简单高效有用的正则表达式
什么是正则表达式?
正则表达式是一组由字母和符号组成的特殊文本,它可以用来从文本中找出满足你想要的格式的句子。
一个正则表达式是一种从左到右匹配主体字符串的模式。 “Regular expression”这个词比较拗口,我们常使用缩写的术语“regex”或“regexp”。正则表达式可以从一个基础字符串中根据一定的匹配模式替换文本中的字符串、验证表单、提取字符串等等。
想象你正在写一个应用,然后你想设定一个用户命名的规则,让用户名包含字符、数字、下划线和连字符,以及限制字符的个数,好让名字看起来没那么丑。我们使用以下正则表达式来验证一个用户名:
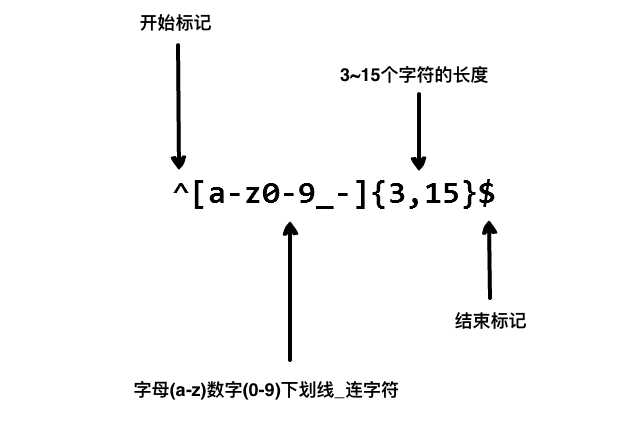
以上的正则表达式可以接受 john_doe、jo-hn_doe、john12_as。但不匹配Jo,因为它包含了大写的字母而且太短了。
1. 基本匹配
正则表达式其实就是在执行搜索时的格式,它由一些字母和数字组合而成。例如:一个正则表达式 the,它表示一个规则:由字母t开始,接着是h,再接着是e。
"the" => The fat cat sat on the mat.
正则表达式123匹配字符串123。它逐个字符的与输入的正则表达式做比较。
正则表达式是大小写敏感的,所以The不会匹配the。
"The" => The fat cat sat on the mat.
正则表达式是大小写敏感的, 所以The不会匹配the.
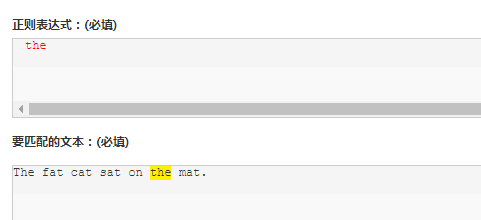
当然也可以让不区分大小写 /the/i,中的i就是不区分大小写,后面会有介绍
2. 元字符
正则表达式主要依赖于元字符。元字符不代表他们本身的字面意思,他们都有特殊的含义。一些元字符写在方括号中的时候有一些特殊的意思。以下是一些元字符的介绍:
| 元字符 | 描述 |
|---|---|
| . | 句号匹配任意单个字符除了换行符。 |
| [ ] | 字符种类。匹配方括号内的任意字符。 |
| [^ ] | 否定的字符种类。匹配除了方括号里的任意字符 |
| * | 匹配>=0个重复的在*号之前的字符。 |
| + | 匹配>=1个重复的+号前的字符。 |
| ? | 标记?之前的字符为可选. |
| {n,m} | 匹配num个大括号之间的字符 (n <= num <= m). |
| (xyz) | 字符集,匹配与 xyz 完全相等的字符串. |
| | | 或运算符,匹配符号前或后的字符. |
| \ | 转义字符,用于匹配一些保留的字符 [ ] ( ) { } . * + ? ^ $ \ | |
| ^ | 从开始行开始匹配. |
| $ | 从末端开始匹配. |
2.1 点运算符 .
.是元字符中最简单的例子。 .匹配任意单个字符,但不匹配换行符。例如,表达式.ar匹配一个任意字符后面跟着是a和r的字符串。
".ar" => The car parked in the garage.
