python pdfplumber库批量提取pdf表格数据转换为excel
目录
- 需求
- 一、实现效果图
- 二、pdfplumber 库
- 三、代码实现
- 1、导入相关包
- 2、读取 pdf , 并获取 pdf 的页数
- 3、提取单个 pdf 文件,保存成 excel
- 4、提取文件夹下多个 pdf 文件,保存成 excel
- 小结
需求
想要提取 pdf 的数据,保存到 excel 中。虽然是可以直接利用 WPS 将 pdf 文件输出成 excel,但这个功能是收费的,而且如果将大量pdf转excel的时候,手动去输出是非常耗时的。我们可以利用 python 的三方工具库 pdfplumber 快速完成这个功能。
一、实现效果图
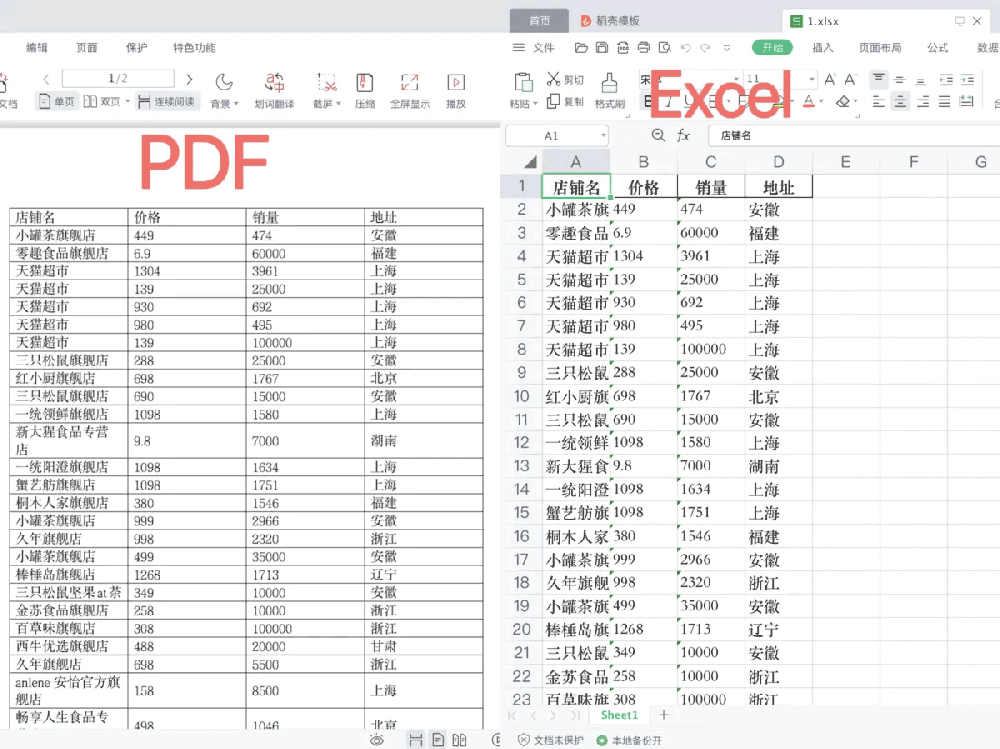
二、pdfplumber 库
pdfplumber 是一个开源 python 工具库-,可以方便地获取 pdf 的各种信息,包括文本、表格、图表、尺寸等。完成我们本文的需求,主要使用 pdfplumber 提取 pdf 表格数据。
安装命令
pip install pdfplumber
三、代码实现
1、导入相关包
import pdfplumber import pandas as pd
2、读取 pdf , 并获取 pdf 的页数
pdf = pdfplumber.open("/Users/wangwangyuqing/Desktop/1.pdf")
pages = pdf.pages
3、提取单个 pdf 文件,保存成 excel
if len(pages) > 1:
tables = []
for each in pages:
table = each.extract_table()
tables.extend(table)
else:
tables = each.extract_table()
data = pd.DataFrame(tables[1:], columns=tables[0])
data
data.to_excel("/Users/wangwangyuqing/Desktop/1.xlsx", index=False)
4、提取文件夹下多个 pdf 文件,保存成 excel
import os
import glob
path = r'/Users/wangwangyuqing/Desktop/pdf文件'
for f in glob.glob(os.path.join(path, "*.pdf")):
res = save_pdf_to_excel(f)
print(res)
def save_pdf_to_excel(path):
# print('文件名为:',path.split('/')[-1].split('.')[0] + '.xlsx')
pdf = pdfplumber.open(path)
pages = pdf.pages
if len(pages) > 1:
tables = []
for each in pages:
table = each.extract_table()
tables.extend(table)
else:
tables = each.extract_table()
data = pd.DataFrame(tables[1:], columns=tables[0])
file_name = path.split('/')[-1].split('.')[0] + '.xlsx'
data.to_excel("/Users/wangwangyuqing/Desktop/data/{}".format(file_name), index=False)
return '保存成功!'
