Python深度学习线性代数示例详解
目录
- 标量
- 向量
- 长度、维度和形状
- 矩阵
- 张量
- 张量算法的基本性质
- 降维
- 点积
- 矩阵-矩阵乘法
- 范数
标量
标量由普通小写字母表示(例如,x、y和z)。我们用 R \mathbb{R} R表示所有(连续)实数标量的空间。
标量由只有一个元素的张量表示。下面代码,我们实例化了两个标量,并使用它们执行一些熟悉的算数运算,即加法、乘法、除法和指数。
import torch x = torch.tensor([3.0]) y = torch.tensor([2.0]) x + y, x * y, x / y, x ** y
tensor([5]), tensor([6]), tensor([1.5]), tensor([9])
向量
向量是标量值组成的列表,我们将这些标量值称为向量的元素或分量。
在数学表示法中,我们通常将向量记为粗体、小写的符号(例如, x \mathbf{x} x、 y \mathbf{y} y和 z \mathbf{z} z)
我们通过一维张量处理向量。一般来说,张量可以具有任意长度,最大长度取决于机器的内存限制。
x = torch.arange(4)
tensor([0, 1, 2, 3])
大量文献认为列向量是向量的默认方向。在数学中,向量 x \mathbf{x} x可以写为:
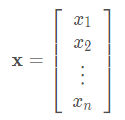
我们可以通过张量的索引来访问任一元素。
x[3]
tensor(3)
长度、维度和形状
在数学表示法中,如果我们想说一个向量 x \mathbf{x} x由 n n n个实值标量组成,我们可以将其表示为 x ∈ R n \mathbf{x} \in \mathbb{R}^{n} x∈Rn。向量的长度通常称为向量的维度。
与普通的Python数组一样,我们可以通过调用Python的内置len()函数来访问张量的长度。
len(x)
4
当用张量表示一个向量(只有一个轴)时,我们也可以通过.shape属性访问向量的长度。形状(shape)是一个元组,列出了张量沿每个轴的长度(维数)。对于只有一个轴的张量,形状只有一个元素。
x.shape
torch.Size([4])
注意,维度(dimension)这个词在不同上下文时往往会有不同的含义,这经常会使人感到困惑。为了清楚起见,我们在此明确一下。向量或轴的维度被用来表示向量或轴的长度,即向量或轴的元素数量。然而,张量的维度用来表示张量具有的轴数。在这个意义上,张量的某个轴的维数就是这个轴的长度。
矩阵

当矩阵具有相同数量的行和列时,其形状将变为正方形;因此,它被称为方矩阵。
当调用函数来实例化张量时,我们可以通过指定两个分量m和n来创建一个形状为 m×n的矩阵。
A = torch.arange(20).reshape(5, 4)
tensor([[0, 1, 2, 3],
[4, 5, 6, 7],
[8, 9, 10, 11],
[12, 13, 14, 15],
[16, 17, 18, 19]])

