如何用六步教会你使用python爬虫爬取数据
目录
- 前言:
- python爬出六部曲
- 第一步:安装requests库和BeautifulSoup库:
- 第二步:获取爬虫所需的header和cookie:
- 第三步:获取网页:
- 第四步:解析网页:
- 第五步:分析得到的信息,简化地址:
- 第六步:爬取内容,清洗数据
- 爬取微博热搜的代码实例以及结果展示:
- 总结
前言:
用python的爬虫爬取数据真的很简单,只要掌握这六步就好,也不复杂。以前还以为爬虫很难,结果一上手,从初学到把东西爬下来,一个小时都不到就解决了。
python爬出六部曲
第一步:安装requests库和BeautifulSoup库:
在程序中两个库的书写是这样的:
import requests from bs4 import BeautifulSoup
由于我使用的是pycharm进行的python编程。所以我就讲讲在pycharm上安装这两个库的方法。在主页面文件选项下,找到设置。进一步找到项目解释器。之后在所选框中,点击软件包上的+号就可以进行查询插件安装了。有过编译器插件安装的hxd估计会比较好入手。具体情况就如下图所示。
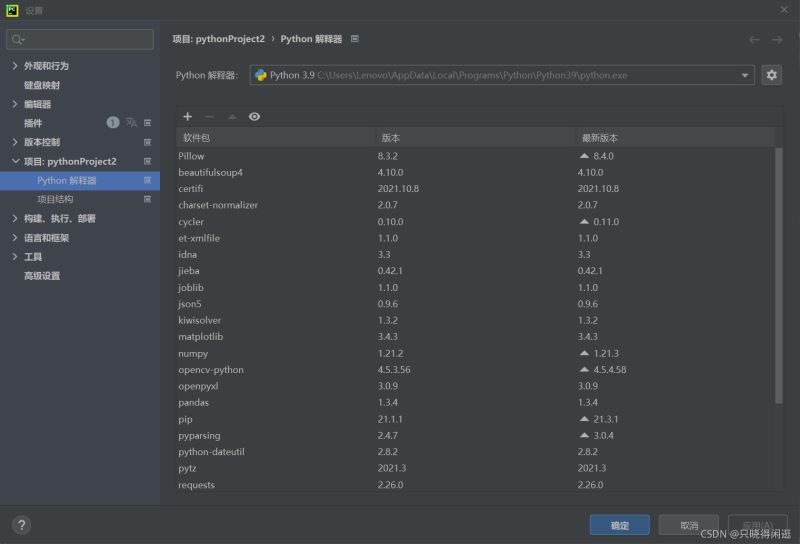
第二步:获取爬虫所需的header和cookie:
我写了一个爬取微博热搜的爬虫程序,这里就直接以它为例吧。获取header和cookie是一个爬虫程序必须的,它直接决定了爬虫程序能不能准确的找到网页位置进行爬取。
首先进入微博热搜的页面,按下F12,就会出现网页的js语言设计部分。如下图所示。找到网页上的Network部分。然后按下ctrl+R刷新页面。如果,进行就有文件信息,就不用刷新了,当然刷新了也没啥问题。然后,我们浏览Name这部分,找到我们想要爬取的文件,鼠标右键,选择copy,复制下网页的URL。就如下图所示。
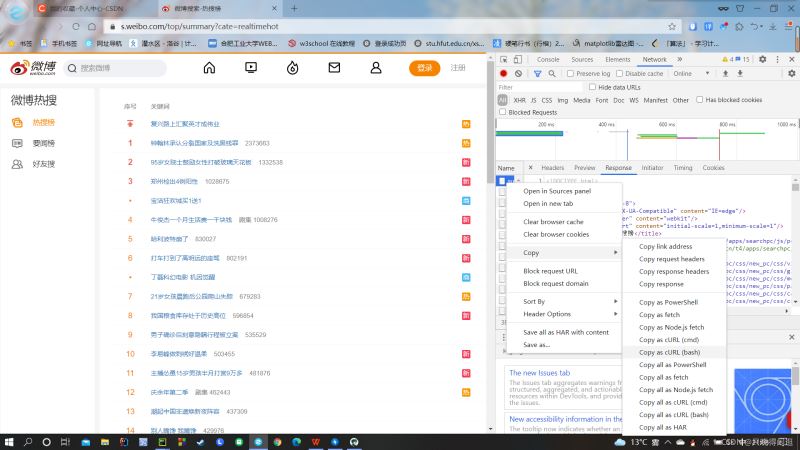
复制好URL后,我们就进入一个网页Convert curl commands to code。这个网页可以根据你复制的URL,自动生成header和cookie,如下图。生成的header和cookie,直接复制走就行,粘贴到程序中。
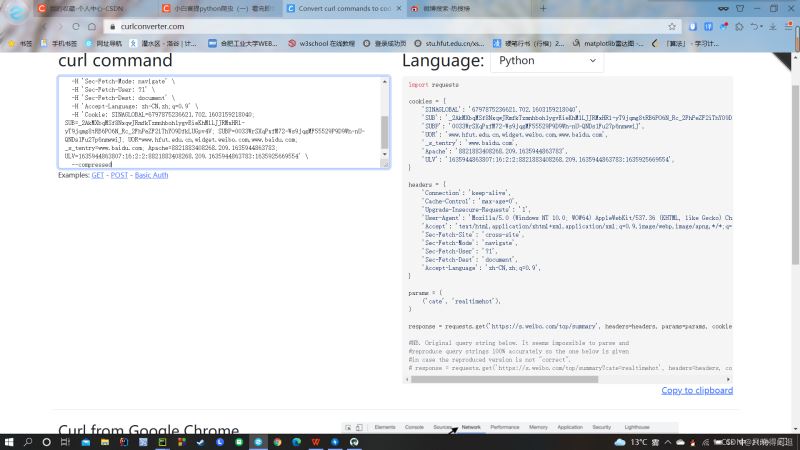
#爬虫头数据
cookies = {
'SINAGLOBAL': '6797875236621.702.1603159218040',
'SUB': '_2AkMXbqMSf8NxqwJRmfkTzmnhboh1ygvEieKhMlLJJRMxHRl-yT9jqmg8tRB6PO6N_Rc_2FhPeZF2iThYO9DfkLUGpv4V',
'SUBP': '0033WrSXqPxfM72-Ws9jqgMF55529P9D9Wh-nU-QNDs1Fu27p6nmwwiJ',
'_s_tentry': 'www.baidu.com',
'UOR': 'www.hfut.edu.cn,widget.weibo.com,www.baidu.com',
'Apache': '7782025452543.054.1635925669528',
'ULV': '1635925669554:15:1:1:7782025452543.054.1635925669528:1627316870256',
}
headers = {
'Connection': 'keep-alive',
'Cache-Control': 'max-age=0',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36 SLBrowser/7.0.0.6241 SLBChan/25',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Sec-Fetch-Site': 'cross-site',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-User': '?1',
