java编程Reference核心原理示例源码分析
带着问题,看源码针对性会更强一点、印象会更深刻、并且效果也会更好。所以我先卖个关子,提两个问题(没准下次跳槽时就被问到)。
- 我们可以用ByteBuffer的allocateDirect方法,申请一块堆外内存创建一个DirectByteBuffer对象,然后利用它去操作堆外内存。这些申请完的堆外内存,我们可以回收吗?可以的话是通过什么样的机制回收的?
- 大家应该都知道WeakHashMap可以用来实现内存相对敏感的本地缓存,为什么WeakHashMap合适这种业务场景,其内部实现会做什么特殊处理呢?
GC可到达性与JDK中Reference类型
上面提到的两个问题,其答案都在JDK的Reference里面。JDK早期版本中并没有Reference相关的类,这导致对象被GC回收后如果想做一些额外的清理工作(比如socket、堆外内存等)是无法实现的,同样如果想要根据堆内存的实际使用情况决定要不要去清理一些内存敏感的对象也是法实现的。
为此JDK1.2中引入的Reference相关的类,即今天要介绍的Reference、SoftReference、WeakReference、PhantomReference,还有与之相关的Cleaner、ReferenceQueue、ReferenceHandler等。与Reference相关核心类基本都在java.lang.ref包下面。其类关系如下:
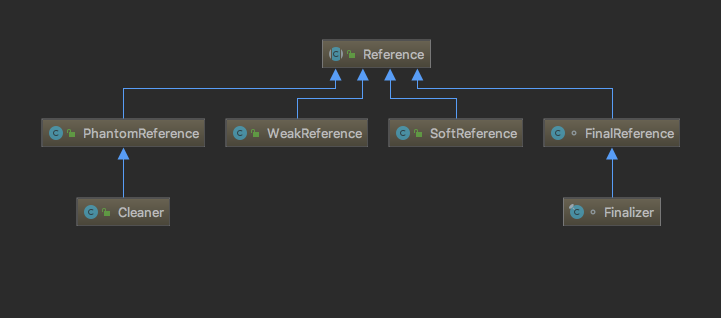
其中,SoftReference代表软引用对象,垃圾回收器会根据内存需求酌情回收软引用指向的对象。普通的GC并不会回收软引用,只有在即将OOM的时候(也就是最后一次Full GC)如果被引用的对象只有SoftReference指向的引用,才会回收。WeakReference代表弱引用对象,当发生GC时,如果被引用的对象只有WeakReference指向的引用,就会被回收。PhantomReference代表虚引用对象(也有叫幻象引用的,个人认为还是虚引用更加贴切),其是一种特殊的引用类型,不能通过虚引用获取到其关联的对象,但当GC时如果其引用的对象被回收,这个事件程序可以感知,这样我们可以做相应的处理。最后就是最常见强引用对象,也就是通常我们new出来的对象。在继续介绍Reference相关类的源码前,先来简单的看一下GC如何决定一个对象是否可被回收。其基本思路是从GC Root开始向下搜索,如果对象与GC Root之间存在引用链,则对象是可达的,GC会根据是否可到达与可到达性决定对象是否可以被回收。而对象的可达性与引用类型密切相关,对象的可到达性可分为5种。
