity object Sub_metering_1 object Sub_metering_2 object Sub_metering_3 float64 dtype: object
df['Date']=pd.DatetimeIndex(df['Date'])
make_em_num = ['Global_active_power', 'Global_reactive_power', 'Voltage', 'Global_intensity', 'Sub_metering_1', 'Sub_metering_2', 'Sub_metering_3']
def floating(string):
try:
return float(string)
except:
return float(0)
for column in tqdm(make_em_num):
df[column] = df[column].apply(lambda item: floating(item))
HBox(children=(FloatProgress(value=0.0, max=7.0), HTML(value='')))
df.dtypes
index int64 Date datetime64[ns] Time object Global_active_power float64 Global_reactive_power float64 Voltage float64 Global_intensity float64 Sub_metering_1 float64 Sub_metering_2 float64 Sub_metering_3 float64 dtype: object
df.head()
.dataframe tbody tr th:only-of-type { vertical-align: middle; } .dataframe tbody tr th { vertical-align: top; } .dataframe thead th { text-align: right; }
| index | Date | Time | Global_active_power | Global_reactive_power | Voltage | Global_intensity | Sub_metering_1 | Sub_metering_2 | Sub_metering_3 |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 2007-01-01 | 0:00:00 | 2.580 | 0.136 | 241.97 | 10.6 | 0.0 | 0.0 | 0.0 |
| 1 | 2007-01-01 | 0:01:00 | 2.552 | 0.100 | 241.75 | 10.4 | 0.0 | 0.0 | 0.0 |
| 2 | 2007-01-01 | 0:02:00 | 2.550 | 0.100 | 241.64 | 10.4 | 0.0 | 0.0 | 0.0 |
| 3 | 2007-01-01 | 0:03:00 | 2.550 | 0.100 | 241.71 | 10.4 | 0.0 | 0.0 | 0.0 |
| 4 | 2007-01-01 | 0:04:00 | 2.554 | 0.100 | 241.98 | 10.4 | 0.0 | 0.0 | 0.0 |
sns.heatmap(df.drop(['index','Date','Time'], axis=1).corr(), annot=True)
<matplotlib.axes._subplots.AxesSubplot at 0x7f31603ed4e0>

三、预测
1.Prophet介绍
Prophet是一种基于可加性模型预测时间序列数据的程序,其中非线性趋势可以按年度、每周和每日的季节性,以及假日效应进行拟合。它最适合于具有强烈季节效应的时间序列和有几个季节的历史数据。Prophet对于缺失的数据和趋势的变化是稳健的,并且通常能够很好地处理异常值。
2.模型介绍
Prophet模型如下:
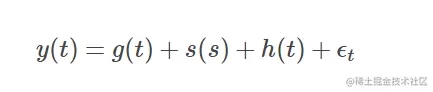
- g(t) 表示趋势函数,拟合非周期性变化;
- s(s)表示周期性变化,比如说每周,每年,季节等;
- h(t)表示假期变化,节假日可能是一天或者多天;
- ϵt为噪声项,用他来表示随机无法预测的波动,我们假设ϵt是高斯的。
趋势中有两个增长函数,分别是分段线性函数(linear)和非线性逻辑回归函数(logistic)拟合增长曲线趋势。通过从数据中选择变化点,Prophet自动探测趋势变化;
