带你用Python实现Saga 分布式事务的方法
目录
- 分布式事务
- SAGA
- SAGA实践
- 处理网络异常
- 处理回滚
- 小结
银行跨行转账业务是一个典型分布式事务场景,假设 A 需要跨行转账给 B,那么就涉及两个银行的数据,无法通过一个数据库的本地事务保证转账的 ACID,只能够通过分布式事务来解决。
分布式事务
分布式事务在分布式环境下,为了满足可用性、性能与降级服务的需要,降低一致性与隔离性的要求,一方面遵循 BASE 理论:
- 基本业务可用性( Basic Availability )
- 柔性状态( Soft state )
- 最终一致性( Eventual consistency )
- 另一方面,分布式事务也部分遵循 ACID 规范:
- 原子性:严格遵循
- 一致性:事务完成后的一致性严格遵循;事务中的一致性可适当放宽
- 隔离性:并行事务间不可影响;事务中间结果可见性允许安全放宽
- 持久性:严格遵循
SAGA
Saga 是这一篇数据库论文SAGAS提到的一个分布式事务方案。其核心思想是将长事务拆分为多个本地短事务,由 Saga 事务协调器协调,如果各个本地事务成功完成那就正常完成,如果某个步骤失败,则根据相反顺序一次调用补偿操作。
目前可用于 SAGA 的开源框架,主要为 Java 语言,其中以 seata 为代表。我们的例子采用 go 语言,使用的分布式事务框架为https://github.com/yedf/dtm,它对分布式事务的支持非常优雅。下面来详细讲解 SAGA 的组成:
DTM 事务框架里,有 3 个角色,与经典的 XA 分布式事务一样:
- AP/应用程序,发起全局事务,定义全局事务包含哪些事务分支
- RM/资源管理器,负责分支事务各项资源的管理
- TM/事务管理器,负责协调全局事务的正确执行,包括 SAGA 正向 /逆向操作的执行
下面看一个成功完成的 SAGA 时序图,就很容易理解 SAGA 分布式事务:

SAGA实践
对于我们要进行的银行转账的例子,我们将在正向操作中,进行转入转出,在补偿操作中,做相反的调整。
首先我们创建账户余额表:
CREATE TABLE dtm_busi.`user_account` ( `id` int(11) AUTO_INCREMENT PRIMARY KEY, `user_id` int(11) not NULL UNIQUE , `balance` decimal(10,2) NOT NULL DEFAULT '0.00', `create_time` datetime DEFAULT now(), `update_time` datetime DEFAULT now() );
我们先编写核心业务代码,调整用户的账户余额
def saga_adjust_balance(cursor, uid, amount):
affected = utils.sqlexec(cursor, "update dtm_busi.user_account set balance=balance+%d where user_id=%d and balance >= -%d" %(amount, uid, amount))
if affected == 0:
raise Exception("update error, balance not enough")
下面我们来编写具体的正向操作 /补偿操作的处理函数
@app.post("/api/TransOutSaga")
def trans_out_saga():
saga_adjust_balance(c, out_uid, -30)
return {"dtm_result": "SUCCESS"}
@app.post("/api/TransOutCompensate")
def trans_out_compensate():
saga_adjust_balance(c, out_uid, 30)
return {"dtm_result": "SUCCESS"}
@app.post("/api/TransInSaga")
def trans_in_saga():
saga_adjust_balance(c, in_uid, 30)
return {"dtm_result": "SUCCESS"}
@app.post("/api/TransInCompensate")
def trans_in_compensate():
saga_adjust_balance(c, in_uid, -30)
return {"dtm_result": "SUCCESS"}
到此各个子事务的处理函数已经 OK 了,然后是开启 SAGA 事务,进行分支调用
# 这是 dtm 服务地址
dtm = "http://localhost:8080/api/dtmsvr"
# 这是业务微服务地址
svc = "http://localhost:5000/api"
req = {"amount": 30}
s = saga.Saga(dtm, utils.gen_gid(dtm))
s.add(req, svc + "/TransOutSaga", svc + "/TransOutCompensate")
s.add(req, svc + "/TransInSaga", svc + "/TransInCompensate")
s.submit()
至此,一个完整的 SAGA 分布式事务编写完成。
如果您想要完整运行一个成功的示例,那么参考这个例子yedf/dtmcli-py-sample,将它运行起来非常简单
# 部署启动 dtm # 需要 docker 版本 18 以上 git clone https://github.com/yedf/dtm cd dtm docker-compose up # 另起一个命令行 git clone https://github.com/yedf/dtmcli-py-sample cd dtmcli-py-sample pip3 install flask dtmcli requests flask run # 另起一个命令行 curl localhost:5000/api/fireSaga
处理网络异常
假设提交给 dtm 的事务中,调用转入操作时,出现短暂的故障怎么办?按照 SAGA 事务的协议,dtm 会重试未完成的操作,这时我们要如何处理?故障有可能是转入操作完成后出网络故障,也有可能是转入操作完成中出现机器宕机。如何处理才能够保障账户余额的调整是正确无问题的?
