SpringBoot使用Caffeine实现缓存的示例代码
目录
- 为什么要在应用程序中添加缓存
- 在Spring Boot应用程序中实现缓存
- SpringBoot提供了什么缓存支持?
- 添加生成依赖项
- 缓存配置
- 缓存方法结果
- 测试缓存是否正常工作
- 为什么缓存有时会很危险
- 缓存更新/失效
- 缓存复制
- 嵌入式缓存
- 远程缓存服务器
- 缓存自定义
- 缓存密钥
- 条件缓存
- @CachePut
- 缓存失效
在本博客中,我们将探讨如何使用Spring的缓存框架向任何Spring Boot应用程序添加基本缓存支持,如果没有正确实现,还将探讨缓存的一些问题。最后但并非最不重要的一点是,我们将看几个在真实场景中有用的缓存示例。
为什么要在应用程序中添加缓存
在深入探讨如何向应用程序添加缓存之前,首先想到的问题是为什么我们需要在应用程序中使用缓存。
假设有一个包含客户数据的应用程序,用户发出两个请求来获取客户的数据(id=100)。
这就是没有缓存时的情况。

如您所见,对于每个请求,应用程序都会转到数据库获取数据。从数据库获取数据是一项成本高昂的操作,因为它涉及IO。
但是,如果中间有一个缓存存储,可以在其中临时存储短时间的数据,则可以将这些往返保存到数据库并在IO时间保存。
这就是使用缓存时上述交互的样子。

在Spring Boot应用程序中实现缓存
SpringBoot提供了什么缓存支持?
- SpringBoot只提供了一个缓存抽象,您可以使用它将缓存透明、轻松地添加到Spring应用程序中。
- 它不提供实际的缓存存储。
- 但是,它可以与不同类型的缓存提供程序一起工作,如Ehcache、Hazelcast、Redis、Caffee等。
- SpringBoot的缓存抽象可以添加到方法中(使用注释)
- 基本上,在执行方法之前,Spring框架将检查方法数据是否已经缓存
- 如果是,则它将从缓存中获取数据。
- 否则它将执行该方法并缓存数据
- 它还提供了从缓存中更新或删除数据的抽象。
- 在我们当前的博客中,我们将了解如何使用Caffeine添加缓存,Caffeine是一种基于Java8的高性能、接近最优的缓存库。
您可以在 application.yaml 文件中指定使用哪个缓存提供程序来设置 spring.cache.type 属性。
但是,如果没有提供属性,Spring将根据添加的库自动检测缓存提供程序。
添加生成依赖项
现在假设您已经启动并运行了基本的Spring boot应用程序,让我们添加缓存依赖项。
打开 build.gradle 文件,并添加以下依赖项以启用Spring Boot的缓存
compile('org.springframework.boot:spring-boot-starter-cache')
接下来我们将添加对Caffeine的依赖
compile group: 'com.github.ben-manes.caffeine', name: 'caffeine', version: '2.8.5'
缓存配置
现在我们需要在Spring Boot应用程序中启用缓存。
为此,我们需要创建一个配置类并提供注释 @EnableCaching 。
@Configuration
@EnableCaching
public class CacheConfig {
}
现在这个类是一个空类,但是我们可以向它添加更多配置(如果需要)。
现在我们已经启用了缓存,让我们提供缓存名称和缓存属性的配置,如缓存大小、缓存过期时间等
最简单的方法是在 application.yaml 中添加配置
spring:
cache:
cache-names: customers, users, roles
caffeine:
spec: maximumSize=500, expireAfterAccess=60s
上述配置执行以下操作
- 将可用缓存名称限制为客户、用户和角色。将最大缓存大小设置为500。
- 当缓存中的对象数达到此限制时,将根据缓存逐出策略从缓存中删除对象。将缓存过期时间设置为1分钟。
- 这意味着项目将在添加到缓存1分钟后从缓存中删除。
还有另一种配置缓存的方法,而不是在 application.yaml 文件中配置缓存。
您可以在缓存配置类中添加并提供一个 CacheManager Bean,该Bean可以完成与上面在 application.yaml 中的配置完全相同的工作
@Bean
public CacheManager cacheManager() {
Caffeine<Object, Object> caffeineCacheBuilder =
Caffeine.newBuilder()
.maximumSize(500)
.expireAfterAccess(
1, TimeUnit.MINUTES);
CaffeineCacheManager cacheManager =
new CaffeineCacheManager(
"customers", "roles", "users");
cacheManager.setCaffeine(caffeineCacheBuilder);
return cacheManager;
}
在我们的代码示例中,我们将使用Java配置。
我们可以在Java中做更多的事情,比如配置 RemovalListener ,当一个项从缓存中删除时执行 RemovalListener ,或者启用缓存统计记录,等等。
缓存方法结果
在我们使用的示例Spring boot应用程序中,我们已经有了以下API GET /API/v1/customer/{id} 来检索客户记录。