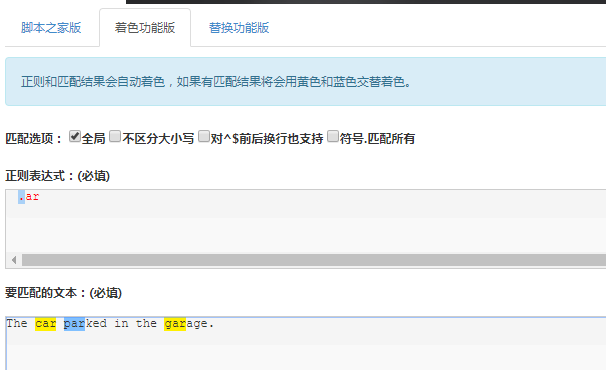
发现只要带ar的,不管前面是什么字母都可以匹配。 car,par,gar
2.2 字符集
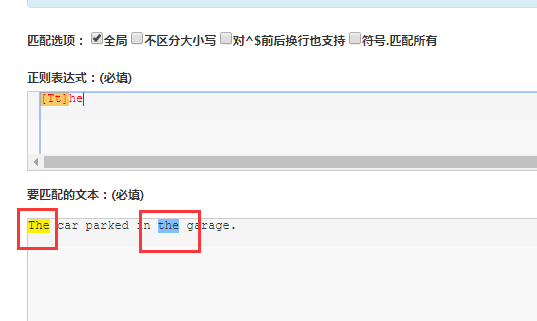
字符集也叫做字符类。方括号用来指定一个字符集。在方括号中使用连字符来指定字符集的范围。在方括号中的字符集不关心顺序。例如,表达式[Tt]he 匹配 the 和 The。
"[Tt]he" => The car parked in the garage.
方括号的句号就表示句号。表达式 ar[.] 匹配 ar.字符串
"ar[.]" => A garage is a good place to park a car.
我们小编补充:
[]好字母部分顺序,而且都是单字母,jb51就是任何包括 j或者b或者5或者1的都是可以匹配的。
如果只能匹配jb51那么只能用(),(jb51|baidu)

方括号的句号就表示句号. 表达式 ar[.] 匹配 ar.字符串

如果不在[]中,那么可以用转义字符 \ 即可
例如上面的正则我们可以这么写 ar\.
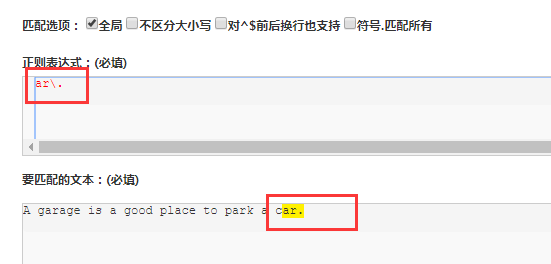
不过如果很多个字符都需要转义,并且没有顺序的话,还是用[]更好用
例如:[./^]

方便吧,这样比一个一个去转义好好懂。
2.2.1 否定字符集
一般来说 ^ 表示一个字符串的开头,但它用在一个方括号的开头的时候,它表示这个字符集是否定的。例如,表达式[^c]ar 匹配一个后面跟着ar的除了c的任意字符。
"[^c]ar" => The car parked in the garage.
2.3 重复次数
后面跟着元字符 +,* or ? 的,用来指定匹配子模式的次数。这些元字符在不同的情况下有着不同的意思。
2.3.1 * 号
*号匹配 在*之前的字符出现大于等于0次。例如,表达式 a* 匹配0或更多个以a开头的字符。表达式[a-z]* 匹配一个行中所有以小写字母开头的字符串。
"[a-z]*" => The car parked in the garage #21.
*字符和.字符搭配可以匹配所有的字符.*。 *和表示匹配空格的符号\s连起来用,如表达式\s*cat\s*匹配0或更多个空格开头和0或更多个空格结尾的cat字符串。
"\s*cat\s*" => The fat cat sat on the concatenation.
