Pandas的数据过滤实现
作者|Amanda Iglesias Moreno 编译|VK 来源|Towards Datas Science
从数据帧中过滤数据是清理数据时最常见的操作之一。Pandas提供了一系列根据行和列的位置和标签选择数据的方法。此外,Pandas还允许你根据列类型获取数据子集,并使用布尔索引筛选行。
在本文中,我们将介绍从Pandas数据框中选择数据子集的最常见操作:
- 按标签选择单列
- 按标签选择多列
- 按数据类型选择列
- 按标签选择一行
- 按标签选择多行
- 按位置选择一行
- 按位置选择多行
- 同时选择行和列
- 选择标量值
- 使用布尔选择选择选择行
数据集
在本文中,我们使用一个小数据集进行学习。在现实世界中,所使用的数据集要大得多;然而,用于过滤数据的过程保持不变。
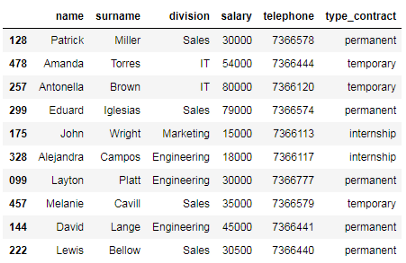
数据框包含公司10名员工的信息:(1)身份证,(2)姓名,(3)姓氏,(4)部门,(5)电话,(6)工资,(7)合同类型。
import pandas as pd
# 员工的信息
id_number = ['128', '478', '257', '299', '175', '328', '099', '457', '144', '222']
name = ['Patrick', 'Amanda', 'Antonella', 'Eduard', 'John', 'Alejandra', 'Layton', 'Melanie', 'David', 'Lewis']
surname = ['Miller', 'Torres', 'Brown', 'Iglesias', 'Wright', 'Campos', 'Platt', 'Cavill', 'Lange', 'Bellow']
division = ['Sales', 'IT', 'IT', 'Sales', 'Marketing', 'Engineering', 'Engineering', 'Sales', 'Engineering', 'Sales']
salary = [30000, 54000, 80000, 79000, 15000, 18000, 30000, 35000, 45000, 30500]
telephone = ['7366578', '7366444', '7366120', '7366574', '7366113', '7366117', '7366777', '7366579', '7366441', '7366440']
type_contract = ['permanent', 'temporary', 'temporary', 'permanent', 'internship', 'internship', 'permanent', 'temporary', 'permanent', 'permanent']
# 包含员工信息的dataframe
df_employees = pd.DataFrame({'name': name, 'surname': surname, 'division': division,
'salary': salary, 'telephone': telephone, 'type_contract': type_contract}, index=id_number)
df_employees
1.按标签选择单列
要在Pandas中选择一个列,我们可以使用.运算符和[]运算符。
按标签选择单列
df[string]
下面的代码使用这两种方法访问salary列。
# 使用.符号选择列(salary) salary = df_employees.salary # 使用方括号选择列(salary) salary_2 = df_employees['salary'] # 当选择单个列时,我们获得一个Series对象 print(type(salary)) # <class 'pandas.core.series.Series'> print(type(salary_2)) # <class 'pandas.core.series.Series'> salary
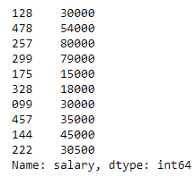
如上所示,当检索单个列时,结果是一个Series对象。为了在只选择一列时获得一个DataFrame对象,我们需要传入一个列表,而不仅仅是一个字符串。
# 通过向索引操作符传递一个字符串来获取一个Series对象 df_employees['salary'] # 通过将带有单个项的列表传递给索引操作符来获取DataFrame对象 df_employees[['salary']]

