python实现scrapy爬虫每天定时抓取数据的示例代码
1. 前言。
1.1. 需求背景。
- 每天抓取的是同一份商品的数据,用来做趋势分析。
- 要求每天都需要抓一份,也仅限抓取一份数据。
- 但是整个爬取数据的过程在时间上并不确定,受本地网络,代理速度,抓取数据量有关,一般情况下在20小时左右,极少情况下会超过24小时。
1.2. 实现功能。
通过以下三步,保证爬虫能自动隔天抓取数据:
每天凌晨00:01启动监控脚本,监控爬虫的运行状态,一旦爬虫进入空闲状态,启动爬虫。
一旦爬虫执行完毕,自动退出脚本,结束今天的任务。
一旦脚本距离启动时间超过24小时,自动退出脚本,等待第二天的监控脚本启动,重复这三步。
2. 环境。
python 3.6.1
系统:win7
IDE:pycharm
安装过scrapy
3. 设计思路。
3.1. 前提:
目前爬虫是通过scrapy模块自带的cmdline.execute来启动的。
from scrapy import cmdline
cmdline.execute('scrapy crawl mySpider'.split())
3.2. 将自动执行脚本做到scrapy爬虫的外部
(1)每天凌晨00:01启动脚本(控制脚本的存活时间为24小时),监测爬虫的运行状态(需要用一个标记信息来表示爬虫的状态:运行还是停止)。
- 如果爬虫处于运行状态(前一天爬取数据尚未结束),进入第(2)步;
- 如果爬虫处于非运行状态(前一天的爬取任务已完成,今天的尚未开始),进入第(3)步;
(2)脚本进入等待阶段,每隔10分钟,检查一下爬虫的运行状态,如(1)。但是一旦发现,脚本的等待时间超过了24小时,则自动退出脚本,因为第二天的监测脚本已经开始运行了,接替了它的任务。
(3)做一些爬虫启动前的准备工作(删除用来续爬的文件,防止爬虫不运行了),启动爬虫爬取数据,待爬虫正常结束后,退出脚本,完成当天的爬取任务。
4. 准备工作。
4.1. 标记爬虫的运行状态。
通过判断文件是否存在的方式来判断爬虫是否处于运行状态:
- 在爬虫启动时,创建一个isRunning.txt文件。
- 在爬虫结束时,删除这个isRunning.txt文件。
那么isRunning.txt存在,就说明爬虫正在运行;文件不存在,就说明爬虫不在运行。
# 文件pipelines.py
# 爬虫启动时
checkFile = "isRunning.txt"
class myPipeline:
def open_spider(self, spider):
self.client = MongoClient('localhost:27017') # 连接Mongodb
self.db = self.client['mydata'] # 待存储数据的数据库mydata
f = open(checkFile, "w") # 创建一个文件,代表爬虫在运行中
f.close()
# 文件pipelines.py
# 爬虫正常结束时
checkFile = "isRunning.txt"
class myPipeline:
def close_spider(self, spider):
self.client.close()
isFileExsit = os.path.isfile(checkFile)
if isFileExsit:
os.remove(checkFile)
4.2. 爬虫支持续爬,能随时暂停,方便调试。
# 在scrapy项目中添加start.py文件,用于启动爬虫
from scrapy import cmdline
# 在爬虫运行过程中,会自动将状态信息存储在crawls/storeMyRequest目录下,支持续爬
cmdline.execute('scrapy crawl mySpider -s JOBDIR=crawls/storeMyRequest'.split())
# Note:若想支持续爬,在ctrl+c终止爬虫时,只能按一次,爬虫在终止时需要进行善后工作,切勿连续多次按ctrl+c