2.3.2 + 号
+号匹配+号之前的字符出现 >=1 次。例如表达式c.+t 匹配以首字母c开头以t结尾,中间跟着至少一个字符的字符串。
"c.+t" => The fat cat sat on the mat.
2.3.3 ? 号
在正则表达式中元字符 ? 标记在符号前面的字符为可选,即出现 0 或 1 次。例如,表达式 [T]?he 匹配字符串 he 和 The。
"[T]he" => The car is parked in the garage.
"[T]?he" => The car is parked in the garage.
2.4 {} 号
在正则表达式中 {} 是一个量词,常用来一个或一组字符可以重复出现的次数。例如, 表达式 [0-9]{2,3} 匹配最少 2 位最多 3 位 0~9 的数字。
"[0-9]{2,3}" => The number was 9.9997 but we rounded it off to 10.0.
我们可以省略第二个参数。例如,[0-9]{2,} 匹配至少两位 0~9 的数字。
"[0-9]{2,}" => The number was 9.9997 but we rounded it off to 10.0.
如果逗号也省略掉则表示重复固定的次数。例如,[0-9]{3} 匹配3位数字
"[0-9]{3}" => The number was 9.9997 but we rounded it off to 10.0.
2.5 (...) 特征标群
特征标群是一组写在 (...) 中的子模式。例如之前说的 {} 是用来表示前面一个字符出现指定次数。但如果在 {} 前加入特征标群则表示整个标群内的字符重复 N 次。例如,表达式 (ab)* 匹配连续出现 0 或更多个 ab。
我们还可以在 () 中用或字符 | 表示或。例如,(c|g|p)ar 匹配 car 或 gar 或 par.
"(c|g|p)ar" => The car is parked in the garage.
2.6 | 或运算符
或运算符就表示或,用作判断条件。
例如 (T|t)he|car 匹配 (T|t)he 或 car。
"(T|t)he|car" => The car is parked in the garage.
2.7 转码特殊字符
反斜线 \ 在表达式中用于转码紧跟其后的字符。用于指定 { } [ ] / \ + * . $ ^ | ? 这些特殊字符。如果想要匹配这些特殊字符则要在其前面加上反斜线 \。
例如 . 是用来匹配除换行符外的所有字符的。如果想要匹配句子中的 . 则要写成 \. 以下这个例子 \.?是选择性匹配.
"(f|c|m)at\.?" => The fat cat sat on the mat.
2.8 锚点
在正则表达式中,想要匹配指定开头或结尾的字符串就要使用到锚点。^ 指定开头,$ 指定结尾。
2.8.1 ^ 号
^ 用来检查匹配的字符串是否在所匹配字符串的开头。
例如,在 abc 中使用表达式 ^a 会得到结果 a。但如果使用 ^b 将匹配不到任何结果。因为在字符串 abc 中并不是以 b 开头。
例如,^(T|t)he 匹配以 The 或 the 开头的字符串。
"(T|t)he" => The car is parked in the garage.
"^(T|t)he" => The car is parked in the garage.
2.8.2 $ 号
同理于 ^ 号,$ 号用来匹配字符是否是最后一个。
例如,(at\.)$ 匹配以 at. 结尾的字符串。
"(at\.)" => The fat cat. sat. on the mat.
"(at\.)$" => The fat cat. sat. on the mat.