此外,重要的是要记住,当列名包含空格时,我们不能使用.表示法来访问数据帧的特定列。如果我们这么做了,就会产生一个语法错误。
2.按标签选择多列
我们可以通过传入一个列名称如下的列表来选择一个数据帧的多个列。
按标签选择多列
df[list_of_strings]
# 通过将包含列名的列表传递给索引操作符来选择多个列 df_employees[['division', 'salary']]
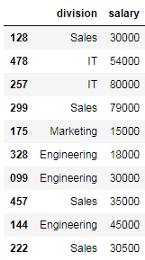
如上所示,结果是一个DataFrame对象,只包含列表中提供的列。
3.按数据类型选择列
我们可以使用pandas.DataFrame.select类型(include=None,exclude=None)根据列的数据类型选择列。该方法接受参数include和exclude中的列表或单个数据类型。
请记住,必须至少提供其中一个参数(include或exclude),并且它们不能包含重叠的元素。
按数据类型选择列
df.select_dtypes(include=None, exclude=None)
在下面的示例中,我们通过传入np.number对象添加到include参数。或者,我们可以通过提供字符串'number'作为输入来获得相同的结果。
可以看到,select_dtypes()方法返回一个DataFrame对象,该对象包括include参数中的数据类型,而排除exclude参数中的数据类型。
import numpy as np # 选择数值列- numpy对象 numeric_inputs = df_employees.select_dtypes(include=np.number) # 使用.columns属性 numeric_inputs.columns # Index(['salary'], dtype='object') # 该方法返回一个DataFrame对象 print(type(numeric_inputs)) # <class 'pandas.core.frame.DataFrame'> # 选择数字列 numeric_inputs_2 = df_employees.select_dtypes(include='number') # 使用.columns属性 numeric_inputs_2.columns # Index(['salary'], dtype='object') # 该方法返回一个DataFrame对象 print(type(numeric_inputs_2)) # <class 'pandas.core.frame.DataFrame'> # 可视化数据框 numeric_inputs

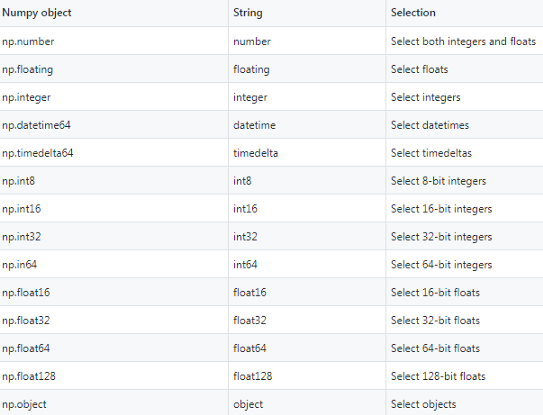
如前所述,select_dtypes()方法可以同时接受字符串和numpy对象作为输入。下表显示了在Pandas中引用数据类型的最常用方法。
作为提醒,我们可以使用pandas.DataFrame.info方法或使用pandas.DataFrame.dtypes属性。前者打印数据帧的简明摘要,包括列名及其数据类型,而后者返回一个包含每个列的数据类型的序列。
# 数据框架的简要摘要,包括列名及其数据类型 df_employees.info()
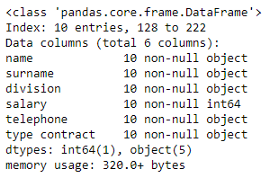
# 检查列的数据类型 df_employees.dtypes
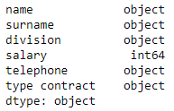
4.按标签选择单行
数据帧和序列不一定有数字索引。默认情况下,索引是表示行位置的整数;但是,它也可以是字母数字字符串。在我们当前的示例中,索引是员工的id号。
# 我们可以使用.index方法检查数据帧的索引 df_employees.index # Index(['128', '478', '257', '299', '175', '328', '099', '457', '144', '222'], dtype='object') # 索引是雇员的id号。
要按id号选择一行,我们可以使用.loc[]索引器提供一个字符串(索引名)作为输入。
按标签选择单行
df.loc[string]
下面的代码显示如何选择id号为478的员工。
# 使用.loc[]索引器选择id号为478的员工 df_employees.loc['478']

如上所示,当选中一行时,.loc[]索引器将返回一个Series对象。但是,我们也可以通过将单个元素列表传递给.loc[]方法来获得单行数据帧,如下所示。
# 使用.loc[]索引器选择id号为478的雇员,并提供一个单元素列表 df_employees.loc[['478']]