我们将向CustomerService类的 getCustomerByd(longCustomerId) 方法添加缓存。
要做到这一点,我们只需要做两件事
1. 将注释 @CacheConfig(cacheNames=“customers”) 添加到 CustomerService 类
提供此选项将确保 CustomerService 的所有可缓存方法都将使用缓存名称“customers”
2. 向方法 Optional getCustomerById(Long customerId) 添加注释 @Cacheable
@Service
@Log4j2
@CacheConfig(cacheNames = "customers")
public class CustomerService {
@Autowired
private CustomerRepository customerRepository;
@Cacheable
public Optional<Customer> getCustomerById(Long customerId) {
log.info("Fetching customer by id: {}", customerId);
return customerRepository.findById(customerId);
}
}
另外,在方法 getCustomerById() 中添加一个 LOGGER 语句,以便我们知道服务方法是否得到执行,或者值是否从缓存返回。
代码如下: log.info("Fetching customer by id: {}", customerId);
测试缓存是否正常工作
这就是缓存工作所需的全部内容。现在是测试缓存的时候了。
启动您的应用程序,并点击客户获取url
http://localhost:8080/api/v1/customer/
在第一次API调用之后,您将在日志中看到以下行—“ Fetching customer by id ”。
但是,如果再次点击API,您将不会在日志中看到任何内容。这意味着该方法没有得到执行,并且从缓存返回客户记录。
现在等待一分钟(因为缓存过期时间设置为1分钟)。
一分钟后再次点击GETAPI,您将看到下面的语句再次被记录——“通过id获取客户”。
这意味着客户记录在1分钟后从缓存中删除,必须再次从数据库中获取。
为什么缓存有时会很危险
缓存更新/失效
通常我们缓存 GET 调用,以提高性能。
但我们需要非常小心的是缓存对象的更新/删除。
@CachePut @cacheexecute
如果未将 @CachePut/@cacheexecute 放入更新/删除方法中,GET调用中缓存返回的对象将与数据库中存储的对象不同。考虑下面的示例场景。

如您所见,第二个请求已将人名更新为“ John Smith ”。但由于它没有更新缓存,因此从此处开始的所有请求都将从缓存中获取过时的个人记录(“ John Doe ”),直到该项在缓存中被删除/更新。
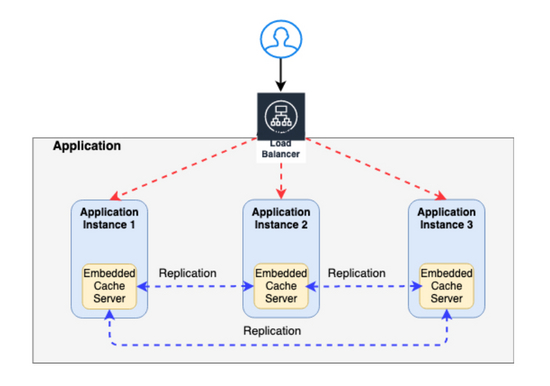
缓存复制
大多数现代web应用程序通常有多个应用程序节点,并且在大多数情况下都有一个负载平衡器,可以将用户请求重定向到一个可用的应用程序节点。

这种类型的部署为应用程序提供了可伸缩性,任何用户请求都可以由任何一个可用的应用程序节点提供服务。
在这些分布式环境(具有多个应用服务器节点)中,缓存可以通过两种方式实现
- 应用服务器中的嵌入式缓存(正如我们现在看到的)
- 远程缓存服务器
嵌入式缓存
嵌入式缓存驻留在应用程序服务器中,它随应用程序服务器启动/停止。由于每台服务器都有自己的缓存副本,因此对其缓存的任何更改/更新都不会自动反映在其他应用程序服务器的缓存中。
考虑具有嵌入式缓存的多节点应用服务器的下面场景,其中用户可以根据应用服务器为其请求服务而得到不同的结果。