- 强可到达,如果从GC Root搜索后,发现对象与GC Root之间存在强引用链则为强可到达。强引用链即有强引用对象,引用了该对象。
- 软可到达,如果从GC Root搜索后,发现对象与GC Root之间不存在强引用链,但存在软引用链,则为软可到达。软引用链即有软引用对象,引用了该对象。
- 弱可到达,如果从GC Root搜索后,发现对象与GC Root之间不存在强引用链与软引用链,但有弱引用链,则为弱可到达。弱引用链即有弱引用对象,引用了该对象。
- 虚可到达,如果从GC Root搜索后,发现对象与GC Root之间只存在虚引用链则为虚可到达。虚引用链即有虚引用对象,引用了该对象。
- 不可达,如果从GC Root搜索后,找不到对象与GC Root之间的引用链,则为不可到达。
看一个简单的列子:

ObjectA为强可到达,ObjectB也为强可到达,虽然ObjectB对象被SoftReference ObjcetE 引用但由于其还被ObjectA引用所以为强可到达;而ObjectC和ObjectD为弱引用达到,虽然ObjectD对象被PhantomReference ObjcetG引用但由于其还被ObjectC引用,而ObjectC又为弱引用达到,所以ObjectD为弱引用达到;而ObjectH与ObjectI是不可到达。引用链的强弱有关系依次是 强引用 > 软引用 > 弱引用 > 虚引用,如果有更强的引用关系存在,那么引用链到达性,将由更强的引用有关系决定。
Reference核心处理流程
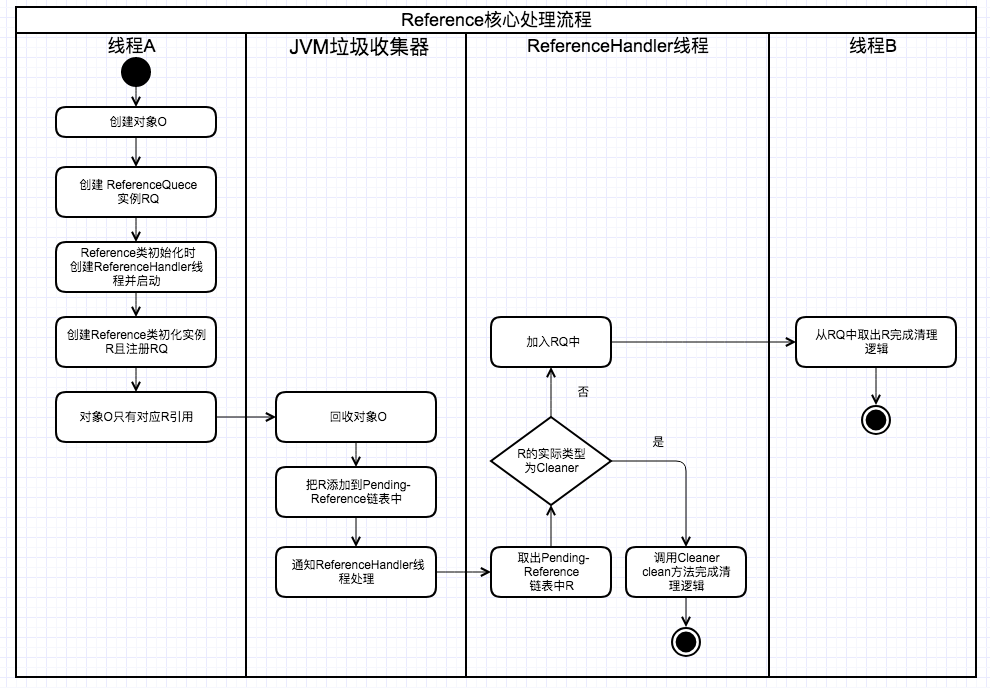
JVM在GC时如果当前对象只被Reference对象引用,JVM会根据Reference具体类型与堆内存的使用情况决定是否把对应的Reference对象加入到一个由Reference构成的pending链表上,如果能加入pending链表JVM同时会通知ReferenceHandler线程进行处理。ReferenceHandler线程是在Reference类被初始化时调用的,其是一个守护进程并且拥有最高的优先级。Reference类静态初始化块代码如下:
static {
//省略部分代码...
Thread handler = new ReferenceHandler(tg, "Reference Handler");
handler.setPriority(Thread.MAX_PRIORITY);
handler.setDaemon(true);
handler.start();
//省略部分代码...