5.按标签选择多行
我们可以使用.loc[]索引器选择多行。除单个标签外,索引器还接受一个列表或标签片段作为输入。
按标签选择多行
df.loc[list_of_strings] df.loc[slice_of_strings]
接下来,我们获得包含id号为478和222的雇员的数据帧的子集,如下所示。
# 使用.loc[]索引器选择id号为478和222的员工 df_employees.loc[['478', '222']]
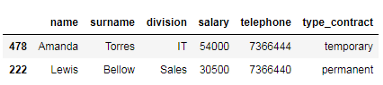
请注意,始终包含.loc[]方法的结束索引,这意味着所选内容包括最后一个标签。
6.按位置选择单行
iloc[]索引器用于按位置索引数据帧。要使用.iloc[]属性选择单行,我们将行位置(单个整数)传递给索引器。
按位置选择单行
df.iloc[integer]
在下面的代码块中,我们选择索引为0的行。在这种情况下,返回数据帧的第一行,因为在Pandas中索引从0开始。
# 选择数据帧的第一行 df_employees.iloc[0]

此外,.iloc[]索引器还支持负整数(从-1开始)作为相对于数据帧末尾的相对位置。
# 选择数据帧的最后一行 df_employees.iloc[-1]
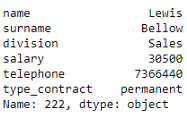
如上所示,当选择一行时,.iloc[]索引器返回一个以列名作为索引的Series对象。但是,正如我们对.loc[]索引器所做的那样,我们还可以通过以下方式将单个整数列表传递给索引器来获取数据帧。
# 选择数据帧的最后一行 df_employees.iloc[[-1]]

最后,请记住,在尝试访问超出边界的索引时会引发索引器错误。
# 数据框的形状- 10行6列 df_employees.shape # (10, 6) # 当试图访问一个越界的索引时,会引发一个IndexError df_employees.iloc[10] # IndexError
7.通过多个位置选择
为了按位置提取多行,我们将list或slice对象传递给.iloc[]索引器。
按位置选择多行
df.iloc[list_of_integers] df.iloc[slice_of_integers]
下面的代码块演示如何使用整数列表选择数据帧的前五行。
# 使用列表选择dataframe的前5行 df_employees.iloc[[0, 1, 2, 3, 4]]v
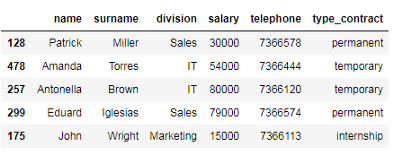
或者,我们可以使用切片表示法得到相同的结果。
# 使用切片选择dataframe的前5行 df_employees.iloc[0:5]
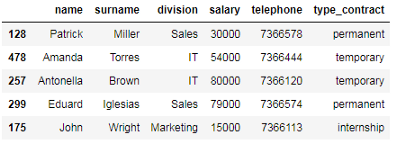
如上所示,Python切片规则(半开区间)适用于.iloc[]属性,这意味着包含第一个索引,但不包括结束索引。
8.同时选择行和列
到目前为止,我们已经学习了如何使用.loc[]和.iloc[]索引器按标签或位置选择数据帧中的行。但是,这两个索引器不仅能够同时选择行,还可以同时选择行和列。
为此,我们必须提供用逗号分隔的行和列标签/位置,如下所示:
同时选择行和列
df.loc[row_labels, column_labels] df.iloc[row_positions, column_positions]
其中行标签和列标签可以是单个字符串、字符串列表或字符串片段。同样,行位置和列位置可以是单个整数、整数列表或整数切片。
下面的示例演示如何使用.loc[]和.iloc[]索引器同时提取行和列。
选择标量值
我们选择id为478的员工的工资,方法如下。
# 按位置选择身份证号为478的员工的工资 df_employees.iloc[1, 3] # 根据标签选择id号为478的员工的工资 df_employees.loc['478', 'salary'] # 54000
在本例中,两个索引器的输出都是整数。
选择单行和多列
我们选择id号为478的员工的姓名、姓氏和薪水,方法是将一个值作为第一个参数,将一个值列表作为第二个参数,从而获得一个Series对象。
# 按职位选择身份证号为478的员工的姓名、姓氏和工资 df_employees.iloc[1, [0, 1, 3]] # 通过标签选择身份证号为478的员工的姓名、姓氏和工资 df_employees.loc['478', ['name', 'surname', 'salary']]