A.T
tensor([[0, 4, 8, 12, 16],
[1, 5, 9, 13, 17],
[2, 6, 10, 14, 18],
[3, 7, 11, 15, 19]])
矩阵是有用的数据结构:它们允许我们组织具有不同变化模式的数据。例如,我们矩阵中的行可能对应于不同的房屋(数据样本),而列可能对应于不同的属性。因此,尽管单个向量的默认方向是列向量,但在表示表格数据集的矩阵中,将每个数据样本作为矩阵中的行向量更为常见。
张量
张量为我们提供了描述具有任意数量轴的 n n n维数组的通用方法。
当我们开始处理图像时,张量将变得更加重要,图像以 n n n维数组形式出现,其中3个轴对应于高度、宽度以及一个通道(channel)轴,用于堆叠颜色通道(红色、绿色和蓝色)。现在,我们将跳过高阶张量,集中在基础知识上。
X = torch.arange(24).reshape(2, 3, 4)
tensor([[[0, 1, 2, 3],
[4, 5, 6, 7],
[8, 9, 10, 11]],
[[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]]])
张量算法的基本性质
任何按元素的一元运算都不会改变其操作数的形状。同样,给定具有相同形状的任意两个张量,任何按元素二元运算的结果都将是相同形状的张量。例如,将两个相同形状的矩阵相加会在这两个矩阵上执行元素的加法。
A = torch.arange(20, dtype=torch.float32).reshape(5,4) B = A.clone A, A + B
tensor([[0, 1, 2, 3],
[4, 5, 6, 7],
[8, 9, 10, 11],
[12, 13, 14, 15],
[16, 17, 18, 19]]),
tensor([[0, 2, 4, 6],
[8, 10, 12, 14],
[16, 18, 20, 22],
[24, 26, 28, 30],
[32, 34, 36, 38]])
具体而言,两个矩阵按元素乘法称为哈达玛积。
A * B
tensor([[0, 1, 4, 9],
[16, 25, 36, 49],
[64, 81, 100, 121],
[144, 169, 196, 225],
[256, 289, 324, 361]])
将张量乘以或加上一个标量不会改变张量的形状,其中张量的每个元素都将与标量相加或相乘。
降维
我们可以对任意张量进行一个有用的操作是计算其元素的和。在代码中,我们可以调用计算求和的函数:
x = torch.arange(4, dtype = torch.float32) x.sum()
tensor(6)
默认的情况下,调用求和函数会沿所有的轴降低张量的维度,使它变为一个标量。我们还可以指定张量沿哪一个轴来通过求和降低维度。以矩阵为例,为了通过求和所有行的元素来降维(轴0),我们可以在调用函数时指定axis = 0。由于输入矩阵沿着0轴降维以生成输出张量,因此输入的轴0的维数在输出形状中丢失。
A.shape
torch.Size([5, 4])
A_sum_axis0 = A.sum(axis = 0) A_sum_axis0, A_sum_axis0.shape
tensor([40, 45, 50, 55]), torch.Size([4])
指定axis = 1将通过汇总所有列的元素降维(轴1)。因此,输入的轴1的维数在输出形状中消失。
A_sum_axis1 = A.sum(axis = 1) A_sum_axis1, A_sum_axis1.shape
tensor([6, 22, 38, 54, 70]), torch.Size([5])
沿着行和列对矩阵求和,等价于对矩阵的所有元素进行求和。
A.sum(axis=[0, 1])
tensor(190)
一个与求和相关的量是平均值。在代码中,我们可以调用函数来计算任意形状张量的平均值。
A.mean()
同样,计算平均值的函数也可以沿指定轴降低张量的维度。
A.mean(axis = 0)
点积
最基本的操作是点积。
给定两个向量,点积是它们相同位置的按元素乘积的和。
y = torch.ones(4, dtype = torch.float32) x, y, torch.dot(x, y)
tensor([0, 1, 2, 3]), tensor([1, 1, 1, 1]), tensor(6)
矩阵-矩阵乘法
在下面的代码中,我们在A和B上执行矩阵乘法。这里的A是一个5行4列的矩阵,B是一个4行3列的矩阵。相乘后,我们得到一个5行3列的矩阵。
B = torch.ones(4, 3) torch.mm(A, B)
范数
线性代数中最有用的一些运算符是范数。非正式地说,一个向量的范数告诉我们一个向量有多大。这里考虑的大小(size)概念不涉及维度,而是分量的大小。
在线性代数中,向量范数是将向量映射到标量的函数 f f f。向量范数要满足一些属性。给定任意向量 x \mathbf{x} x,第一个性质来说,如果我们按常数因子 α \alpha α缩放向量的所有元素,其范数也会按相同常数因子的绝对值缩放:

第二个性质是我们熟悉的三角不等式:

第三个性质简单地说范数必须是非负的。
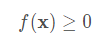
最后一个性质要求范数最小为0,当且仅当向量全由0组成。


u = torch.tensor([3, 4]) torch.norm(u)

u = torch.tensor([3, 4]) torch.abs(u).sum()
tensor(7)

