tensorflow没有output结点,存储成pb文件的例子
Tensorflow中保存成pb file 需要 使用函数
graph_util.convert_variables_to_constants(sess, sess.graph_def,
output_node_names=[]) []中需要填写你需要保存的结点。如果保存的结点在神经网络中没有被显示定义该怎么办?
例如我使用了tf.contrib.slim或者keras,在tf的高层很多情况下都会这样。
在写神经网络时,只需要简单的一层层传导,一个slim.conv2d层就包含了kernal,bias,activation function,非常的方便,好处是网络结构一目了然,坏处是什么呢?

在尝试保存pb的 output node names时,需要将最后的输出结点保存下来,与这个结点相关的,从输入开始,经过层层传递的嵌套函数或者操作的相关结点,都会被保存,但无效的例如 计算准确率,计算loss等,就可以省略了,因为保存的pb主要是用来做预测的。
在准备查看所有的结点名称并选取保存时,发现scope "local3"里面仅有相关的weights 和biases,这两个是单独存在的,即保存这两个参数并没有任何意义。

那么这时候有两种解决办法:
方法一:
graph_util.convert_variables_to_constants(sess, sess.graph_def, output_node_names=[var.name[:-2] for var in tf.global_variables()])
那么这个的意思是所有的variable的都被保存下来 但函数中要求的是 node name 我们通过 global_variables获得的是 变量名 并不是 节点名
(例如 output:0 就是变量名,又叫tensor name)
output就是 node name了。
在tensorboard中可以一窥究竟
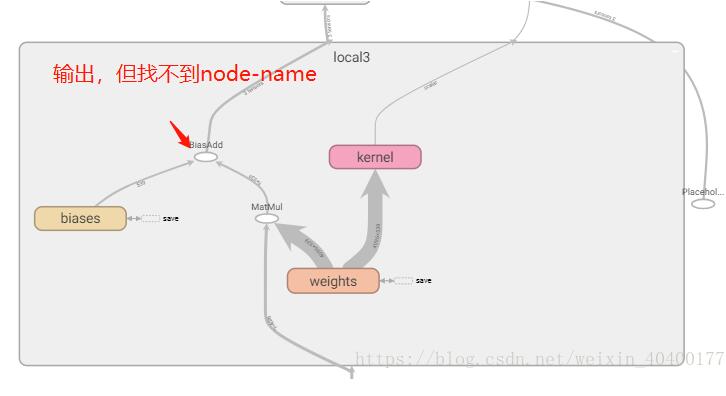
通过这样 也可以将 所有的变量全部保存下来(但是你并不能使用,是因为你的output并没有名字,所以你不可以通过常用的sess.graph.get_tensor_by_name来使用)
方法二:
那就是直接改写神经网络了....当然了还是比较简单的,只要改写最后一个,改写成output即可,tensorflow中无论是 变量、操作op、函数、都可以命名,那么这个地方是一个简单的全连接,仅需要将weights*net(上一层的输出) +bias 即可,我们只要将bias相加的结果命名为 ouput即可:
with tf.name_scope('local3'):
local3_weights = tf.Variable(tf.truncated_normal([4096, self.output_size], stddev=0.1))
local3_bias = tf.Variable(tf.constant(0.1, shape=[self.output_size]))
result = tf.add(tf.matmul(net, local3_weights), local3_bias, name="output")
这样将上述的convert_variables_to_constants中的output_node_names只需要填写一个['output']即可,因为这一个output结点,需要从input开始,将所有的神经网络前向传播的操作和参数全部保存下来,因此保存的结点数量 和 方法一保存的结点数量是一样的(console显示都是 convert 24)。
完整的pb保存为:(我是将ckpt读入进来,然后存成pb的)
from tensorflow.python.platform import gfile
load_ckpt():
path = './data/output/loss1.0/'
print("read from ckpt")
ckpt = tf.train.get_checkpoint_state(path)
saver = tf.train.Saver()
saver.restore(sess, ckpt.model_checkpoint_path)
def write2pb_file():
constant_graph = graph_util.convert_variables_to_constants(sess, sess.graph_def,
output_node_names=["output"])
with tf.gfile.GFile(path+'loss1.0.pb', mode='wb') as f:
f.write(constant_graph.SerializeToString())
print("Model is saved as " + path+'loss1.0.pb')
def main():
load_ckpt()
write2pb_file()
如果是简单的直接保存,那就更简单了。
pb文件的read,很多人会将一个net写成一个类,在引入的时候会将新建这个类,然后读入ckpt文件,这完全没有问题,但是在读取pb时,就会发生问题,因为pb中已经包含了图与参数,引入时会创建一个默认的图,但是net类中自己也会创建一个图,那么这时候你运行程序,参数其实并没有使用.pb的文件。
所以我们不能创建net类,然后直接读入.pb文件,对.pb文件,通过如下代码,获取.pb的graph中的输入和输出。
self.output = self.sess.graph.get_tensor_by_name("output:0")
self.input = self.sess.graph.get_tensor_by_name("images:0")
注意此时要加:0 因为你获取的不再是结点了,而是一个真实的变量,我的理解是,结点相当于一个类,:0是对象,默认初始化值就是对象的初始化。
然后就可以通过self.sess.run(self.output(feed_dict={self.input: your_input})))运行你的网络了!