选择不相交的行和列
要选择多行和多列,我们需要向两个索引器传递两个值列表。下面的代码显示如何提取id号为478和222的员工的姓名、姓氏和工资。
# 按职位选择身份证号为478和222的员工的姓名、姓氏和工资 df_employees.iloc[[1, 9], [0, 1, 3]] # 根据标签选择身份证号为478和222的员工的姓名、姓氏和工资 df_employees.loc[['478', '222'], ['name', 'surname', 'salary']]
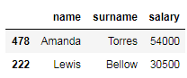
与以前不同,这两个索引器的输出都是一个DataFrame对象。
选择连续的行和列
我们可以使用切片表示法提取数据帧的连续行和列。下面的代码片段显示如何选择id号为128、478、257和299的员工的姓名、姓氏和薪水。
# 按职位选择id号为128、478、257、299的员工的姓名、姓氏和工资 df_employees.iloc[:4, [0, 1, 3]] # 按标签选择id号为128、478、257、299的员工的姓名、姓氏和工资 df_employees.loc[:'299', ['name', 'surname', 'salary']]
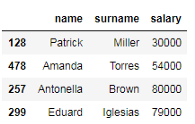
如上所示,我们只使用切片表示法来提取数据帧的行,因为我们要选择的id号是连续的(索引从0到3)。
一定要记住.loc[]索引器使用一个闭合的间隔,同时提取开始标签和停止标签。相反,.iloc[]索引器使用半开区间,因此不包括停止索引处的值。
9.使用.at[]和.iat[]索引器选择标量值
如上所述,我们可以通过将两个用逗号分隔的字符串/整数传递给.loc[]和.iloc[]索引器来选择标量值。此外,Pandas还提供了两个优化函数来从数据帧对象中提取标量值:.at[]和.iat[]运算符。前者通过标签提取单个值,而后者通过位置访问单个值。
通过标签和位置选择标量值
df.at[string, string] df.iat[integer, integer]
下面的代码显示如何使用.at[]和.iat[]索引器按标签和位置选择id号为478的员工的工资。
# 按位置选择身份证号为478的员工的工资 df_employees.iat[1, 3] # 根据标签选择id号为478的员工的工资 df_employees.at['478', 'salary'] # 54000
我们可以使用%timeit magic函数来计算这两个Python语句的执行时间。如下所示,.at[]和.iat[]运算符比.loc[]和.iloc[]索引器快得多。
# loc索引器的执行时间 %timeit df_employees.loc['478', 'salary'] # at索引器的执行时间 %timeit df_employees.at['478', 'salary']

# iloc索引器的执行时间 %timeit df_employees.iloc[1, 3] # iat索引器的执行时间 %timeit df_employees.iat[1, 3]

最后,必须记住,.at[]和.iat[]索引器只能用于访问单个值,在尝试选择数据帧的多个元素时会引发类型错误。
# 当尝试选择多个元素时,会引发异常 df_employees.at['478', ['name', 'surname', 'salary']] # TypeError
10.使用布尔选择行
到目前为止,我们已经根据标签和位置过滤了数据帧中的行和列。或者,我们也可以用布尔索引在Pandas中选择一个子集。布尔选择包括通过为每一行提供布尔值(True或False)来选择数据帧的行。
在大多数情况下,这个布尔数组是通过将一个条件应用于一个或多个列的值来计算的,该条件的计算结果为True或False,具体取决于这些值是否满足条件。但是,也可以使用其他序列、Numpy数组、列表或Pandas系列手动创建布尔数组。
然后,布尔值序列放在方括号[]内,返回与真值相关联的行。
使用布尔选择选择选择行
df[sequence_of_booleans]
根据单列值的布尔选择
根据单列值过滤数据帧的最常见方法是使用比较运算符。
比较运算符计算两个操作数(A和b)之间的关系,并根据是否满足条件返回True或False。下表包含Python中可用的比较运算符。
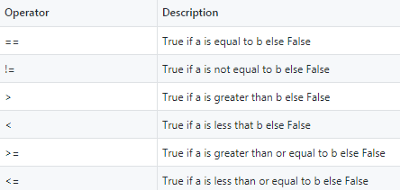
这些比较运算符可用于数据帧的单列,以获得布尔值序列。例如,我们使用大于运算符确定员工的工资是否大于45000,如下所示。
# 工资超过45000的员工 df_employees['salary'] > 45000 1
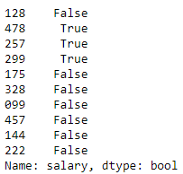
输出是一系列布尔函数,其中工资高于45000为真,低于或等于45000为假。正如你可能注意到的那样,boolean系列具有与原始数据帧相同的索引(id编号)。
可以将此序列传递给索引运算符[],以仅返回结果为True的行。
# 选择工资高于45000的员工 df_employees[df_employees['salary'] > 45000]
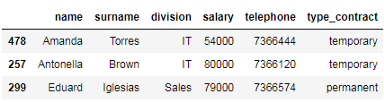
如上所示,我们获得了一个数据帧对象,其中只包含工资高于45000的员工。
根据多列值的布尔选择
之前,我们已经根据一个条件过滤了一个数据帧。但是,我们也可以使用逻辑运算符将多个布尔表达式组合在一起。
在Python中,有三个逻辑运算符:and、or和not。但是,这些关键字在Pandas中不可用于组合多个布尔条件。而是使用以下运算符。