4.3. Log按照每天的日期命名,方便查看和调试
设置Log等级:
# 文件mySpider.py
class mySpider(CrawlSpider):
name = "mySpider"
allowed_domains = ['http://photo.poco.cn/']
custom_settings = {
'LOG_LEVEL':'INFO', # 减少Log输出量,仅保留必要的信息
# ...... 在爬虫内部用custom_setting可以让这个配置信息仅对这一个爬虫生效
}
以日期为Log文件命名
# 文件settings.py
import datetime
BOT_NAME = 'mySpider'
ROBOTSTXT_OBEY = False
startDate = datetime.datetime.now().strftime('%Y%m%d')
LOG_FILE=f"mySpiderlog{startDate}.txt"
4.4. 为数据按日期存储到不同的表(mongodb的集合)中
# 文件pipelines.py
import datetime
GALANCE=f'galance{datetime.datetime.now().strftime("%Y%m%d")}' # 表名
class myPipeline:
def open_spider(self, spider):
self.client = MongoClient('localhost:27017') # 连接Mongodb
self.db = self.client['mydata'] # 待存储数据的数据库mydata
self.db[GALANCE].insert(dict(item))

4.5. 编写批处理文件启动爬虫
# 文件run.bat cd /d F:/newClawer20170831/mySpider call python main.py pause

5. 实现代码
5.1. 编写python脚本
# 文件timerStartDaily.py
from scrapy import cmdline
import datetime
import time
import shutil
import os
recoderDir = r"crawls" # 这是为了爬虫能够续爬而创建的目录,存储续爬需要的数据
checkFile = "isRunning.txt" # 爬虫是否在运行的标志
startTime = datetime.datetime.now()
print(f"startTime = {startTime}")
i = 0
miniter = 0
while True:
isRunning = os.path.isfile(checkFile)
if not isRunning: # 爬虫不在执行,开始启动爬虫
# 在爬虫启动之前处理一些事情,清掉JOBDIR = crawls
isExsit = os.path.isdir(recoderDir) # 检查JOBDIR目录crawls是否存在
print(f"mySpider not running, ready to start. isExsit:{isExsit}")
if isExsit:
removeRes = shutil.rmtree(recoderDir) # 删除续爬目录crawls及目录下所有文件
print(f"At time:{datetime.datetime.now()}, delete res:{removeRes}")
else:
print(f"At time:{datetime.datetime.now()}, Dir:{recoderDir} is not exsit.")
time.sleep(20)
clawerTime = datetime.datetime.now()
waitTime = clawerTime - startTime
print(f"At time:{clawerTime}, start clawer: mySpider !!!, waitTime:{waitTime}")
cmdline.execute('scrapy crawl mySpider -s JOBDIR=crawls/storeMyRequest'.split())
break #爬虫结束之后,退出脚本
else:
print(f"At time:{datetime.datetime.now()}, mySpider is running, sleep to wait.")
i += 1
time.sleep(600) # 每10分钟检查一次
miniter += 10
if miniter >= 1440: # 等待满24小时,自动退出监控脚本
break
5.2. 编写bat批处理文件
# 文件runTimerRunDaily.bat cd /d F:/newClawer20170831/mySpider call python timerStartDaily.py pause
6. 部署。
6.1. 添加计划任务。
参考以下这篇博客部署windows计划任务:
https://www.jb51.net/article/204879.htm
有关windows计划任务相关设置的详细说明如下:
https://technet.microsoft.com/zh-cn/library/cc722178.aspx
6.2. 注意事项。
(1)在添加计划任务时,要按照如下图进行勾选(只在用户登录时运行),才能弹出下面的cmd任务界面,方便观察和调试。

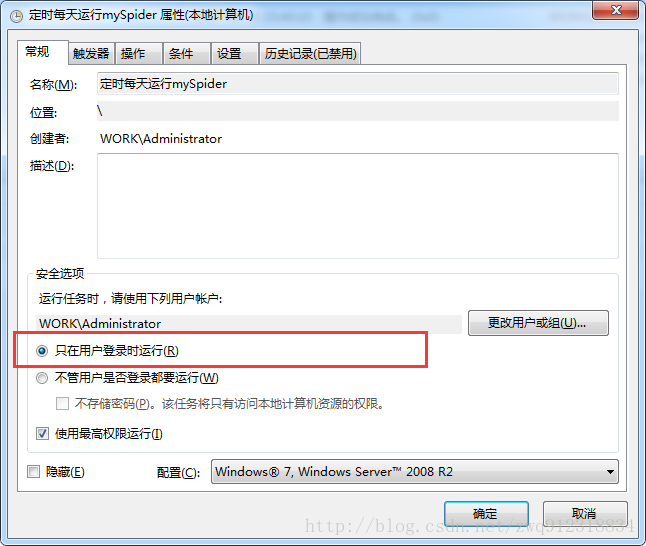
(2)由于爬虫运行时间很长,如果按照默认设置,在凌晨运行实例时,上一次启动尚未结束,会导致这次启动失败,所以要更改默认设置为(如果此任务已经运行:并行运行新实例。保护机制在于每个启动脚本在等待24小时候会自动退出,来保证不会重复启动)。

