Python机器学习多层感知机原理解析
目录
- 隐藏层
- 从线性到非线性
- 激活函数
- ReLU函数
- sigmoid函数
- tanh函数
隐藏层
我们在前面描述了仿射变换,它是一个带有偏置项的线性变换。首先,回想下之前下图中所示的softmax回归的模型结构。该模型通过单个仿射变换将我们的输入直接映射到输出,然后进行softmax操作。如果我们的标签通过仿射变换后确实与我们的输入数据相关,那么这种方法就足够了。但是,仿射变换中的线性是一个很强的假设。
我们的数据可能会有一种表示,这种表示会考虑到我们的特征之间的相关交互作用。在此表示的基础上建立一个线性模型可能会是合适的,但我们不知道如何手动计算这么一种表示。对于深度神经网络,我们使用观测数据来联合学习隐藏层表示和应用于该表示的线性预测器。
我们可以通过在网络中加入一个或多个隐藏层来克服线性模型的限制,使其能处理更普遍的函数关系类型。要做到这一点,最简单的方法是将许多全连接层堆叠在一起。每一层都输出到上面的层,直到生成最后的输出。我们可以把前L−1层看作表示,把最后一层看作线性预测器。这种架构通常称为多层感知机(multilayer perceptron),通常缩写为MLP。下面,我们以图的方式描述了多层感知机。

这个多层感知机有4个输入,3个输出,其隐藏层包含5个隐藏单元。输入层不涉及任何计算,因此使用此网络产生输出只需要实现隐藏层和输出层的计算;因此,这个多层感知机的层数为2。注意,这个层都是全连接的。每个输入都会影响隐藏层中的每个神经元,而隐藏层中的每个神经元又会影响输出层的每个神经元。
然而,具有全连接层的多层感知机的参数开销可能会高得令人望而却步,即使在不改变输入和输出大小的情况下,也可能促使在参数节约和模型有效性之间进行权衡。
从线性到非线性

注意,在添加隐藏层之后,模型现在需要跟踪和更新额外的参数。
可我们能从中得到什么好处呢?这里我们会惊讶地发现:在上面定义的模型里,我们没有好处。上面的隐藏单元由输入的仿射函数给出,而输出(softmax操作前)只是隐藏单元的仿射函数。仿射函数的仿射函数本身就是仿射函数。但是我们之前的线性模型已经能够表示任何仿射函数。

由于 X中的每一行对应于小批量中的一个样本,处于记号习惯的考量,我们定义非线性函数 σ也以按行的方式作用于其输入,即一次计算一个样本。我们在之前以相同的方式使用了softmax符号来表示按行操作。但是在本节中,我们应用于隐藏层的激活函数通常不仅仅是按行的,而且也是按元素。这意味着在计算每一层的线性部分之后,我们可以计算每个激活值,而不需要查看其他隐藏单元所取的值。对于大多数激活函数都是这样。

激活函数
激活函数通过计算加权和并加上偏置来确定神经元是否应该被激活。它们是输入信号转换为输出的可微运算。大多数激活函数都是非线性的。由于激活函数是深度学习的基础,下面简要介绍一些常见的激活函数。
import torch from d2l import torch as d2l
ReLU函数
最受欢迎的选择是线性整流单元,因为它实现简单,同时在各种预测任务中表现良好。ReLU提供了一种非常简单的非线性变换。给定元素x ,ReLU函数被定义为该元素与0的最大值:
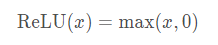
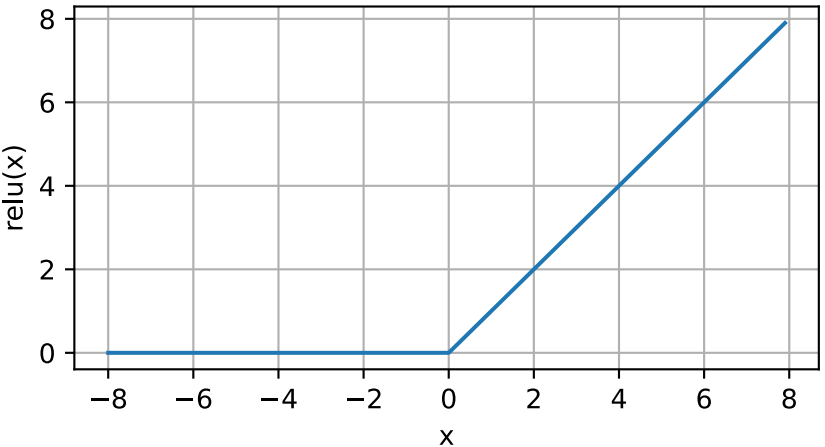
通俗地说,ReLU函数通过将相应的激活值设为0来仅保留正元素并丢弃所有负元素。为了直观感受下,我们可以画出函数的曲线图。下图所示,激活函数是分段线性的。
x = torch.arange(-8, 8, 0.1, requires_grad=True) y = torch.relu(x) d2l.plot(x.detach(), y.detach(), 'x', 'relu(x)', figsize=(5, 2.5))
注意,当输入值精确等于0时,ReLU函数不可导。在此时,我们默认使用左侧的导数,即当输入为0时导数为0。我们可以忽略这种情况,因为输入可能永远都不会是0。这里用上一句古老的谚语,“如果微妙的边界条件很重要,我们很可能是在研究数学而非工程”,这个观点正好适用于这里。下面我们绘制ReLU函数的导数。
y.backward(torch.ones_ilke(x), retain_graph=True) d2l.plot(x.detach(), x.grad, 'x', 'grad of relu', figsize=(5, 2.5))