下面的代码展示了如何选择薪水高于45000的员工,以及有一份永久合同,其中包含两个布尔表达式和逻辑运算符&。
# 选择工资高于45000并有长期合同的员工 df_employees[(df_employees['salary'] > 45000) & (df_employees['type_contract'] == 'permanent')]

如你所知,在Python中,比较运算符的优先级高于逻辑运算符。但是,它不适用于逻辑运算符优先于比较运算符的panda。因此,我们需要将每个布尔表达式包装在括号中以避免错误。
使用Pandas方法的布尔选择
Pandas提供了一系列返回布尔值序列的内置函数,它是结合比较运算符和逻辑运算符的更复杂布尔表达式的一个有吸引力的替代方案。
isin方法
这个pandas.Series.isin方法接受一系列值,并在序列中与列表中的值匹配的位置返回True。
此方法允许我们检查列中是否存在一个或多个元素,而无需使用逻辑运算符或。下面的代码显示如何使用逻辑运算符or和isin方法选择具有永久或临时合同的员工。
# 使用逻辑操作符或选择具有永久或临时合同的员工 df_employees[(df_employees['type_contract'] == 'temporary') | (df_employees['type_contract'] == 'permanent')] # 使用isin方法选择有永久或临时合同的员工 df_employees[df_employees['type_contract'].isin(['temporary', 'permanent'])]
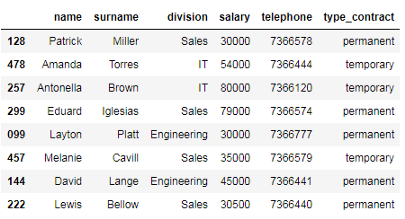
如你所见,isin方法在检查同一列中的多个或条件时非常方便。另外,它更快!
# 使用逻辑运算符|执行时间 %timeit df_employees[(df_employees['type_contract'] == 'temporary') | (df_employees['type_contract'] == 'permanent')] # isin方法的执行时间 %timeit df_employees[df_employees['type_contract'].isin(['temporary', 'permanent'])]