}
而ReferenceHandler线程内部的run方法会不断地从Reference构成的pending链表上获取Reference对象,如果能获取则根据Reference的具体类型进行不同的处理,不能则调用wait方法等待GC回收对象处理pending链表的通知。ReferenceHandler线程run方法源码:
public void run() {
//死循环,线程启动后会一直运行
while (true) {
tryHandlePending(true);
}
}
run内部调用的tryHandlePending源码:
static boolean tryHandlePending(boolean waitForNotify) {
Reference<Object> r;
Cleaner c;
try {
synchronized (lock) {
if (pending != null) {
r = pending;
//instanceof 可能会抛出OOME,所以在将r从pending链上断开前,做这个处理
c = r instanceof Cleaner ? (Cleaner) r : null;
//将将r从pending链上断开
pending = r.discovered;
r.discovered = null;
} else {
//等待CG后的通知
if (waitForNotify) {
lock.wait();
}
//重试
return waitForNotify;
}
}
} catch (OutOfMemoryError x) {
//当抛出OOME时,放弃CPU的运行时间,这样有希望收回一些存活的引用并且GC能回收部分空间。同时能避免频繁地自旋重试,导致连续的OOME异常
Thread.yield();
//重试
return true;
} catch (InterruptedException x) {
//重试
return true;
}
//如果是Cleaner类型的Reference调用其clean方法并退出
if (c != null) {
c.clean();
return true;
}
ReferenceQueue<? super Object> q = r.queue;
//如果Reference有注册ReferenceQueue,则处理pending指向的Reference结点将其加入ReferenceQueue中
if (q != ReferenceQueue.NULL) q.enqueue(r);
return true;
}
上面tryHandlePending方法中比较重要的点是c.clean()与q.enqueue®,这个是文章最开始提到的两个问题答案的入口。Cleaner的clean方法用于完成清理工作,而ReferenceQueue是将被回收对象加入到对应的Reference列队中,等待其他线程的后继处理。更具体地关于Cleaner与ReferenceQueue后面会再详细说明。Reference的核心处理流程可总结如下:
对Reference的核心处理流程有整体了解后,再来回过头细看一下Reference类的源码。
/* Reference实例有四种内部的状态
* Active: 新创建Reference的实例其状态为Active。当GC检测到Reference引用的referent可达到状态发生改变时,
* 为改变Reference的状态为Pending或Inactive。这个取决于创建Reference实例时是否注册过ReferenceQueue。
* 注册过其状态会转换为Pending,同时GC会将其加入pending-Reference链表中,否则为转换为Inactive状态。
* Pending: 代表Reference是pending-Reference链表的成员,等待ReferenceHandler线程调用Cleaner#clean
* 或ReferenceQueue#enqueue操作。未注册过ReferenceQueue的实例不会达到这个状态
* Enqueued: Reference实例成为其被创建时注册过的ReferenceQueue的成员,代表已入队列。当其从ReferenceQueue
* 中移除后,其状态会变为Inactive。
* Inactive: 什么也不会做,一旦处理该状态,就不可再转换。
* 不同状态时,Reference对应的queue与成员next变量值(next可理解为ReferenceQueue中的下个结点的引用)如下:
* Active: queue为Reference实例被创建时注册的ReferenceQueue,如果没注册为Null。此时,next为null,
* Reference实例与queue真正产生关系。
* Pending: queue为Reference实例被创建时注册的ReferenceQueue。next为当前实例本身。
* Enqueued: queue为ReferenceQueue.ENQUEUED代表当前实例已入队列。next为queue中的下一实列结点,
* 如果是queue尾部则为当前实例本身
* Inactive: queue为ReferenceQueue.NULL,当前实例已从queue中移除与queue无关联。next为当前实例本身。
*/
public abstract class Reference<T> {
// Reference 引用的对象
private T referent;
/* Reference注册的queue用于ReferenceHandler线程入队列处理与用户线程取Reference处理。
* 其取值会根据Reference不同状态发生改变,具体取值见上面的分析
*/
volatile ReferenceQueue<? super T> queue;
// 可理解为注册的queue中的下一个结点的引用。其取值会根据Reference不同状态发生改变,具体取值见上面的分析
volatile Reference next;
/* 其由VM维护,取值会根据Reference不同状态发生改变,
* 状态为active时,代表由GC维护的discovered-Reference链表的下个节点,如果是尾部则为当前实例本身
* 状态为pending时,代表pending-Reference的下个节点的引用。否则为null
*/
transient private Reference<T> discovered;
/* pending-Reference 链表头指针,GC回收referent后会将Reference加pending-Reference链表。
* 同时ReferenceHandler线程会获取pending指针,不为空时Cleaner.clean()或入列queue。
* pending-Reference会采用discovered引用接链表的下个节点。
*/
private static Reference<Object> pending = null;
// 可理解为注册的queue中的下一个结点的引用。其取值会根据Reference不同状态发生改变,具体取值见上面的分析
volatile Reference next;
//用于CG同步Reference成员变量值的对象。
static private class Lock { }
private static Lock lock = new Lock();
//省略部分代码...