'Sec-Fetch-Dest': 'document',
'Accept-Language': 'zh-CN,zh;q=0.9',
}
params = (
('cate', 'realtimehot'),
)
复制到程序中就像这样。这是微博热搜的请求头。
第三步:获取网页:
我们将header和cookie搞到手后,就可以将它复制到我们的程序里。之后,使用request请求,就可以获取到网页了。
#获取网页
response = requests.get('https://s.weibo.com/top/summary', headers=headers, params=params, cookies=cookies)
第四步:解析网页:
这个时候,我们需要回到网页。同样按下F12,找到网页的Elements部分。用左上角的小框带箭头的标志,如下图,点击网页内容,这个时候网页就会自动在右边显示出你获取网页部分对应的代码。

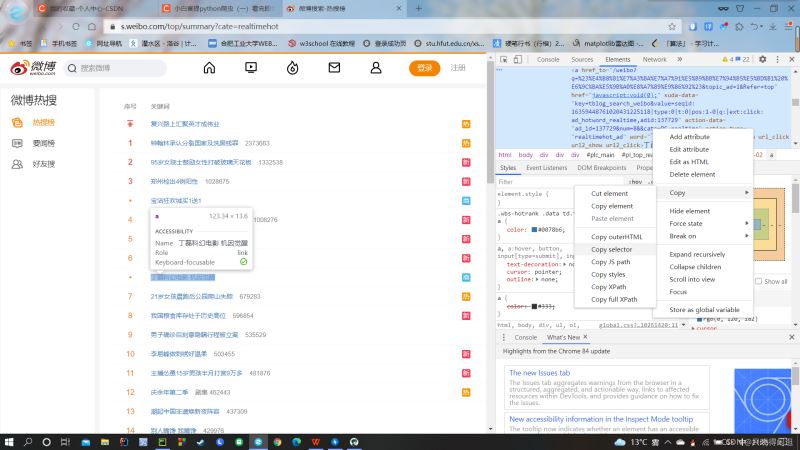
如上图所示,我们在找到想要爬取的页面部分的网页代码后,将鼠标放置于代码上,右键,copy到selector部分。就如上图所示。
第五步:分析得到的信息,简化地址:
其实刚才复制的selector就相当于网页上对应部分存放的地址。由于我们需要的是网页上的一类信息,所以我们需要对获取的地址进行分析,提取。当然,就用那个地址也不是不行,就是只能获取到你选择的网页上的那部分内容。
#pl_top_realtimehot > table > tbody > tr:nth-child(1) > td.td-02 > a #pl_top_realtimehot > table > tbody > tr:nth-child(2) > td.td-02 > a #pl_top_realtimehot > table > tbody > tr:nth-child(9) > td.td-02 > a
这是我获取的三条地址,可以发现三个地址有很多相同的地方,唯一不同的地方就是tr部分。由于tr是网页标签,后面的部分就是其补充的部分,也就是子类选择器。可以推断出,该类信息,就是存储在tr的子类中,我们直接对tr进行信息提取,就可以获取到该部分对应的所有信息。所以提炼后的地址为:
#pl_top_realtimehot > table > tbody > tr > td.td-02 > a
这个过程对js类语言有一定了解的hxd估计会更好处理。不过没有js类语言基础也没关系,主要步骤就是,保留相同的部分就行,慢慢的试,总会对的。
第六步:爬取内容,清洗数据
这一步完成后,我们就可以直接爬取数据了。用一个标签存储上面提炼出的像地址一样的东西。标签就会拉取到我们想获得的网页内容。
#爬取内容 content="#pl_top_realtimehot > table > tbody > tr > td.td-02 > a"
之后我们就要soup和text过滤掉不必要的信息,比如js类语言,排除这类语言对于信息受众阅读的干扰。这样我们就成功的将信息,爬取下来了。
fo = open("./微博热搜.txt",'a',encoding="utf-8")
a=soup.select(content)
for i in range(0,len(a)):
a[i] = a[i].text
fo.write(a[i]+'\n')
fo.close()
我是将数据存储到了文件夹中,所以会有wirte带来的写的操作。想把数据保存在哪里,或者想怎么用,就看读者自己了。
爬取微博热搜的代码实例以及结果展示:
import os
import requests
from bs4 import BeautifulSoup
#爬虫头数据
cookies = {
'SINAGLOBAL': '6797875236621.702.1603159218040',
'SUB': '_2AkMXbqMSf8NxqwJRmfkTzmnhboh1ygvEieKhMlLJJRMxHRl-yT9jqmg8tRB6PO6N_Rc_2FhPeZF2iThYO9DfkLUGpv4V',
'SUBP': '0033WrSXqPxfM72-Ws9jqgMF55529P9D9Wh-nU-QNDs1Fu27p6nmwwiJ',
'_s_tentry': 'www.baidu.com',
'UOR': 'www.hfut.edu.cn,widget.weibo.com,www.baidu.com',
'Apache': '7782025452543.054.1635925669528',
'ULV': '1635925669554:15:1:1:7782025452543.054.1635925669528:1627316870256',
}
headers = {
'Connection': 'keep-alive',
'Cache-Control': 'max-age=0',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36 SLBrowser/7.0.0.6241 SLBChan/25',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Sec-Fetch-Site': 'cross-site',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-User': '?1',
'Sec-Fetch-Dest': 'document',
'Accept-Language': 'zh-CN,zh;q=0.9',
}
params = (
('cate', 'realtimehot'),
)
#数据存储
fo = open("./微博热搜.txt",'a',encoding="utf-8")
#获取网页
response = requests.get('https://s.weibo.com/top/summary', headers=headers, params=params, cookies=cookies)
#解析网页
response.encoding='utf-8'
soup = BeautifulSoup(response.text, 'html.parser')
#爬取内容
content="#pl_top_realtimehot > table > tbody > tr > td.td-02 > a"
#清洗数据
a=soup.select(content)
for i in range(0,len(a)):
a[i] = a[i].text
fo.write(a[i]+'\n')
fo.close()

总结
到此这篇关于如何用六步教会你使用python爬虫爬取数据的文章就介绍到这了,更多相关python爬虫爬取数据内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python爬虫爬取网页表格数据
用python爬取网页表格数据,供大家参考,具体内容如下 from bs4 import BeautifulSoup import requests import csv import bs4 #检查url地址 def check_link(url): try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: print('无法链接服务器!!!')
