R语言 UTF-8各种问题的解决方案
R语言在碰到读UTF-8文件,或者处理UTF-8数据时总是会遇到各种各样的问题,本姑娘也是在碰了n多次壁,被气得吐血好多次之后,终于对这类总结出了一些解决办法:
1. 读UTF-8文件,例如UTF-8格式的csv:
最好的处理办法就是:
a1=read.table('C:\\test11.csv',sep=',',fileEncoding = 'UTF-8',header = F)
如果使用如下方法可能会出错(全是血泪教训啊):
a2=read.csv('C:\\test11.csv',fileEncoding = 'UTF-8',header = F)
a2=read.csv('C:\\test11.csv',encoding = 'UTF-8',header = F)
2. 如何在R里把一个数据转化为UTF-8格式:
因为我在R里写了一段程序,需要把数据转化为JSON格式,通过上面的方法读进来的数据是没有问题,但是数据再R里并不是utf-8格式存储的,所以toJSON()时报了如下错误:
unable to escape string. String is not utf8
后来发现R里有一个函数可以把数据转为utf8格式:enc2utf8()
> a='小源' > Encoding(a)#查看a的编码格式 [1] "unknown" > b=enc2utf8(a) > Encoding(b) [1] "UTF-8"
3. 如何SOURCE一个UTF-8格式的R文件:
source一个utf8编码保存的R脚本,在windows下(linux由于默认编码就是utf8,直接source就可以)
source('test.R',encoding = 'UTF-8')
补充:mac系统csv乱码_R语言写入UTF-8格式CSV乱码解决办法
中文编码方式有GBK(GB2312)和UTF-8两种。
由于区域设置问题,在Windows系统下,Excel程序默认用GBK格式读取CSV文件。
因此会导致乱码。
如下图所示:

解决的办法是用tidyverse包中的write_excel_csv()函数。
下面上代码:
library(tidyverse)
x <- c('好好地', '针对是棒极啦', '哈好好好好好爱吼吼吼啊', '啊')
y <- c(1, 2, 3, 4)
z <- c('haha', 'hehe', 'hoho', 'lala')
xyz_tbl <- tibble(x,y,z)
read_csv(file = 'data1.csv', )
#乱码
write.csv(xyz_tbl,'data_old.csv',row.names = T,fileEncoding='UTF-8')
#再次乱码
write_csv(xyz_tbl, 'data.csv')
#解决问题
write_excel_csv(xyz_tbl, 'data_ex.csv')
#以上文件用R读取都没问题
read_csv(file = 'data.csv')
read_csv(file = 'data_ex.csv')
read_csv(file = 'data_old.csv')

原数据

data.csv

data_ex.csv
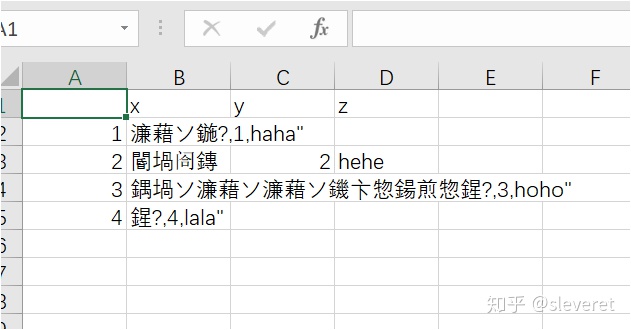
data_old.csv
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
R语言 小数点位数的设置方式
经常用数据分析,有时不同的文件的小数位数不一样,但是我们可以让它们的位数保持一致的,下面的介绍就是设置小数位数. 使用options函数 > options(digits) 默认为7位 > a=0.234333323#9位> a[1] 0.2343333 下面开始设置下 > options(digits=3)> a=0.34434434#8位> a[1] 0.344 看最大的位数 > options(digits=27)Error in options(digit
-
R语言中的因子类型详解
一.Factor函数 #函数factor可以把一个向量编码为一个因子,其一般形式为: #factor(x,levels=sort(unique(x),na.last=TRUE),labels,exculde=NA,order=FALSE) #其中x是向量,levels是水平,可以自行指定各离散的取值,不指定时由x的不同值来表示,labels可以用来指定各水平的标签 #不指定时用各离散取值的对应字符串 sex<-c("M","F","M",&
-

