MySQL全文索引、联合索引、like查询、json查询速度哪个快
查询背景
有一个表tmp_test_course大概有10万条记录,然后有个json字段叫outline,存了一对多关系(保存了多个编码,例如jy1577683381775)
我们需要在这10万条数据中检索特定类型的数据,目标总数据量:2931条
SELECT COUNT(*) FROM tmp_test_course WHERE `type`=5 AND del=2 AND is_leaf=1
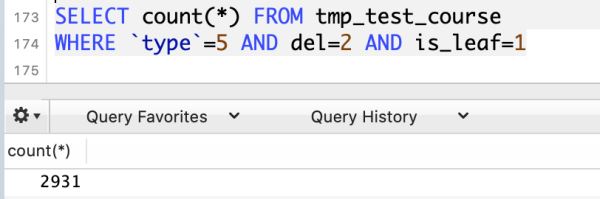
我们在限定为上面类型的同时,还得包含下面任意一个编码(也就是OR查询)
jy1577683381775
jy1577683380808
jy1577683379178
jy1577683378676
jy1577683377617
jy1577683376672
jy1577683375903
jy1578385720787
jy1499916986208
jy1499917112460
jy1499917093400
jy1499917335579
jy1499917334770
jy1499917333339
jy1499917331557
jy1499917330833
jy1499917329615
jy1499917328496
jy1576922006950
jy1499916993558
jy1499916992308
jy1499917003454
jy1499917002952
下面分别列出4种方式查询outline字段,给出相应的查询时间和扫描行数
一、like查询
耗时248毫秒
SELECT * FROM tmp_test_course WHERE `type`=5 AND del=2 AND is_leaf=1 AND ( outline like '%jy1577683381775%' OR outline like '%jy1577683380808%' OR outline like '%jy1577683379178%' OR outline like '%jy1577683378676%' OR outline like '%jy1577683377617%' OR outline like '%jy1577683376672%' OR outline like '%jy1577683375903%' OR outline like '%jy1578385720787%' OR outline like '%jy1499916986208%' OR outline like '%jy1499917112460%' OR outline like '%jy1499917093400%' OR outline like '%jy1499917335579%' OR outline like '%jy1499917334770%' OR outline like '%jy1499917333339%' OR outline like '%jy1499917331557%' OR outline like '%jy1499917330833%' OR outline like '%jy1499917329615%' OR outline like '%jy1499917328496%' OR outline like '%jy1576922006950%' OR outline like '%jy1499916993558%' OR outline like '%jy1499916992308%' OR outline like '%jy1499917003454%' OR outline like '%jy1499917002952%' )
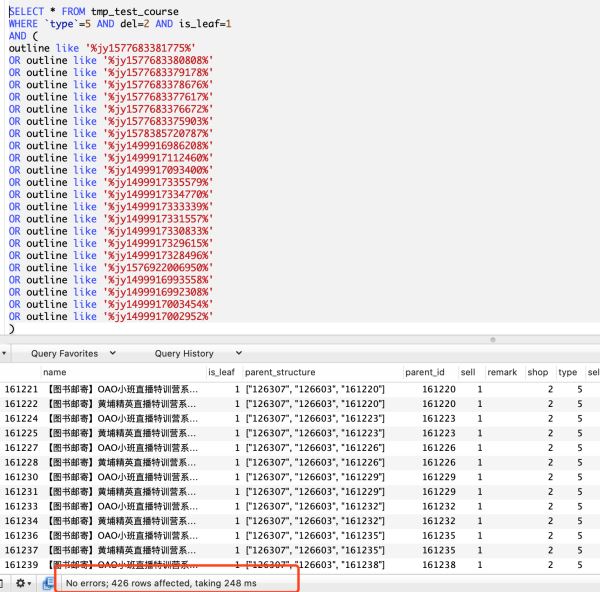
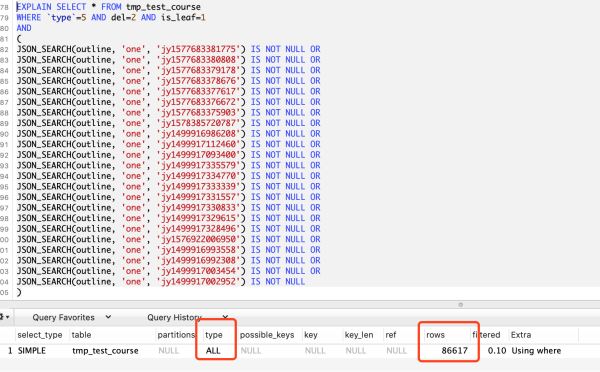
EXPLAIN分析结果如下,全表扫描
二、json函数查询
耗时196毫秒,速度稍微快了一点
