Python异步爬虫requests和aiohttp中代理IP的使用
爬虫要想爬的好,IP代理少不了。。现在网站基本都有些反爬措施,访问速度稍微快点,就会发现IP被封,不然就是提交验证。下面就两种常用的模块来讲一下代理IP的使用方式。话不多说,直接开始。
requests中代理IP的使用:
requests中使用代理IP只需要添加一个proxies参数即可。proxies的参数值是一个字典,key是代理协议(http/https),value就是ip和端口号,具体格式如下。
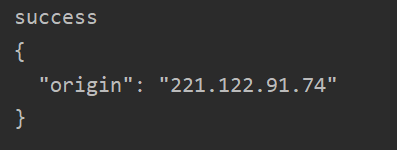
try:
response = requests.get('https://httpbin.org/ip', headers=headers,
proxies={'https':'https://221.122.91.74:9401'}, timeout=6)
print('success')
# 检测代理IP是否使用成功
# 第一种方式,返回发送请求的IP地址,使用时要在 get() 添加 stream = True
# print(response.raw._connection.sock.getpeername()[0])
# 第二种方式,直接返回测试网站的响应数据的内容
print(response.text)
except Exception as e:
print('error',e)
注意: peoxies的key值(http/https)要和url一致,不然会直接使用本机IP直接访问。
aiohttp中代理IP的使用:
由于requests模块不支持异步,迫不得已使用aiohttp,掉了不少坑。
它的使用方式和requests相似,也是在get()方法中添加一个参数,但此时的参数名为proxy,参数值是字符串,且字符串中的代理协议,只支持http,写成https会报错。
这里记录一下我的纠错历程。。
首先根据网上的使用方式,我先试了一下下面的代码。
async def func():
async with aiohttp.ClientSession() as session:
try:
async with session.get("https://httpbin.org/ip", headers=headers,
proxy='http://183.220.145.3:80', timeout=6) as response:
page_text = await response.text()
print('success')
print(page_text)
except Exception as e:
print(e)
print('error')
if __name__=='__main__':
asyncio.run(func())

修改后,再来
async def func():
con = aiohttp.TCPConnector(verify_ssl=False)
async with aiohttp.ClientSession(connector=aiohttp.TCPConnector(verify_ssl=False)) as session:
try:
async with session.get("https://httpbin.org/ip", headers=headers,
proxy='http://183.220.145.3:80', timeout=6) as response:
# print(response.raw._connection.sock.getpeername()[0])
page_text = await response.text()
print(page_text)
print('success')
except Exception as e:
print(e)
print('error')

非但没有解决反倒多了一个警告,好在改一下就好。额~懒得粘了,直接来最终版本吧。。
# 修改事件循环的策略,不能放在协程函数内部,这条语句要先执行
asyncio.set_event_loop_policy(asyncio.WindowsSelectorEventLoopPolicy())
async def func():
# 添加trust_env=True
async with aiohttp.ClientSession(connector=aiohttp.TCPConnector(ssl=False), trust_env=True) as session:
try:
async with session.get("https://httpbin.org/ip", headers=headers,
proxy='http://183.220.145.3:80', timeout=10) as response:
page_text = await response.text()
print(page_text)
print('success')
except Exception as e:
print(e)
print('error')

虽然纠错过程有点长,但好在知道怎么用了。
到此这篇关于Python异步爬虫requests和aiohttp中代理IP的使用的文章就介绍到这了,更多相关requests和aiohttp中代理IP内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python requests更换代理适用于IP频率限制的方法
有些网址具有IP限制,比如同一个IP一天只能点赞一次. 解决方法就是更换代理IP. 从哪里获得成千上万的IP呢? 百度"http代理" 可获得一大堆网站. 比如某代理网站,1天6元,可以无限提取. 把提取的IP,保存到txt文件中. 写一个方法,读取文件,存入数组中 def getProxysFromFile(): with open("proxy.txt", "r") as f: l = f.readlines() return l 比如执行某
-
基于python requests库中的代理实例讲解
直接上代码: #request代理(proxy) """ 1.启动代理服务器Heroku,相当于aliyun 2.在主机1080端口启动Socks 服务 3.将请求转发到1080端口 4.获取相应资源 首先要安装包pip install 'requests[socksv5]' """ import requests #定义一个代理服务器,所有的http及https都走socks5的协议,sock5相当于http协议,它是在会话层 #把它转到本机的
-
Python requests设置代理的方法步骤
指导文档: http://docs.python-requests.org/en/master/user/advanced/ 的Proxies http://docs.python-requests.org/en/latest/user/advanced/ 的SSL Cert Verification requests设置代理 import requests proxies = {'http': 'http://localhost:8888', 'https': 'http://localhos
-
Python3 requests模块如何模仿浏览器及代理
requests是使用Apache2 licensed 许可证的HTTP库. 用python编写. 比urllib2模块更简洁. Request支持HTTP连接保持和连接池,支持使用cookie保持会话,支持文件上传,支持自动响应内容的编码,支持国际化的URL和POST数据自动编码. 在python内置模块的基础上进行了高度的封装,从而使得python进行网络请求时,变得人性化,使用Requests可以轻而易举的完成浏览器可有的任何操作. 代码如下 import requests def xia
-
python requests 测试代理ip是否生效
代码如下所示: import requests '''代理IP地址(高匿)''' proxy = { 'http': 'http://117.85.105.170:808', 'https': 'https://117.85.105.170:808' } '''head 信息''' head = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.
-