R语言-进行数据的重新编码(recode)操作
在分析数据时我们经常会遇到将变量值转换成其他的值的情况(如:将连续变量转成分类变量)这时就需要我们对原有数据进行重新编码.本文将介绍R软件中常用的三种重编吗方法: 1.使用逻辑判断式编码. 2.使用cut函数编码. 3.使用car程序包的recode函数. (一)使用逻辑判断式 (1)现假设我们需要将下面的连续型变量x按照10与20分成三个组,新的分组名称为1.2.3: > x2=1*(x<=10)+2*(x>10&x<=20)+3*(x>20) > x2 [1
-
R语言-如何切换科学计数法和更换小数点位数
看代码吧~ options(scipen = 100) # 小数点后100位不使用科学计数法 options(digits = 3) # 保留小数点后三位 补充:R语言将数据导出到csv时出现科学计数表示 R语言导出数据时是默认科学计数表示的,但是对于一些数字,其并没有数字的意思,只是一串ID,也会自动变成科学计数导致数据错误,处理方法有: 1.formatC函数 用format=参数指定C格式类型,如"d"(整数),"f"'(定点实数),"e"
-
R语言-如何将list转换为向量
从excel中直接读取的数据为list,如下转换为向量 as.vector(unlist(x)) 补充:R语言基本运算,向量,矩阵,list,数组 1. 基本运算 1.1 加.减.乘.除 赋值可以使用a=数值,亦可以用a<-数值 1.2 余数.整除 1.3 绝对值: abs() .判断正负:sign() .幂.指数:^ .平方根:sqrt() 1.4 以二为底的对数: log2() .以十为底的对数:log10() .自定义底的对数:log(c,base=) .自然常数e的对数:log(a,ba
-
R语言差异检验:非参数检验操作
非参数检验是在总体方差未知或知道甚少的情况下,利用样本数据对总体分布形态进行推断的方法.它利用数据的大小间的次序关系(秩Rank),而不是具体数值信息,得出推断结论. 它是参数检验所需要的某些条件不满足时所使用的方法. 和参数检验相比,非参数检验的优势如下: 稳健性.对总体分布的条件要求放宽 对数据类型要求不严格,适用有序分类变量 适用范围广 劣势: 没有利用实际数值,损失了部分信息,检验的有效性较差. 非参数性检验的方法非常多,基于方法的检验功效性角度,本文只涉及 双独立样本:Mann-Whi
-
R语言-实现按日期分组求皮尔森相关系数矩阵
R语言按日期分组求相关系数 前几天得到了3700+支股票一周内的波动率,想要计算每周各个股票之间的相关系数并将其可视化.最终结果保存在制定文件夹中. 部分数据如下: 先读取数据 data<-read.csv("D:/data/stock_day_close_price_week_series.csv", header = TRUE,blank.lines.skip = TRUE) 利用mice包处理缺失值: library(lattice) library(MASS) libra
-
R语言-因子与向量的转换方式
一.因子的特点或性质 1.因子可视为C或JAVA语言中的枚举,适用于有限状态的表示. 2.因子不可以赋枚举集合外的值,如一个因子包含male,female,则不能再赋male和female以为的值,赋其他值会将该元素设置为空值. 二.因子的建立 1.因子的建立 假定有因子gendor,为一组人的性别: > gendor<-factor(c('m','f','f','m'),labels=c('male','female')) 则通过上式建立一个性别因子. > gendor [1] fem
-
R语言读取csv文件出错的解决方案
今天在用R语言读取.csv文件的时候报错 Error in make.names(col.names, unique = TRUE) : invalid multibyte string 5 上网查了很久才知道原来是格式的问题(保存文件格式的编码不正确) 重新保存正确的格式就没有问题了~ 补充:R语言读取csv文件,第一列列名出现乱码的解决方法 在利用R语言读取csv文件时,第一列列名总是出现乱码,代码如下: setwd("E:\2.Model\4. Simulation") #设定文
-
R语言 出现矩阵/缺失值的解决方案
缺失值处理一般包括三步: 1. 识别缺失数据: 2. 检查导致数据缺失的原因: 3. 删除包含缺失值的实例或用合理的数值代替(插补)缺失值. 1.判断缺失值 函数is.na().is.nan()和is.infinite()可分别用来识别缺失值.不可能值和无穷值.每个返回结果都是 TRUE或FALSE na表示缺失值 nan表示NOT A NUMBER infinite表示+-Inf 一定要亲手试x = 0/0,以及x = 1/0 >x <- NA > is.na(x) [1] TRUE
-