between方法
这个熊猫系列方法接受两个用逗号分隔的标量,它们表示一个值范围的上下边界,并在该范围内的位置返回True。
以下代码选择工资高于或等于30000且小于或等于80000的员工。
# 薪资高于或等于30000,低于或等于80000的员工 df_employees[df_employees['salary'].between(30000, 80000)]
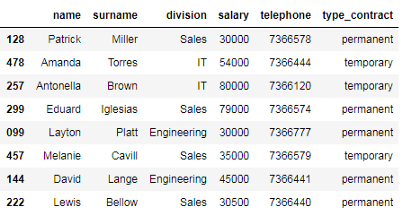
如你所见,这两个边界(30000和80000)都包括在内。要排除它们,我们必须按以下方式传递inclusive=False参数。
# 薪资在3万以上,8万以下的员工 df_employees[df_employees['salary'].between(30000, 80000, inclusive=False)]
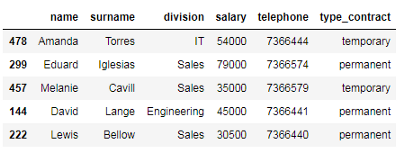
正如你可能注意到的,上面的代码相当于编写两个布尔表达式,并使用逻辑运算符and对它们求值。
# 薪资高于或等于30000,低于或等于80000的员工 df_employees[(df_employees['salary']>=30000) & (df_employees['salary']<=80000)]
字符串方法
此外,我们还可以将布尔索引与字符串方法一起使用,只要它们返回布尔值序列。
例如pandas.Series.str.contains方法检查列的所有元素中是否存在子字符串,并返回一系列布尔值,我们可以将这些布尔值传递给索引运算符以筛选数据帧。
下面的代码显示如何选择包含57的所有电话号码。
# 选择所有包含57的电话号码
df_employees[df_employees['telephone'].str.contains('57')]
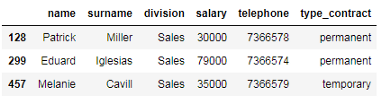
当contains方法计算子字符串是否包含在序列的每个元素中。pandas.Series.str.startswith函数检查字符串开头是否存在子字符串。同样地pandas.Series.str.endswith测试字符串末尾是否存在子字符串。
以下代码显示如何选择姓名以“A”开头的员工。
# 选择名字以“A”开头的员工
df_employees[df_employees['name'].str.startswith('A')]

摘要
在本文中,我们学习从Dataframe中选择子集。此外,我们还提供了多个使用示例。现在!现在是时候在清理你自己的数据时应用这些技术了!
到此这篇关于Pandas的数据过滤实现的文章就介绍到这了,更多相关Pandas 数据过滤内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
详解pandas如何去掉、过滤数据集中的某些值或者某些行?
摘要在进行数据分析与清理中,我们可能常常需要在数据集中去掉某些异常值.具体来说,看看下面的例子. 0.导入我们需要使用的包 import pandas as pd pandas是很常用的数据分析,数据处理的包.anaconda已经有这个包了,纯净版python的可以自行pip安装. 1.去掉某些具体值 数据集df中,对于属性appPlatform(最后一列),我们想删除掉取值为2的那些样本.如何做?非常简单. import pandas as pd df[(True-df['appPlatfor
-
Python学习笔记之pandas索引列、过滤、分组、求和功能示例
本文实例讲述了Python学习笔记之pandas索引列.过滤.分组.求和功能.分享给大家供大家参考,具体如下: 解析html内容,保存为csv文件 //www.jb51.net/article/162401.htm 前面我们已经把519961(基金编码)这种基金的历史净值明细表html内容抓取到了本地,现在我们还是需要 解析html,取出相关的值,然后保存为csv文件以便pandas来统计分析. from bs4 import BeautifulSoup import os import csv
-
Pandas过滤dataframe中包含特定字符串的数据方法
假如有一列全是字符串的dataframe,希望提取包含特定字符的所有数据,该如何提取呢? 因为之前尝试使用filter,发现行不通,最终找到这个行得通的方法. 举例说明: 我希望提取所有包含'Mr.'的人名 1.首先将他们进行字符串化,并得到其对应的布尔值: >>> bool = df.str.contains('Mr\.') #不要忘记正则表达式的写法,'.'在里面要用'\.'表示 >>> print('bool : \n', bool) 2.通过dataframe的
-