这类网络异常的妥当处理,是分布式事务中的大难题,异常情况包括三类:重复请求、空补偿、悬挂,都需要正确处理
DTM 提供了子事务屏障功能,保证上述异常情况下的业务逻辑,只会有一次正确顺序下的成功提交。(子事务屏障详情参考分布式事务最经典的七种解决方案的子事务屏障环节)
我们把处理函数调整为:
@app.post("/api/TransOutSaga")
def trans_out_saga():
with barrier.AutoCursor(conn_new()) as cursor:
def busi_callback(c):
saga_adjust_balance(c, out_uid, -30)
barrier_from_req(request).call(cursor, busi_callback)
return {"dtm_result": "SUCCESS"}
这里的 barrier_from_req(request).call(cursor, busi_callback)调用会使用子事务屏障技术,保证 busi_callback 回调函数仅被提交一次
您可以尝试多次调用这个 TransIn 服务,仅有一次余额调整。
处理回滚
假如银行将金额准备转入用户 2 时,发现用户 2 的账户异常,返回失败,会怎么样?我们调整处理函数,让转入操作返回失败
@app.post("/api/TransInSaga")
def trans_in_saga():
return {"dtm_result": "FAILURE"}
我们给出事务失败交互的时序图
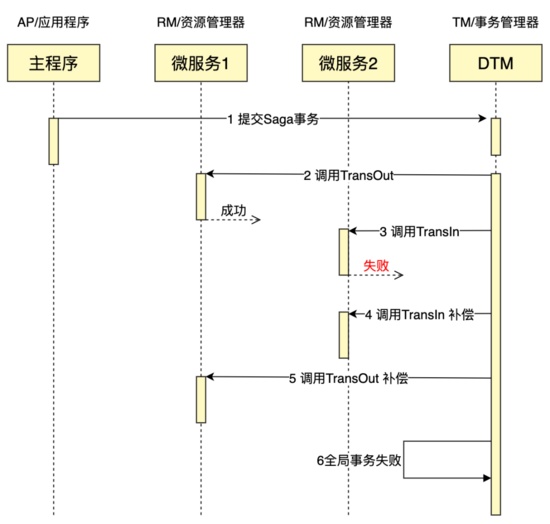
这里有一点,TransIn 的正向操作什么都没有做,就返回了失败,此时调用 TransIn 的补偿操作,会不会导致反向调整出错了呢?
不用担心,前面的子事务屏障技术,能够保证 TransIn 的错误如果发生在提交之前,则补偿为空操作;TransIn 的错误如果发生在提交之后,则补偿操作会将数据提交一次。
您可以将返回错误的 TransIn 改成:
@app.post("/api/TransInSaga")
def trans_in_saga():
with barrier.AutoCursor(conn_new()) as cursor:
def busi_callback(c):
saga_adjust_balance(c, in_uid, 30)
barrier_from_req(request).call(cursor, busi_callback)
return {"dtm_result": "FAILURE"}
最后的结果余额依旧会是对的,原理可以参考:分布式事务最经典的七种解决方案的子事务屏障环节
小结
在这篇文章里,我们介绍了 SAGA 的理论知识,也通过一个例子,完整给出了编写一个 SAGA 事务的过程,涵盖了正常成功完成,异常情况,以及成功回滚的情况。相信读者通过这边文章,对 SAGA 已经有了深入的理解。
文中使用的 dtm 是新开源的 Golang 分布式事务管理框架,功能强大,支持 TCC 、SAGA 、XA 、事务消息等事务模式,支持 Go 、python 、PHP 、node 、csharp 等语言的。同时提供了非常简单易用的接口。
阅读完此篇干货,欢迎大家访问项目https://github.com/yedf/dtm,给颗星星支持!