}
上面解释了Reference中的主要成员的作用,其中比较重要是Reference内部维护的不同状态,其状态不同成员变量queue、pending、discovered、next的取值都会发生变化。Reference的主要方法如下:
//构造函数,指定引用的对象referent
Reference(T referent) {
this(referent, null);
}
//构造函数,指定引用的对象referent与注册的queue
Reference(T referent, ReferenceQueue<? super T> queue) {
this.referent = referent;
this.queue = (queue == null) ? ReferenceQueue.NULL : queue;
}
//获取引用的对象referent
public T get() {
return this.referent;
}
//将当前对象加入创建时注册的queue中
public boolean enqueue() {
return this.queue.enqueue(this);
}
ReferenecQueue与Cleaner源码分析
先来看下ReferenceQueue的主要成员变量的含义。
//代表Reference的queue为null。Null为ReferenceQueue子类 static ReferenceQueue<Object> NULL = new Null<>(); //代表Reference已加入当前ReferenceQueue中。 static ReferenceQueue<Object> ENQUEUED = new Null<>(); //用于同步的对象 private Lock lock = new Lock(); //当前ReferenceQueue中的头节点 private volatile Reference<? extends T> head = null; //ReferenceQueue的长度 private long queueLength = 0;
ReferenceQueue中比较重要的方法为enqueue、poll、remove方法。
//入列队enqueue方法,只被Reference类调用,也就是上面分析中ReferenceHandler线程为调用
boolean enqueue(Reference<? extends T> r) {
//获取同步对象lock对应的监视器对象
synchronized (lock) {
//获取r关联的ReferenceQueue,如果创建r时未注册ReferenceQueue则为NULL,同样如果r已从ReferenceQueue中移除其也为null
ReferenceQueue<?> queue = r.queue;
//判断queue是否为NULL 或者 r已加入ReferenceQueue中,是的话则入队列失败
if ((queue == NULL) || (queue == ENQUEUED)) {
return false;
}
assert queue == this;
//设置r的queue为已入队列
r.queue = ENQUEUED;
//如果ReferenceQueue头节点为null则r的next节点指向当前节点,否则指向头节点
r.next = (head == null) ? r : head;
//更新ReferenceQueue头节点
head = r;
//列队长度加1
queueLength++;
//为FinalReference类型引用增加FinalRefCount数量
if (r instanceof FinalReference) {
sun.misc.VM.addFinalRefCount(1);
}
//通知remove操作队列有节点
lock.notifyAll();
return true;
}
}
poll方法源码相对简单,其就是从ReferenceQueue的头节点获取Reference。
public Reference<? extends T> poll() {
//头结点为null直接返回,代表Reference还没有加入ReferenceQueue中
if (head == null)
return null;
//获取同步对象lock对应的监视器对象
synchronized (lock) {
return reallyPoll();
}
}
//从队列中真正poll元素的方法
private Reference<? extends T> reallyPoll() {
Reference<? extends T> r = head;
//double check 头节点不为null
if (r != null) {
//保存头节点的下个节点引用
Reference<? extends T> rn = r.next;
//更新queue头节点引用
head = (rn == r) ? null : rn;
//更新Reference的queue值,代表r已从队列中移除
r.queue = NULL;
//更新Reference的next为其本身
r.next = r;
queueLength--;
//为FinalReference节点FinalRefCount数量减1
if (r instanceof FinalReference) {
sun.misc.VM.addFinalRefCount(-1);
}
//返回获取的节点
return r;
}
return null;
}
remove方法的源码如下:
public Reference<? extends T> remove(long timeout) throws IllegalArgumentException, InterruptedException {
if (timeout < 0) {
throw new IllegalArgumentException("Negative timeout value");
}
//获取同步对象lock对应的监视器对象
synchronized (lock) {
//获取队列头节点指向的Reference
Reference<? extends T> r = reallyPoll();
//获取到返回
if (r != null) return r;
long start = (timeout == 0) ? 0 : System.nanoTime();
//在timeout时间内尝试重试获取
for (;;) {
//等待队列上有结点通知
lock.wait(timeout);