Pandas的数据过滤实现
作者|Amanda Iglesias Moreno 编译|VK 来源|Towards Datas Science 从数据帧中过滤数据是清理数据时最常见的操作之一.Pandas提供了一系列根据行和列的位置和标签选择数据的方法.此外,Pandas还允许你根据列类型获取数据子集,并使用布尔索引筛选行. 在本文中,我们将介绍从Pandas数据框中选择数据子集的最常见操作: 按标签选择单列 按标签选择多列 按数据类型选择列 按标签选择一行 按标签选择多行 按位置选择一行 按位置选择多行 同时选择行和列 选
-
对pandas进行数据预处理的实例讲解
参加kaggle数据挖掘比赛,就第一个赛题Titanic的数据,学习相关数据预处理以及模型建立,本博客关注基于pandas进行数据预处理过程.包括数据统计.数据离散化.数据关联性分析 引入包和加载数据 import pandas as pd import numpy as np train_df =pd.read_csv('../datas/train.csv') # train set test_df = pd.read_csv('../datas/test.csv') # test set
-
pandas实现数据读取&清洗&分析的项目实践
目录 一.数据读取和写入 1.1 CSV和txt文件: 1.2 Excel文件: 1.3 MYSQL数据库: 二.数据清洗 2.1 清除不需要的行数据 2.2 清除不需要的列 2.3 调整列的展示顺序或列标签名 2.4 对行数据进行排序 2.5 空值的处理 2.6 数据去重处理 2.7 对指定列数据进行初步加工 2.8 对DataFrame内所有数据进行初步加工处理 2.9 设置数据格式 三.数据切片和筛选查询 3.1 行切片 3.2 列切片 3.3 数据筛选和查询 3.4 遍历 四.数据简单统
-
Bootstrap + AngularJS 实现简单的数据过滤字符查找功能
具体代码如下所示: find.html <!DOCTYPE html> <html ng-app="find"> <head> <title>字符查找</title> <meta charset="utf-8"/> <script src="../Script/angular.min.js" type="text/javascript">&l
-
Python数据分析之如何利用pandas查询数据示例代码
前言 在数据分析领域,最热门的莫过于Python和R语言,本文将详细给大家介绍关于Python利用pandas查询数据的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧. 示例代码 这里的查询数据相当于R语言里的subset功能,可以通过布尔索引有针对的选取原数据的子集.指定行.指定列等.我们先导入一个student数据集: student = pd.io.parsers.read_csv('C:\\Users\\admin\\Desktop\\student.csv')
-
PHP数据过滤的方法
在指南的开始,我们说过数据过滤在任何语言.任何平台上都是WEB应用安全的基石.这包含检验输入到应用的数据以及从应用输出的数据,而一个好的软件设计可以帮助开发人员做到:确保数据过滤无法被绕过,确保不合法的信息不会影响合法的信息,并且识别数据的来源.关于如何确保数据过滤无法被绕过有各种各样的观点,而其中的两种观点比其他更加通用并可提供更高级别的保障.调度方法这种方法是用一个单一的 php 脚本调度(通过 URL).其他任何操作在必要的时候使用include或require包含进来.这种方法一般需要每
-
MYSQL必知必会读书笔记第七章之数据过滤
mysql简介 MySQL是一种开放源代码的关系型数据库管理系统(RDBMS),MySQL数据库系统使用最常用的数据库管理语言--结构化查询语言(SQL)进行数据库管理. 计算次序: where 可以包含任意数目的and和or,允许两者结合以进行复杂和高级的过滤.但是SQL在操作or之前会优先的处理AND操作符.如果想优先的使用or的条件可以使用括号. in:为什么要使用in操作符?其优点具体如下. 1.在使用长的合法选项清单时,in操作符的语法更清楚直观 2.在使用IN时,计算的次序更容易管理
-
php 参数过滤、数据过滤详解
下面通过一段代码给大家介绍php参数过滤 class mysafe{ public $logname; public $isshwomsg; function __construct(){ set_error_handler('MyError',E_ALL); //----- } function MyError($errno, $errstr, $errfile, $errline){ echo "<b>Error number:</b> [$errno],error
-
pandas DataFrame数据转为list的方法
首先使用np.array()函数把DataFrame转化为np.ndarray(),再利用tolist()函数把np.ndarray()转为list,示例代码如下: # -*- coding:utf-8-*- import numpy as np import pandas as pd data_x = pd.read_csv("E:/Tianchi/result/features.csv",usecols=[2,3,4])#pd.dataframe data_y = pd.read_
-
vue实现前台列表数据过滤搜索、分页效果
本文实例为大家分享了vue实现列表数据过滤搜索.分页效果的具体代码,供大家参考,具体内容如下 job.vue页面 <style lang="scss"> .job-wrapper { padding-top: 50px; } .job-left { float: left; margin-right: 20px; padding: 20px; width: 310px; background: #fff; } .job-serach-title { margin: 8px