使用傅里叶级数建模每年的季节分量;
使用虚变量代表过去,将来的相同节假日,属于节假日就为1,不属于就是0;
用户提供的重要节假日列表
- Modeling:建立时间序列模型。分析师根据预测问题的背景选择一个合适的模型。
- Forecast Evaluation:模型评估。根据模型对历史数据进行仿真,在模型的参数不确定的情况下,我们可以进行多种尝试,并根 据对应的仿真效果评估哪种模型更适合。
- Surface Problems:呈现问题。如果尝试了多种参数后,模型的整体表现依然不理想,这个时候可以将误差较大的潜在原因呈现给分析师。
- Visually Inspect Forecasts:以可视化的方式反馈整个预测结果。当问题反馈给分析师后,分析师考虑是否进一步调整和构建模型。
3.Prophet优点
- 准确,快速,拟合非常快,可以进行交互式探索
- 全自动,无需人工操作就能对混乱的数据做出合理的预测
- 可调整的预测,预测模型的参数非常容易解释,可以用业务知识改进或调整预测
- 对缺失值和变化剧烈的时间序列和离散值能做很好有很好的鲁棒性,不需要填补缺失值;
import matplotlib.pyplot as plt
df.shape
(260640, 10)
df=df.sample(n=10000)
def prophet_forecaster(data, x, y, period=100):
new_df = pd.DataFrame(columns=['ds', 'y'])
new_df['ds']= data[x]
new_df['y'] = data[y]
model = Prophet()
model.fit(new_df)
future_dates = model.make_future_dataframe(periods=period)
forecast = model.predict(future_dates)
model.plot(forecast)
plt.title(f"Forecasting on the next {period} days for {y}")
prophet_forecaster(df, x='Date', y='Global_active_power', period=100)
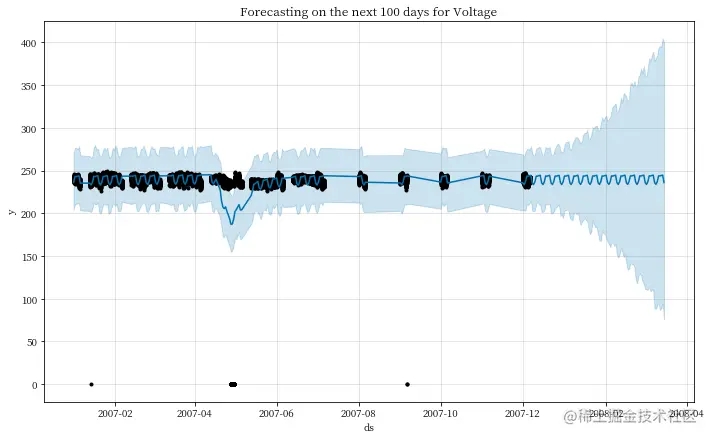
prophet_forecaster(df, x='Date', y='Voltage', period=100)
INFO:prophet:Disabling yearly seasonality. Run prophet with yearly_seasonality=True to override this. INFO:prophet:Disabling daily seasonality. Run prophet with daily_seasonality=True to override this.
以上就是kaggle数据分析家庭电力消耗过程详解的详细内容,更多关于kaggle数据分析电力消耗的资料请关注我们其它相关文章!
相关推荐
-

Pandas数据分析之groupby函数用法实例详解
目录 正文 一.了解groupby 二.数据文件简介 三.求各个商品购买量 四.求各个商品转化率 五.转化率最高的30个商品及其转化率 小小の总结 正文 今天本人在赶学校课程作业的时候突然发现groupby这个分组函数还是蛮有用的,有了这个分组之后你可以实现很多统计目标. 当然,最主要的是,他的使用非常简单 本期我们以上期作业为例,单走一篇文章来看看这个函数可以实现哪些功能: (本期需要准备的行囊): jupyter notebook环境(anaconda自带) pandas第三方库 numpy
-
Python数据分析Numpy中常用相关性函数
目录 摘要: 一.股票相关性分析 二.多项式 三.求极值的知识 摘要: NumPy中包含大量的函数,这些函数的设计初衷是能更方便地使用,掌握解这些函数,可以提升自己的工作效率.这些函数包括数组元素的选取和多项式运算等.下面通过实例进行详细了解. 前述通过对某公司股票的收盘价的分析,了解了某些Numpy的一些函数.通常实际中,某公司的股价被另外一家公司的股价紧紧跟随,它们可能是同领域的竞争对手,也可能是同一公司下的不同的子公司.可能因两家公司经营的业务类型相同,面临同样的挑战,需要相同的原料和资源
-
Seaborn数据分析NBA球员信息数据集