//获取队列中的头节点指向的Reference
r = reallyPoll();
//获取到返回
if (r != null) return r;
if (timeout != 0) {
long end = System.nanoTime();
timeout -= (end - start) / 1000_000;
//已超时但还没有获取到队列中的头节点指向的Reference返回null
if (timeout <= 0) return null;
start = end;
}
}
}
}
简单的分析完ReferenceQueue的源码后,再来整体回顾一下Reference的核心处理流程。JVM在GC时如果当前对象只被Reference对象引用,JVM会根据Reference具体类型与堆内存的使用情况决定是否把对应的Reference对象加入到一个由Reference构成的pending链表上,如果能加入pending链表JVM同时会通知ReferenceHandler线程进行处理。ReferenceHandler线程收到通知后会调用Cleaner#clean或ReferenceQueue#enqueue方法进行处理。如果引用当前对象的Reference类型为WeakReference且堆内存不足,那么JMV就会把WeakReference加入到pending-Reference链表上,然后ReferenceHandler线程收到通知后会异步地做入队列操作。而我们的应用程序中的线程便可以不断地去拉取ReferenceQueue中的元素来感知JMV的堆内存是否出现了不足的情况,最终达到根据堆内存的情况来做一些处理的操作。实际上WeakHashMap低层便是过通上述过程实现的,只不过实现细节上有所偏差,这个后面再分析。再来看看ReferenceHandler线程收到通知后可能会调用的另外一个类Cleaner的实现。
同样先看一下Cleaner的成员变量,再看主要的方法实现。
//继承了PhantomReference类也就是虚引用,PhantomReference源码很简单只是重写了get方法返回null
public class Cleaner extends PhantomReference<Object> {
/* 虚队列,命名很到位。之前说CG把ReferenceQueue加入pending-Reference链中后,ReferenceHandler线程在处理时
* 是不会将对应的Reference加入列队的,而是调用Cleaner.clean方法。但如果Reference不注册ReferenceQueue,GC处理时
* 又无法把他加入到pending-Reference链中,所以Cleaner里面有了一个dummyQueue成员变量。
*/
private static final ReferenceQueue<Object> dummyQueue = new ReferenceQueue();
//Cleaner链表的头结点
private static Cleaner first = null;
//当前Cleaner节点的后续节点
private Cleaner next = null;
//当前Cleaner节点的前续节点
private Cleaner prev = null;
//真正执行清理工作的Runnable对象,实际clean内部调用thunk.run()方法
private final Runnable thunk;
//省略部分代码...
}
从上面的成变量分析知道Cleaner实现了双向链表的结构。先看构造函数与clean方法。
//私有方法,不能直接new
private Cleaner(Object var1, Runnable var2) {
super(var1, dummyQueue);
this.thunk = var2;
}
//创建Cleaner对象,同时加入Cleaner链中。
public static Cleaner create(Object var0, Runnable var1) {
return var1 == null ? null : add(new Cleaner(var0, var1));
}
//头插法将新创意的Cleaner对象加入双向链表,synchronized保证同步
private static synchronized Cleaner add(Cleaner var0) {
if (first != null) {
var0.next = first;
first.prev = var0;
}
//更新头节点引用
first = var0;
return var0;
}
public void clean() {
//从Cleaner链表中先移除当前节点
if (remove(this)) {
try {
//调用thunk.run()方法执行对应清理逻辑
this.thunk.run();
} catch (final Throwable var2) {
//省略部分代码..
}
}
}
可以看到Cleaner的实现还是比较简单,Cleaner实现为PhantomReference类型的引用。当JVM GC时如果发现当前处理的对象只被PhantomReference类型对象引用,同之前说的一样其会将该Reference加pending-Reference链中上,只是ReferenceHandler线程在处理时如果PhantomReference类型实际类型又是Cleaner的话。其就是调用Cleaner.clean方法做清理逻辑处理。Cleaner实际是DirectByteBuffer分配的堆外内存收回的实现,具体见下面的分析。
DirectByteBuffer堆外内存回收与WeakHashMap敏感内存回收
绕开了一大圈终于回到了文章最开始提到的两个问题,先来看一下分配给DirectByteBuffer堆外内存是如何回收的。在创建DirectByteBuffer时我们实际是调用ByteBuffer#allocateDirect方法,而其实现如下:
public static ByteBuffer allocateDirect(int capacity) {
return new DirectByteBuffer(capacity);
}
DirectByteBuffer(int cap) {
//省略部分代码...
try {
//调用unsafe分配内存
base = unsafe.allocateMemory(size);
} catch (OutOfMemoryError x) {
//省略部分代码...
}
//省略部分代码...