torch.norm(torch.ones((4, 9)))
范数和目标:
在深度学习中,我们经常试图解决优化问题:最大化分配给观测数据的概率;最小化预测和真实观测之间的距离。用向量表示物品(如单词、产品或新闻文章),以便最小化相似项目之间的距离,最大化不同项目之间的距离。通常,目标,或许是深度学习算法最终要的组成部分(除了数据),被表达为范数。
以上就是Python深度学习线性代数示例详解的详细内容,更多关于Python线性代数的资料请关注我们其它相关文章!
相关推荐
-
Python 执行矩阵与线性代数运算
问题 你需要执行矩阵和线性代数运算,比如矩阵乘法.寻找行列式.求解线性方程组等等. 解决方案 NumPy 库有一个矩阵对象可以用来解决这个问题. 矩阵类似于3.9小节中数组对象,但是遵循线性代数的计算规则.下面的一个例子展示了矩阵的一些基本特性: >>> import numpy as np >>> m = np.matrix([[1,-2,3],[0,4,5],[7,8,-9]]) >>> m matrix([[ 1, -2, 3], [ 0, 4,
-

8种用Python实现线性回归的方法对比详解
前言 说到如何用Python执行线性回归,大部分人会立刻想到用sklearn的linear_model,但事实是,Python至少有8种执行线性回归的方法,sklearn并不是最高效的. 今天,让我们来谈谈线性回归.没错,作为数据科学界元老级的模型,线性回归几乎是所有数据科学家的入门必修课.抛开涉及大量数统的模型分析和检验不说,你真的就能熟练应用线性回归了么?未必! 在这篇文章中,文摘菌将介绍8种用Python实现线性回归的方法.了解了这8种方法,就能够根据不同需求,灵活选取最为高效的方法实现线
-
Python numpy线性代数用法实例解析
这篇文章主要介绍了Python numpy线性代数用法实例解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 numpy中线性代数用法 矩阵乘法 >>> import numpy as np >>> x=np.array([[1,2,3],[4,5,6]]) >>> y=np.array([[7,8],[-1,7],[8,9]]) >>> x array([[1, 2, 3], [4
-
python的几种矩阵相乘的公式详解
1. 同线性代数中矩阵乘法的定义: np.dot() np.dot(A, B):对于二维矩阵,计算真正意义上的矩阵乘积,同线性代数中矩阵乘法的定义.对于一维矩阵,计算两者的内积.见如下Python代码: import numpy as np # 2-D array: 2 x 3 two_dim_matrix_one = np.array([[1, 2, 3], [4, 5, 6]]) # 2-D array: 3 x 2 two_dim_matrix_two = np.array([[1, 2]
-
Python解决线性代数问题之矩阵的初等变换方法
定义一个矩阵初等行变换的类 class rowTransformation(): array = ([[],[]]) def __init__(self,array): self.array = array def __mul__(self, other): pass # 交换矩阵的两行 def exchange_two_lines(self,x,y): a = self.array[x-1:x].copy() self.array[x-1:x] = self.array[y-1:y] self
-
Python深度学习线性代数示例详解
目录 标量 向量 长度.维度和形状 矩阵 张量 张量算法的基本性质 降维 点积 矩阵-矩阵乘法 范数 标量 标量由普通小写字母表示(例如,x.y和z).我们用 R \mathbb{R} R表示所有(连续)实数标量的空间. 标量由只有一个元素的张量表示.下面代码,我们实例化了两个标量,并使用它们执行一些熟悉的算数运算,即加法.乘法.除法和指数. import torch x = torch.tensor([3.0]) y = torch.tensor([2.0]) x + y, x * y, x
-
Python-OpenCV深度学习入门示例详解
目录 0. 前言 1. 计算机视觉中的深度学习简介 1.1 深度学习的特点 1.2 深度学习大爆发 2. 用于图像分类的深度学习简介 3. 用于目标检测的深度学习简介 4. 深度学习框架 keras 介绍与使用 4.1 keras 库简介与安装 4.2 使用 keras 实现线性回归模型 4.3 使用 keras 进行手写数字识别 小结 0. 前言 深度学习已经成为机器学习中最受欢迎和发展最快的领域.自 2012 年深度学习性能超越机器学习等传统方法以来,深度学习架构开始快速应用于包括计算机视觉
-
python assert的用处示例详解
