group by用法详解
一. 概述
group_by的意思是根据by对数据按照哪个字段进行分组,或者是哪几个字段进行分组。
二. 语法
select 字段 from 表名 where 条件 group by 字段
或者
select 字段 from 表名 group by 字段 having 过滤条件
注意:对于过滤条件,可以先用where,再用group by或者是先用group by,再用having
三. 案例
1 创建表格并插入数据
说明:在plsql developer上创建表格并插入数据,以便下面进行简单字段分组以及多个字段分组,同时还结合聚合函数进行运算。
创建student表
create table student
(id int not null ,
name varchar2(30),
grade varchar2(30),
salary varchar2(30)
)
在student表中插入数据
insert into student values(1,'zhangsan','A',1500);
insert into student values(2,'lisi','B',3000);
insert into student values(1,'zhangsan','A',1500);
insert into student values(4,'qianwu','A',3500);
insert into student values(3,'zhaoliu','C',2000);
insert into student values(1,'huyifei','D',2500);
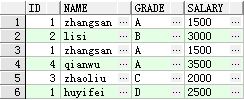
数据插入到student表中的结果
2 单个字段分组
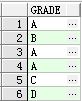
① select grade from student 查出所有学生等级(包括重复的等级)
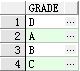
② select grade from student group by grade 查出学生等级的种类(按照等级划分,去除重复的)
3 多个字段分组
select name , sum(salary) from student group by name , grade 按照名字和等级划分,查看相同名字下的工资总和
注意:这里有一点需要说明一下,多个字段进行分组时,需要将name和grade看成一个整体,只要是name和grade相同的可以分成一组;如果只是name相同,grade不同就不是一组。

4 配合聚合函数一起使用
常用的聚合函数:count() , sum() , avg() , max() , min()
count():计数
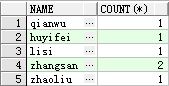
select name , count(*) from student group by name 查看表中相同人名的个数
得出的如下结果
sum():求和
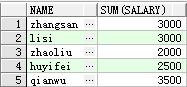
select name , sum(salary) from student group by name 查看表中人员的工资和(同姓的工资相加)
得出的如下结果
avg():平均数
select name , avg(salary) from student group by name , grade 查看表中人员的工资平均数(同姓工资平均数)
得出的如下结果

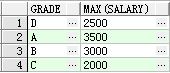
max():最大值
select grade , max(salary) from student group by grade 查看按等级划分人员工资最大值
得出的如下结果
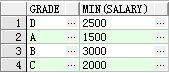
min():最小值
select grade , min(salary) from student group by grade 查看按等级划分人员工资最小值
得出的如下结果
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
MySQL数据库分组查询group by语句详解
一:分组函数的语句顺序 1 SELECT ... 2 FROM ... 3 WHERE ... 4 GROUP BY ... 5 HAVING ... 6 ORDER BY ... 二:WHERE和HAVING筛选条件的区别 数据源 位置 关键字 WHERE 原始表 ORDER BY语句之前 WHERE HAVING 分组后的结果集 ORDER BY语句之后 HAVING 三:举例说明 #1.查询每个班学生的最大年龄 SELECT MAX(age),class FROM STU_CLASS GR
-