//前面分析中的Cleaner对象创建,持有当前DirectByteBuffer的引用
cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
att = null;
}
里面和DirectByteBuffer堆外内存回收相关的代码便是Cleaner.create(this, new Deallocator(base, size, cap))这部分。还记得之前说实际的清理逻辑是里面和DirectByteBuffer堆外内存回收相关的代码便是Cleaner里面的Runnable#run方法吗?直接看Deallocator.run方法源码:
public void run() {
if (address == 0) {
// Paranoia
return;
}
//通过unsafe.freeMemory释放创建的堆外内存
unsafe.freeMemory(address);
address = 0;
Bits.unreserveMemory(size, capacity);
}
终于找到了分配给DirectByteBuffer堆外内存是如何回收的的答案。再总结一下,创建DirectByteBuffer对象时会创建一个Cleaner对象,Cleaner对象持有了DirectByteBuffer对象的引用。当JVM在GC时,如果发现DirectByteBuffer被地方法没被引用啦,JVM会将其对应的Cleaner加入到pending-reference链表中,同时通知ReferenceHandler线程处理,ReferenceHandler收到通知后,会调用Cleaner#clean方法,而对于DirectByteBuffer创建的Cleaner对象其clean方法内部会调用unsafe.freeMemory释放堆外内存。最终达到了DirectByteBuffer对象被GC回收其对应的堆外内存也被回收的目的。
再来看一下文章开始提到的另外一个问题WeakHashMap如何实现敏感内存的回收。实际WeakHashMap实现上其Entry继承了WeakReference。
//Entry继承了WeakReference, WeakReference引用的是Map的key
private static class Entry<K,V> extends WeakReference<Object> implements Map.Entry<K,V> {
V value;
final int hash;
Entry<K,V> next;
/**
* 创建Entry对象,上面分析过的ReferenceQueue,这个queue实际是WeakHashMap的成员变量,
* 创建WeakHashMap时其便被初始化 final ReferenceQueue<Object> queue = new ReferenceQueue<>()
*/
Entry(Object key, V value,
ReferenceQueue<Object> queue,
int hash, Entry<K,V> next) {
super(key, queue);
this.value = value;
this.hash = hash;
this.next = next;
}
//省略部分原码...
}
往WeakHashMap添加元素时,实际都会调用Entry的构造方法,也就是会创建一个WeakReference对象,这个对象的引用的是WeakHashMap刚加入的Key,而所有的WeakReference对象关联在同一个ReferenceQueue上。我们上面说过JVM在GC时,如果发现当前对象只有被WeakReference对象引用,那么会把其对应的WeakReference对象加入到pending-reference链表上,并通知ReferenceHandler线程处理。而ReferenceHandler线程收到通知后,对于WeakReference对象会调用ReferenceQueue#enqueue方法把他加入队列里面。现在我们只要关注queue里面的元素在WeakHashMap里面是在哪里被拿出去啦做了什么样的操作,就能找到文章开始问题的答案啦。最终能定位到WeakHashMap的expungeStaleEntries方法。
private void expungeStaleEntries() {
//不断地从ReferenceQueue中取出,那些只有被WeakReference对象引用的对象的Reference
for (Object x; (x = queue.poll()) != null; ) {
synchronized (queue) {
//转为 entry
Entry<K,V> e = (Entry<K,V>) x;
//计算其对应的桶的下标
int i = indexFor(e.hash, table.length);
//取出桶中元素
Entry<K,V> prev = table[i];
Entry<K,V> p = prev;
//桶中对应位置有元素,遍历桶链表所有元素
while (p != null) {
Entry<K,V> next = p.next;
//如果当前元素(也就是entry)与queue取出的一致,将entry从链表中去除
if (p == e) {
if (prev == e)
table[i] = next;
else
prev.next = next;
// Must not null out e.next;
//清空entry对应的value
e.value = null;
size--;
break;
}
prev = p;
p = next;
}
}
}
}
现在只看一下WeakHashMap哪些地方会调用expungeStaleEntries方法就知道什么时候WeakHashMap里面的Key变得软可达时我们就可以将其对应的Entry从WeakHashMap里面移除。直接调用有三个地方分别是getTable方法、size方法、resize方法。 getTable方法又被很多地方调用如get、containsKey、put、remove、containsValue、replaceAll。最终看下来,只要对WeakHashMap进行操作就行调用expungeStaleEntries方法。所有只要操作了WeakHashMap,没WeakHashMap里面被再用到的Key对应的Entry就会被清除。再来总结一下,为什么WeakHashMap适合作为内存敏感缓存的实现。当JVM 在GC时,如果发现WeakHashMap里面某些Key没地方在被引用啦(WeakReference除外),JVM会将其对应的WeakReference对象加入到pending-reference链表上,并通知ReferenceHandler线程处理。而ReferenceHandler线程收到通知后将对应引用Key的WeakReference对象加入到 WeakHashMap内部的ReferenceQueue中,下次再对WeakHashMap做操作时,WeakHashMap内部会清除那些没有被引用的Key对应的Entry。这样就达到了每操作WeakHashMap时,自动的检索并清量没有被引用的Key对应的Entry的目地。
总结
本文通过两个问题引出了JDK中Reference相关类的源码分析,最终给出了问题的答案。但实际上一般开发规范中都会建议禁止重写Object#finalize方法同样与Reference类关系密切(具体而言是Finalizer类)。受篇幅的限制本文并未给出分析,有待各位自己看源码啦。半年没有写文章啦,有点对不住关注的小伙伴。希望看完本文各位或多或少能有所收获。如果觉得本文不错就帮忙转发记得标一下出处,谢谢。后面我还会继续分享一些自己觉得比较重要的东西给大家。由于个人能力有限,文中不足与错误还望指正。
以上就是java编程Reference核心原理示例源码分析的详细内容,更多关于Reference核心原理的资料请关注我们其它相关文章!