使用assert断言是学习python一个非常好的习惯,python assert 断言句语格式及用法很简单.在没完善一个程序之前,我们不知道程序在哪里会出错,与其让它在运行最崩溃,不如在出现错误条件时就崩溃,这时候就需要assert断言的帮助.本文主要是讲assert断言的基础知识. python assert断言的作用 python assert断言是声明其布尔值必须为真的判定,如果发生异常就说明表达示为假.可以理解assert断言语句为raise-if-not,用来测试表示式,其返回值为
-
python音频处理的示例详解
准备工作: 首先,我们需要 import 几个工具包,一个是 python 标准库中的 wave 模块,用于音频处理操作,另外两个是 numpy 和 matplot,提供数据处理函数. 一:读取本地音频数据 处理音频第一步是需要从让计算机"听到"声音,这里我们使用 python 标准库中自带的 wave模块进行音频参数的获取. (1) 导入 wave 模块 (2) 使用 wave 中的函数 open 打开音频文件,wave.open(file,mode)函数带有两个参数, 第一个 fi
-
Python模块glob函数示例详解教程
目录 本文大纲 支持4个常用的通配符 1)glob()函数 2)iglob()函数 3)escape()函数 总结 本文大纲 glob模块也是Python标准库中一个重要的模块,主要用来查找符合特定规则的目录和文件,并将搜索的到的结果返回到一个列表中.使用这个模块最主要的原因就是,该模块支持几个特殊的正则通配符,用起来贼方便,这个将会在下方为大家进行详细讲解. 支持4个常用的通配符 使用glob模块能够快速查找我们想要的目录和文件,就是由于它支持*.**.? .[ ]这三个通配符,那么它们到底是
-
python opencv图像处理基本操作示例详解
目录 1.图像基本操作 ①读取图像 ②显示图像 ③视频读取 ④图像截取 ⑤颜色通道提取及还原 ⑥边界填充 ⑦数值计算 ⑧图像融合 2.阈值与平滑处理 ①设定阈值并对图像处理 ②图像平滑-均值滤波 ③图像平滑-方框滤波 ④图像平滑-高斯滤波 ⑤图像平滑-中值滤波 3.图像的形态学处理 ①腐蚀操作 ②膨胀操作 ③开运算和闭运算 4.图像梯度处理 ①梯度运算 ②礼帽与黑帽 ③图像的梯度处理 5.边缘检测 ①Canny边缘检测 1.图像基本操作 ①读取图像 ②显示图像 该函数中,name是显示窗口的名字
-
Python实现数据清洗的示例详解
目录 前言 去掉信息不全的用户 描述 答案 修补缺失的用户数据 描述 答案 解决牛客网用户重复的数据 描述 答案 统一最后刷题日期的格式 描述 答案 将用户的json文件转换为表格形式 描述 答案 前言 Python实际针对数据分析的学习是库,用库来解决一系列的数据分析问题 去掉信息不全的用户 描述 现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔): Nowcoder_ID:用户ID Level:等级 Achievement_value
-
对python周期性定时器的示例详解
一.用thread实现定时器 py_timer.py文件 #!/usr/bin/python #coding:utf-8 import threading import os import sys class _Timer(threading.Thread): def __init__(self, interval, function, args=[], kwargs={}): threading.Thread.__init__(self) self.interval = interval se
-
Python OpenCV形态学运算示例详解
目录 1. 腐蚀 & 膨胀 1.1什么是腐蚀&膨胀 1.2 腐蚀方法 cv2.erode() 1.3 膨胀方法 cv2.dilate() 2. 开运算 & 闭运算 2.1 简述 2.2 开运算 2.3 闭运算 3. morphologyEx()方法 3.1 morphologyEx()方法 介绍 3.2 梯度运算 3.3 顶帽运算 3.4 黑帽运算 1. 腐蚀 & 膨胀 1.1什么是腐蚀&膨胀 腐蚀&膨胀是图像形态学中的两种核心操作 腐蚀可以描述为是让图像沿
-
Vue3中Vuex状态管理学习实战示例详解
目录 引言 一.目录结构 二.版本依赖 三.配置Vuex 四.使用Vuex 引言 Vuex 是 Vue 全家桶重要组成之一,专为 Vue.js 应用程序开发的 状态管理模式 + 库 ,它采用集中式存储管理应用的所有组件的状态,并以相应的规则保证状态以一种可预测的方式发生变化. 一.目录结构 demo/ package.json vite.config.js index.html public/ src/ api/ assets/ common/ components/ store/ index.