Python办公自动化批量处理文件实现示例
目录
- 引言
- 需求分析
- Python实现
- 结束语
引言
要说在工作中最让人头疼的就是用同样的方式处理一堆文件夹中文件,这并不难,但就是繁。所以在遇到机械式的操作时一定要记得使用Python来合理偷懒!今天我将以处理微博热搜数据来示例如何使用Python批量处理文件夹中的文件,主要将涉及:
- Python批量读取不同文件夹()
- Pandas数据处理()
- Python操作Markdown文件()
需求分析
首先来说明一下需要完成的任务,下面是我们的文件夹结构
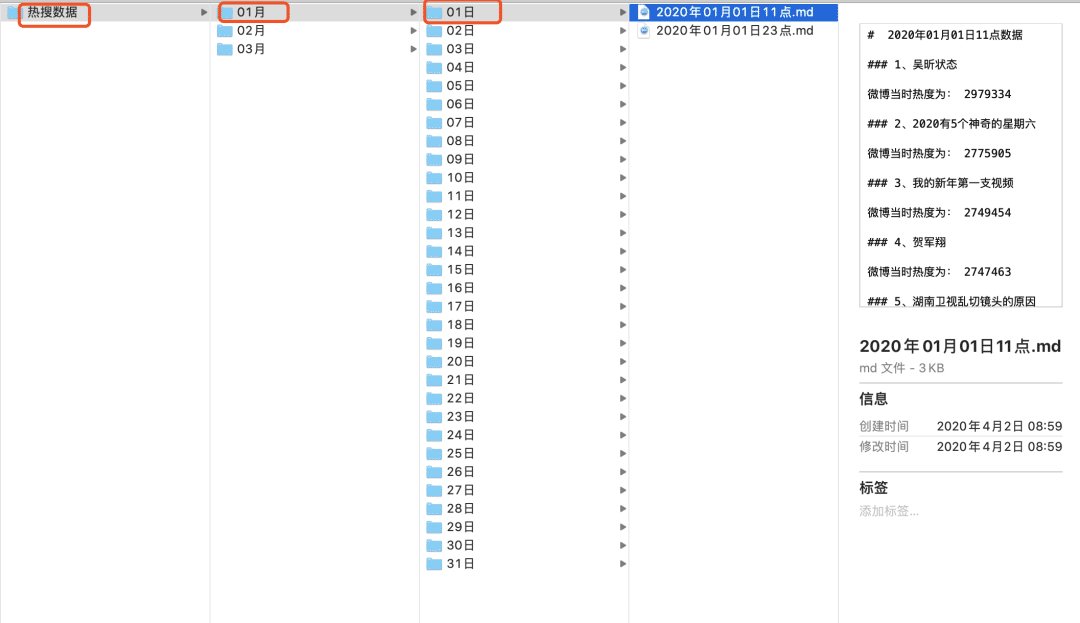
因为微博历史热搜是没有办法去爬的,所以只能写一个爬虫每天定时爬取热搜并保存,所以在我当时分析数据时使用的就是上图展示的数据,每天的数据以套娃形式被保存在三级目录下,并且热搜是以markdown文件存储的,打开是这样

而我要做的就是将这三个月的微博热搜数据处理成这样
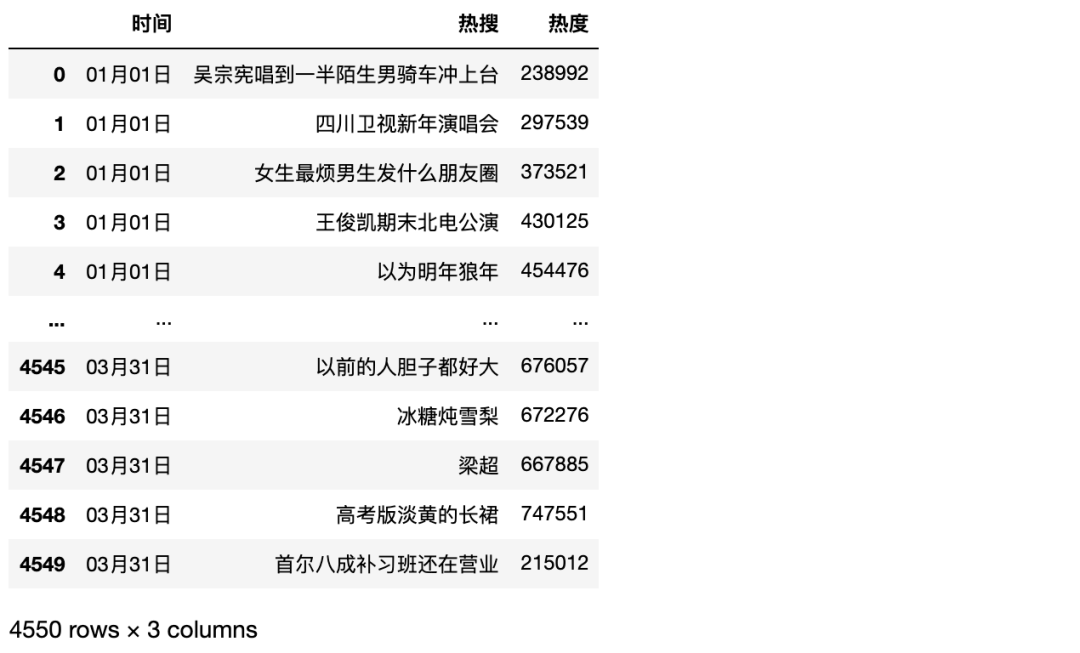
这困难吗,手动的话无非是依次点三下进入每天的数据文件夹再打开md文件手动复制粘贴进Excel,不就几万条数据,大不了一天不吃饭也能搞定!现在我们来看看如何用Python光速处理。
Python实现
在操作之前我们来思考一下如何使用Python实现,其实和手动的过程类似:先读取全部文件,再对每一天的数据处理、保存。所以第一步就是将我们需要的全部文件路径提取出来,首先导入相关库