到此这篇关于带你用Python实现Saga 分布式事务的问题的文章就介绍到这了,更多相关Python Saga 分布式事务内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python通过zookeeper实现分布式服务代码解析
借助zookeeper可以实现服务器的注册与发现,有需求的时候调用zookeeper来发现可用的服务器,将任务均匀分配到各个服务器上去. 这样可以方便的随任务的繁重程度对服务器进行弹性扩容,客户端和服务端是非耦合的,也可以随时增加客户端. zk_server.py import threading import json import socket import sys from kazoo.client import KazooClient # TCP服务端绑定端口开启监听,同时将自己注册到z
-
Python 分布式缓存之Reids数据类型操作详解
1.Redis API 1.安装redis模块 $ pip3.8 install redis 2.使用redis模块 import redis # 连接redis的ip地址/主机名,port,password=None r = redis.Redis(host="127.0.0.1",port=6379,password="gs123456") 3.redis连接池 redis-py使用connection pool来管理对一个redis server的所有连接,避
-
python爬虫分布式获取数据的实例方法
在我们进行卫生大扫除的时候,因为工作任务较多,所以我们会进行分工,每个人负责不同的打扫项目.同样分工合作的理念,在python分布式爬虫中也得到了应用.我们需要给不同的爬虫分配指令,让它们去分头行动获取同一个网站的数据.那么这些爬虫是怎么分工搜集数据的呢?感兴趣的小伙伴,我们可以通过下面的示例进行解惑. 假设我有三台爬虫服务器A.B和C.我想让我所有的账号登录任务分散到三台服务器.让用户抓取在A和B上执行,让粉丝和关注抓取在C上执行,那么启动A.B.C三个服务器的celery worker的命令
-
python分布式编程实现过程解析
分布式编程的难点在于: 1.服务器之间的通信,主节点如何了解从节点的执行进度,并在从节点之间进行负载均衡和任务调度: 2.如何让多个服务器上的进程访问同一资源的不同部分进行执行 第一部分涉及到网络编程的底层细节 第二个问题让我联想到hdfs的一些功能. 首先分布式进程还是解决的是单机单进程无法处理的大数据量大计算量的问题,希望能加通过一份代码(最多主+从两份)来并行执行一个大任务. 这就面临两个问题,首先将程序分布到多台服务器,其次将输入数据分配给多台服务器. 第一个问题相对比较简单,毕竟程序一
-
python分布式计算dispy的使用详解
dispy,是用asyncoro实现的分布式并行计算框架. 框架也是非常精简,只有4个组件,在其源码文件夹下可以找到: dispy.py (client) provides two ways of creating "clusters": JobCluster when only one instance of dispy may run and SharedJobCluster when multiple instances may run (in separate processe
-

支持python的分布式计算框架Ray详解
项目地址:https://github.com/ray-project/ray 1.简介 Ray为构建分布式应用程序提供了一个简单.通用的API.Ray是一种分布式执行框架,便于大规模应用程序和利用先进的机器学习库. Ray通过以下方式完成这项任务: 为构建和运行分布式应用程序提供简单的原语. 使最终用户能够并行化单个机器代码,而代码更改很少到零. 在核心Ray之上包含大量应用程序.库和工具,以支持复杂的应用程序. 2.安装 安装方式比较简单: pip install ray==1.4.1 [r
-
带你用Python实现Saga 分布式事务的方法
目录 分布式事务 SAGA SAGA实践 处理网络异常 处理回滚 小结 银行跨行转账业务是一个典型分布式事务场景,假设 A 需要跨行转账给 B,那么就涉及两个银行的数据,无法通过一个数据库的本地事务保证转账的 ACID,只能够通过分布式事务来解决. 分布式事务 分布式事务在分布式环境下,为了满足可用性.性能与降级服务的需要,降低一致性与隔离性的要求,一方面遵循 BASE 理论: 基本业务可用性( Basic Availability ) 柔性状态( Soft state ) 最终一致性( Eve
-
讲解如何利用 Python完成 Saga 分布式事务
目录 1.分布式事务 2.SAGA 3.SAGA 实践 4.处理网络异常 5.处理回滚 6.小结 银行跨行转账业务是一个典型分布式事务场景,假设 A 需要跨行转账给 B,那么就涉及两个银行的数据,无法通过一个数据库的本地事务保证转账的 ACID,只能够通过分布式事务来解决. 1.分布式事务 分布式事务在分布式环境下,为了满足可用性.性能与降级服务的需要,降低一致性与隔离性的要求,一方面遵循 BASE 理论: 基本业务可用性( Basic Availability ) 柔性状态( Soft sta