使用ReLU的原因是,它求导表现得特别好,要么让参数消失,要么让参数通过。这使得优化表现得更好,并且ReLU减轻了困扰以往神经网络梯度消失问题。
注意,ReLU函数有许多变体,包括参数化ReLU函数(Parameterized ReLU)。该变体为ReLU添加了一个线性项,因此即使参数是负的,某些信息仍然可以通过:

sigmoid函数

在最早的神经网络中,科学家们感兴趣的是对“激发”或“不激发”的生物神经元进行建模。因此,这一领域的先驱,如人工神经元的发明者麦卡洛克和皮茨,从他们开始就专注于阈值单元。阈值单元在其输入低于某个阈值时取值为0,当输入超过阈值时取1。
当人们的注意力逐渐转移到梯度的学习时,sigmoid函数是一个自然的选择,因为它是一个平滑的、可微的阈值单元近似。当我们想要将输出视作二分类问题的概率时,sigmoid仍然被广泛用作输出单元上的激活函数(可以将sigmoid视为softmax的特例)。然而, sigmoid在隐藏层中已经较少使用,它在大部分时候已经被更简单、更容易训练的ReLU所取代。

tanh函数
与sigmoid函数类似,tanh(双曲正切)函数也能将其输入压缩转换到区间(-1,1)上。tanh函数的公式如下:

下面我们绘制tanh函数。注意,当输入在0附近时,tanh函数接近线性变换。函数的形状类似于sigmoid函数,不同的是tanh函数关于坐标系原点中心对称。

以上就是Python机器学习多层感知机原理解析的详细内容,更多关于Python机器学习多层感知机的资料请关注我们其它相关文章!
相关推荐
-

感知器基础原理及python实现过程详解
简单版本,按照李航的<统计学习方法>的思路编写 数据采用了著名的sklearn自带的iries数据,最优化求解采用了SGD算法. 预处理增加了标准化操作. ''' perceptron classifier created on 2019.9.14 author: vince ''' import pandas import numpy import logging import matplotlib.pyplot as plt from sklearn.datasets import loa
-
python实现多层感知器
写了个多层感知器,用bp梯度下降更新,拟合正弦曲线,效果凑合. # -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt def sigmod(z): return 1.0 / (1.0 + np.exp(-z)) class mlp(object): def __init__(self, lr=0.1, lda=0.0, te=1e-5, epoch=100, size=None): self.lear
-
python实现多层感知器MLP(基于双月数据集)
本文实例为大家分享了python实现多层感知器MLP的具体代码,供大家参考,具体内容如下 1.加载必要的库,生成数据集 import math import random import matplotlib.pyplot as plt import numpy as np class moon_data_class(object): def __init__(self,N,d,r,w): self.N=N self.w=w self.d=d self.r=r def sgn(self,x): i
-
python实现感知机模型的示例
from sklearn.linear_model import Perceptron import argparse #一个好用的参数传递模型 import numpy as np from sklearn.datasets import load_iris #数据集 from sklearn.model_selection import train_test_split #训练集和测试集分割 from loguru import logger #日志输出,不清楚用法 #python is a
-
Python机器学习多层感知机原理解析
目录 隐藏层 从线性到非线性 激活函数 ReLU函数 sigmoid函数 tanh函数 隐藏层 我们在前面描述了仿射变换,它是一个带有偏置项的线性变换.首先,回想下之前下图中所示的softmax回归的模型结构.该模型通过单个仿射变换将我们的输入直接映射到输出,然后进行softmax操作.如果我们的标签通过仿射变换后确实与我们的输入数据相关,那么这种方法就足够了.但是,仿射变换中的线性是一个很强的假设. 我们的数据可能会有一种表示,这种表示会考虑到我们的特征之间的相关交互作用.在此表示的基础上建立
-
Python机器学习logistic回归代码解析
本文主要研究的是Python机器学习logistic回归的相关内容,同时介绍了一些机器学习中的概念,具体如下. Logistic回归的主要目的:寻找一个非线性函数sigmod最佳的拟合参数 拟合.插值和逼近是数值分析的三大工具 回归:对一直公式的位置参数进行估计 拟合:把平面上的一些系列点,用一条光滑曲线连接起来 logistic主要思想:根据现有数据对分类边界线建立回归公式.以此进行分类 sigmoid函数:在神经网络中它是所谓的激励函数.当输入大于0时,输出趋向于1,输入小于0时,输出趋向0
-
python标识符命名规范原理解析
这篇文章主要介绍了python标识符命名规范原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 简单地理解,标识符就是一个名字,就好像我们每个人都有属于自己的名字,它的主要作用就是作为变量.函数.类.模块以及其他对象的名称. Python 中标识符的命名不是随意的,而是要遵守一定的命令规则,比如说: 1.标识符是由字符(A~Z 和 a~z).下划线和数字组成,但第一个字符不能是数字. 2.标识符不能和 Python 中的保留字相同.有关保留
-
Python @property装饰器原理解析
这篇文章主要介绍了Python @property装饰器原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 1.通过@property装饰器,可以直接通过方法名来访问方法,不需要在方法名后添加一对"()"小括号. class Person: def __init__(self, name): self.__name = name @property def say(self): return self.__name xioabai
-
python线程join方法原理解析
这篇文章主要介绍了python线程join方法原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 几个事实 1 python 默认参数创建线程后,不管主线程是否执行完毕,都会等待子线程执行完毕才一起退出,有无join结果一样 2 如果创建线程,并且设置了daemon为true,即thread.setDaemon(True), 则主线程执行完毕后自动退出,不会等待子线程的执行结果.而且随着主线程退出,子线程也消亡. 3 join方法的作用是阻
-
python机器学习实现神经网络示例解析
目录 单神经元引论 参考 多神经元 单神经元引论 对于如花,大美,小明三个因素是如何影响小强这个因素的. 这里用到的是多元的线性回归,比较基础 from numpy import array,exp,dot,random 其中dot是点乘 导入关系矩阵: X= array ( [ [0,0,1],[1,1,1],[1,0,1],[0,1,1]]) y = array( [ [0,1,1,0]]).T ## T means "transposition" 为了满足0到1的可能性,我们采用
-
python机器学习Logistic回归原理推导
目录 前言 Logistic回归原理与推导 sigmoid函数 目标函数 梯度上升法 Logistic回归实践 数据情况 训练算法 算法优缺点 前言 Logistic回归涉及到高等数学,线性代数,概率论,优化问题.本文尽量以最简单易懂的叙述方式,以少讲公式原理,多讲形象化案例为原则,给读者讲懂Logistic回归.如对数学公式过敏,引发不适,后果自负. Logistic回归原理与推导 Logistic回归中虽然有回归的字样,但该算法是一个分类算法,如图所示,有两类数据(红点和绿点)分布如下,如果
-
Python动态强类型解释型语言原理解析
PYTHON是一门动态解释性的强类型定义语言:编写时无需定义变量类型:运行时变量类型强制固定:无需编译,在解释器环境直接运行. 动态和静态 静态语言:是指在编译时变量的数据类型即可确定的语言,多数静态类型语言要求在使用变量之前必须声明数据类型.例如:C++.Java.Delphi.C# .go等. 动态语言:是在运行时确定数据类型的语言.变量使用之前不需要类型声明,通常变量的类型是被赋值的那个值的类型.例如:Python.Ruby.Perl等. 强类型和弱类型 强类型和弱类型主要是站在变量类型处
-
Python常用数据分析模块原理解析
前言 python是一门优秀的编程语言,而是python成为数据分析软件的是因为python强大的扩展模块.也就是这些python的扩展包让python可以做数据分析,主要包括numpy,scipy,pandas,matplotlib,scikit-learn等等诸多强大的模块,在结合上ipython交互工具 ,以及python强大的爬虫数据获取能力,字符串处理能力,让python成为完整的数据分析工具. numpy 官网:https://www.scipy.org/ NumPy(Numeric
-
Python小波变换去噪的原理解析
一.小波去噪的原理 信号产生的小波系数含有信号的重要信息,将信号经小波分解后小波系数较大,噪声的小波系数较小,并且噪声的小波系数要小于信号的小波系数,通过选取一个合适的阀值,大于阀值的小波系数被认为是有信号产生的,应予以保留,小于阀值的则认为是噪声产生的,置为零从而达到去噪的目的.小波阀值去噪的基本问题包括三个方面:小波基的选择,阀值的选择,阀值函数的选择. (1) 小波基的选择:通常我们希望所选取的小波满足以下条件:正交性.高消失矩.紧支性.对称性或反对称性.但事实上具有上述性质的小波是不可能