(3)如果想支持续传,只能按一次 ctrl + c 来停止爬虫运行。因为终止爬虫时,爬虫需要做一些善后工作,如果连续按多次ctrl + c来停止爬虫,爬虫将来不及善后,会导致无法续爬。 6.3. 效果展示。
正常执行完成:

正在执行中:

到此这篇关于python实现scrapy爬虫每天定时抓取数据的示例代码的文章就介绍到这了,更多相关python scrapy定时抓取内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python中用Scrapy实现定时爬虫的实例讲解
一般网站发布信息会在具体实现范围内发布,我们在进行网络爬虫的过程中,可以通过设置定时爬虫,定时的爬取网站的内容.使用python爬虫框架Scrapy框架可以实现定时爬虫,而且可以根据我们的时间需求,方便的修改定时的时间. 1.Scrapy介绍 Scrapy是python的爬虫框架,用于抓取web站点并从页面中提取结构化的数据.任何人都可以根据需求方便的修改.Scrapy用途广泛,可以用于数据挖掘.监测和自动化测试. 2.使用Scrapy框架定时爬取 import time from scrapy
-
浅析python实现scrapy定时执行爬虫
项目需要程序能够放在超算中心定时运行,于是针对scrapy写了一个定时爬虫的程序main.py ,直接放在scrapy的存储代码的目录中就能设定时间定时多次执行. 最简单的方法:直接使用Timer类 import time import os while True: os.system("scrapy crawl News") time.sleep(86400) #每隔一天运行一次 24*60*60=86400s或者,使用标准库的sched模块 import sched #初始化sch
-