import pandas as pd import os import glob from pathlib import Path
读取全部文件名的方法有很多比如使用OS模块

但是由于我们是多层文件夹,使用OS模块只能一层一层读取,要写多个循环从而效率不高,所以我们告别os.path使用Pathlib来操作,三行代码就能搞定,看注释
from pathlib import Path
p = Path("/Users/liuhuanshuo/Desktop/热搜数据/") #初始化构造Path对象
FileList=list(p.glob("**/*.md")) #得到所有的markdown文件`</pre>
来看下结果
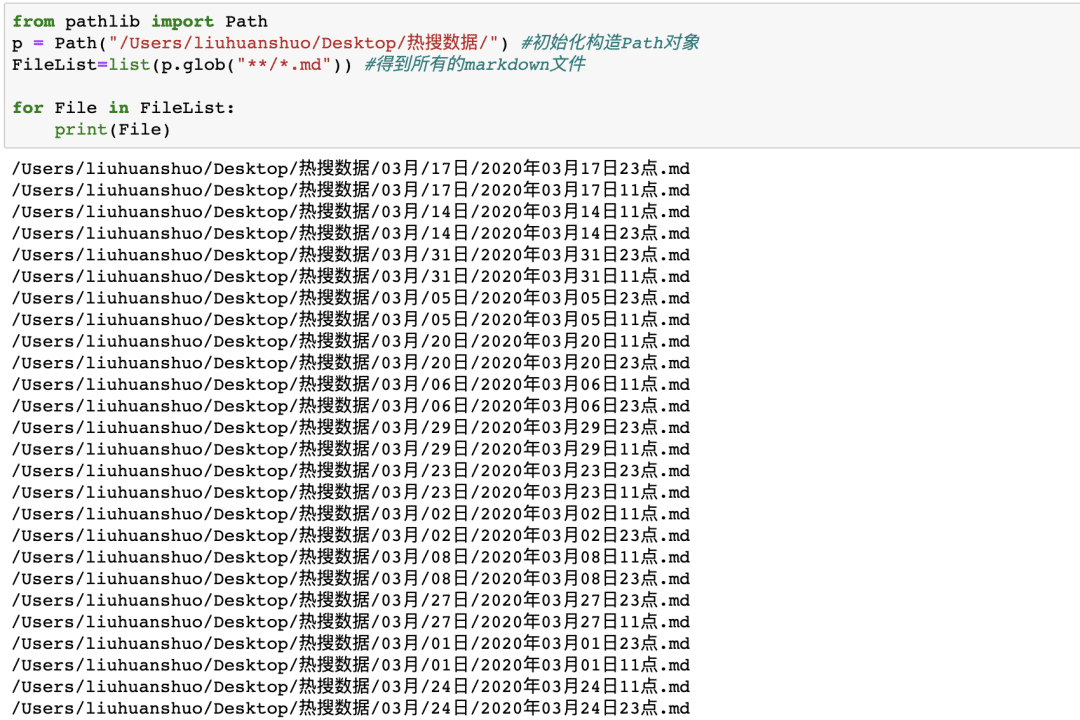
成功读取了热搜数据下多层文件夹中的全部md文件!但是新的问题来了,每天有两条热搜汇总,一个11点一个23点,考虑到会有重合数据所以我们在处理之前先进行去重,而这就简单了,不管使用正则表达式还是按照奇偶位置提取都行,这里我是用lambda表达式一行代码搞定
filelist = list(filter(lambda x: str(x).find("23点") >= 0, FileList))
现在我们每天就只剩下23点的热搜数据,虽然是markdown文件,但是Python依旧能够轻松处理,我们打开其中一个来看看