3. 简写字符集
正则表达式提供一些常用的字符集简写。如下:
| 简写 | 描述 |
|---|---|
| . | 除换行符外的所有字符 |
| \w | 匹配所有字母数字,等同于 [a-zA-Z0-9_] |
| \W | 匹配所有非字母数字,即符号,等同于: [^\w] |
| \d | 匹配数字: [0-9] |
| \D | 匹配非数字: [^\d] |
| \s | 匹配所有空格字符,等同于: [\t\n\f\r\p{Z}] |
| \S | 匹配所有非空格字符: [^\s] |
| \f | 匹配一个换页符 |
| \n | 匹配一个换行符 |
| \r | 匹配一个回车符 |
| \t | 匹配一个制表符 |
| \v | 匹配一个垂直制表符 |
| \p | 匹配 CR/LF(等同于 \r\n),用来匹配 DOS 行终止符 |
4. 零宽度断言(前后预查)
先行断言和后发断言都属于非捕获簇(不捕获文本 ,也不针对组合计进行计数)。先行断言用于判断所匹配的格式是否在另一个确定的格式之前,匹配结果不包含该确定格式(仅作为约束)。
例如,我们想要获得所有跟在 $ 符号后的数字,我们可以使用正后发断言 (?<=\$)[0-9\.]*。这个表达式匹配 $ 开头,之后跟着 0,1,2,3,4,5,6,7,8,9,. 这些字符可以出现大于等于 0 次。
零宽度断言如下:
| 符号 | 描述 |
|---|---|
| ?= | 正先行断言-存在 |
| ?! | 负先行断言-排除 |
| ?<= | 正后发断言-存在 |
| ?<! | 负后发断言-排除 |
4.1 ?=... 正先行断言
?=... 正先行断言,表示第一部分表达式之后必须跟着 ?=...定义的表达式。
返回结果只包含满足匹配条件的第一部分表达式。定义一个正先行断言要使用 ()。在括号内部使用一个问号和等号: (?=...)。
正先行断言的内容写在括号中的等号后面。例如,表达式 (T|t)he(?=\sfat) 匹配 The 和 the,在括号中我们又定义了正先行断言 (?=\sfat) ,即 The 和 the 后面紧跟着 (空格)fat。
"(T|t)he(?=\sfat)" => The fat cat sat on the mat.
4.2 ?!... 负先行断言
负先行断言 ?! 用于筛选所有匹配结果,筛选条件为 其后不跟随着断言中定义的格式。 正先行断言 定义和 负先行断言 一样,区别就是 = 替换成 ! 也就是 (?!...)。
表达式 (T|t)he(?!\sfat) 匹配 The 和 the,且其后不跟着 (空格)fat。
"(T|t)he(?!\sfat)" => The fat cat sat on the mat.
4.3 ?<= ... 正后发断言
正后发断言 记作(?<=...) 用于筛选所有匹配结果,筛选条件为 其前跟随着断言中定义的格式。例如,表达式 (?<=(T|t)he\s)(fat|mat) 匹配 fat 和 mat,且其前跟着 The 或 the。
"(?<=(T|t)he\s)(fat|mat)" => The fat cat sat on the mat.
4.4 ?<!... 负后发断言
负后发断言 记作 (?<!...) 用于筛选所有匹配结果,筛选条件为 其前不跟随着断言中定义的格式。例如,表达式 (?<!(T|t)he\s)(cat) 匹配 cat,且其前不跟着 The 或 the。
"(?<!(T|t)he\s)(cat)" => The cat sat on cat.
5. 标志
标志也叫模式修正符,因为它可以用来修改表达式的搜索结果。这些标志可以任意的组合使用,它也是整个正则表达式的一部分。
| 标志 | 描述 |
|---|---|
| i | 忽略大小写。 |
| g | 全局搜索。 |
| m | 多行修饰符:锚点元字符 ^ $ 工作范围在每行的起始。 |
5.1 忽略大小写(Case Insensitive)
修饰语 i 用于忽略大小写。例如,表达式 /The/gi 表示在全局搜索 The,在后面的 i 将其条件修改为忽略大小写,则变成搜索 the 和 The,g 表示全局搜索。
"The" => The fat cat sat on the mat.
"/The/gi" => The fat cat sat on the mat.
5.2 全局搜索(Global search)
修饰符 g 常用于执行一个全局搜索匹配,即(不仅仅返回第一个匹配的,而是返回全部)。例如,表达式 /.(at)/g 表示搜索 任意字符(除了换行)+ at,并返回全部结果。
"/.(at)/" => The fat cat sat on the mat.
"/.(at)/g" => The fat cat sat on the mat.