以上这篇tensorflow没有output结点,存储成pb文件的例子就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

详解Tensorflow数据读取有三种方式(next_batch)
Tensorflow数据读取有三种方式: Preloaded data: 预加载数据 Feeding: Python产生数据,再把数据喂给后端. Reading from file: 从文件中直接读取 这三种有读取方式有什么区别呢? 我们首先要知道TensorFlow(TF)是怎么样工作的. TF的核心是用C++写的,这样的好处是运行快,缺点是调用不灵活.而Python恰好相反,所以结合两种语言的优势.涉及计算的核心算子和运行框架是用C++写的,并提供API给Python.Python调用这些A
-
TensorFlow模型保存/载入的两种方法
TensorFlow 模型保存/载入 我们在上线使用一个算法模型的时候,首先必须将已经训练好的模型保存下来.tensorflow保存模型的方式与sklearn不太一样,sklearn很直接,一个sklearn.externals.joblib的dump与load方法就可以保存与载入使用.而tensorflow由于有graph, operation 这些概念,保存与载入模型稍显麻烦. 一.基本方法 网上搜索tensorflow模型保存,搜到的大多是基本的方法.即 保存 定义变量 使用saver.s
-
对tensorflow中的strides参数使用详解
在二维卷积函数tf.nn.conv2d(),最大池化函数tf.nn.max_pool(),平均池化函数 tf.nn.avg_pool()中,卷积核的移动步长都需要制定一个参数strides(步长),因为无论是卷积操作还是各种类型的池化操作,都是某种形式的滑动窗口(sliding window)处理,这就要求指定从当前窗口移动下一个窗口位置的移动步长. TensorFlow 文档关于 strides的说明如下: strides: A list of ints that has length >=
-
TensorFlow 模型载入方法汇总(小结)
一.TensorFlow常规模型加载方法 保存模型 tf.train.Saver()类,.save(sess, ckpt文件目录)方法 参数名称 功能说明 默认值 var_list Saver中存储变量集合 全局变量集合 reshape 加载时是否恢复变量形状 True sharded 是否将变量轮循放在所有设备上 True max_to_keep 保留最近检查点个数 5 restore_sequentially 是否按顺序恢复变量,模型较大时顺序恢复内存消耗小 True var_list是字典
-
tensorflow实现tensor中满足某一条件的数值取出组成新的tensor
首先使用tf.where()将满足条件的数值索引取出来,在numpy中,可以直接用矩阵引用索引将满足条件的数值取出来,但是在tensorflow中这样是不行的.所幸,tensorflow提供了tf.gather()和tf.gather_nd()函数. 看下面这一段代码: import tensorflow as tf sess = tf.Session() def get_tensor(): x = tf.random_uniform((5, 4)) ind = tf.where(x>0.5)
-
tensorflow没有output结点,存储成pb文件的例子
Tensorflow中保存成pb file 需要 使用函数 graph_util.convert_variables_to_constants(sess, sess.graph_def, output_node_names=[]) []中需要填写你需要保存的结点.如果保存的结点在神经网络中没有被显示定义该怎么办? 例如我使用了tf.contrib.slim或者keras,在tf的高层很多情况下都会这样. 在写神经网络时,只需要简单的一层层传导,一个slim.conv2d层就包含了kernal,b
-
将tensorflow模型打包成PB文件及PB文件读取方式
1. tensorflow模型文件打包成PB文件 import tensorflow as tf from tensorflow.python.tools import freeze_graph with tf.Graph().as_default(): with tf.device("/cpu:0"): config = tf.ConfigProto(allow_soft_placement=True) with tf.Session(config=config).as_defaul
-
tensorflow实现将ckpt转pb文件的方法
