详解从 0 开始使用 Docker 快速搭建 Hadoop 集群环境
Linux
Info:
- Ubuntu 16.10 x64
Docker 本身就是基于 Linux 的,所以首先以我的一台服务器做实验。虽然最后跑 wordcount 已经由于内存不足而崩掉,但是之前的过程还是可以参考的。
连接服务器
使用 ssh 命令连接远程服务器。
ssh root@[Your IP Address]
更新软件列表
apt-get update
更新完成。

安装 Docker
sudo apt-get install docker.io
当遇到输入是否继续时,输入「Y/y」继续。
安装完成
输入「docker」测试是否安装成功。
拉取镜像
镜像,是 Docker 的核心,可以通过从远程拉取镜像即可配置好我们所需要的环境,我们这次需要的是 Hadoop 集群的镜像。
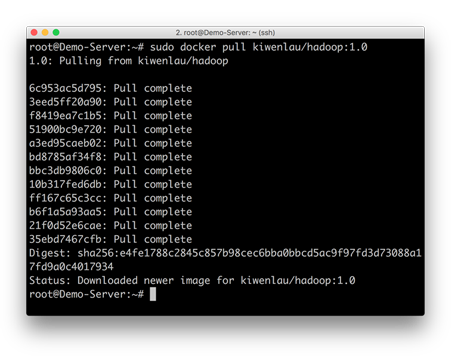
在本文中,我们将使用 kiwenlau 的 Hadoop 集群镜像以及其配置。由于我的服务器本身即在国外,因此拉取镜像的速度较快,国内由于众所周知的原因,可以替换为相应的国内源,以加快拉取速度。
sudo docker pull kiwenlau/hadoop:1.0
拉取镜像完成。
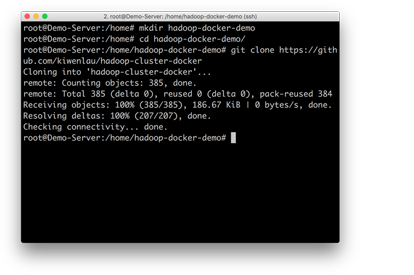
克隆仓库
克隆仓库到当前文件夹(可以自行创建并切换到相应文件夹)。
git clone https://github.com/kiwenlau/hadoop-cluster-docker
克隆仓库完成
桥接网络
sudo docker network create --driver=bridge hadoop
运行容器
cd hadoop-cluster-docker ./start-container.sh
默认是 1 个主节点,2 个从节点,当然也可以根据性能调整为 N 节点,详见文末参考链接。
启动 Hadoop
./start-hadoop.sh
在上一步,我们已经运行容器,即可直接运行 Hadoop。启动时长与机器性能有关,也是难为了我这一台 512 MB 内存的服务器。
测试 Word Count
./run-wordcount.sh
Word Count 是一个测试 Hadoop 的 Shell 脚本,即计算文本中的单词个数。不过由于我的服务器内存不够分配无法完成,所以后续以本机进行测试。
网页管理
我们可以通过网页远程管理 Hadoop:
- Name Node: [Your IP Address]:50070/
- Resource Manager: [Your IP Address]:8088/
macOS
Info:
- macOS 10.12.4 beta (16E191a)
下载 & 安装
打开 Docker 官方网站:https://www.docker.com,选择社区版,并下载、安装。Windows 系统用户可以选择 Windows 版本。
Docker CE
macOS or Windows
运行 Docker
打开 Docker。为了简单,我没有改动配置,如需更改,可以在 Preferences 中修改。
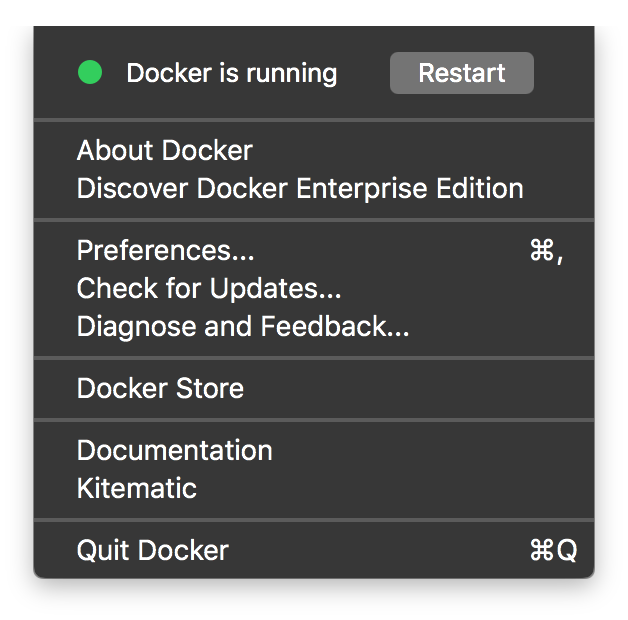
我们可以在终端(Terminal)输入「docker」,测试是否安装成功。
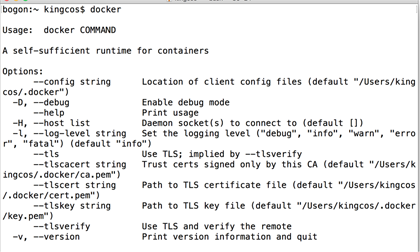
拉取镜像 & 克隆仓库 & 桥接网络 & 运行容器 & 启动 Hadoop
同 Linux。
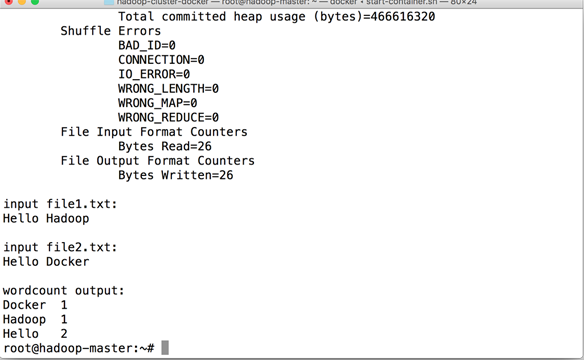