R语言 install.packages 无法读取索引的解决方案
问题描述 在公司的Centos服务器上安装R的包,总是安装不成功,然后有如下提醒: Warning: 无法在貯藏處https://mirrors.ustc.edu.cn/CRAN/src/contrib中读写索引 Warning message: package 'DBI' is not available (for R version 3.2.2) 问题修复 [更好的方案请直接看最后边PS] 执行下边这条命令,随便选几个源. setRepositories(addURLs = c(CRANxt
-
R语言 UTF-8各种问题的解决方案
R语言在碰到读UTF-8文件,或者处理UTF-8数据时总是会遇到各种各样的问题,本姑娘也是在碰了n多次壁,被气得吐血好多次之后,终于对这类总结出了一些解决办法: 1. 读UTF-8文件,例如UTF-8格式的csv: 最好的处理办法就是: a1=read.table('C:\\test11.csv',sep=',',fileEncoding = 'UTF-8',header = F) 如果使用如下方法可能会出错(全是血泪教训啊): a2=read.csv('C:\\test11.csv',file
-
基于R语言xlsx安装遇到的问题及解决方案
1.java环境的安装,如果java安装的是64位使用R软件一定要是64位,如果使用32位会报错,版本一定要对应. 2.安装顺序要是install.packages("rJava") install.packages("xlsxjars") install.packages("xlsx") 3.如果之前不是安装2中那样的顺序安装,虽然rJava或者xlsxjars包都下载了,但是就是安装不上xlsx,这时候可以选择到R安装目录下的library中
-
R语言 中文乱码的解决方案
问题背景 在R Studio中重新载入之前编辑好的.r文件,结果发现内容中的所有中文都乱码了. 问题解决 在R Studio中选择菜单栏File->Reopen with Encoding- 选择当初编辑.r文件保存的格式,如常见的UTF-8: 最后确定,乱码问题搞定. 补充:2个实用的解决R语言中文乱码方法 导入R代码出现中文乱码是时长发生的让人头疼的事情,两个经常用到的方法供参考. 方法1 导入R代码,出现乱码,依次点击File-Reopen with encoding-Choose enc
-
R语言导入导出数据的几种方法汇总
导出: 对于某一数据集导出文件的方法 导出例子:write.csv(data_1,file = "d:/1111111111.csv") 其中data_1是你的数据集,file是你的存储路径和要存储的名字 导入: 1 使用键盘输入数据 (1) 创建一个空数据框(或矩阵),其中变量名和变量的模式需与理想中的最终数据集一致: (2)针对这个数据对象调用文本编辑器,输入你的数据,并将结果保存回此数据对象中. 在下例中,你将创建一个名为mydata的数据框,它含有三个变量:age(数值型).
-
R语言多元Logistic逻辑回归应用实例
可以使用逐步过程确定多元逻辑回归.此函数选择模型以最小化AIC. 如何进行多元逻辑回归 可以使用阶梯函数通过逐步过程确定多元逻辑回归.此函数选择模型以最小化AIC. 通常建议不要盲目地遵循逐步程序,而是要使用拟合统计(AIC,AICc,BIC)比较模型,或者根据生物学或科学上合理的可用变量建立模型. 多元相关是研究潜在自变量之间关系的一种工具.例如,如果两个独立变量彼此相关,可能在最终模型中都不需要这两个变量,但可能有理由选择一个变量而不是另一个变量. 多元相关 创建数值变量的数据框 Data.
-
R语言ggplot2边框背景去除的实现
ggplot2是R语言功能强大的可视化包,但是在作图时有很多默认设置(边框,背景等)会影响图片美观度.比如我们用ggolot2做一个简单的柱状图,就会发现有灰色背景和白色线条.对于这一问题给出几种解决方案. ggplot(mtcars)+geom_bar(aes(x=cyl)) 1.theme_classic() 应用R自带的主题,比如theme_classic(),就可以使图片美观许多,不仅背景去掉了,坐标轴也更加清晰,如下图所示: ggplot(mtcars)+geom_bar(aes(x=
-
解决R语言安装时出现辑程包不存在的问题
[解决方案] 1.使用命令单独安装caret,安装的时间很长. install.packages("caret", dependencies = c("Depends", "Suggests")) 需要安装依赖的包全部安装之后,就可以了. 依赖包如下: dependencies 'doMC', 'rpvm', 'Rcompression', 'RMySQL', 'globaltest', 'OpenMx', 'pryr', 'gpclib', '