打开方式和其他文件类似使用with语句,返回一个list,但是这个list并不能直接为我们所用,第一个元素包含时间,后面每天的热搜和热度也不是直接存储,含有markdown语法中的一些没用的符号和换行符,而清洗这些数据就是常规操作了,使用下面的代码即可,主要就是使用正则表达式,看注释
with open(file) as f:
lines = f.readlines()
lines = [i.strip() for i in lines] #去除空字符
data = list(filter(None, lines))
del data[0]
data = data[0:100]
date = re.findall('年(.+)2',str(file))[0]
content = data[::2] #奇偶分割
rank = data[1::2]
#提取内容与排名
for i in range(len(content)):
content[i] = re.findall('、(.+)',content[i])[0]
for i in range(len(rank)):
rank[i] = re.findall(' (.+)',rank[i])[0]`
最后只需要写一个循环遍历每一天的文件并进行清洗,再创建一个DataFrame用于存储每天的数据即可
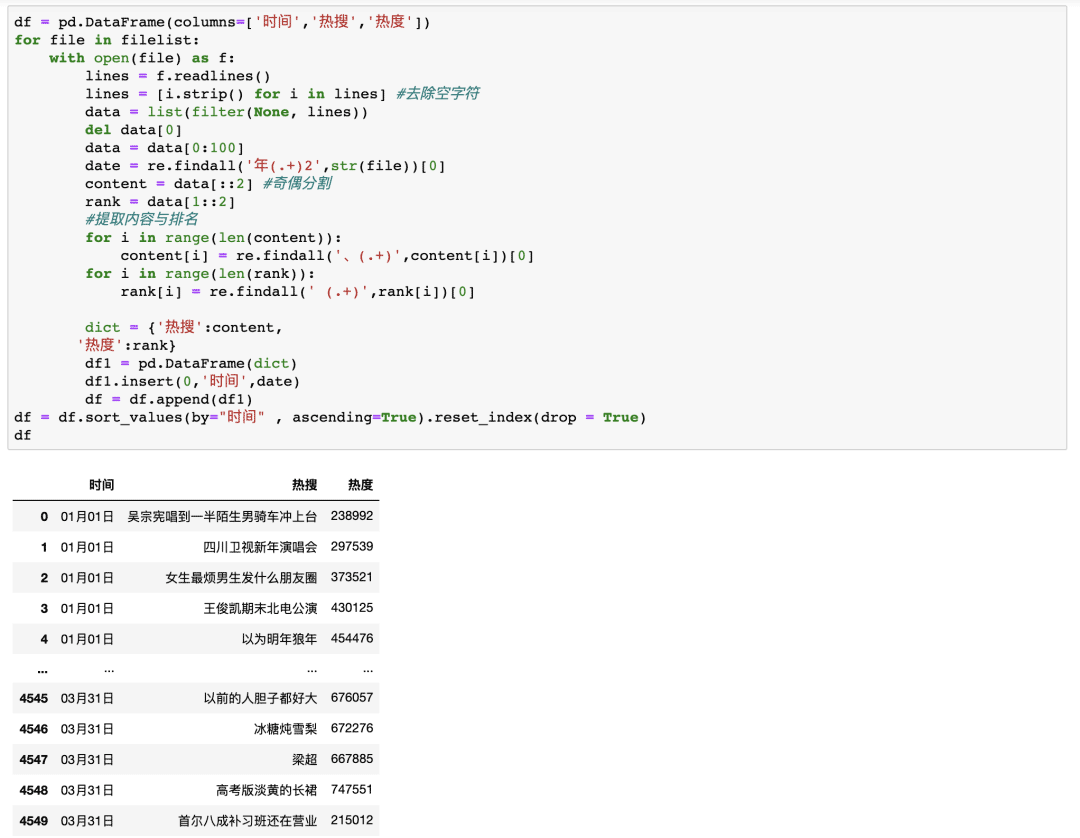
可以看到,并没有使用太复杂的代码就成功实现了我们的需求!