测试 Word Count
./run-wordcount.sh
同 Linux,但这次我们可以运算出结果了。
Windows
其实最开始就没有打算放出 Windows 版,倒不是因为觉得 Windows 不好,而是目前手头没有 Windows 的电脑,借用同学的电脑也不是很方便。如果需要安装 Docker,需要 CPU 支持虚拟化,且安装了 64 位 Windows 10 Pro/企业版(需要开启 Hyper-V)。其他版本的 Windows 可以安装 Docker Toolbox。
Intellij IDEA
我们的 Hadoop 集群已经在容器里安装完成,而且已经可以运行。相比自己一个个建立虚拟机,这样的确十分方便、快捷。为了便于开发调试,接下来就需要在 Intellij IDEA 下配置开发环境,包管理工具选择 Gradle。Maven 配合 Eclipse 的配置网上已经有很多了,需要的同学可以自行搜索。
Docker 开启 9000 端口映射
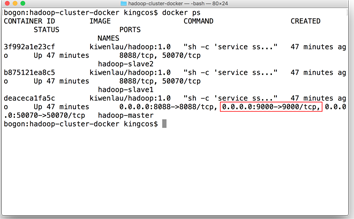
由于我们使用的是 kiwenlau的镜像和开源脚本,虽然加快了配置过程,但是也屏蔽了很多细节。比如在其脚本中只默认开启了 50070 和 8088 的端口映射,我们可以通过 docker ps(注意是在本机,而不是在容器运行该命令)列出所有容器,查看容器映射的端口。
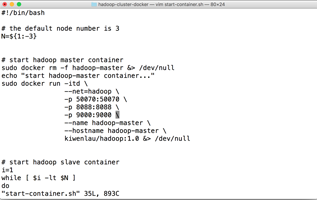
cd hadoop-cluster-docker vim start-container.sh
切换到脚本文件夹,使用 Vim 编辑 start-container.sh。在图中光标处添加以下内容,保存并退出。
-p 9000:9000 \
重启容器,并查看容器状态,如图即为映射成功。
开启 Web HDFS 管理*
该步非必须。为了方便在网页端管理,因此开启 Web 端,默认关闭。
which hadoop cd /usr/local/hadoop/etc/hadoop/ ls vi core-site.xml
找到 Hadoop 配置文件路径,使用 Vi 编辑,若 Vi 的插入模式(Insert Mode)中,上下左右变成了 ABCD,那么可以使用以下命令即可:cp /etc/vim/vimrc ~/.vimrc 修复。
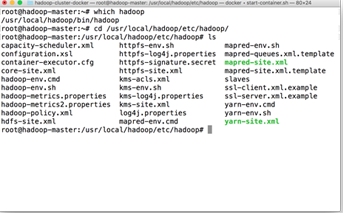
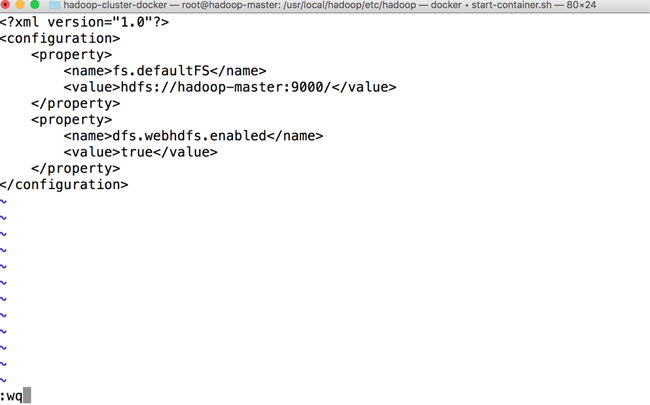
添加以下内容。
<property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property>
启动 Hadoop
同 Linux。
构建依赖
使用 Intellij IDEA 新建一个 Gradle 项目,在 Build.gradle 中加入以下依赖(对应容器 Hadoop 版本)。
compile group: 'org.apache.hadoop', name: 'hadoop-common', version: '2.7.2' compile group: 'org.apache.hadoop', name: 'hadoop-hdfs', version: '2.7.2'
Demo
import org.apache.commons.io.IOUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.junit.Before;
import org.junit.Test;
import java.io.FileInputStream;
import java.io.IOException;