5.3 多行修饰符(Multiline)
多行修饰符 m 常用于执行一个多行匹配。
像之前介绍的 (^,$) 用于检查格式是否是在待检测字符串的开头或结尾。但我们如果想要它在每行的开头和结尾生效,我们需要用到多行修饰符 m。
例如,表达式 /at(.)?$/gm 表示小写字符 a 后跟小写字符 t ,末尾可选除换行符外任意字符。根据 m 修饰符,现在表达式匹配每行的结尾。
"/.at(.)?$/" => The fat cat sat on the mat.
"/.at(.)?$/gm" => The fat cat sat on the mat.
6. 贪婪匹配与惰性匹配(Greedy vs lazy matching)
正则表达式默认采用贪婪匹配模式,在该模式下意味着会匹配尽可能长的子串。我们可以使用 ? 将贪婪匹配模式转化为惰性匹配模式。
"/(.*at)/" => The fat cat sat on the mat.
"/(.*?at)/" => The fat cat sat on the mat.
贡献
报告问题
开放合并请求
传播此文档
直接和我联系 ziishaned@gmail.com 或 Twitter URL
许可证
MIT © Zeeshan Ahmad
相关推荐
-
PHP正则表达式完全教程之基础篇
目前,正则表达式已经在很多软件中得到广泛的应用,包括*nix(Linux, Unix等),HP等操作系统,PHP,C#,Java等开发环境,以及很多的应用软件中,都可以看到正则表达式的影子. 正则表达式的使用,可以通过简单的办法来实现强大的功能. 为了简单有效而又不失强大,造成了正则表达式代码的难度较大,学习起来也不是很容易. 例子: ^.+@.+..+$ 这样的代码曾经多次把我自己给吓退过.可能很多人也是被这样的代码给吓跑的吧. 学习完本教程将让你也可以自由应用这样的代码. 正则表达式的历史
-

Python正则表达式之基础篇
正则表达式是用于处理字符串的强大工具,它并不是Python的一部分. 其他编程语言中也有正则表达式的概念,区别只在于不同的编程语言实现支持的语法数量不同. 它拥有自己独特的语法以及一个独立的处理引擎,在提供了正则表达式的语言里,正则表达式的语法都是一样的. 下图展示了使用正则表达式进行匹配的流程: 1.1介绍 正则表达式并不是Python的一部分.正则表达式是用于处理字符串的强大工具,拥有自己独特的语法以及一个独立的处理引擎,效率上可能不如str自带的方法,但功能十分强大.得益于这一点,在提供了
-
Ruby中使用正则表达式的基础指引
正则表达式的内建支持通常只限于脚本语言如Ruby,Perl和awk等,这是一个耻辱:尽管正则表达式很神秘,但它是一个强大的文本处理工具.通过内建而不是通过程序库接口来支持它,有很大的不同. 正则表达式只是一种指定字符模式的方法,这个字符模式会在字符串中进行匹配.在Ruby中,通常在斜线之间(/pattern/)编写模式(pattern)来创建正则表达式.同时,Ruby就是Ruby,正则表达式是对象并且可以当作对象来操作. 比如,可以使用如下的正则表达式来编写模式,它会匹配包含Perl或Pytho
-
Java正则表达式入门基础篇(新手必看)
正则表达式是一种可以用于模式匹配和替换的规范,一个正则表达式就是由普通的字符(例如字符a到z)以及特殊字符(元字符)组成的文字模式,它 用以描述在查找文字主体时待匹配的一个或多个字符串.正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配. 众所周知,在程序开发中,难免会遇到需要匹配.查找.替换.判断字符串的情况发生,而这些情况有时又比较复杂,如果用纯编码方式解决,往往会浪费程序员的时间及精力.因此,学习及使用正则表达式,便成了解决这一矛盾的主要手段. 大家都知道,正则表达式是一种可以
-
javascript正则表达式基础知识入门
正则表达式的好处到底在哪里呢,下面我们先进行个了解: 我们用js中处理字符串的方法,写出取出字符串中数字的函数: var str='dgh6a567sdo23ujaloo932'; function getNumber(obj){ var arr=[]; for (var i = 0; i < obj.length; i++) { if (obj.charAt(i)>='0'&&obj.charAt(i)<='9'){ arr.push(obj.charAt(i)); }