python实现scrapy爬虫每天定时抓取数据的示例代码
1. 前言. 1.1. 需求背景. 每天抓取的是同一份商品的数据,用来做趋势分析. 要求每天都需要抓一份,也仅限抓取一份数据. 但是整个爬取数据的过程在时间上并不确定,受本地网络,代理速度,抓取数据量有关,一般情况下在20小时左右,极少情况下会超过24小时. 1.2. 实现功能. 通过以下三步,保证爬虫能自动隔天抓取数据: 每天凌晨00:01启动监控脚本,监控爬虫的运行状态,一旦爬虫进入空闲状态,启动爬虫. 一旦爬虫执行完毕,自动退出脚本,结束今天的任务. 一旦脚本距离启动时间超过24小时,自动
-
python爬虫构建代理ip池抓取数据库的示例代码
爬虫的小伙伴,肯定经常遇到ip被封的情况,而现在网络上的代理ip免费的已经很难找了,那么现在就用python的requests库从爬取代理ip,创建一个ip代理池,以备使用. 本代码包括ip的爬取,检测是否可用,可用保存,通过函数get_proxies可以获得ip,如:{'HTTPS': '106.12.7.54:8118'} 下面放上源代码,并详细注释: import requests from lxml import etree from requests.packages import u
-
PHP使用Curl实现模拟登录及抓取数据功能示例
本文实例讲述了PHP使用Curl实现模拟登录及抓取数据功能.分享给大家供大家参考,具体如下: 使用PHP的Curl扩展库可以模拟实现登录,并抓取一些需要用户账号登录以后才能查看的数据.具体实现的流程如下(个人总结): 1. 首先需要对相应的登录页面的html源代码进行分析,获得一些必要的信息: (1)登录页面的地址: (2)验证码的地址: (3)登录表单需要提交的各个字段的名称和提交方式: (4)登录表单提交的地址: (5)另外要需要知道要抓取的数据所在的地址. 2. 获取cookie并存储(针
-
python数据抓取分析的示例代码(python + mongodb)
本文介绍了Python数据抓取分析,分享给大家,具体如下: 编程模块:requests,lxml,pymongo,time,BeautifulSoup 首先获取所有产品的分类网址: def step(): try: headers = { ..... } r = requests.get(url,headers,timeout=30) html = r.content soup = BeautifulSoup(html,"lxml") url = soup.find_all(正则表达式
-
scrapy与selenium结合爬取数据(爬取动态网站)的示例代码
scrapy框架只能爬取静态网站.如需爬取动态网站,需要结合着selenium进行js的渲染,才能获取到动态加载的数据. 如何通过selenium请求url,而不再通过下载器Downloader去请求这个url? 方法:在request对象通过中间件的时候,在中间件内部开始使用selenium去请求url,并且会得到url对应的源码,然后再将 源 代码通过response对象返回,直接交给process_response()进行处理,再交给引擎.过程中相当于后续中间件的process_req
-
Python爬虫框架Scrapy实战之批量抓取招聘信息
网络爬虫抓取特定网站网页的html数据,但是一个网站有上千上万条数据,我们不可能知道网站网页的url地址,所以,要有个技巧去抓取网站的所有html页面.Scrapy是纯Python实现的爬虫框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便- Scrapy 使用wisted这个异步网络库来处理网络通讯,架构清晰,并且包含了各种中间件接口,可以灵活的完成各种需求.整体架构如下图所示: 绿线是数据流向,首先从初始URL 开始,Scheduler 会将其
-
python制作爬虫并将抓取结果保存到excel中
学习Python也有一段时间了,各种理论知识大体上也算略知一二了,今天就进入实战演练:通过Python来编写一个拉勾网薪资调查的小爬虫. 第一步:分析网站的请求过程 我们在查看拉勾网上的招聘信息的时候,搜索Python,或者是PHP等等的岗位信息,其实是向服务器发出相应请求,由服务器动态的响应请求,将我们所需要的内容通过浏览器解析,呈现在我们的面前. 可以看到我们发出的请求当中,FormData中的kd参数,就代表着向服务器请求关键词为Python的招聘信息. 分析比较复杂的页面请求与响应信息,
-
Python使用Scrapy爬虫框架全站爬取图片并保存本地的实现代码
大家可以在Github上clone全部源码. Github:https://github.com/williamzxl/Scrapy_CrawlMeiziTu Scrapy官方文档:http://scrapy-chs.readthedocs.io/zh_CN/latest/index.html 基本上按照文档的流程走一遍就基本会用了. Step1: 在开始爬取之前,必须创建一个新的Scrapy项目. 进入打算存储代码的目录中,运行下列命令: scrapy startproject CrawlMe
-
Python 利用scrapy爬虫通过短短50行代码下载整站短视频
近日,有朋友向我求助一件小事儿,他在一个短视频app上看到一个好玩儿的段子,想下载下来,可死活找不到下载的方法.这忙我得帮,少不得就抓包分析了一下这个app,找到了视频的下载链接,帮他解决了这个小问题. 因为这个事儿,勾起了我另一个念头,这不最近一直想把python爬虫方面的知识梳理梳理吗,干脆借机行事,正凑着短视频火热的势头,做一个短视频的爬虫好了,中间用到什么知识就理一理. 我喜欢把事情说得很直白,如果恰好有初入门的朋友想了解爬虫的技术,可以将就看看,或许对你的认识会有提升.如果有高手路过,
-
详解Python之Scrapy爬虫教程NBA球员数据存放到Mysql数据库
获取要爬取的URL 爬虫前期工作 用Pycharm打开项目开始写爬虫文件 字段文件items # Define here the models for your scraped items # # See documentation in: # https://docs.scrapy.org/en/latest/topics/items.html import scrapy class NbaprojectItem(scrapy.Item): # define the fields for yo