结束语
以上就是使用Python再一次解放双手并成功偷懒的案例,可能读取Markdown文件在你的日常工作中并用不到,但是通过本案例希望你能学会如何批量处理文件夹,批量读取清洗数据。更重要的是在你的工作学习中,遇到需要重复操作的任务时,是否能够想起使用Python来自动化解决
以上就是Python办公自动化批量处理文件实现示例的详细内容,更多关于Python办公自动化批量处理文件的资料请关注我们其它相关文章!
相关推荐
-

Python办公自动化处理的10大场景应用示例
目录 引言 1.Python处理Excel数据 2.Python处理PDF文本 3.Python处理Email 4.Python处理数据库 5.Python处理批量文件 6.Python控制鼠标 7.Python控制键盘 8.Python压缩文件 9.Python爬取网络数据 10.Python处理图片图表 小结 引言 知乎上有个热门问题,Python 未来会成为大众办公常用编程工具吗? 在编程世界里,Python已经是名副其实的网红了.曾经一个学汉语言的研究生,问我怎么学Python,因为他们
-
Python实现Word表格转成Excel表格的示例代码
准备工作 pip install docx pip install openpyxl 具体代码 # 没有的先pip install 包名称 from docx import Document from openpyxl import Workbook document = Document('Docx文件路径.dicx') count = 0 tables = [] wb = Workbook() ws = wb.active # 设置列数,可以指定列名称,有几列就设置几个, # A对应列1,B
-
Python八个自动化办公的技巧
目录 导语 1.Word文档doc转docx 1.1 导入工具包 1.2 获取文件夹下面所有doc文件明细 1.3 转换文件 2.文字地址批量转经纬度 2.1 导入工具包 2.2 定义转换函数 2.3 地址转换 3.经纬度计算距离 3.1 导入工具包 3.2 读取数据 3.3 计算距离 4.百度经纬度转高德经纬度 4.1 工具包 4.2 定义函数 4.3 单个转换 4.4 批量转换 5.Excel文件批量合并 5.1 工具包 5.2 获取文件列表 5.3 转换存储数据 6.Word文件批量转pd
-
Python 自动化处理Excel和Word实现自动办公
今天我来分享一些Python办公自动化的方法,欢迎收藏学习,喜欢点赞支持,欢迎畅聊. Openpyxl Openpyxl 可以说是 Python 中最通用的工具模块了,它使与 Excel 交互pip install openpyxl pip install python-docx简直就像在公园里漫步一样. 有了它,你就可以读写所有当前和传统的 excel 格式,即 xlsx 和 xls. Openpyxl 允许填充行和列.执行公式.创建 2D 和 3D 图表.标记轴和标题,以及大量可以派上用场的
-
拿来就用!Python批量合并PDF的示例代码
大家好,今天分享一个实用的办公脚本:将多个PDF合并为一个PDF,例如我手上现在有如下3个PDF分册,需要整合成一个完整的PDF 如果换成你操作的话,是不是打开百度搜索:PDF合并,然后去第三方网站操作,可能会收费不说还担心文件泄漏,现在有请Python出场,简单快速,光速合并,拿走就用! 首先导入需要的库和路径设置 import os from PyPDF2 import PdfFileReader, PdfFileWriter if __name__ == '__main__': # 设置存
-
Python自动化办公之Word文件内容的读取
目录 前言 利用 python 批量读取文件 word利器之python-docx python-docx 安装 python-docx 之 Document python-docx 之段落内容读取 python-docx 之表格内容读取 前言 前面几个章节我们学习了对于普通文件的操作,比如说文件的创建.复制粘贴.裁剪粘贴.文件名的重命名.删除等等.另外还学习了一些基本练习,如何查找文件.如何按照内容查找文件等等. 在本章节及后续,将开始学习一些特殊文件的自动化相关操作.如 word.excel
-
Python办公自动化批量处理文件实现示例
目录 引言 需求分析 Python实现 结束语 引言 要说在工作中最让人头疼的就是用同样的方式处理一堆文件夹中文件,这并不难,但就是繁.所以在遇到机械式的操作时一定要记得使用Python来合理偷懒!今天我将以处理微博热搜数据来示例如何使用Python批量处理文件夹中的文件,主要将涉及: Python批量读取不同文件夹() Pandas数据处理() Python操作Markdown文件() 需求分析 首先来说明一下需要完成的任务,下面是我们的文件夹结构 因为微博历史热搜是没有办法去爬的,所以只能写
-
Python之批量创建文件的实例讲解