SELECT * FROM tmp_test_course WHERE `type`=5 AND del=2 AND is_leaf=1 AND ( JSON_SEARCH(outline, 'one', 'jy1577683381775') IS NOT NULL OR JSON_SEARCH(outline, 'one', 'jy1577683380808') IS NOT NULL OR JSON_SEARCH(outline, 'one', 'jy1577683379178') IS NOT NULL OR JSON_SEARCH(outline, 'one', 'jy1577683378676') IS NOT NULL OR JSON_SEARCH(outline, 'one', 'jy1577683377617') IS NOT NULL OR JSON_SEARCH(outline, 'one', 'jy1577683376672') IS NOT NULL OR JSON_SEARCH(outline, 'one', 'jy1577683375903') IS NOT NULL OR JSON_SEARCH(outline, 'one', 'jy1578385720787') IS NOT NULL OR JSON_SEARCH(outline, 'one', 'jy1499916986208') IS NOT NULL OR JSON_SEARCH(outline, 'one', 'jy1499917112460') IS NOT NULL OR JSON_SEARCH(outline, 'one', 'jy1499917093400') IS NOT NULL OR JSON_SEARCH(outline, 'one', 'jy1499917335579') IS NOT NULL OR JSON_SEARCH(outline, 'one', 'jy1499917334770') IS NOT NULL OR JSON_SEARCH(outline, 'one', 'jy1499917333339') IS NOT NULL OR JSON_SEARCH(outline, 'one', 'jy1499917331557') IS NOT NULL OR JSON_SEARCH(outline, 'one', 'jy1499917330833') IS NOT NULL OR JSON_SEARCH(outline, 'one', 'jy1499917329615') IS NOT NULL OR JSON_SEARCH(outline, 'one', 'jy1499917328496') IS NOT NULL OR JSON_SEARCH(outline, 'one', 'jy1576922006950') IS NOT NULL OR JSON_SEARCH(outline, 'one', 'jy1499916993558') IS NOT NULL OR JSON_SEARCH(outline, 'one', 'jy1499916992308') IS NOT NULL OR JSON_SEARCH(outline, 'one', 'jy1499917003454') IS NOT NULL OR JSON_SEARCH(outline, 'one', 'jy1499917002952') IS NOT NULL )
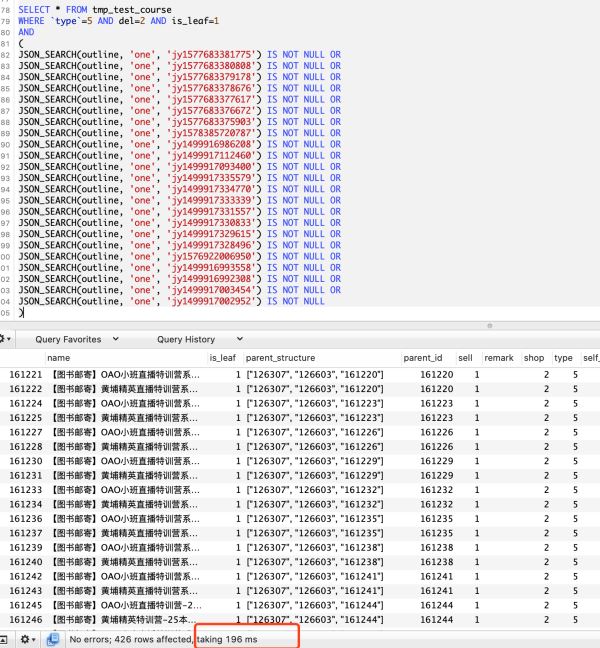
EXPLAIN分析结果如下,还是全表扫描
三、联合索引查询
下面为该表建立一个联合索引(本来想建一个type-del-is_leaf-outline的索引,但是outline字段太长限制,所以只加type-del-is_leaf的联合索引
ALTER TABLE tmp_test_course ADD KEY `type-del-is_leaf` (`type`,`del`,`is_leaf`)
加入索引后再执行like和json查询,明显提速。
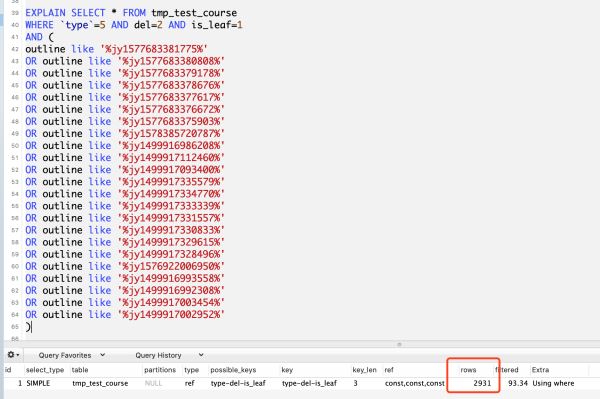
like执行用了136毫秒,json查询用了82.6毫秒,由此可见针对json类型使用json函数查询比like快
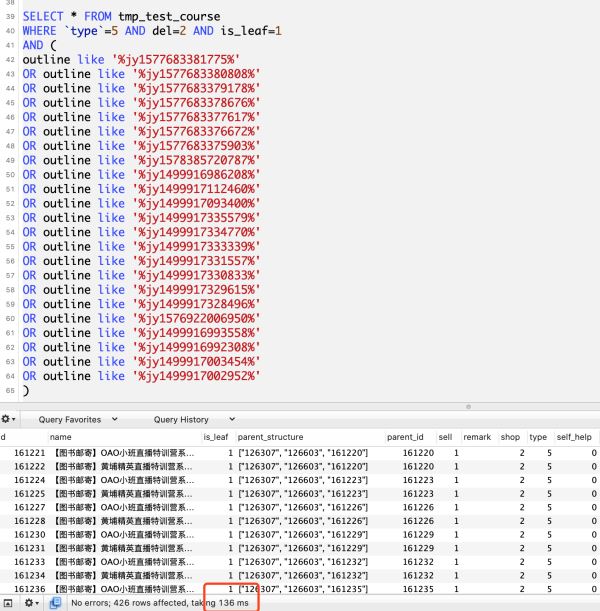

EXPLAIN分析结果如下,两者查询扫描的行数都限定在了2931行

四、全文索引查询
因为全文索引只支持CHAR、VARCHAR和TEXT,我们需要把JSON字段定义改一下