import java.net.URI;
/**
* Created by kingcos on 25/03/2017.
*/
public class HDFSOperations {
FileSystem fileSystem;
@Before
public void configure() throws Exception {
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS", "hdfs://192.168.1.120:9000");
fileSystem = FileSystem.get(URI.create("hdfs://192.168.1.120:9000"), configuration, "root");
}
@Test
public void listFiles() throws IOException {
Path path = new Path("/");
RemoteIterator<LocatedFileStatus> iterator = fileSystem.listFiles(path, true);
while (iterator.hasNext()) {
LocatedFileStatus status = iterator.next();
System.out.println(status.getPath().getName());
}
}
@Test
public void rm() throws IOException {
Path path = new Path("/");
fileSystem.delete(path, true);
}
@Test
public void mkdir() throws IOException {
Path path = new Path("/demo");
fileSystem.mkdirs(path);
}
}
之后便可以通过 IDEA 直接写代码来测试,这里简单写了几个方法。
总结
在写这篇文章之前,其实我对 Docker 的概念很不了解。但是通过 Learn by do it. 大致知道了其中的概念和原理。我们完全可以构建自己的容器 Dockerfile,来部署生产和开发环境,其强大的可移植性大大缩短配置的过程。
由于个人对 Hadoop 和 Docker 的了解甚少,如有错误,希望指出,我会学习、改正。
相关推荐
-

Linux中安装配置hadoop集群详细步骤
一. 简介 参考了网上许多教程,最终把hadoop在ubuntu14.04中安装配置成功.下面就把详细的安装步骤叙述一下.我所使用的环境:两台ubuntu 14.04 64位的台式机,hadoop选择2.7.1版本.(前边主要介绍单机版的配置,集群版是在单机版的基础上,主要是配置文件有所不同,后边会有详细说明) 二. 准备工作 2.1 创建用户 创建用户,并为其添加root权限,经过亲自验证下面这种方法比较好. sudo adduser hadoop sudo vim /etc/sudoers
-
hadoop动态增加和删除节点方法介绍
上一篇文章中我们介绍了Hadoop编程基于MR程序实现倒排索引示例的有关内容,这里我们看看如何在Hadoop中动态地增加和删除节点(DataNode). 假设集群操作系统均为:CentOS 6.7 x64 Hadoop版本为:2.6.3 一.动态增加DataNode 1.准备新的DataNode节点机器,配置SSH互信,可以直接复制已有DataNode中.ssh目录中的authorized_keys和id_rsa 2.复制Hadoop运行目录.hdfs目录及tmp目录至新的DataNode 3.