-

Python爬虫:通过关键字爬取百度图片
使用工具:Python2.7 点我下载 scrapy框架 sublime text3 一.搭建python(Windows版本) 1.安装python2.7 ---然后在cmd当中输入python,界面如下则安装成功 2.集成Scrapy框架----输入命令行:pip install Scrapy 安装成功界面如下: 失败的情况很多,举例一种: 解决方案: 其余错误可百度搜索. 二.开始编程. 1.爬取无反爬虫措施的静态网站.例如百度贴吧,豆瓣读书. 例如-<桌面吧>的一个帖子https:
-
python制作爬虫爬取京东商品评论教程
本篇文章是python爬虫系列的第三篇,介绍如何抓取京东商城商品评论信息,并对这些评论信息进行分析和可视化.下面是要抓取的商品信息,一款女士文胸.这个商品共有红色,黑色和肤色三种颜色, 70B到90D共18个尺寸,以及超过700条的购买评论. 京东商品评论信息是由JS动态加载的,所以直接抓取商品详情页的URL并不能获得商品评论的信息.因此我们需要先找到存放商品评论信息的文件.这里我们使用Chrome浏览器里的开发者工具进行查找. 具体方法是在商品详情页点击鼠标右键,选择检查,在弹出的开发者工具界
-
如何使用python爬虫爬取要登陆的网站
你好 由于你是游客 无法查看本文 请你登录再进 谢谢合作..... 当你在爬某些网站的时候 需要你登录才可以获取数据 咋整? 莫慌 把这几招传授给你 让你以后从容应对 登录的常见方法无非是这两种 1.让你输入帐号和密码登录 2.让你输入帐号密码+验证码登录 今天 先跟你说说第一种 需要验证码的咱们下一篇再讲 第一招 Cookie大法 你平常在上某个不为人知的网站的时候 是不是发现你只要登录一次 就可以一直看到你想要的内容 过了一阵子才需要再次登录 这就是因为 Cookie 在做怪 简单来说 就是
-
使用Python爬虫爬取小红书完完整整的全过程
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理. 以下文章来源于Python进击者 ,作者kuls Python爬虫.数据分析.网站开发等案例教程视频免费在线观看 https://space.bilibili.com/523606542 小红书 首先,我们打开之前大家配置好的charles 我们来简单抓包一下小红书小程序(注意这里是小程序,不是app) 不选择app的原因是,小红书的App有点难度,参照网上的一些思路,还是选择了小程序 1
-
Python3实现的爬虫爬取数据并存入mysql数据库操作示例
本文实例讲述了Python3实现的爬虫爬取数据并存入mysql数据库操作.分享给大家供大家参考,具体如下: 爬一个电脑客户端的订单.罗总推荐,抓包工具用的是HttpAnalyzerStdV7,与chrome自带的F12类似.客户端有接单大厅,罗列所有订单的简要信息.当单子被接了,就不存在了.我要做的是新出订单就爬取记录到我的数据库zyc里. 设置每10s爬一次. 抓包工具页面如图: 首先是爬虫,先找到数据存储的页面,再用正则爬出. # -*- coding:utf-8 -*- import re
-
python爬虫实战之爬取京东商城实例教程
前言 本文主要介绍的是利用python爬取京东商城的方法,文中介绍的非常详细,下面话不多说了,来看看详细的介绍吧. 主要工具 scrapy BeautifulSoup requests 分析步骤 1.打开京东首页,输入裤子将会看到页面跳转到了这里,这就是我们要分析的起点 2.我们可以看到这个页面并不是完全的,当我们往下拉的时候将会看到图片在不停的加载,这就是ajax,但是当我们下拉到底的时候就会看到整个页面加载了60条裤子的信息,我们打开chrome的调试工具,查找页面元素时可以看到每条裤子的信
-
python爬虫爬取微博评论案例详解
前几天,杨超越编程大赛火了,大家都在报名参加,而我也是其中的一员. 在我们的项目中,我负责的是数据爬取这块,我主要是把对于杨超越 的每一条评论的相关信息. 数据格式:{"name":评论人姓名,"comment_time":评论时间,"comment_info":评论内容,"comment_url":评论人的主页} 以上就是我们需要的信息. 爬虫前的分析: 以上是杨超越的微博主页,这是我们首先需要获取到的内容. 因为我们需要等
-
Python爬虫爬取一个网页上的图片地址实例代码
本文实例主要是实现爬取一个网页上的图片地址,具体如下. 读取一个网页的源代码: import urllib.request def getHtml(url): html=urllib.request.urlopen(url).read() return html print(getHtml(http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=%E5%A3%81%E7%BA%B8&ct=201326592&am
-
Python实现爬取知乎神回复简单爬虫代码分享
看知乎的时候发现了一个 "如何正确地吐槽" 收藏夹,里面的一些神回复实在很搞笑,但是一页一页地看又有点麻烦,而且每次都要打开网页,于是想如果全部爬下来到一个文件里面,是不是看起来很爽,并且随时可以看到全部的,于是就开始动手了. 工具 1.Python 2.7 2.BeautifulSoup 分析网页 我们先来看看知乎上该网页的情况 网址:,容易看到,网址是有规律的,page慢慢递增,这样就能够实现全部爬取了. 再来看一下我们要爬取的内容: 我们要爬取两个内容:问题和回答,回答仅限于显示