-
PHP正则表达式基础入门
思维导图 介绍 正则表达式,大家在开发中应该是经常用到,现在很多开发语言都有正则表达式的应用,比如JavaScript.Java..Net.PHP 等,我今天就把我对正则表达式的理解跟大家唠唠,不当之处,请多多指教! 需要知道的术语--下面的术语你知道多少? Δ 定界符 Δ 字符域 Δ 修饰符 Δ 限定符 Δ 脱字符 Δ 通配符(正向预查,反向预查) Δ 反向引用 Δ 惰性匹配 Δ 注释 Δ 零字符宽 定位 我们什么时候使用正则表达式呢?不是所有的字符操作都用正则就好了,ph
-
Java 正则表达式入门详解(基础进阶)
正则表达式是一种文本模式,包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为"元字符").模式描述在搜索文本时要匹配的一个或多个字符串 先来两篇基础知识对于以前没了解过正则表达式的朋友可以先看下面两篇文章 1.正则表达式30分钟入门教程 30分钟内让你明白正则表达式是什么,并对它有一些基本的了解,让你可以在自己的程序或网页里使用它. 2.正则表达式基本语法详解 Java 正则表达式 正则表达式定义了字符串的模式. 正则表达式可以用来搜索.编辑或处理文本. 正则表达式并不仅限于
-
详解linux正则表达式(基础正则表达式+扩展正则表达式)
正则表达式应用非常广泛,例如:php,Python,java等,但在linux中最常用的正则表达式的命令就是grep(egrep),sed,awk等,换句话 说linux三剑客要想能工作的更高效,就一定离不开正则表达式的配合. 1.什么是正则表达式? 简单的说,正则表达式就是为处理大量的字符串而定义的一套规则和方法.通过定义的这些特殊符号的辅助,系统管理员就可以快速过滤.替换或者输出需要的字符串.linux正则表达式一般以行为单位处理的. 2.为什么要学正则表达式 在企业工作中,我们每天做的li
-
简单高效有用的正则表达式
什么是正则表达式? 正则表达式是一组由字母和符号组成的特殊文本,它可以用来从文本中找出满足你想要的格式的句子. 一个正则表达式是一种从左到右匹配主体字符串的模式. "Regular expression"这个词比较拗口,我们常使用缩写的术语"regex"或"regexp".正则表达式可以从一个基础字符串中根据一定的匹配模式替换文本中的字符串.验证表单.提取字符串等等. 想象你正在写一个应用,然后你想设定一个用户命名的规则,让用户名包含字符.数字.
-
简单且有用的Python数据分析和机器学习代码
为什么选择Python进行数据分析? Python是一门动态的.面向对象的脚本语言,同时也是一门简约,通俗易懂的编程语言.Python入门简单,代码可读性强,一段好的Python代码,阅读起来像是在读一篇外语文章.Python这种特性称为"伪代码",它可以使你只关心完成什么样的工作任务,而不是纠结于Python的语法. 另外,Python是开源的,它拥有非常多优秀的库,可以用于数据分析及其他领域.更重要的是,Python与最受欢迎的开源大数据平台Hadoop具有很好的兼容性.因此,学习
-
详解简单高效的Go struct优化
目录 前言 先来看个例子 内存对齐机制 案例进一步分析 总结 前言 结构体的定义,大家都很熟悉,但想要定义出更节省内存空间的结构体,可不是一件简单的事. 我们必须掌握了Go的结构体内存对齐机制,才能做出相应的优化(节省内存并提高性能). 先来看个例子 下面定义两个结构体,字段都一样,只是部分字段稍微调整了一下顺序. 但输出的结果,为什么bad占用24字节,而good却只占用16字节呢?一个顺序调整就节省了8个字节,太神奇了 type BadSt struct { A int32 B int64
-
用函数模板,写一个简单高效的 JSON 查询器的方法介绍
