R语言 install.packages 无法读取索引的解决方案
问题描述
在公司的Centos服务器上安装R的包,总是安装不成功,然后有如下提醒:
Warning: 无法在貯藏處https://mirrors.ustc.edu.cn/CRAN/src/contrib中读写索引 Warning message: package ‘DBI' is not available (for R version 3.2.2)
问题修复
【更好的方案请直接看最后边PS】
执行下边这条命令,随便选几个源。
setRepositories(addURLs = c(CRANxtras = http://cran.at.r-project.org/))
这样再执行install.packages() 就OK了。
问题分析
公司网络因为https访问不了,只能访问http的源造成的,虽然这个问题不普遍,但是如果碰到确实比较恼火,折腾一早上才找到上边的解决办法。其他参考
PS:其他方案
最后才发现,你可以在选择镜像的时候选择18: (HTTP mirrors) 。⊙﹏⊙b汗
补充:R语言 下载包出错Warning: 无法在貯藏處https://cloud.r-project.org/src/contrib中读写索引:
报错原因,竟然是ie浏览器的问题,unbelievable
1、在R中,下载包的时候,却发现报错: Warning: 无法在貯藏處https://cloud.r-project.org/src/contrib中读写索引: 无法打开URL'https://cloud.r-project.o

2、后来针对CRAN重新选择,但以下这几个都选择了一遍。都还是报错。
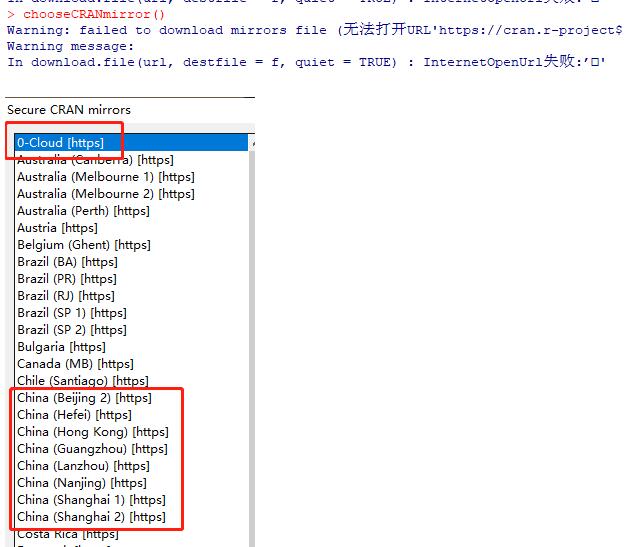
3、最后找到原因了。下载包是依赖本机的ie浏览器下载的。本身电脑 的ie浏览器出错了,打开是网页显示 打不开的。所以导致下载包出错。

