SpringData关键字查询实现方法详解
一、创建项目并导入Jap相关依赖
1.1
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-jpa</artifactId> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid-spring-boot-starter</artifactId> <version>1.1.10</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <scope>runtime</scope> <version>5.1.27</version> </dependency>
1.2
Application.perteries配置
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
spring.datasource.username=root
spring.datasource.password=123
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/jpa?useUnicode=true&characterEncoding=utf8&useSSL=true&serverTimezone=GMT
#将sql语句展示到控制台
spring.jpa.show-sql=true
spring.jpa.database=mysql
spring.jpa.database-platform=mysql
#ddl-auto:create----每次运行该程序,没有表格会新建表格,表内有数据会清空
#ddl-auto:create-drop----每次程序结束的时候会清空表
#ddl-auto:update----每次运行程序,没有表格会新建表格,表内有数据不会清空,只会更新
#ddl-auto:validate----运行程序会校验数据与数据库的字段类型是否相同,不同会报错
spring.jpa.hibernate.ddl-auto=update
#采用哪种方言
spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.MySQL57Dialect
二、关键字查询
1.1
创建

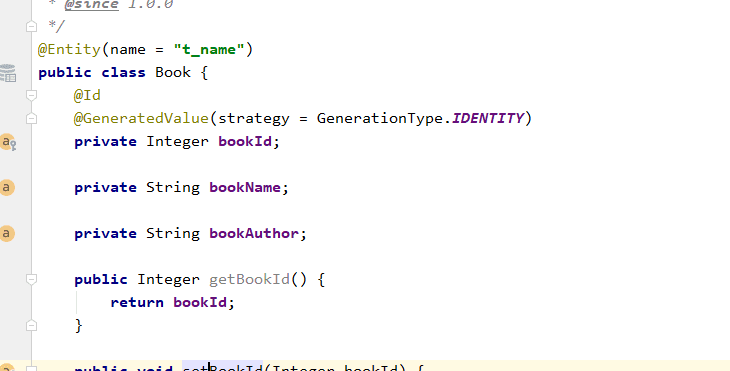
@Entity
将实体类Book创建成表,默认不指定就是类名,name指定表名
@ID
主键
@GeneratedValue
自增长
1.2
创建


1.3
JAP的功能函数


在这里定义你的查询规则就ok了
1.3.1
保存

1.3.2
修改

注:如果数据库中没有该数据则是添加,存在则是修改
1.3.3
删除

1.3.4
查询太多就举例分页把

三、自定义查询
同样还是在BookDao里写

注:nativeQuery=true代表使用sql语句查询,默认使用JPA ql查询
四、自定义添加修改
BookDao类

注:@Query @Modifying @Transactional三个注解一个不能少
@Modifying
对数据库修改操作
@Transactional
事务
图片中的两种写法都可以,第一种顺序不能颠倒
@Param不是mybatis的那个这个是jpa的
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Spring Boot 自定义数据源DruidDataSource代码
这篇文章主要介绍了Spring Boot 自定义数据源DruidDataSource代码,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一.添加依赖 <dependency> <groupId>com.alibaba</groupId> <artifactId>druid</artifactId> <version>1.0.26</version> </depend
-
Spring Data JPA分页复合查询原理解析
Spring Data JPA是Spring Data家族的一部分,可以轻松实现基于JPA的存储库. 此模块处理对基于JPA的数据访问层的增强支持. 它使构建使用数据访问技术的Spring驱动应用程序变得更加容易. 在相当长的一段时间内,实现应用程序的数据访问层一直很麻烦. 必须编写太多样板代码来执行简单查询以及执行分页和审计. Spring Data JPA旨在通过减少实际需要的工作量来显著改善数据访问层的实现. 作为开发人员,您编写repository接口,包括自定义查找器方法,Spring
-
Spring Data JPA进行数据分页与排序的方法
一.导读 如果一次性加载成千上万的列表数据,在网页上显示将十分的耗时,用户体验不好.所以处理较大数据查询结果展现的时候,分页查询是必不可少的.分页查询必然伴随着一定的排序规则,否则分页数据的状态很难控制,导致用户可能在不同的页看到同一条数据.那么,本文的主要内容就是给大家介绍一下,如何使用Spring Data JPA进行分页与排序. 二.实体定义 我们使用一个简单的实体定义:Article(文章) @Data @AllArgsConstructor @NoArgsConstructor @Bu
-