正如您在上面的示例中所看到的,更新请求更新了 Application Node2 的数据库和嵌入式缓存。
但是, Application Node1 的嵌入式缓存未更新,并且包含过时数据。因此, Application Node1 的任何请求都将继续服务于旧数据。
要解决这个问题,您需要实现 CACHE REPLICATION —其中任何一个缓存中的任何更新都会自动复制到其他缓存(下图中显示为蓝色虚线)
远程缓存服务器
解决上述问题的另一种方法是使用远程缓存服务器(如下所示)。

然而,这种方法的最大缺点是增加了响应时间——这是由于从远程缓存服务器获取数据时的网络延迟(与内存缓存相比)
缓存自定义
到目前为止,我们看到的缓存示例是向应用程序添加基本缓存所需的唯一代码。
然而,现实世界的场景可能不是那么简单,可能需要进行一些定制。在本节中,我们将看到几个这样的例子
缓存密钥
我们知道缓存是密钥、值对的存储。
示例1:默认缓存键–具有单参数的方法
最简单的缓存键是当方法只有一个参数,并且该参数成为缓存键时。在下面的示例中, Long customerId 是缓存键

示例2:默认缓存键–具有多个参数的方法
在下面的示例中,缓存键是所有三个参数的SimpleKey– countryId 、 regionId 、 personId 。

示例3:自定义缓存密钥
在下面的示例中,我们将此人的 emailAddress 指定为缓存的密钥

示例4:使用 KeyGenerator 的自定义缓存密钥
让我们看看下面的示例–如果要缓存当前登录用户的所有角色,该怎么办。

该方法中没有提供任何参数,该方法在内部获取当前登录用户并返回其角色。
为了实现这个需求,我们需要创建一个如下所示的自定义密钥生成器

然后我们可以在我们的方法中使用这个键生成器,如下所示。

条件缓存
在某些用例中,我们只希望在满足某些条件的情况下缓存结果
示例1(支持 java.util.Optional –仅当存在时才缓存)
仅当结果中存在 person 对象时,才缓存 person 对象。
@Cacheable( value = "persons", unless = "#result?.id") public Optional<Person> getPerson(Long personId)
示例2(如果需要,by-pass缓存)
@Cacheable(value = "persons", condition="#fetchFromCache") public Optional<Person> getPerson(long personId, boolean fetchFromCache)
仅当方法参数“ fetchFromCache ”为true时,才从缓存中获取人员。通过这种方式,方法的调用方有时可以决定绕过缓存并直接从数据库获取值。
示例3(基于对象属性的条件计算)
仅当价格低于500且产品有库存时,才缓存产品。
@Cacheable( value="products", condition="#product.price<500", unless="#result.outOfStock") public Product findProduct(Product product)
@CachePut
我们已经看到 @Cacheable 用于将项目放入缓存。
但是,如果该对象被更新,并且我们想要更新缓存,该怎么办?
我们已经在前面的一节中看到,不更新缓存post任何更新操作都可能导致从缓存返回错误的结果。
@CachePut(key = "#person.id") public Person update(Person person)
但是如果 @Cacheable 和 @CachePut 都将一个项目放入缓存,它们之间有什么区别?
主要区别在于实际的方法执行
@Cacheable @CachePut
缓存失效
缓存失效与将对象放入缓存一样重要。
当我们想要从缓存中删除一个或多个对象时,有很多场景。让我们看一些例子。
例1
假设我们有一个用于批量导入个人记录的API。
我们希望在调用此方法之前,应该清除整个 person 缓存(因为大多数 person 记录可能会在导入时更新,而缓存可能会过时)。我们可以这样做如下
@CacheEvict( value = "persons", allEntries = true, beforeInvocation = true) public void importPersons()
例2
我们有一个Delete Person API,我们希望它在删除时也能从缓存中删除 Person 记录。
@CacheEvict( value = "persons", key = "#person.emailAddress") public void deletePerson(Person person)
默认情况下 @CacheEvict 在方法调用后运行。
到此这篇关于SpringBoot使用Caffeine实现缓存的示例代码的文章就介绍到这了,更多相关SpringBoot Caffeine缓存内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
SpringBoot集成Caffeine缓存的实现步骤
Maven依赖 要开始使用咖啡因Caffeine和Spring Boot,我们首先添加spring-boot-starter-cache和咖啡因Caffeine依赖项: <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-cache</artifactId> </depend
-