目录 1. 数据介绍 2. 案例演示 2.1 获取数据 2.2 查看数据基本信息 2.3 数据分析 2.3.1 效率值相关性分析 本案例使用 Jupyter Notebook进行案例演示,数据集为NBA球员信息数据集.本项目将进行完整的数据分析演示. 1. 数据介绍 数据集共有342个球员样本,38个特征,即342行×38列. 数据集主要信息如下表所示: 球员姓名 位置 身高 体重 年龄 球龄 上场次数 场均时间 进攻能力 防守能力 是否入选过全明星 球员薪金 本数据集主要可以用来做数据处理以及
-
kaggle+mnist实现手写字体识别
现在的许多手写字体识别代码都是基于已有的mnist手写字体数据集进行的,而kaggle需要用到网站上给出的数据集并生成测试集的输出用于提交.这里选择keras搭建卷积网络进行识别,可以直接生成测试集的结果,最终结果识别率大概97%左右的样子. # -*- coding: utf-8 -*- """ Created on Tue Jun 6 19:07:10 2017 @author: Administrator """ from keras.mo
-
使用pytorch完成kaggle猫狗图像识别方式
kaggle是一个为开发商和数据科学家提供举办机器学习竞赛.托管数据库.编写和分享代码的平台,在这上面有非常多的好项目.好资源可供机器学习.深度学习爱好者学习之用. 碰巧最近入门了一门非常的深度学习框架:pytorch,所以今天我和大家一起用pytorch实现一个图像识别领域的入门项目:猫狗图像识别. 深度学习的基础就是数据,咱们先从数据谈起.此次使用的猫狗分类图像一共25000张,猫狗分别有12500张,我们先来简单的瞅瞅都是一些什么图片. 我们从下载文件里可以看到有两个文件夹:train和t
-
python挖掘蛋卷基金投资组合数据分析
目录 一.网页分析 1.打开网页 2.查看json 二.数据获取 1.观察json的结构 三.代码实现 1.基本操作 2.写一个可以重复使用的函数 3.完整代码 一.网页分析 1.打开网页 我们随意打开一个蛋卷基金上投资组合的网页,例如: 链接: https://danjuanapp.com/strategy/CSI1033 这里以Microsoft Edge浏览器为例 . 点击下载查看详图 2.查看json 选择“XHR”,发现有一个以基金编号命名的文件,单击它,查看请求标头. 点击下载查看详
-
JS数据分析数据去重及参数序列化示例
目录 列表去重 对象转为查询字符串 获取查询参数 列表去重 使用 Set 数据结构 const set = new Set([2, 8, 3, 8, 5]) 注:Set 数据结构认为对象永不相等,即使是两个空对象,在 Set 结构内部也是不等的 方法封装 const uniqueness = (data, key) => { const hash = new Map() return data.filter(item => !hash.has(item[key]) && has
-
kaggle数据分析家庭电力消耗过程详解
目录 一.家庭电力消耗分析 1.背景描述 数据说明 2.数据来源 3.问题描述 二.数据加载 三.预测 1.Prophet介绍 2.模型介绍 3.Prophet优点 一.家庭电力消耗分析 1.背景描述 本数据集包含了一个家庭6个月的用电数据,收集于2007年1月至2007年6月.这些数据包括全球有功功率.全球无功功率.电压.全球强度.分项计量1(厨房).分项计量2(洗衣房)和分项计量3(电热水器和空调)等信息.该数据集共有260,640个测量值,可以为了解家庭用电情况提供重要的见解. 我们要感谢
-
实例解说TCP连接建立及结束过程详解
[简 介] TCP连接是面向可靠的连接,它通过建立可靠连接实现数据的可靠传输,在应用程序中被广泛使用.由于FTP命令采用的连接就是TCP连接,下面给大家介绍一下如何使用Sniffer工具捕获FTP命令数据包,分析TCP连接建立和结束的详细过程,使大家更好地理解和详细掌握TCP连接建立的三次握手过程和四次结束的过程. 一.FTP命令数据包的捕获 1.搭建网络环境.建立一台FTP服务器,设置IP地址为:76.88.16.16.建立一台FTP客户端,IP地址设为76.88.16.104,在其上安装
-
Mysql 5.7.18安装方法及启动MySQL服务的过程详解
MySQL 是一个非常强大的关系型数据库.但有些初学者在安装配置的时候,遇到种种的困难,在此就不说安装过程了,说一下配置过程.在官网下载的MySQL时候,有msi格式和zip格式.Msi直接运行安装即可,zip则解压在自己喜欢的目录地址即可.在安装这两种的时候,都需要配置才能用.以下介绍主要是msi格式默认的地址:C:\Program Files\ mysql-5.7.18-win32. 一.在安装或者解压后,需要配置环境变量,过程如下:我的电脑->属性->高级系统设置->高级->
