浅谈SciPy中的optimize.minimize实现受限优化问题
问题描述:有一批样本x,每个样本都有几个固定的标签,如(男,24岁,上海),需要从中抽取一批样本,使样本总的标签比例满足分布P(x),如(男:女=49%:51%、20岁:30岁=9%:11%、..........)
采用KL-散度作为优化目标函数。
KL-散度又叫相对熵
KL-散度在机器学习中,P用来表示样本的真实分布,比如[1,0,0]表示当前样本属于第一类。Q用来表示模型所预测的分布,比如[0.7,0.2,0.1]
KL-散度直观的理解就是如果用P来描述样本,那么就非常完美。而用Q来描述样本,虽然可以大致描述,但是不是那么的完美,信息量不足,需要额外的一些“信息增量”才能达到和P一样完美的描述。如果我们的Q通过反复训练,也能完美的描述样本,那么就不再需要额外的“信息增量”,Q等价于P。
公式:
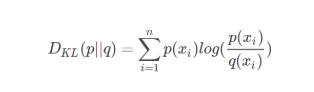
使用SciPy中的optimize.minimize来进行优化。
def minimize(fun, x0, args=(), method=None, jac=None, hess=None,
hessp=None, bounds=None, constraints=(), tol=None,
callback=None, options=None):
几个重要的参数:
fun:目标函数(he objective function to be minimized);
x0:参数初始值(Initial guess. Array of real elements of size (n,));
bounds:参数取值范围限制(Bounds on variables for L-BFGS-B, TNC, SLSQP and trust-constr methods.)
constraints:约束函数(Constraints definition (only for COBYLA, SLSQP and trust-constr)
Constraints for COBYLA, SLSQP are defined as a list of dictionaries. Each dictionary with fields: type : str Constraint type: 'eq' for equality, 'ineq' for inequality. fun : callable The function defining the constraint. jac : callable, optional The Jacobian of `fun` (only for SLSQP). args : sequence, optional Extra arguments to be passed to the function and Jacobian. )
tol : 目标函数误差范围,控制迭代结束(optional Tolerance for termination. For detailed control, use solver-specific options.) options : 其他一些可选参数(dict, optional A dictionary of solver options. All methods accept the following generic options:)
求解过程:
定义优化函数:
def obj_function(x): 其中x为要优化的变量,在本问题中有480类的样本(如:男,24岁,上海),每类样本10-1000个不等,x为每类抽取的比例。要从中抽取50000个样本,满足22个约束条件(男:女=50%:50%、20岁:30岁=9%:11%等等)。
例如:男性要占总样本的50%,则 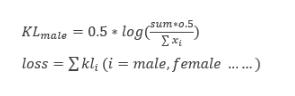
选择优化函数。SciPy中可以使用bounds参数的算法有:L-BFGS-B, TNC, SLSQP and trust-constr,可以使用constraints 参数的算法有: COBYLA, SLSQP and trust-constr
调参:optimize.minimize有统一的参数,但每个优化算法都有自己特有的参数,可以看源码中的参数列表。
运行:res = optimize.minimize(sample_fun, np.array(x0), bounds=bound, method='L-BFGS-B', tol=1e-11, options={'disp': True, 'maxiter': 300, 'maxfun': 1500000}),最终的结果保存在res.x中
如果程序没达到指定的迭代次数就停止,可能有两种原因:
STOP: TOTAL NO. of f AND g EVALUATIONS EXCEEDS LIMIT 增大参数maxfun;
CONVERGENCE: REL_REDUCTION_OF_F_<=_FACTR*EPSMCH 调小参数tol
以上这篇浅谈SciPy中的optimize.minimize实现受限优化问题就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
python统计函数库scipy.stats的用法解析
背景 总结统计工作中几个常用用法在python统计函数库scipy.stats的使用范例. 正态分布 以正态分布的常见需求为例了解scipy.stats的基本使用方法. 1.生成服从指定分布的随机数 norm.rvs通过loc和scale参数可以指定随机变量的偏移和缩放参数,这里对应的是正态分布的期望和标准差.size得到随机数数组的形状参数.(也可以使用np.random.normal(loc=0.0, scale=1.0, size=None)) In [4]: import numpy a
-
浅谈SciPy中的optimize.minimize实现受限优化问题