-
如何用C#实现SAGA分布式事务
目录 背景 成功的 SAGA 异常的 SAGA 子事务屏障 写在最后 背景 银行跨行转账业务是一个典型分布式事务场景,假设 A 需要跨行转账给 B,那么就涉及两个银行的数据,无法通过一个数据库的本地事务保证转账的 ACID ,只能够通过分布式事务来解决. 市面上使用比较多的分布式事务框架,支持 SAGA 的,大部分都是 JAVA 为主的,没有提供 C# 的对接方式,或者是对接难度大,一定程度上让人望而却步. 下面就基于这个框架来实践一下银行转账的例子. 前置工作 dotnet add packa
-
一文带你了解Python 四种常见基础爬虫方法介绍
一.Urllib方法 Urllib是python内置的HTTP请求库 import urllib.request #1.定位抓取的url url='http://www.baidu.com/' #2.向目标url发送请求 response=urllib.request.urlopen(url) #3.读取数据 data=response.read() # print(data) #打印出来的数据有ASCII码 print(data.decode('utf-8')) #decode将相应编码格式的
-
用python完成一个分布式事务TCC
前言: 什么是分布式事务?银行跨行转账业务是一个典型分布式事务场景,假设A需要跨行转账给B,那么就涉及两个银行的数据,无法通过一个数据库的本地事务保证转账的ACID,只能够通过分布式事务来解决. 分布式事务就是指事务的发起者.资源及资源管理器和事务协调者分别位于分布式系统的不同节点之上.在上述转账的业务中,用户A-100操作和用户B+100操作不是位于同一个节点上.本质上来说,分布式事务就是为了保证在分布式场景下,数据操作的正确执行. 什么是TCC分布式事务,TCC是Try.Confirm.Ca
-
Spring中使用atomikos+druid实现经典分布式事务的方法
经典分布式事务,是相对互联网中的柔性分布式事务而言,其特性为ACID原则,包括原子性(Atomictiy).一致性(Consistency).隔离性(Isolation).持久性(Durabilit): 原子性:事务是一个包含一系列操作的原子操作.事务的原子性确保这些操作全部完成或者全部失败. 一致性:一旦事务的所有操作结束,事务就被提交.然后你的数据和资源将处于遵循业务规则的一直状态. 隔离性:因为同时在相同数据集上可能有许多事务处理,每个事务应该与其他事务隔离,避免数据破坏. 持久性:一旦事
-
spring整合atomikos实现分布式事务的方法示例
前言 Atomikos 是一个为Java平台提供增值服务的并且开源类事务管理器,主要用于处理跨数据库事务,比如某个指令在A库和B库都有写操作,业务上要求A库和B库的写操作要具有原子性,这时候就可以用到atomikos.笔者这里整合了一个spring和atomikos的demo,并且通过案例演示说明atomikos的作用. 准备工作 开发工具:idea 数据库:mysql , oracle 正文 源码地址: https://github.com/qw870602/atomikos 演示原理:通过在
-
关于MySQL与Golan分布式事务经典的七种解决方案
目录 1.基础理论 1.1 事务 1.2 分布式事务 2.分布式事务的解决方案 2.1 两阶段提交/XA 2.2 SAGA 2.3 TCC 2.4 本地消息表 2.5 事务消息 2.6 最大努力通知 2.7 AT事务模式 3.异常处理 3.1 异常情况 3.2 子事务屏障 3.3 子事务屏障原理 3.4 子事务屏障小结 4.分布式事务实践 4.1 一个SAGA事务 4.2 处理网络异常 4.3 处理回滚 5.总结 前言: 随着业务的快速发展.业务复杂度越来越高,几乎每个公司的系统都会从单体走向分
-
springboot整合shardingsphere和seata实现分布式事务的实践
各个框架版本信息 springboot: 2.1.3 springcloud: Greenwich.RELEASE seata: 1.0.0 shardingsphere:4.0.1 maven 依赖 <dependency> <!--<groupId>io.shardingsphere</groupId>--> <groupId>org.apache.shardingsphere</group
-
一文搞明白Java Spring Boot分布式事务解决方案
目录 前言 1. 什么是反向补偿 2. 基本概念梳理 3. 什么是两阶段提交 4. AT 模式 5. TCC 模式 6. XA 模式 7. Saga 模式 前言 分布式事务,咱们前边也聊过很多次了,网上其实也有不少文章在介绍分布式事务,不过里边都会涉及到不少专业名词,看的大家云里雾里,所以还是有一些小伙伴在微信上问我. 那么今天,我就再来一篇文章,和大家捋一捋这个话题.以下的内容主要围绕阿里的 seata 来和大家解释. 1. 什么是反向补偿 首先,来和大家解释一个名词,大家在看分布式事务相关资