小结
python 中还有很多库可以处理 pdf,比如 PyPDF2、pdfminer 等,本文选择pdfplumber 的原因在于能轻松访问有关 PDF 的所有详细信息,包括作者、来源、日期等,并且用于提取文本和表格的方法灵活可定制。大家可以根据手头数据需求,再去解锁 pdfplumber 的更多用法。
以上就是python pdfplumber库批量提取pdf表格数据转换为excel的详细内容,更多关于python pdfplumber库pdf转换excel的资料请关注我们其它相关文章!
相关推荐
-
python实现PDF中表格转化为Excel的方法
这几天想统计一下<中国人文社会科学期刊 AMI 综合评价报告(2018 年):A 刊评价报告>中的期刊,但是只找到了该报告的PDF版,对于表格的编辑不太方便,于是想到用Python将表格转成Excel格式. 看过别人写的博客,发现Python解析PDF有以下四种方式: -pdfminer:擅长文字的解析,把表格解析成普通的文本,没有格式: -pdf2html:把pdf解析成html,但html的标签并没有规律,解析一个表格还可以,多个表格的话不太好提取: -tabula:对于简单的表格,即单元
-

Python实现提取PDF简历信息并存入Excel
目录 介绍 1. 将PDF文档中的文字读取到word中 2. 将word中读到的文字输入到excel中 介绍 今天为大家分享一个真实的案例. 今天接到人力资源部同事的需求,想把他人投递的PDF简历资料里的关键信息数据,提取到excel表中汇总. 目标资料背景:是由求职者自行编制的简历材料,投递到人力资源部.由于其数据格式的不确定,对数据信息的采集带来了一定困难. 我的解答思路是:先从PDF文档中抓取文字信息保存到word文档中,然后再从word文档中读取文字信息保存到excel中. 1. 将PD
-
python操作mysql、excel、pdf的示例
一.学习如何定义一个对象 代码: #!/usr/bin/python # -*- coding: UTF-8 -*- # 1. 定义Person类 class Person: def __init__(self, name, age): self.name = name self.age = age def watch_tv(self): print(f'{self.name} 看电视') # 2. 定义loop函数 # 打印 1-max 中的奇数 def test_person(): pers
-
Python利用pdfplumber实现读取PDF写入Excel
目录 一.Python操作PDF 13大库对比 二.pdfplumber模块 1.安装 2. 加载PDF 3. pdfplumber.PDF类 4. pdfplumber.Page类 三.实战操作 1. 提取单个PDF全部页数 2. 批量提取多个PDF文件 一.Python操作PDF 13大库对比 PDF(Portable Document Format)是一种便携文档格式,便于跨操作系统传播文档.PDF文档遵循标准格式,因此存在很多可以操作PDF文档的工具,Python自然也不例外. Pyth
-
Python自动化办公实战案例详解(Word、Excel、Pdf、Email邮件)
目录 背景 实现过程 1)替换Word模板生成对应邀请函 2)将Word邀请函转化为Pdf格式 4)自动发送邮件 5)完整代码 总结 背景 想象一下,现在你有一份Word邀请函模板,然后你有一份客户列表,上面有客户的姓名.联系方式.邮箱等基本信息,然后你的老板现在需要替换邀请函模板中的姓名,然后将Word邀请函模板生成Pdf格式,之后编辑统一的邀请话术(邮件正文),再依次发送邀请函附件到客户邮箱,你会怎么做? 正常情况下,我们肯定是复制粘贴Excel表格中的客户姓名,之后挨个Word文档进行替换
-
Python读取pdf表格写入excel的方法
背景 今天突然想到之前被要求做同性质银行的数据分析.妈耶!十几个银行,每个银行近5年的财务数据,而且财务报表一般都是 pdf 的,我们将 pdf 中表的数据一个个的拷贝到 excel 中,再借助 excel 去进行求和求平均等聚合函数操作,完事了还得把求出来的结果再统一 CV 到另一张表中,进行可视化分析- 当然,那时风流倜傥的 老Amy 还熟练的玩转着 excel ,也是个秀儿~ 今天就思索着,如果当年我会 Python 是不是可以让我成为班级最靓的崽!用技术占领高地,HHH,所以今天我来了,
-
python pdfplumber库批量提取pdf表格数据转换为excel
目录 需求 一.实现效果图 二.pdfplumber 库 三.代码实现 1.导入相关包 2.读取 pdf , 并获取 pdf 的页数 3.提取单个 pdf 文件,保存成 excel 4.提取文件夹下多个 pdf 文件,保存成 excel 小结 需求 想要提取 pdf 的数据,保存到 excel 中.虽然是可以直接利用 WPS 将 pdf 文件输出成 excel,但这个功能是收费的,而且如果将大量pdf转excel的时候,手动去输出是非常耗时的.我们可以利用 python 的三方工具库 pdfpl
-
Python 用三行代码提取PDF表格数据