-
yum安装CDH5.5 hive、impala的过程详解
一.安装hive 组件安排如下: 172.16.57.75 bd-ops-test-75 mysql-server 172.16.57.77 bd-ops-test-77 Hiveserver2 HiveMetaStore 1.安装hive 在77上安装hive: # yum install hive hive-metastore hive-server2 hive-jdbc hive-hbase -y 在其他节点上可以安装客户端: # yum install hive hive-server2
-
DBA_Oracle Startup / Shutdown启动和关闭过程详解(概念)(对数据库进行各种维护操作)
一.摘要 Oracle数据库的完整启动过程是分步骤完成的,包含以下3个步骤: 启动实例-->加载数据库-->打开数据库 因为Oracle数据库启动过程中不同的阶段可以对数据库进行不同的维护操作,对应我们不同的需求,所以就需不同的模式启动数据库. 1. Oracle启动需要经历四个状态:SHUTDOWN .NOMOUNT .MOUNT .OPEN 2. Oracle关闭的四种方式:Normal, Immediate, Transactional, Abort 3. 启动和关闭过程详解 二.数
-
JavaScript处理解析JSON数据过程详解
JSON (JavaScript Object Notation)一种简单的数据格式,比xml更轻巧. JSON 是 JavaScript 原生格式,这意味着在 JavaScript 中处理 JSON 数据不需要任何特殊的 API 或工具包. JSON的规则很简单: 对象是一个无序的"'名称/值'对"集合.一个对象以"{"(左括号)开始,"}"(右括号)结束.每个"名称"后跟一个":"(冒号):"
-
linux中了minerd之后的完全清理过程(详解)
一不小心装了一个Redis服务,开了一个全网的默认端口,一开始以为这台服务器没有公网ip,结果发现之后悔之莫及啊 某天发现cpu load高的出奇,发现一个minerd进程 占了大量cpu,google了一下,发现自己中招了 下面就是清理过程 第一步 1.立即停止redis服务,修改端口权限,增加密码措施 2.按照网上的资料 删除 crontab 里的两个内容 sudo rm /var/spool/cron/root sudo rm /var/spool/cron/crontabs/root 3
-
Android 定时任务过程详解
在Android开发中,通过以下三种方法定时执行任务: 一.采用Handler与线程的sleep(long)方法(不建议使用,java的实现方式) 二.采用Handler的postDelayed(Runnable, long)方法(最简单的android实现) 三.采用Handler与timer及TimerTask结合的方法(比较多的任务时建议使用) android里有时需要定时循环执行某段代码,或者需要在某个时间点执行某段代码,这个需求大家第一时间会想到Timer对象,没错,不过我们还有更好的
-
Android4.X中SIM卡信息初始化过程详解
本文实例讲述了Android4.X中SIM卡信息初始化过程详解.分享给大家供大家参考,具体如下: Phone 对象初始化的过程中,会加载SIM卡的部分数据信息,这些信息会保存在IccRecords 和 AdnRecordCache 中.SIM卡的数据信息的初始化过程主要分为如下几个步骤 1.RIL 和 UiccController 建立监听关系 ,SIM卡状态发生变化时,UiccController 第一个去处理. Phone 应用初始化 Phone 对象时会建立一个 RIL 和UiccCont
-
基于python中pygame模块的Linux下安装过程(详解)
一.使用pip安装Python包 大多数较新的Python版本都自带pip,因此首先可检查系统是否已经安装了pip.在Python3中,pip有时被称为pip3. 1.在Linux和OS X系统中检查是否安装了pip 打开一个终端窗口,并执行如下命令: Python2.7中: zhuzhu@zhuzhu-K53SJ:~$ pip --version pip 8.1.1 from /usr/lib/python2.7/dist-packages (python 2.7) Python3.X中: z