4、开始修复了ie浏览器,打开设置→Internet选项→高级→重置


5、ie浏览器修复好了,打开是正常的了。意味着,下载包也正常了。

6、选择CRAN,选择china任意一个后。没有报错,下载包,也正常了。

以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-

R语言ggplot2之图例的设置
引言 图例的设置包括移除图例.改变图例的位置.改变标签的顺序.改变图例的标题等. 移除图例 有时候你想移除图例,使用 guides(). library(ggplot2) p <- ggplot(PlantGrowth, aes(x=group, y=weight, fill=group)) + geom_boxplot() p + guides(fill=FALSE) 改变图例的位置 我们可以用theme(legend.position=-)将图例移到图表的上方.下方.左边和右边. p <-
-
R语言-解决处理矩阵遇到内存不足的问题
如下: Error : cannot allocate vector of size X Gb 类似于这种问题的可能处理办法: 1. 可以用matrix尽量不要用data frame; 2. 可以用integer matrix尽量不要用 double matrix; 3. 对于大量运算后最好加上一个gc(), 强制R语言回收内存: 4. 对于大矩阵而言用bigmemory包,可以将大矩阵放到临时文件中,不占用内存. 补充:R语言之内存管理 在处理大型数据过程中,R语言的内存管理就显得十分重要,以
-
R语言数据框中的负索引介绍
以R语言自带的mtcars数据框为例: 这是原始的mtcars数据: 这里只列出了前面几行数据. 然后负索引mtcars[,-2:-3],得到的结果 删除了第二列和第三列数据 所以R语言数据框中的负索引是指删除数据框中对应的列(或者行) ps:这和Python里面的规则好像不太一样,Python里的负索引好像是指倒数第几列(或者第几行),这里这两个软件区别还挺大的~~写个笔记提醒一下自己~ 补充:R语言中的负整数索引 看代码吧~ > x<-matrix(c(1,2,3,4,5,6,7,8,9)
-
R语言:数据筛选match的使用详解
数据筛选是在分析中最常用的步骤,如微生物组分析中,你的OTU表.实验设计.物种注释之间都要不断筛选,来进行数据对齐,或局部分析. 今天来详解一下此函数的用法. match match:匹配两个向量,返回x中存在的返回索引或TRUE.FALSE match函数使用格式有如下两种: 第一种方便设置参数,返回x中元素在table中的位置 match(x, table, nomatch = NA_integer_, incomparables = NULL) 第二种简洁,返回x中每个元素在table中是
-
R语言 查找满足条件的数并获取索引的操作
1.在R语言中,如何找到满足条件的数呢? 例如给定一个向量c2,要求找到数值大于0的数: > c2 [1] 0.00 0.00 0.00 0.00 0.00 0.00 0.06 0.09 0.20 0.09 0.08 0.14 0.14 0.23 [15] 0.08 0.06 0.12 0.20 0.14 0.11 0.20 0.14 0.17 0.15 0.18 0.15 0.20 0.12 [29] 0.23 0.08 0.12 0.08 0.23 0.12 0.08 0.17 0.18 0
-
教你利用R语言测试电脑的性能
利用R语言测试电脑的性能如何 同事新配了一个电脑,想用R语言编写一个程序,看一下电脑性能如何,让我写个代码测试一下. 我能怎么样,我也不懂如何测试电脑啊,那就计算一下矩阵的运算吧.因为我理解的电脑运行性能就是矩阵计算了. 编写代码 rm(list=ls()) set.seed(123) # 设置矩阵的行数 n = 10000 # 生成一个矩阵 value = rnorm(n*n, 10,3) mat = matrix(value,n,n) # 测试电脑性能 system.time({ # 矩阵求
-
R语言中文本文件分割 符号 sep的用法
一般情况下: csv 文件 sep = "," # 以逗号分割 txt 文件 sep = "\t" #以制表符分割 其他文件 sep = " " #以空格分割 具体情况,具体调整 sep= 文件中的字段分离符,用于文件数据文本的读取和保存过程中指定分割符号. 补充:用R语言把超大文本文件拆分成几个小文本文件 近一段时间一直在研究一些医院的数据. 前两天遇到一个尴尬:想打开一个仅有3G左右的文本文件(有时候必须要打开,直接传到数据库满足不了需求),
-
R语言 install.packages 无法读取索引的解决方案
问题描述 在公司的Centos服务器上安装R的包,总是安装不成功,然后有如下提醒: Warning: 无法在貯藏處https://mirrors.ustc.edu.cn/CRAN/src/contrib中读写索引 Warning message: package 'DBI' is not available (for R version 3.2.2) 问题修复 [更好的方案请直接看最后边PS] 执行下边这条命令,随便选几个源. setRepositories(addURLs = c(CRANxt
-
基于R语言xlsx安装遇到的问题及解决方案