ALTER TABLE tmp_test_course MODIFY `outline` VARCHAR(1024) NOT NULL DEFAULT '[]'
添加全文索引
ALTER TABLE tmp_test_course ADD FULLTEXT INDEX outline (outline);
现在再来用全文索引进行检索
SELECT * FROM tmp_test_course
WHERE `type`=5 AND del=2 AND is_leaf=1
AND
MATCH(outline) AGAINST ('jy1577683381775 jy1577683380808 jy1577683379178 jy1577683378676 jy1577683377617 jy1577683376672 jy1577683375903 jy1578385720787 jy1499916986208 jy1499917112460 jy1499917093400 jy1499917335579 jy1499917334770 jy1499917333339 jy1499917331557 jy1499917330833 jy1499917329615 jy1499917328496 jy1576922006950 jy1499916993558 jy1499916992308 jy1499917003454 jy1499917002952')
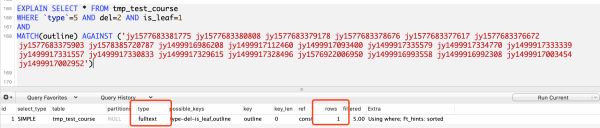
耗时11.6毫秒,速度提升极其明显,可见全文索引的牛逼。

EXPLAIN分析结果如下,显示只扫描了一行
结论
以下是4种情况的执行结果
全文索引: 11.6ms
联合索引:82.6ms(json)、136ms(like)
json函数查询:196ms
like查询: 248ms
结论:全文索引 > 联合索引 > json函数查询 > like查询
数据量越大,全文索引速度越明显,就10万的量,查询速度大概比直接查询快了20倍左右,如果是百万或千万级别的表,提升差距会更加大,所以有条件还是老老实实用全文索引吧
到此这篇关于MySQL全文索引、联合索引、like查询、json查询速度哪个快的文章就介绍到这了,更多相关mysql 全文索引 联合索引 like查询 json查询内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
mysql like查询字符串示例语句
MySQL提供标准的SQL模式匹配,以及一种基于象Unix实用程序如vi.grep和sed的扩展正则表达式模式匹配的格式 一.SQL模式 SQL的模式匹配允许你使用"_"匹配任何单个字符,而"%"匹配任意数目字符(包括零个字符).在 MySQL中,SQL的模式缺省是忽略大小写的.下面显示一些例子.注意在你使用SQL模式时,你不能使用=或!=:而使用LIKE或NOT LIKE比较操作符. SELECT 字段 FROM 表 WHERE 某字段 Like 条件 其中关于条
-
深入浅析Mysql联合索引最左匹配原则
前言 之前在网上看到过很多关于mysql联合索引最左前缀匹配的文章,自以为就了解了其原理,最近面试时和面试官交流,发现遗漏了些东西,这里自己整理一下这方面的内容. 最左前缀匹配原则 在mysql建立联合索引时会遵循最左前缀匹配的原则,即最左优先,在检索数据时从联合索引的最左边开始匹配,示例: 对列col1.列col2和列col3建一个联合索引 KEY test_col1_col2_col3 on test(col1,col2,col3); 联合索引 test_col1_col2_col3 实际建
-
MySQL 联合索引与Where子句的优化 提高数据库运行效率
网站系统上线至今,数据量已经不知不觉上到500M,近8W记录了.涉及数据库操作的基本都是变得很慢了,用的人都会觉得躁火~~然后把这个情况在群里一贴,包括机器配置什么的一说,马上就有群友发话了,而且帮我确定了不是机器配置的问题,"深圳-枪手"热心人他的机器512内存过百W的数据里也跑得飞快,甚至跟那些几W块的机器一样牛(吹过头了),呵呵~~~ 在群友的分析指点下,尝试把排序.条件等一个一个去除来做测试,结果发现问题就出在排序部分,去除排序的时候,执行时间由原来的48秒变成0.3x秒,这是
-
mysql查询字段类型为json时的两种查询方式