问题描述:有一批样本x,每个样本都有几个固定的标签,如(男,24岁,上海),需要从中抽取一批样本,使样本总的标签比例满足分布P(x),如(男:女=49%:51%.20岁:30岁=9%:11%...........) 采用KL-散度作为优化目标函数. KL-散度又叫相对熵 KL-散度在机器学习中,P用来表示样本的真实分布,比如[1,0,0]表示当前样本属于第一类.Q用来表示模型所预测的分布,比如[0.7,0.2,0.1] KL-散度直观的理解就是如果用P来描述样本,那么就非常完美.而用Q来描述样本
-
浅谈python中scipy.misc.logsumexp函数的运用场景
scipy.misc.logsumexp函数的输入参数有(a, axis=None, b=None, keepdims=False, return_sign=False),具体配置可参见这里,返回的值是np.log(np.sum(np.exp(a))). 这里需要强调的是使用该函数的场景: 一般来说,该函数主要用于非常小的数值的运算(比如蒙特卡洛取样样本).在这种情况下,将数据保持log处理是必须的.所以这时你如果想将数组中的数据累加求和就需要这样计算log(sum(exp(a))),但这样做就
-

浅谈Angular中ngModel的$render
在我开始着手ngModel的领域时候,有一个问题很令我纠结,那就是$render()到底是做什么的呢?查了很多资料都只是简单的描述一下,这就令我很纠结了,终于在一个阳光明媚的晚上,我终于解决了这个大问题 那么这个$render方法到底是干什么的呢?他的用处就是在$viewValue改变的时候可以重新绑定model数据,但是我们要注意一点($viewValue和DOM节点的value是不同的),我觉得他们的区别有点类似setTimeout和$timeout的区别,但是又不太一样.ps:其实mode
-
浅谈Java中Unicode的编码和实现
Unicode的编码和实现 大概来说,Unicode编码系统可分为编码方式和实现方式两个层次. 编码方式 字符是抽象的最小文本单位.它没有固定的形状(可能是一个字形),而且没有值."A"是一个字符,"€"也是一个字符.字符集是字符的集合.编码字符集是一个字符集,它为每一个字符分配一个唯一数字. Unicode 最初设计是作为一种固定宽度的 16 位字符编码.也就是每个字符占用2个字节.这样理论上一共最多可以表示216(即65536)个字符.上述16位统一码字符构成基
-
浅谈python中copy和deepcopy中的区别
在下是个编程爱好者,最近将魔爪伸向了Python编程.....遇到copy和deepcopy感到很困惑,现在针对这两个方法进行区分,一种是浅复制(copy),一种是深度复制(deepcopy). 首先说一下deepcopy,所谓的深度复制,在这里我理解的是完全复制然后变成一个新的对象,复制的对象和被复制的对象没有任何关系,彼此之间无论怎么改变都相互不影响. 然后说一下copy,在这里我分为两类来说,一种是字典数据类型的copy函数,一种是copy包的copy函数. 一.字典数据类型的copy函数
-
浅谈python中列表、字符串、字典的常用操作
列表操作如此下: a = ["haha","xixi","baba"] 增:a.append[gg] a.insert[1,gg] 在下标为1的地方,新增 gg 删:a.remove(haha) 删除列表中从左往右,第一个匹配到的 haha del a.[0] 删除下标为0 对应的值 a.pop(0) 括号里不写内容,默认删除最后一个,写了,就删除对应下标的内容 改:a.[0] = "gg" 查:a[0] a.index(&q
-
浅谈PHP中的数据传输CURL
确认是否安装了CURL扩展 Linux下命令: [root@fengniu020 ~]# php -i | grep -i curl Additional .ini files parsed => /etc/php.d/curl.ini, curl cURL support => enabled cURL Information => 7.19.7 curl操作步骤解析: CURL实例 1.一个简单的curl,抓取百度首页 2.下载一个网页并把内容中的"百度"替换为&
-
浅谈django中的认证与登录
认证登录 django.contrib.auth中提供了许多方法,这里主要介绍其中的三个: 1 authenticate(**credentials) 提供了用户认证,即验证用户名以及密码是否正确 一般需要username password两个关键字参数 如果认证信息有效,会返回一个 User 对象.authenticate()会在User 对象上设置一个属性标识那种认证后端认证了该用户,且该信息在后面的登录过程中是需要的.当我们试图登陆一个从数据库中直接取出来不经过authent
-
浅谈Vim中的Tab与空格缩进
vim缩进参数解析 缩进用 tab 制表符还是空格,个人爱好问题.但是在大多项目中,习惯使用空格.关于缩进,vim中可以通过如下四个参数进行配置 set tabstop=4 set softtabstop=4 set shiftwidth=4 set noexpandtab / expandtab1 解析: tabstop 表示按一个tab之后,显示出来的相当于几个空格,默认的是8个. softtabstop 表示在编辑模式的时候按退格键的时候退回缩进的长度. shiftwidth 表示每一级缩
-
浅谈mysql中多表不关联查询的实现方法
大家在使用MySQL查询时正常是直接一个表的查询,要不然也就是多表的关联查询,使用到了左联结(left join).右联结(right join).内联结(inner join).外联结(outer join).这种都是两个表之间有一定关联,也就是我们常常说的有一个外键对应关系,可以使用到 a.id = b.aId这种语句去写的关系了.这种是大家常常使用的,可是有时候我们会需要去同时查询两个或者是多个表的时候,这些表又是没有互相关联的,比如要查user表和user_history表中的某一些数据