SpringBoot+SpringCache实现两级缓存(Redis+Caffeine)
1. 缓存.两级缓存 1.1 内容说明 Spring cache:主要包含spring cache定义的接口方法说明和注解中的属性说明 springboot+spring cache:rediscache实现中的缺陷 caffeine简介 spring boot+spring cache实现两级缓存 使用缓存时的流程图 1.2 Sping Cache spring cache是spring-context包中提供的基于注解方式使用的缓存组件,定义了一些标准接口,通过实现这些接口,就可以通过在方法
-
SpringBoot 缓存 Caffeine使用解析
目录 Redis和Caffeine的区别 相同点 不同点 联系 Spring Boot 缓存 Caffeine使用 1.需要添加的依赖 2.配置 3.使用Caffeine缓存 Caffeine其他常用注解 手动添加.获取.删除缓存 1.从缓存中获取数据 2.向缓存中添加数据 3.删除缓存中的数据 Redis和Caffeine的区别 相同点 两个都是缓存的方式 不同点 redis是分布式缓存,通过网络将数据存储到redis服务器内存里 caffeine是将数据存储在本地应用里 caffeine和r
-
Springboot Caffeine本地缓存使用示例
Caffeine是使用Java8对Guava缓存的重写版本性能有很大提升 一 依赖 <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-cache</artifactId> </dependency> <!-- caffeine --> <dependency> <groupId&
-
springboot集成本地缓存Caffeine的三种使用方式(小结)
目录 第一种方式(只使用Caffeine) 第二种方式(使用Caffeine和spring cache) 第三种方式(使用Caffeine和spring cache) 第一种方式(只使用Caffeine) gradle添加依赖 dependencies { implementation 'org.springframework.boot:spring-boot-starter-jdbc' implementation 'org.springframework.boot:spring-boot-s
-
SpringBoot使用Caffeine实现缓存的示例代码
目录 为什么要在应用程序中添加缓存 在Spring Boot应用程序中实现缓存 SpringBoot提供了什么缓存支持? 添加生成依赖项 缓存配置 缓存方法结果 测试缓存是否正常工作 为什么缓存有时会很危险 缓存更新/失效 缓存复制 嵌入式缓存 远程缓存服务器 缓存自定义 缓存密钥 条件缓存 @CachePut 缓存失效 在本博客中,我们将探讨如何使用Spring的缓存框架向任何Spring Boot应用程序添加基本缓存支持,如果没有正确实现,还将探讨缓存的一些问题.最后但并非最不重要的一点是,
-
springboot 使用自定义的aspect的示例代码
对某个类型中的方法进行拦截,然后加入固定的业务逻辑,这是AOP面向切面编程可以做的事,在springboot里实现aop的方法也有很多, spring-boot-starter-aop 或者 aspectjweaver 都是可以实现的,不过我们在实现之前,先来看一下aop里的几个概念. 概念 切面(Aspect):是指横切多个对象的关注点的一个模块化,事务管理就是J2EE应用中横切关注点的很好示例.在Spring AOP中,切面通过常规类(基本模式方法)或者通过使用了注解@Aspect的常规类来
-
MyBatis整合Redis实现二级缓存的示例代码
MyBatis框架提供了二级缓存接口,我们只需要实现它再开启配置就可以使用了. 特别注意,我们要解决缓存穿透.缓存穿透和缓存雪崩的问题,同时也要保证缓存性能. 具体实现说明,直接看代码注释吧! 1.开启配置 SpringBoot配置 mybatis: configuration: cache-enabled: true 2.Redis配置以及服务接口 RedisConfig.java package com.leven.mybatis.api.config; import com.fasterx