表结构如下: id varchar(32) info json 数据: id = 1 info = {"age": "18","disname":"小明"} -------------------------------------------- 现在我需要获取info中disanme的值,查询方法有: 1. select t.id,JSON_EXTRACT(t.info,'$.disname') as disname fro
-
MySQL全文索引应用简明教程
本文从以下几个方面介绍下MySQL全文索引的基础知识: MySQL全文索引的几个注意事项 全文索引的语法 几种搜索类型的简介 几种搜索类型的实例 全文索引的几个注意事项 搜索必须在类型为fulltext的索引列上,match中指定的列必须在fulltext中指定过 仅能应用在表引擎为MyIsam类型的表中(MySQL 5.6以后也可以用在Innodb表引擎中了) 仅能再char.varchar.text类型的列上面创建全文索引 像普通索引一样,可以在定义表时指定,也可以在创建表后添加或者修改 对
-

MySQL联合索引功能与用法实例分析
本文实例讲述了MySQL联合索引功能与用法.分享给大家供大家参考,具体如下: 联合索引又叫复合索引.对于复合索引:Mysql从左到右的使用索引中的字段,一个查询可以只使用索引中的一部份,但只能是最左侧部分.例如索引是key index (a,b,c). 可以支持a | a,b| a,b,c 3种组合进行查找,但不支持 b,c进行查找 .当最左侧字段是常量引用时,索引就十分有效. 两个或更多个列上的索引被称作复合索引. 利用索引中的附加列,您可以缩小搜索的范围,但使用一个具有两列的索引 不同于使用
-
mysql5.6及以下版本如何查询数据库里的json
MySQL里面保存数据有时候会把一些杂乱且不常用的时候丢进一个json字段里面 下面说说mysql存储json注意那些格式吧: 1:注意保存是中文不要变成转码的,转码之后导致查询非常麻烦,压缩时候后面多带一个参数,方便不止一点点哟! json_encode(array(),JSON_UNESCAPED_UNICODE); 好处:这样查询的时候中文字符更好的匹配查询 2:字段统一 存的时候最好开始定好字段名称 ,开发一个大点的项目不可能一个人开发统一字段可以减少很多不需要的麻烦和字段不同意
-
基于mysql全文索引的深入理解
前言:本文简单讲述全文索引的应用实例,MYSQL演示版本5.5.24. Q:全文索引适用于什么场合? A:全文索引是目前实现大数据搜索的关键技术. 至于更详细的介绍请自行百度,本文不再阐述. -------------------------------------------------------------------------------- 一.如何设置? 如图点击结尾处的{全文搜索}即可设置全文索引,不同MYSQL版本名字可能不同. 二.设置条件 1.表的存储引擎是MyISAM,默认
-
验证Mysql中联合索引的最左匹配原则详情
目录 前言 如何验证联合索引的有效性 多个单一索引进行验证 联合索引 总结 前言 后端面试中一定是必问mysql的,在以往的面试中好几个面试官都反馈我Mysql基础不行,今天来着重复习一下自己的弱点知识.在Mysql调优中索引优化又是非常重要的方法,不管公司的大小只要后端项目中用到了mysql,几乎都会遇到Mysql查询需要优化的需求.经常有时候前端业务没有压力,经常会在管理后台逻辑中遇到mysql统计查询压力,可能是代码写太烂了,哈哈.在日常工作中我遇到过同事建立索引后问我某个查询条件是否能命
-
mysql的联合索引(复合索引)的实现
联合索引 本文中联合索引的定义为(MySQL): ALTER TABLE `table_name` ADD INDEX (`col1`,`col2`,`col3`); 联合索引的优点 若多个一条SQL,需要多个用到两个条件 SELECT * FROM `user_info` WHERE username='XX',password='XXXXXX'; 当索引在检索 password字段的时候,数据量大大缩小,索引的命中率减小,增大了索引的效率. 符合索引的索引体积比单独索引的体积要小,而且只是一
-
一个案例彻底弄懂如何正确使用mysql inndb联合索引