批量创建文件其实很简单,只需要按照需要创建写文件.写完关闭当前写文件.创建新的写文件.写完关闭当前文件...不断循环即可,以下是一个简单例子,将大文件big.txt按照每1000行分割成一个个小文件. 具体做法如下: # -*- coding: utf-8 -*- index = 0 count = 0 f_in = open("%d.txt" % index, "w") with open("big.txt", "r") a
-
Python实现自动化整理文件的示例代码
目录 自动化整理计算机文件 1. 文件的自动分类 2. 文件和文件夹的快速查找 3. 自动清理重复文件 4. 批量转换图片格式 5. 按拍摄日期自动分类图片 自动化整理计算机文件 通过Python编程完成文件的自动分类.文件和文件夹的快速查找.重复文件的清理.图片格式的转换等常见工作. 1. 文件的自动分类 根据文件的扩展名将文件分类整理到不同文件夹中. 使用os和shutil模块 os模块提供了许多操作文件和文件夹的函数,可对文件或文件夹进行新建.删除.查看属性以及查找路径等操作. shuti
-
Python实现批量下载文件
Python实现批量下载文件 #!/usr/bin/env python # -*- coding:utf-8 -*- from gevent import monkey monkey.patch_all() from gevent.pool import Pool import requests import sys import os def download(url): chrome = 'Mozilla/5.0 (X11; Linux i86_64) AppleWebKit/537.36
-
Python实现批量转换文件编码的方法
本文实例讲述了Python实现批量转换文件编码的方法.分享给大家供大家参考.具体如下: 这里将某个目录下的所有文件从一种编码转换为另一种编码,然后保存 import os import shutil def match(config,fullpath,type): flag=False if type == 'exclude': for item in config['src']['exclude']: if fullpath.startswith(config['src']['path']+o
-
python实现批量改文件名称的方法
本文实例讲述了python实现批量改文件名称的方法.分享给大家供大家参考.具体分析如下: 发现python中提供了大量的模块函数,有时候一些系统操作在python中非常简单 下面的文件关键是要放到要操作的目录下, 下面是把当前目录下的图片批量命名,从00开始,其中小于10 的我们在名称前面补零,或者可以利用os设置路径 #-*- coding: UTF-8 -*- import os filenames = os.listdir(os.getcwd()) for name in filename
-
python 自动批量打开网页的示例
如下所示: import webbrowser import codecs import time with open("test.txt") as fp: for ebayno in fp: url = 'http://ebay.com/itm/'+ebayno.strip() time.sleep(1) #打开间隔时间 webbrowser.open(url) #打开网页 以上这篇python 自动批量打开网页的示例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多
-
python scp 批量同步文件的实现方法
该脚本用于将源主机列表路径下的所有文件同步于目标主机的/tmp下面 #!/usr/bin/python # -*- coding:utf-8 -*- import pexpect import os import os.path src_path = ['/tmp/', '/opt/', '/root/'] dest_host = "192.168.143.201" dest_path = "/tmp" for path in src_path: file_list
-
python 实现批量xls文件转csv文件的方法
引言:以前写的一个批量xls转csv的python简单脚本,用的是python2.7 #coding=utf-8 import os import time import logging import xlrd import csv #xls文件存放路径 INPUTPATH= u"D:\\lsssl\\桌面\\xls文件" #生成的csv文件存放路径 OUTPATH = u"D:\\lsssl\桌面\\csv" class changeCenter: def __i
-
python实现批量移动文件
本文通过实例为大家分享了python实现批量移动文件的具体代码,供大家参考,具体内容如下 任务:每个大文件夹下有许多小文件夹,将小文件夹里的pdf文件移动到指定文件夹.如图: 最终效果: 废话不多说 上源码: import os import shutil path_main = r"C:\Users\e2164\Desktop\待处理文件夹"#待处理文件夹路径 filelist_main = os.listdir(path_main) #将"待处理文件夹"下的文件