-
SpringBoot文件分片上传的示例代码
目录 背景 文件MD5计算 文件分片切割 文件分片接收 检查分片 保存分片 合并分片 云文件分片上传 阿里云OSS 华为云OBS Minio 背景 最近好几个项目在运行过程中客户都提出文件上传大小的限制能否设置的大一些,用户经常需要上传好几个G的资料文件,如图纸,视频等,并且需要在上传大文件过程中进行优化实时展现进度条,进行技术评估后针对框架文件上传进行扩展升级,扩展接口支持大文件分片上传处理,减少服务器瞬时的内存压力,同一个文件上传失败后可以从成功上传分片位置进行断点续传,文件上传成功后再次上
-
SpringBoot实现WebSocket即时通讯的示例代码
目录 1.引入依赖 2.WebSocketConfig 开启WebSocket 3.WebSocketServer 4.测试连接发送和接收消息 5.在线测试地址 6.测试截图 1.引入依赖 <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-websocket</artifactId> </dependency>
-
SpringBoot 签到奖励实现方案的示例代码
前言 最近在做社交业务,用户进入APP后有签到功能,签到成功后获取相应的奖励: 项目状况:前期尝试业务阶段: 特点: 快速实现(不需要做太重,满足初期推广运营即可) 快速投入市场去运营 用户签到: 用户在每次启动时查询签到记录(规则:连续7日签到从0开始,签到过程中有断签从0开始) 如果今日未签到则提示用户可以进行签到 用户签到获取相应的奖励 提到签到,脑海中首先浮现特点: 需要记录每位用户每天的签到情况 查询时根据规则进行签到记录情况 需求&流程设计&技术实现方案 需求原型图 查询签到记
-
webpack+express实现文件精确缓存的示例代码
由于最近开发的个人博客(Vue + node)在使用过程中,发现网络加载有点慢,所以打算对它进行一次优化.本次优化的目标如下: index.html 设置成 no-cache,这样每次请求的时候都会比对一下 index.html 文件有没变化,如果没变化就使用缓存,有变化就使用新的 index.html 文件. 其他所有文件一律使用长缓存,例如设置成缓存一年 maxAge: 1000 * 60 * 60 * 24 * 365. 前端代码使用 webpack 打包,根据文件内容生成对应的文件名,每
-
Springboot实现Shiro整合JWT的示例代码
写在前面 之前想尝试把JWT和Shiro结合到一起,但是在网上查了些博客,也没太有看懂,所以就自己重新研究了一下Shiro的工作机制,然后自己想了个(傻逼)办法把JWT和Shiro整合到一起了 另外接下来还会涉及到JWT相关的内容,我之前写过一篇博客,可以看这里:Springboot实现JWT认证 Shiro的Session机制 由于我的方法是改变了Shiro的默认的Session机制,所以这里先简单讲一下Shiro的机制,简单了解Shiro是怎么确定每次访问的是哪个用户的 Servlet的Se
-
Springboot实现XSS漏洞过滤的示例代码
背景 前阵子做了几个项目,终于开发完毕,进入了测试阶段,信心满满将项目部署到测试环境,然后做了安全测评之后..... (什么!你竟然说我代码不安全???) 然后测出了 Xss漏洞 安全的问题 解决方案 场景:可以在页面输入框输入JS脚本, 攻击者可以利用此漏洞执行恶意的代码 ! 问题演示 所以我们要对于前端传输的参数做处理,做统一全局过滤处理 既然要过滤处理,我们首先需要实现一个自定义过滤器 总共包含以下四部分 XssUtil XssFilterAutoConfig XssHttpSe
-
vue移动端项目中如何实现页面缓存的示例代码
背景 在移动端中,页面跳转之间的缓存是必备的一个需求. 例如:首页=>列表页=>详情页. 从首页进入列表页,列表页需要刷新,而从详情页返回列表页,列表页则需要保持页面缓存. 对于首页,一般我们都会让其一直保持缓存的状态. 对于详情页,不管从哪个入口进入,都会让其重新刷新. 实现思路 说到页面缓存,在vue中那就不得不提keep-alive组件了,keep-alive提供了路由缓存功能,本文主要基于它和vuex来实现应用里的页面跳转缓存. vuex里维护一个数组cachePages,用以保存当前