1.java环境的安装,如果java安装的是64位使用R软件一定要是64位,如果使用32位会报错,版本一定要对应. 2.安装顺序要是install.packages("rJava") install.packages("xlsxjars") install.packages("xlsx") 3.如果之前不是安装2中那样的顺序安装,虽然rJava或者xlsxjars包都下载了,但是就是安装不上xlsx,这时候可以选择到R安装目录下的library中
-
R语言-如何循环读取excel并保存为RData
之前写过一个循环读取excel的代码,最近又有了新的需求:循环读取xlsx文件中的多个sheet,处理完之后循环输出到xlsx文件中的多个sheet中,总结一下. 1.循环读取csv文件并输出为RData格式 homedir <- "D:/Documents/tina/Database" #设置路径 setwd(homedir) temp = list.files(pattern="*.csv") for (i in 1:length(temp)) { fil
-
R语言操作XML文件实例分析
XML是一种文件格式,它使用标准ASCII文本共享万维网,内部网和其他地方的文件格式和数据. 它代表可扩展标记语言(XML). 类似于HTML它包含标记标签. 但是与HTML中的标记标记描述页面的结构不同,在xml中,标记标记描述了包含在文件中的数据的含义. 您可以使用"XML"包读取R语言中的xml文件. 此软件包可以使用以下命令安装. install.packages("XML") 输入数据 通过将以下数据复制到文本编辑器(如记事本)中来创建XMl文件. 使用.
-
R语言UpSet包实现集合可视化示例详解
目录 前言 一.R包及数据 二.upset()函数 1)基本参数 2)queries参数 3)attribute.plots参数 3.1 添加柱形图和散点图 3.2 添加箱线图 3.3 添加密度曲线图 前言 介绍一个R包UpSetR,专门用来集合可视化,当多集合的韦恩图不容易看的时候,就是它大展身手的时候了. 一.R包及数据 #安装及加载R包 #install.packages("UpSetR") library(UpSetR) #载入数据集 data <- read.csv(&
-
R语言ggplot2实现将多个照片拼接到一起
将多个照片拼接到一起,然而电脑上没有安装ps 和 ai (拼图我暂时只想到这两个软件了) 直接使用R语言吧 思路是读取图片 使用ggplot2 显示 最后使用patchwork 拼接 代码 library(ggplot2) library(jpeg) library(ggpubr) library(patchwork) img0<-readJPEG("308/0.JPG") p0<-ggplot()+ background_image(img0)+ theme_void()
-
R语言读取excel数据的方法(两行命令)
安装库 安装xlsx install.packages("xlsx") 使用 library(xlsx) ray = read.xlsx('D:/Code/R/Data in Excel/Chapter 8/gamma-ray.xls',1) 后面的参数,第一个放地址,第二个放具体sheet页(这里除了可以放数值之外,还可以放对应的名字(字符串)).除此之外,还可以使用encoding="utf-8"的方式来定义使用中文数据. 效果: > a = read.x
-
R语言批量读取某路径下文件内容的方法
R刚入门的时候,能够正确读取单个文件就觉得小有成就,随着时间的积累,单一文件地读取已经不能满足需求了,此时,批量地做就是解放双手地过程. 使用for循环把下载地TCGA数据读入R语言并转换成数据框 使用三个for循环来完成,这是第一个for循环. 1. 把所有数据读入在一个文件夹中 dir.create("data_in_one") #创建目标文件夹,也可右键创建 dir("rawdata/") #查看原路径的内容 for (dirname in dir("
-
R语言rhdf5读写hdf5并展示文件组织结构和索引数据
前言 h5只是一种简单的数据组织格式[层级数据存储格式(HierarchicalDataFormat:HDF)],该格式被设计用以存储和组织大量数据. 在一些单细胞文献中,作者通常会将分析的数据上传到GEO数据库保存为.h5格式文件,而不是我们常见的工程文件(rds文件,表格数据等),所以为了解析利用这些数据需要对hdf5格式的组织结构有一定的了解. (注:在Seurat包中有现成的函数Seurat::Read10X_h5()可以用来提取表达矩阵,但似乎此外无法从h5文件中提取更多的信息). G
-
R语言修改下载安装包install.package的默认存储路径的操作方法
这次遇到的问题是:R语言下载安装包时会先将下载下来的二进制zip文件保存在本地,然后将其解压安装到R的library文件夹下.包被下载后会默认将二进制zip文件保存在本地C盘的临时会话的downloaded_packages目录下,不希望保存在该目录下,想手动修改保存路径. 查找了一下方法,发现很多都让用.libPaths()或者lib参数来修改.这里说明一下.libPaths和lib参数的作用. libPaths {base} 文档中给出的说明大致意思就是这是一个获取或者设定R存放已经安装的包