SpringBoot整合Spring Data Elasticsearch的过程详解
Spring Data Elasticsearch提供了ElasticsearchTemplate工具类,实现了POJO与elasticsearch文档之间的映射 elasticsearch本质也是存储数据,它不支持事物,但是它的速度远比数据库快得多, 可以这样来对比elasticsearch和数据库 索引(indices)--------数据库(databases) 类型(type)------------数据表(table) 文档(Document)---------------- 行(ro
-
Spring Data JPA带条件分页查询实现原理
最新Spring Data JPA官方参考手册 Version 2.0.0.RC2,2017-07-25 https://docs.spring.io/spring-data/jpa/docs/2.0.0.RC2/reference/html/ JPA参考手册 (找了半天, 在线版的只找到这个) https://www.objectdb.com/java/jpa Spring Data JPA的Specification类, 是按照Eric Evans的<领域驱动设计>书中Specificat
-
Spring data elasticsearch使用方法详解
这篇文章主要介绍了Spring data elasticsearch使用方法详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一.准备 1.添加依赖 <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-elasticsearch</artifactId> &l
-
Spring Data Jpa的四种查询方式详解
这篇文章主要介绍了Spring Data Jpa的四种查询方式详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一.调用接口的方式 1.基本介绍 通过调用接口里的方法查询,需要我们自定义的接口继承Spring Data Jpa规定的接口 public interface UserDao extends JpaRepository<User, Integer>, JpaSpecificationExecutor<User> 使用这
-
SpringData关键字查询实现方法详解
一.创建项目并导入Jap相关依赖 1.1 <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-jpa</artifactId> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifac
-
Java this 关键字的使用方法详解
Java this 关键字的使用方法详解 构造方法中的this关键字 构造方法是一个类的对象在通过new关键字创建时自动调用的,在程序中不能向调用其他方法一样通过方法名(也就是类名)来调用.但如果一个类有多个构造方法,可以在一个构造方法中通过this(paras-)来调用其他的构造方法. 使用this来调用其他构造方法有如下几个约束. 1) 只能在构造方法中通过this来调用其他构造方法,普通方法中不能使用. 2) 不能通过this递归调用构造方法,即不能在一个构造方法中通过this直接或间接调
-
MySQL联合查询实现方法详解
联合查询简单说 就是将两次查询合并在一起 例如 我们这里有一个用户表 我们先编写一段SQL select name from staff where age > 21; 查询年龄大于21的 输出结果如下 然后我们再写一段sql select name from staff where status =1; 查询 status 状态字段等于1 的 输出效果如下 然后我们可以二合一一下 select name from staff where age > 21 union all select n
-
Java super关键字的使用方法详解
构造方法中的super关键字 在Java子类的构造方法中可以通过super关键字来调用父类的构造方法.其用法为: 1) super(); 访问父类中的无参构造函数 2) super (paras-); 访问父类中的成员函数yyy super()来调用父类无参的构造方法,但即使不使用super(),默认也会调用父类无参的构造方法.父类无参的构造方法可以是自定义的无参构造方法,也可以是编译器自动生成的默认构造方法.但如果父类中定义了有参的构造方法,但没有定义无参的构造方法,这时编译器不会生成默认构造
-
Mongoose实现虚拟字段查询的方法详解
前言 不知道大家知不知道,mongoose为数据模型提供了虚拟属性, 借此可以更加一致地.方便地读写模型属性,类似于C#或Java中的访问器. 我们知道虚拟属性在Query阶段一定是查不到的,因为事实上MongoDB并没有存储这些属性. 但是否可以通过一个拦截器来实现虚拟属性的查询呢? 这个问题很有趣,而且在很多场景下都相当方便.例如: 实现一个暴力的全文检索时,需要对多个字段匹配统一查询词,该查询词可抽象为虚拟属性: 多处都需要进行同一个复杂条件的查询时,可以用虚拟属性封装该查询条件. 事实上
-
Java面向对象编程中final关键字的使用方法详解
在Java中通过final关键字来声明对象具有不变性(immutable),这里的对象包括变量,方法,类,与C++中的const关键字效果类似. immutable指对象在创建之后,状态无法被改变 可以从三个角度考虑使用final关键字: 代码本身:不希望final描述的对象所表现的含义被改变 安全:final对象具有只读属性,是线程安全的 效率:无法修改final对象本身,对其引用的操作更为高效 final 变量 定义final Object a,则a只能被初始化一次,一旦初始化,a的数据无法
-
MyBatis带参查询的方法详解
#{}占位符 类似于jdbc中通过PreparedStatement进行操作的方式, 会将sql语句中需要参数的位置使用?进行占位,后续由传进来的参数进行参数的绑定.?处绑定的都是值,不能指定表的列,转换成sql时表名会被当成字符串,会出错,防止sql注入. select username,age,password from 'tb_user' 简单类型参数 简单类型指的是: 基本数据类型, 包装类型, String, java.sql.*.当参数是简单类型时, MyBatis会忽略SQL语句中
-
在php7中MongoDB实现模糊查询的方法详解
前言 在实际开发中, 有不少的场景需要使用到模糊查询, MongoDB shell 模糊查询很简单: db.collection.find({'_id': /^5101/}) 上面这句就是查询_id以'5101'开始的内容. 在老的MogoDB中模糊查询挺简单的,这里简单记录下模糊查询的操作方式: 命令行下: db.letv_logs.find({"ctime":/uname?/i}); php操作 $query=array("name"=>new Mongo
-
MySql实现跨表查询的方法详解
复制代码 代码如下: SELECT c.id, c.order_id, c.title, c.content, c.create_time, o.last_pic FROM `orders` o , `case` c WHERE c.order_id = o.order_id ORDER BY c.id DESC LIMIT 15; 关于跨表提取字段的方法!利用order_id相同字段,提取case中的id,order_id,title,content,create_time:orders表中的
-
java关键字final使用方法详解
它所表示的是"这部分是无法修改的".不想被改变的原因有两个:效率.设计.使用到final的有三种情况:数据.方法.类. 一. final数据 有时候数据的恒定不变是很有用的,它能够减轻系统运行时的负担.对于这些恒定不变的数据我可以叫做"常量"."常量"主要应用与以下两个地方:1.编译期常量,永远不可改变.2.运行期初始化时,我们希望它不会被改变.对于编译期常量,它在类加载的过程就已经完成了初始化,所以当类加载完成后是不可更改的,编译期可以将它代入