Python异步爬虫requests和aiohttp中代理IP的使用
爬虫要想爬的好,IP代理少不了..现在网站基本都有些反爬措施,访问速度稍微快点,就会发现IP被封,不然就是提交验证.下面就两种常用的模块来讲一下代理IP的使用方式.话不多说,直接开始. requests中代理IP的使用: requests中使用代理IP只需要添加一个proxies参数即可.proxies的参数值是一个字典,key是代理协议(http/https),value就是ip和端口号,具体格式如下. try: response = requests.get('https://httpbin
-
Python异步爬虫实现原理与知识总结
一.背景 默认情况下,用get请求时,会出现阻塞,需要很多时间来等待,对于有很多请求url时,速度就很慢.因为需要一个url请求的完成,才能让下一个url继续访问.一种很自然的想法就是用异步机制来提高爬虫速度.通过构建线程池或者进程池完成异步爬虫,即使用多线程或者多进程来处理多个请求(在别的进程或者线程阻塞时). import time #串形 def getPage(url): print("开始爬取网站",url) time.sleep(2)#阻塞 print("爬取完成
-
Python爬虫简单运用爬取代理IP的实现
功能1: 爬取西拉ip代理官网上的代理ip 环境:python3.8+pycharm 库:requests,lxml 浏览器:谷歌 IP地址:http://www.xiladaili.com/gaoni/ 分析网页源码: 选中div元素后右键找到Copy再深入子菜单找到Copy Xpath点击一下就复制到XPath 我们复制下来的Xpth内容为:/html/body/div/div[3]/div[2]/table/tbody/tr[50]/td[1] 虽然可以查出来ip,但不利于程序自动爬取所有
-
Python异步爬虫多线程与线程池示例详解
目录 背景 异步爬虫方式 多线程,多进程(不建议) 线程池,进程池(适当使用) 单线程+异步协程(推荐) 多线程 线程池 背景 当对多个url发送请求时,只有请求完第一个url才会接着请求第二个url(requests是一个阻塞的操作),存在等待的时间,这样效率是很低的.那我们能不能在发送请求等待的时候,为其单独开启进程或者线程,继续请求下一个url,执行并行请求 异步爬虫方式 多线程,多进程(不建议) 好处:可以为相关阻塞的操作单独开启线程或者进程,阻塞操作就可以异步会执行 弊端:不能无限制开
-
python异步爬虫之多线程
多线程,多进程(不建议使用)优点:可以为相关阻塞的操作单独开启线程或者进程,阻塞操作可以异步执行弊端:无法无限制开启多线程或多进程.原则:线程池处理的是阻塞且耗时的操作 单线爬虫示例: import time def get_page(str): print("正在下载:",str) time.sleep(2) print('下载成功:',str) name_list = ['aa','bb','cc','dd'] start_time = time.time(
-
关于Python网络爬虫requests库的介绍
1. 什么是网络爬虫 简单来说,就是构建一个程序,以自动化的方式从网络上下载.解析和组织数据. 就像我们浏览网页的时候,对于我们感兴趣的内容我们会复制粘贴到自己的笔记本中,方便下次阅读浏览——网络爬虫帮我们自动完成这些内容 当然如果遇到一些无法复制粘贴的网站——网络爬虫就更能显示它的力量了 为什么需要网络爬虫 当我们需要做一些数据分析的时候——而很多时候这些数据存储在网页中,手动下载需要花费的时间太长,这时候我们就需要网络爬虫帮助我们自动爬取这些数据来(当然我们会过滤掉网页上那些没用的东西) 网
-
python脚本实现统计日志文件中的ip访问次数代码分享
适用的日志格式: 106.45.185.214 - - [06/Aug/2014:07:38:59 +0800] "GET / HTTP/1.0" 200 10 "-" "-" 171.104.119.22 - - [06/Aug/2014:08:55:01 +0800] "GET / HTTP/1.0" 200 10 "-" "-" 27.31.238.242 - - [06/Aug/
-
Python中利用aiohttp制作异步爬虫及简单应用
摘要: 简介 asyncio可以实现单线程并发IO操作,是Python中常用的异步处理模块.关于asyncio模块的介绍,笔者会在后续的文章中加以介绍,本文将会讲述一个基于asyncio实现的HTTP框架--aiohttp,它可以帮助我们异步地实现HTTP请求,从而使得我们的程序效率大大提高. 简介 asyncio可以实现单线程并发IO操作,是Python中常用的异步处理模块.关于asyncio模块的介绍,笔者会在后续的文章中加以介绍,本文将会讲述一个基于asyncio实现的HTTP框架--ai
-
Python网络爬虫中的同步与异步示例详解
一.同步与异步 #同步编程(同一时间只能做一件事,做完了才能做下一件事情) <-a_url-><-b_url-><-c_url-> #异步编程 (可以近似的理解成同一时间有多个事情在做,但有先后) <-a_url-> <-b_url-> <-c_url-> <-d_url-> <-e_url-> <-f_url-> <-g_url-> <-h_url-> <--i_ur
-
python中数据爬虫requests库使用方法详解
一.什么是Requests Requests 是Python语编写,基于urllib,采Apache2 Licensed开源协议的 HTTP 库.它urllib 更加方便,可以节约我们大量的工作,完全满足HTTP测试需求. 一句话--requests是python实现的简单易用的HTTP库 二.安装Requests库 进入命令行win+R执行 命令:pip install requests 项目导入:import requests 三.各种请求方式 直接上代码,不明白可以查看我的urllib的基