-
Java执行hadoop的基本操作实例代码
Java执行hadoop的基本操作实例代码 向HDFS上传本地文件 public static void uploadInputFile(String localFile) throws IOException{ Configuration conf = new Configuration(); String hdfsPath = "hdfs://localhost:9000/"; String hdfsInput = "hdfs://localhost:9000/user/
-
详解VMware12使用三台虚拟机Ubuntu16.04系统搭建hadoop-2.7.1+hbase-1.2.4(完全分布式)
初衷 首先说明一下既然网上有那么多教程为什么要还要写这样一个安装教程呢?网上教程虽然多,但是有些教程比较老,许多教程忽略许多安装过程中的细节,比如添加用户的权限,文件权限,小编在安装过程遇到许多这样的问题所以想写一篇完整的教程,希望对初学Hadoop的人有一个直观的了解,我们接触真集群的机会比较少,虚拟机是个不错的选择,可以基本完全模拟真实的情况,前提是你的电脑要配置相对较好不然跑起来都想死,废话不多说. 环境说明 本文使用VMware® Workstation 12 Pro虚拟机创建并安装三台
-
详解搭建ubuntu版hadoop集群
用到的工具:VMware.hadoop-2.7.2.tar.jdk-8u65-linux-x64.tar.ubuntu-16.04-desktop-amd64.iso 1. 在VMware上安装ubuntu-16.04-desktop-amd64.iso 单击"创建虚拟机"è选择"典型(推荐安装)"è单击"下一步" è点击完成 修改/etc/hostname vim hostname 保存退出 修改etc/hosts 127.0.0.1 loc
-
详解从 0 开始使用 Docker 快速搭建 Hadoop 集群环境
Linux Info: Ubuntu 16.10 x64 Docker 本身就是基于 Linux 的,所以首先以我的一台服务器做实验.虽然最后跑 wordcount 已经由于内存不足而崩掉,但是之前的过程还是可以参考的. 连接服务器 使用 ssh 命令连接远程服务器. ssh root@[Your IP Address] 更新软件列表 apt-get update 更新完成. 安装 Docker sudo apt-get install docker.io 当遇到输入是否继续时,输入「Y/y」继
-
Docker快速搭建Redis集群的方法示例
什么是Redis集群 Redis集群是Redis提供的分布式数据库方案,集群通过分片(sharding)来进行数据共享,并提供复制和故障转移功能. 节点 一个Redis集群通常由多个节点(node)组成,在刚开始的时候,每个节点都是相互独立的,它们都处于一个只包含自己的集群当中,要组建一个真正可工作的集群,我们必须将各个独立的节点连接起来,构成一个包含多个节点的集群. 集群配置 配置文件 下载配置文件:https://raw.githubusercontent.com/antirez/redis
-
使用docker快速搭建Spark集群的方法教程
前言 Spark 是 Berkeley 开发的分布式计算的框架,相对于 Hadoop 来说,Spark 可以缓存中间结果到内存而提高某些需要迭代的计算场景的效率,目前收到广泛关注.下面来一起看看使用docker快速搭建Spark集群的方法教程. 适用人群 正在使用spark的开发者 正在学习docker或者spark的开发者 准备工作 安装docker (可选)下载java和spark with hadoop Spark集群 Spark运行时架构图 如上图: Spark集群由以下两个部分组成 集
-
使用sealos快速搭建K8s集群环境的过程