本博客实现将自己训练保存的ckpt模型转换为pb文件,该方法适用于任何ckpt模型,当然你需要确定ckpt模型输入/输出的节点名称. 使用 tf.train.saver()保存模型时会产生多个文件,会把计算图的结构和图上参数取值分成了不同的文件存储.这种方法是在TensorFlow中是最常用的保存方式. 例如:下面的代码运行后,会在save目录下保存了四个文件: import tensorflow as tf # 声明两个变量 v1 = tf.Variable(tf.random_normal(
-
TensorFlow:将ckpt文件固化成pb文件教程
本文是将yolo3目标检测框架训练出来的ckpt文件固化成pb文件,主要利用了GitHub上的该项目. 为什么要最终生成pb文件呢?简单来说就是直接通过tf.saver保存行程的ckpt文件其变量数据和图是分开的.我们知道TensorFlow是先画图,然后通过placeholde往图里面喂数据.这种解耦形式存在的方法对以后的迁移学习以及对程序进行微小的改动提供了极大的便利性.但是对于训练好,以后不再改变的话这种存在就不再需要.一方面,ckpt文件储存的数据都是变量,既然我们不再改动,就应当让其变
-
如何使用C#将Tensorflow训练的.pb文件用在生产环境详解
前言 TensorFlow是Google开源的一款人工智能学习系统.为什么叫这个名字呢?Tensor的意思是张量,代表N维数组:Flow的意思是流,代表基于数据流图的计算.把N维数字从流图的一端流动到另一端的过程,就是人工智能神经网络进行分析和处理的过程. 训练了很久的Tf模型,终于要到生产环境中去考研一番了.今天花费了一些时间去研究tf的模型如何在生产环境中去使用.大概整理了这些方法. 继续使用分步骤保存了的ckpt文件 这个貌似脱离不了tensorflow框架,而且生成的ckpt文件比较大,
-
TensorFlow实现checkpoint文件转换为pb文件
由于项目需要,需要将TensorFlow保存的模型从ckpt文件转换为pb文件. import os from tensorflow.python import pywrap_tensorflow from net2use import inception_resnet_v2_small#这里使用自己定义的模型函数即可 import tensorflow as tf if __name__=='__main__': pb_file = "./model/output.pb" ckpt_
-
Tensorflow 使用pb文件保存(恢复)模型计算图和参数实例详解
一.保存: graph_util.convert_variables_to_constants 可以把当前session的计算图串行化成一个字节流(二进制),这个函数包含三个参数:参数1:当前活动的session,它含有各变量 参数2:GraphDef 对象,它描述了计算网络 参数3:Graph图中需要输出的节点的名称的列表 返回值:精简版的GraphDef 对象,包含了原始输入GraphDef和session的网络和变量信息,它的成员函数SerializeToString()可以把这些信息串行
-
tensorflow使用freeze_graph.py将ckpt转为pb文件的方法
废话少说直接上代码样例如下 import tensorflow as tf import os from tensorflow.python.tools import freeze_graph # 本来这个model本无需解释太多,但是这么多人不能耐下心来看,那么我简单的说一下吧 # network是你们自己定义的模型结构而已 # ps: # def network(input): # return tf.layers.max_pooling2d(input, 2, 2) from model
-
tensorflow模型文件(ckpt)转pb文件的方法(不知道输出节点名)
网上关于tensorflow模型文件ckpt格式转pb文件的帖子很多,本人几乎尝试了所有方法,最后终于成功了,现总结如下.方法无外乎下面两种: 使用tensorflow.python.tools.freeze_graph.freeze_graph 使用graph_util.convert_variables_to_constants 1.tensorflow模型的文件解读 使用tensorflow训练好的模型会自动保存为四个文件,如下 checkpoint:记录近几次训练好的模型结果(名称).
-
tensorflow从ckpt和从.pb文件读取变量的值方式
最近在学习tensorflow自带的量化工具的相关知识,其中遇到的一个问题是从tensorflow保存好的ckpt文件或者是保存后的.pb文件(这里的pb是把权重和模型保存在一起的pb文件)读取权重,查看量化后的权重是否变成整形. 因此将自己解决这个问题记录下来,为了下一次遇到时,可以有所参考,也希望给有需要的同学一个可能的参考. (1) 从保存的ckpt读取变量的值(以读取保存的第一个权重为例) from tensorflow.python import pywrap_tensorflow i