有一个业务是查询最新审核的5条数据 SELECT `id`, `title` FROM `th_content` WHERE `audit_time` < 1541984478 AND `status` = 'ONLINE' ORDER BY `audit_time` DESC, `id` DESC LIMIT 5; 查看当时的监控情况 cpu 使用率是超过了100%,show processlist看到很多类似的查询都是处于create sort index的状态. 查看该表的结构 CREAT
-
MySQL全文索引、联合索引、like查询、json查询速度哪个快
查询背景 有一个表tmp_test_course大概有10万条记录,然后有个json字段叫outline,存了一对多关系(保存了多个编码,例如jy1577683381775) 我们需要在这10万条数据中检索特定类型的数据,目标总数据量:2931条 SELECT COUNT(*) FROM tmp_test_course WHERE `type`=5 AND del=2 AND is_leaf=1 我们在限定为上面类型的同时,还得包含下面任意一个编码(也就是OR查询) jy157768338177
-
mysql索引(覆盖索引,联合索引,索引下推)
目录 什么是索引? 索引的实现方式 innodb的索引模型 索引维护 覆盖索引 联合索引 索引下推 什么是索引? 当我们使用汉语字典查找某个字时,我们会先通过拼音目录查到那个字所在的页码,然后直接翻到字典的那一页,找到我们要查的字,通过拼音目录查找比我们拿起字典从头一页一页翻找要快的多,数据库索引也一样,索引就像书的目录,通过索引能极大提高数据查询的效率. 索引的实现方式 在数据库中,常见的索引实现方式有哈希表.有序数组.搜索树 哈希表 哈希表是通过键值对(key-value)存储数据的索引实现
-
MySql模糊查询json关键字检索方案示例
目录 前言 方案一: 方案二: 方案三: 方案四(最终采用方案): 总结 前言 最近在项目中遇到这样一个需求:需要在数据表中检索包含指定内容的结果集,该字段的数据类型为text,存储的内容是json格式,具体表结构如下: CREATE TABLE `product` ( `id` INT(11) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT 'ID', `name` VARCHAR(100) NOT NULL DEFAULT '' COMMENT '产品名称
-
MySQL前缀索引导致的慢查询分析总结
前端时间跟一个DB相关的项目,alanc反馈有一个查询,使用索引比不使用索引慢很多倍,有点毁三观.所以跟进了一下,用explain,看了看2个查询不同的结果. 不用索引的查询的时候结果如下,实际查询中速度比较块. 复制代码 代码如下: mysql> explain select * from rosterusers limit 10000,3 ; +----+-------------+-------------+------+---------------+------+---------+-
-
MySQL使用命令创建、删除、查询索引的介绍
MySQL数据库表可以创建.查看.重建和删除索引,索引可以提供查询速度.索引根据分类,分为普通索引和唯一索引:有新建索引.修改索引和删除.但是索引不是到处都可以创建,需要根据具体的条件.下面利用实例说明索引创建到销毁的过程,操作如下: 熟悉使用MySQL命令可以方便灵活地执行各种数据库操作:本文主要是对如何使用命令操作MySQL索引,包括创建索引.重建索引.查询索引.删除索引的操作.以下所列示例中的 `table_name` 表示数据表名,`index_name` 表示索引名,column li
-
mysql利用覆盖索引避免回表优化查询
前言 说到覆盖索引之前,先要了解它的数据结构:B+树. 先建个表演示(为了简单,id按顺序建): id name 1 aa 3 kl 5 op 8 aa 10 kk 11 kl 14 jk 16 ml 17 mn 18 kl 19 kl 22 hj 24 io 25 vg 29 jk 31 jk 33 rt 34 ty 35 yu 37 rt 39 rt 41 ty 45 qt 47 ty 53 qi 57 gh 61 dh 以主键以外的列值作为键值构建的 B+ 树索引,我们称之为非聚集索引.