相关推荐
-
Java 中 Reference用法详解
Java Reference详解 在 jdk 1.2 及其以后,引入了强引用.软引用.弱引用.虚引用这四个概念.网上很多关于这四个概念的解释,但大多是概念性的泛泛而谈,今天我结合着代码分析了一下,首先我们先来看定义与大概解释(引用类型在包 Java.lang.ref 里). 1.强引用(StrongReference) 强引用不会被GC回收,并且在java.lang.ref里也没有实际的对应类型.举个例子来说: Object obj = new Object(); 这里的obj引用便是一个强引
-
java中的Reference类型用法说明
本文简要总结java中的Reference类型. 最近在研读jdk并发框架,其中AQS是重点,由于我打破砂锅问到底的轻微强迫症,google了AQS作者Doug Lea的论文原文[The java.util.concurrent Synchronizer Framework],有兴趣的同学可以自行下载.其中谈到设计同步框架的核心是选择一个严格意义上的FIFO队列,作为阻塞线程队列并对其进行维护. 对此主要由两种选择,一个是MCS锁,另一个时CLH锁.因为CLH锁比MCS对取消和超时的处理更方便,
-

Java中几个Reference常见的作用详解
前言 Java中几个Reference作用,也是面试的时候经常问到的问题,以前总是记一次忘一次,现在有时间,索性写个demo测试一把.下面来一起看看详细的介绍: 具体代码如下: JVM 参数: -Xmx10m -Xms5m -XX:+PrintGC SoftReference的时候: weakReference的时候: StrongReference: 由于strong是JVM默认的,这里就不做了,直接就是一点都不会被回收,直至OOM PhantomReference: 虚引用并不会改变内存回收
-
详解java中Reference的实现与相应的执行过程
一.Reference类型(除强引用) 可以理解为Reference的直接子类都是由jvm定制化处理的,因此在代码中直接继承于Reference类型没有任何作用.只能继承于它的子类,相应的子类类型包括以下几种.(忽略没有在java中使用的,如jnireference) SoftReference WeakReference FinalReference PhantomReference 上面的引用类型在相应的javadoc中也有提及.FinalReference专门为finalize方法设计,另
-
详解Java弱引用(WeakReference)的理解与使用
看到篇帖子, 国外一个技术面试官在面试senior java developer的时候, 问到一个weak reference相关的问题. 他没有期望有人能够完整解释清楚weak reference是什么, 怎么用, 只是期望有人能够提到这个concept和java的GC相关. 很可惜的是, 20多个拥有5年以上java开发经验的面试者中, 只有两人知道weak reference的存在, 而其中只有一人实际用到过他. 无疑, 在interviewer眼中, 对于weak reference的理
-
java编程Reference核心原理示例源码分析
带着问题,看源码针对性会更强一点.印象会更深刻.并且效果也会更好.所以我先卖个关子,提两个问题(没准下次跳槽时就被问到). 我们可以用ByteBuffer的allocateDirect方法,申请一块堆外内存创建一个DirectByteBuffer对象,然后利用它去操作堆外内存.这些申请完的堆外内存,我们可以回收吗?可以的话是通过什么样的机制回收的? 大家应该都知道WeakHashMap可以用来实现内存相对敏感的本地缓存,为什么WeakHashMap合适这种业务场景,其内部实现会做什么特殊处理呢?