JSON可谓是JavaScript的亮点,它能用优雅简练的代码实现Object和Array的初始化.同样是基于文本的数据定义,它比符号分隔更有语义,比XML更简洁.因此越来越多的JS开发中,使用它作为数据的传输和储存. JS数组内置了不少有用的方法,方便我们对数据的查询和筛选.例如我们有一堆数据: 复制代码 代码如下: var heros = [ // 名============攻=====防=======力量====敏捷=====智力==== {name:'冰室女巫
-
asp.net+sqlserver实现的简单高效的权限设计示例
大部分系统都有权限系统.一般来说,它能管控人员对某个否页面的访问:对某些字段.控件可见或者不可见.对gridview中的数据是否可删除.可添加.可新增等等.大部分人都把权限作为一个子系统独立出来.但是这里我不是想设计一个权限管理系统,网上的设计方案太多了,可以说每个开发人员都有自己的开发权限管理系统的想法和思路. 在这篇文章中,我先用简单的C#代码模仿一个用户的权限,再使用sql去模拟.这是一种很简单,很直观,很高效的方式去判定用户的权限. C#: 好吧,先从最简单开始,定义一个用户(User)
-
Java简单高效实现分页功能
今天想说的就是能够在我们操作数据库的时候更简单的更高效的实现,现成的CRUD接口直接调用,方便快捷,不用再写复杂的sql,带吗简单易懂,话不多说上方法 1.Utils.java工具类中的方法 /** 2 * 获取Sort * * @param direction - 排序方向 * @param column - 用于排序的字段 */ public static Sort getSort(String direction,String column){ Sort sort = null; if(c
-
简单高效:用Swatch做Linux日志分析
日志文件是我们发现系统问题的重要参考信息. 大部分的系统服务出现问题时都会给syslogd(系统日志守护进程)发送消息. 然后用户发觉并根据错误提示信息采取行动. 然而对于1000行以上的日志文件, 我们必须使用日志检查工具节省时间和避免漏掉重要信息. Swatch从字面上可以简单理解为Watcher(守护者). 其它的日志分析软件定期地扫描日志文件, 向你报告系统已经发生的问题或者状况. Swatch程序不仅能够做这些, 而且它能够像Syslogd守护程序那样主动的扫描日志文件并对特定的日志消
-
javascript 简单高效判断数据类型 系列函数 By shawl.qiu
说明: 前段时间把 ASP VBScript 掌握得差不多的时候, 就转而学习 Javascript/Jscript, 主要是学 Jscript 啦. 不过这两者基本上没什么区别, 唯一不同的是 Jscript 没有客户端的概念. 在刚开始时, 发现 VBS 的一些实用函数 Js 好多都没有, formatNumber 呀 isArray 呀 isDate 呀 等等. 还有日期对象也是很奇怪, 不能直接加加减减, 要set***... 不过对 Javascript/Jscript 掌握到一
-
发一个数据过滤的代码,很简单,有用的着的拿去
Filterlist Example Filterlist Example Keanu ReevesLaurence FishburneMonica BellucciDaniel BernhardtNona GayeLachy HulmeNathaniel LeesHarry J. LennixMatt McColmCarrie-Anne MossCollin ChouGenevieve O'ReillyHarold Perrineau Jr.Jada Pinkett SmithAdrian R
-
微信小程序网络封装(简单高效)
废话引言 小程序虽然出世很久了,但一直没怎么接触到小程序开发.吉他兴趣班老师想弄一个小程序发布课程信息和打卡功能,作为IT一员就自愿加入了这个小程序开发小组中.虽然小程序面向的是前端工程师,但作为移动端程序猿感觉甚是友好,加上有点前端基础就更是觉得入手很easy啦. 微信小程序的网络请求很便捷,直接调用就可以了.但最好还是根据需求,处理一些参数回调信息,进行二次封装,为整个小程序应用直接提供调方法接口岂不是更好? 利用网络请求的一贯思维,分三个回调:onStart:开始请求, onSuccess