目录 一.前言 二.sealos 三.准备环境 sealos 安装 虚拟机设置 网络 windows网络 虚拟机的网络 网卡配置 其他配置 RPM 源 四.安装开始 五.可能遇见的问题 sealos run的时候镜像下载缓慢 六.安装测试 安装Kubernetes Dashboard 一.前言 最近在做谷粒商城项目,搞到k8s了,但是跟这老师的方法一步一步做还是搭建不起来. 我不断的试错啊,各种bug都遇见了一个也没解决我真是啊哭死! 二.sealos 直到遇见一个大佬同学,告诉我sealos几
-
使用docker compose搭建consul集群环境的例子
consul基本概念 server模式和client模式 server模式和client模式是consul节点的类型:client不是指的用户客户端. server模式提供数据持久化功能. client模式不提供持久化功能,并且实际上他也不工作,只是把用户客户端的请求转发到server模式的节点.所以可以把client模式的节点想象成LB(load balance),只负责请求转发. 通常server模式的节点需要配置成多个例如3个,5个.而client模式节点个数没有限制. server模式启
-
ubuntu docker搭建Hadoop集群环境的方法
spark要配合Hadoop的hdfs使用,然而Hadoop的特点就是分布式,在一台主机上搭建集群有点困难,百度后发现可以使用docker构建搭建,于是开搞: github项目:https://github.com/kiwenlau/hadoop-cluster-docker 参考文章://www.jb51.net/article/109698.htm docker安装 文章中安装的是docker.io 但是我推荐安装docker-ce,docker.io版本太老了,步骤如下: 1.国际惯例更新
-
Docker快速搭建PHP+Nginx+Mysql环境及踩坑
目录 准备 创建目录 配置PHP 拉取php-fpm镜像 启动php-fpm 配置Nginx 拉取Nginx镜像 配置nginx.conf 启动Nginx 配置MySQL 拉取MySQL镜像 启动MySQL 常见问题 1.thinkphp报错 Undefined class constant 'MYSQL_ATTR_INIT_COMMAND' 2.thinkphp 报错 STORAGE_WRITE_ERROR:./Application/Runtime/Cache/Home/4e64ea6a20
-
Docker Consul概述以及集群环境搭建步骤(图文详解)
目录 一.Docker consul概述 二.基于 nginx 与 consul 构建自动发现即高可用的 Docker 服务架构 一.Docker consul概述 容器服务更新与发现:先发现再更新,发现的是后端节点上容器的变化(registrator),更新的是nginx配置文件(agent) registrator:是consul安插在docker容器里的眼线,用于监听监控节点上容器的变化(增加或减少,或者宕机),一旦有变化会把这些信息告诉并注册在consul server端(使用回调和协程
-
使用docker快速部署Elasticsearch集群的方法
本文将使用Docker容器(使用docker-compose编排)快速部署Elasticsearch 集群,可用于开发环境(单机多实例)或生产环境部署. 注意,6.x版本已经不能通过 -Epath.config 参数去指定配置文件的加载位置,文档说明: For the archive distributions, the config directory location defaults to $ES_HOME/config. The location of the >config direc
-
Docker容器搭建Kafka集群的详细过程
目录 一.Kafka集群的搭建 1.拉取相关镜像 2.运行zookeeper 3.运行kafka 4.设置topic 5.进行生产者和消费者测试 一.Kafka集群的搭建 1.拉取相关镜像 docker pull wurstmeister/kafka docker pull zookeeper 2.运行zookeeper docker run -d --name zookeeper -p 2181:2181 -t zookeeper 3.运行kafka Kafka0: docker run -d