-
Java中的InputStreamReader和OutputStreamWriter源码分析_动力节点Java学院整理
InputStreamReader和OutputStreamWriter源码分析 1. InputStreamReader 源码(基于jdk1.7.40) package java.io; import java.nio.charset.Charset; import java.nio.charset.CharsetDecoder; import sun.nio.cs.StreamDecoder; // 将"字节输入流"转换成"字符输入流" public class
-
关于Java Guava ImmutableMap不可变集合源码分析
目录 Java Guava不可变集合ImmutableMap的源码分析 一.案例场景 二.ImmutableMap源码分析 Java Guava不可变集合ImmutableMap的源码分析 一.案例场景 遇到过这样的场景,在定义一个static修饰的Map时,使用了大量的put()方法赋值,就类似这样-- public static final Map<String,String> dayMap= new HashMap<>(); static { dayMap.put("
-
Java 中的FileReader和FileWriter源码分析_动力节点Java学院整理
FileReader和FileWriter源码分析 1. FileReader 源码(基于jdk1.7.40) package java.io; public class FileReader extends InputStreamReader { public FileReader(String fileName) throws FileNotFoundException { super(new FileInputStream(fil java io系列21之 InputStreamReade
-
深入理解框架背后的原理及源码分析
目录 问题1 问题2 总结 近期团队中同学遇到几个问题,想在这儿跟大家分享一波,虽说不是很有难度,但是背后也折射出一些问题,值得思考. 开始之前先简单介绍一下我所在团队的技术栈,基于这个背景再展开后面将提到的几个问题,将会有更深刻的体会. 控制层基于SpringMvc,数据持久层基于JdbcTemplate自己封装了一套类MyBatis的Dao框架,视图层基于Velocity模板技术,其余组件基于SpringCloud全家桶. 问题1 某应用发布以后开始报数据库连接池不够用异常,日志如下: co
-
Java Shutdown Hook场景使用及源码分析
目录 背景 Shutdown Hook 介绍 关闭钩子被调用场景 注意事项 实践 Shutdown Hook 在 Spring 中的运用 背景 如果想在 Java 进程退出时,包括正常和异常退出,做一些额外处理工作,例如资源清理,对象销毁,内存数据持久化到磁盘,等待线程池处理完所有任务等等.特别是进程异常挂掉的情况,如果一些重要状态没及时保留下来,或线程池的任务没被处理完,有可能会造成严重问题.那该怎么办呢? Java 中的 Shutdown Hook 提供了比较好的方案.我们可以通过 Java
-
Nacos配置中心集群原理及源码分析
目录 Nacos集群工作原理 配置变更同步入口 AsyncNotifyService AsyncTask 目标节点接收请求 NacosDelayTaskExecuteEngine ProcessRunnable processTasks DumpProcessor.process Nacos作为配置中心,必然需要保证服务节点的高可用性,那么Nacos是如何实现集群的呢? 下面这个图,表示Nacos集群的部署图. Nacos集群工作原理 Nacos作为配置中心的集群结构中,是一种无中心化节点的设计
-
java并发容器CopyOnWriteArrayList实现原理及源码分析
CopyOnWriteArrayList是Java并发包中提供的一个并发容器,它是个线程安全且读操作无锁的ArrayList,写操作则通过创建底层数组的新副本来实现,是一种读写分离的并发策略,我们也可以称这种容器为"写时复制器",Java并发包中类似的容器还有CopyOnWriteSet.本文会对CopyOnWriteArrayList的实现原理及源码进行分析. 实现原理 我们都知道,集合框架中的ArrayList是非线程安全的,Vector虽是线程安全的,但由于简单粗暴的锁同步机制,
-
SpringBoot2入门自动配置原理及源码分析
目录 SpringBoot自动配置 一.@SpringBootApplication 1. @SpringBootConfiguration 2. @ComponentScan 3. @EnableAutoConfiguration 二.自动配置示例 1. 未生效的自动配置 2. 生效的自动配置 三.小结 SpringBoot自动配置 之前为什么会去了解一些底层注解,其实就是为了后续更好的了解 springboot 底层的一些原理,比如自动配置原理. 一.@SpringBootApplicati
-
java 中modCount 详解及源码分析
modCount到底是干什么的呢 在ArrayList,LinkedList,HashMap等等的内部实现增,删,改中我们总能看到modCount的身影,modCount字面意思就是修改次数,但为什么要记录modCount的修改次数呢? 大家发现一个公共特点没有,所有使用modCount属性的全是线程不安全的,这是为什么呢?说明这个玩意肯定和线程安全有关系喽,那有什么关系呢 阅读源码,发现这玩意只有在本数据结构对应迭代器中才使用,以HashMap为例: private abstract clas