从 PDF 表格中获取数据是一项痛苦的工作.不久前,一位开发者提供了一个名为 Camelot 的工具,使用三行代码就能从 PDF 文件中提取表格数据. PDF 文件是一种非常常用的文件格式,通常用于正式的电子版文件.它能够很好的将不同的排版格式固定下来,形成版面清晰且美观的展示效果.然而,对于想要从 PDF 中提取信息的人们来说,PDF 是个噩梦,尤其是表格. 大量的学术报告.论文.分析文章都使用 PDF 展示其中的表格数据,但是对于如果想要直接从表格中复制数据则会非常麻烦.不久前,有一位开发者
-
python用pdfplumber提取pdf表格数据并保存到excel文件中
目录 pdfplumber操作pdf文件 一.pdfplumber安装及导入 二.pdfplumber基础使用 1.基础知识 2.获取pdf基础信息 3.pdfplumber提取表格数据 三.提取pdf表格数据并保存到excel中 总结 pdfplumber操作pdf文件 python开源库pdfplumber,可以较为方便地获取pdf的各种信息,包含pdf的基本信息(作者.创建时间.修改时间…)及表格.文本.图片等信息,基本可以满足较为简单的格式转换功能. 一.pdfplumber安装及导入
-
用Python提取PDF表格的方法
大家好,从PDF中提取信息是办公场景中经常需要用到的操作,也是经常又读者在后台问的一个操作. 内容少的话我们可以手动复制粘贴,但如果需要批量提取就可以考虑使用Python,之前我也转载过相关文章,提到主要就是使用pdfplumber库,今天我们再次举例讲解. 通常PDF里的表格分为图片型和文本型.文本型又分简单型和复杂型.本文就针对这三部分举例讲解. 提取简单型表格 提取较为复杂型表格 提取图片型表格 用到的模块主要有 pdfplumber pandas Tesseract PIL 文中出现的P
-
基于Python快速处理PDF表格数据
我们有下面一张PDF格式存储的表格,现在需要使用Python将它提取出来. 使用Python提取表格数据需要使用pdfplumber模块,打开CMD,安装代码如下: pip install pdfplumber 安装完之后,将需要使用的模块导入 import pdfplumberimport pandas as pd 然后打开PDF文件 # 使用with语句打开pdf文件 with pdfplumber.open("D:\\python\\cai\\yq.pdf") as pdf: #
-
Python批量提取PDF文件中文本的脚本
本文实例为大家分享了Python批量提取PDF文件中文本的具体代码,供大家参考,具体内容如下 首先需要执行命令pip install pdfminer3k来安装处理PDF文件的扩展库. import os import sys import time pdfs = (pdfs for pdfs in os.listdir('.') if pdfs.endswith('.pdf')) for pdf1 in pdfs: pdf = pdf1.replace(' ', '_').replace('-
-
Python自动化之批量生成含指定数据的word文档
目录 一.需求说明 二.开始动手动脑 三.总结 一.需求说明 在平时工作当中,经常需要处理文件,特别是Word,处理Word时会遇一类比较常见的场景:文档中大部分文字固定不变,小部分内容需要修改. 这时我们会机械的重复打开.修改.保存文档等一系列操作,内容少还可勉强接受,内容一旦多了,心里难免会心浮气躁. 今天我要给大家介绍一个秘密武器-docxtpl开发包,有了这个只需写一份模板,其他的都交给电脑自己进行. 首先需要你的电脑安装好了Python环境,并且安装好了Python开发工具. 如果你还
-
python 三种方法提取pdf中的图片
有时我们需要将一份或者多份PDF文件中的图片提取出来,如果采取在线的网站实现的话又担心图片泄漏,手动操作又觉得麻烦,其实用Python也可以轻松搞定! 今天就跟大家系统分享几种Python提取 PDF 图片的方法.其实没有非常完美的方法,每种方法提取效率都不是百分之百,因此可以考虑用多种方法进行互补,主要将涉及: 基于 fitz 库和正则搜索提取图片 基于 pdf2image 库的两种方法提取图片 基于 fitz 库和正则搜索 fitz 是 pymupdf 的子模块,需要先用命令行安装 pymu
-
Thinkphp5+PHPExcel实现批量上传表格数据功能
1.首先要下载PHPExcel放到vendor文件夹下,我的路径是:项目/vendor/PHPExcel/,把下载的PHPExcel文件放在这里 2.前端代码 <!DOCTYPE html> <html> <head> <title>批量导入数据</title> </head> <body> <form action="{:url('/index/index/importExcel')}" met
-
详解Python如何实现批量为PDF添加水印
目录 准备环境 获得经销商名字对应的列表 生成水印PDF 合并水印与目标PDF 总结 我们有时候需要把一些机密文件发给多个客户,为了避免客户泄露文件,会在机密文件中添加水印.每个客户收到的文件内容相同,但是水印都不相同.这样一来,如果资料泄露了,通过水印就知道是从谁手上泄露的. 今天,一个做市场的朋友找我咨询PDF加水印的问题,如下图所示: 他有一个Excel文件,文件里面有10000个经销商的名字,他要把价目表PDF发给这些经销商,每个经销商收到的PDF文件上面的水印都是这个经销商自己的名字.