浅谈MySQL中的group by
目录 1.前言 2.准备user表 2.1 group by规则 2.2 group by使用 2.3 having使用 2.4 order by与limit 2.5 with rollup 1.前言 MySQL的group by用于对查询的数据进行分组:此外MySQL提供having子句对分组内的数据进行过滤. MySQL提供了许多select子句关键字, 它们在语句中的顺序如下所示: 子句 作用 是否必须/何时使用 select 查询要返回的数据或者表达式 是 from 指定查询的表 否 w
-
Oracle中分组查询group by用法规则详解
Oracle中group by用法 在select 语句中可以使用group by 子句将行划分成较小的组,一旦使用分组后select操作的对象变为各个分组后的数据,使用聚组函数返回的是每一个组的汇总信息. 使用having子句 限制返回的结果集.group by 子句可以将查询结果分组,并返回行的汇总信息Oracle 按照group by 子句中指定的表达式的值分组查询结果. 在带有group by 子句的查询语句中,在select 列表中指定的列要么是group by 子句中指定的列,要么包
-
c#中查询表达式GroupBy的使用方法
说明: c#中实现IEnumerable<T>接口的类提供了很多扩展方法,其中Select,Where等为最常见的,且几乎和Sql语法类似比较好理解,基本满足了日常处理集合的大部分需求,然而还有一部分稍有不一样理解起来比较拗,实际分析一下实现的原理倒也很好理解,本篇文章介绍一下GroupBy的使用方法. 实验基础数据用例: Student类: public class Student { public int StuId { get; set; } public string ClassNam
-
如何在datatable中使用groupby进行分组统计
本文介绍了在datatable中使用groupby进行分组统计,下面是为大家分享的效果图和实现代码: 实现效果 在SQL中我们可以使用groupby来进行分组统计,如果数据在datatable中该如何使用groupby呢,下面的方法可以实现groupby,代码如下: DataTable dt = new DataTable("cart"); DataColumn dc1 = new DataColumn("areaid", Type.GetType("Sy
-
MYSQL GROUP BY用法详解
背景介绍 最近在设计数据库的时候因为开始考虑不周,所以产生了大量的重复数据.现在需要把这些重复的数据删除掉,使用到的语句就是Group By来完成.为了进一步了解这条语句的作用,我打算先从简单入手. 建一个测试表 复制代码 代码如下: create table test_group(id int auto_increment primary key, name varchar(32), class varchar(32), score int); 查看表结构 desc test_group 插入
-
group by用法详解
一. 概述 group_by的意思是根据by对数据按照哪个字段进行分组,或者是哪几个字段进行分组. 二. 语法 select 字段 from 表名 where 条件 group by 字段 或者 select 字段 from 表名 group by 字段 having 过滤条件 注意:对于过滤条件,可以先用where,再用group by或者是先用group by,再用having 三. 案例 1
-
group by用法详解
一. 概述 group_by的意思是根据by对数据按照哪个字段进行分组,或者是哪几个字段进行分组. 二. 语法 select 字段 from 表名 where 条件 group by 字段 或者 select 字段 from 表名 group by 字段 having 过滤条件 注意:对于过滤条件,可以先用where,再用group by或者是先用group by,再用having 三. 案例 1
-
mysql之group by和having用法详解
GROUP BY语法可以根据给定数据列的每个成员对查询结果进行分组统计,最终得到一个分组汇总表. select子句中的列名必须为分组列或列函数,列函数对于group by子句定义的每个组返回一个结果. 某个员工信息表结构和数据如下: id name dept salary edlevel hiredate 1 张三 开发部 2000 3 2009-10-11 2 李四 开发部 2500 3 2009-10-01 3 王五 设计部 2600 5 2010-10-02 4 王六 设计部 2300 4
-
Python正则表达式中group与groups的用法详解
目录 1 .group函数 1.1 返回整个匹配结果 1.2 返回指定分组的匹配结果 1.3 处理没有匹配结果的情况 2. groups函数 3. group和groups的使用场景 在Python中,正则表达式的group和groups方法是非常有用的函数,用于处理匹配结果的分组信息.group方法是re.MatchObject类中的一个函数,用于返回匹配对象的整个匹配结果或特定的分组匹配结果.而groups方法同样是re.MatchObject类中的函数,它返回的是所有分组匹配结果组成的元组
-
Angular 中 select指令用法详解
最近在angular中使用select指令时,出现了很多问题,搞得很郁闷.查看了很多资料后,发现select指令并不简单,决定总结一下. select用法: <select ng-model="" [name=""] [required=""] [ng-required=""] [ng-options=""]> </select> 属性说明: 发现并没有ng-change属性 ng-
-
MySQL两种临时表的用法详解
外部临时表 通过CREATE TEMPORARY TABLE 创建的临时表,这种临时表称为外部临时表.这种临时表只对当前用户可见,当前会话结束的时候,该临时表会自动关闭.这种临时表的命名与非临时表可以同名(同名后非临时表将对当前会话不可见,直到临时表被删除). 内部临时表 内部临时表是一种特殊轻量级的临时表,用来进行性能优化.这种临时表会被MySQL自动创建并用来存储某些操作的中间结果.这些操作可能包括在优化阶段或者执行阶段.这种内部表对用户来说是不可见的,但是通过EXPLAIN或者SHOW S
-
python正则-re的用法详解
天在刷题的时候用到了正则,用的过程中就感觉有点不太熟练了,很久没有用正则都有点忘了.所以现在呢,我们就一起来review一下python中正则模块re的用法吧. 今天是review,所以一些基础的概念就不做介绍了,先来看正则中的修饰符以及它的功能: 修饰符 •re.I 使匹配对大小写不敏感 •re.L 做本地化识别匹配 •re.M 多行匹配,影响^和$ •re.S 使.匹配包括换行在内的所有字符 •re.U 根据Unicode字符集解析字符.这个标志影响\w \W \b \B •re.X 该标志
-
pandas中read_csv、rolling、expanding用法详解
如下所示: import pandas as pd from pandas import DataFrame series = pd.read_csv('daily-min-temperatures.csv',header=0, index_col=0, parse_dates=True,squeeze=True) temps = DataFrame(series.values) width = 3 shifted = temps.shift(width-1) print(shifted) wi
-
Linux常用命令之grep命令用法详解
1.官方简介 grep是linux的常用命令,用于对文件和文本执行重复搜索任务的Unix工具,可以通过grep命令指定特定搜索条件来搜索文件及其内容以获取有用的信息. Usage: grep [OPTION]... PATTERN [FILE]... Search for PATTERN in each FILE or standard input. PATTERN is, by default, a basic regular expression (BRE). Example: grep -