实操Python爬取觅知网素材图片示例
目录
- 【一、项目背景】
- 【二、项目目标】
- 【三、涉及的库和网站】
- 【四、项目分析】
- 【五、项目实施】
- 【六、效果展示】
- 【七、总结】
【一、项目背景】
在素材网想找到合适图片需要一页一页往下翻,现在学会python就可以用程序把所有图片保存下来,慢慢挑选合适的图片。
【二、项目目标】
1、根据给定的网址获取网页源代码。
2、利用正则表达式把源代码中的图片地址过滤出来。
3、过滤出来的图片地址下载素材图片。
【三、涉及的库和网站】
1、网址如下:
2、涉及的库:requests、lxml
【四、项目分析】
首先需要解决如何对下一页的网址进行请求的问题。可以点击下一页的按钮,观察到网站的变化分别如下所示:
https://www.51miz.com/so-sucai/1789243.html https://www.51miz.com/so-sucai/1789243/p_2/ https://www.51miz.com/so-sucai/1789243/p_3/
我们可以发现图片页数是1789243/p{},p{}花括号数字表示图片哪一页。
【五、项目实施】
1、打开觅知网,在搜索中输入你想要的图片素材(以鼠年素材图片为例)。
2、根据上一步对网址的分析,首先我们定义一个类叫做ImageSpider,类里面定义初始化函数、发送请求获取响应数据函数、解析函数、主函数。首先初始化函数,准备url地址和headers,代码如下图所示。

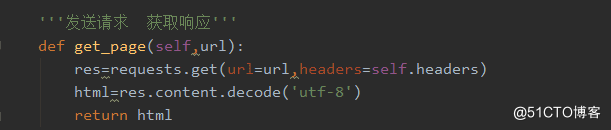
3、发送请求获取响应数据函数。
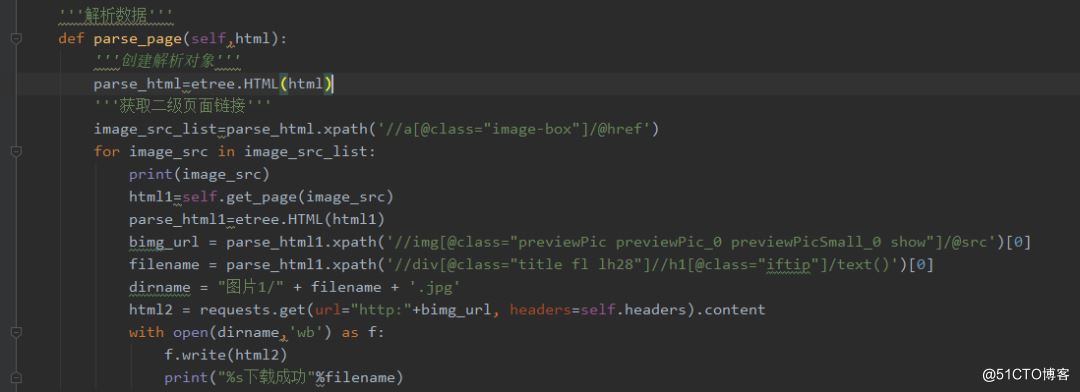
4、解析数据,使用xpath获取二级页面链接,最后把图片存储在文件夹中。使用谷歌浏览器选择开发者工具或直接按F12,发现我们需要的图片src是在img标签下的,于是用Python的requests提取该组件。

5、主函数,代码如下图所示。

【六、效果展示】
1、运行程序,在控制台输入你要爬取的页数,如下图所示。

2、在本地可以看到效果图,如下图所示。

【七、总结】
1、不建议抓取太多数据,容易对服务器造成负载,浅尝辄止即可。
2、希望通过这个项目,能够帮助大家下载到素材图片。
3、本文基于Python网络爬虫,利用爬虫库,实现素材图片的获取。实现的时候,总会有各种各样的问题,切勿眼高手低,勤动手,才可以理解的更加深刻。
到此这篇关于实操Python爬取觅知网素材图片示例的文章就介绍到这了,更多相关Python爬取觅知网素材图片内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python3直接爬取图片URL并保存示例
有时候我们会需要从网络上爬取一些图片,来满足我们形形色色直至不可描述的需求. 一个典型的简单爬虫项目步骤包括两步:获取网页地址和提取保存数据. 这里是一个简单的从图片url收集图片的例子,可以成为一个小小的开始. 获取地址 这些图片的URL可能是连续变化的,如从001递增到099,这种情况可以在程序中将共同的前面部分截取,再在最后递增并字符串化后循环即可. 抑或是它们的URL都保存在某个文件中,这时可以读取到列表中: def getUrls(path): urls = [] with open(
-
python3 爬取图片的实例代码
具体代码如下所示: #coding=utf8 from urllib import request import re import urllib,os url='http://tieba.baidu.com/p/3840085725' def get_image(url): #获取页面源码 page = urllib.request.urlopen(url) html = page.read() #解码,否则报错 html = html.decode('utf8') #正则匹配获取()的内容
-

Python爬虫之教你利用Scrapy爬取图片
Scrapy下载图片项目介绍 Scrapy是一个适用爬取网站数据.提取结构性数据的应用程序框架,它可以通过定制化的修改来满足不同的爬虫需求. 使用Scrapy下载图片 项目创建 首先在终端创建项目 # win4000为项目名 $ scrapy startproject win4000 该命令将创建下述项目目录. 项目预览 查看项目目录 win4000 win4000 spiders __init__.py __init__.py items.py middlewares.py pipelines
-
python爬虫爬取图片的简单代码
Python是很好的爬虫工具不用再说了,它可以满足我们爬取网络内容的需求,那最简单的爬取网络上的图片,可以通过很简单的方法实现.只需导入正则表达式模块,并利用spider原理通过使用定义函数的方法可以轻松的实现爬取图片的需求. 1.spider原理 spider就是定义爬取的动作及分析网站的地方. 以初始的URL**初始化Request**,并设置回调函数. 当该request**下载完毕并返回时,将生成**response ,并作为参数传给该回调函数. 2.实现python爬虫爬取图片 第一步
-
实操Python爬取觅知网素材图片示例
目录 [一.项目背景] [二.项目目标] [三.涉及的库和网站] [四.项目分析] [五.项目实施] [六.效果展示] [七.总结] [一.项目背景] 在素材网想找到合适图片需要一页一页往下翻,现在学会python就可以用程序把所有图片保存下来,慢慢挑选合适的图片. [二.项目目标] 1.根据给定的网址获取网页源代码. 2.利用正则表达式把源代码中的图片地址过滤出来. 3.过滤出来的图片地址下载素材图片. [三.涉及的库和网站] 1.网址如下: https://www.51miz.com/
-
python 爬取学信网登录页面的例子
我们以学信网为例爬取个人信息 **如果看不清楚 按照以下步骤:** 1.火狐为例 打开需要登录的网页–> F12 开发者模式 (鼠标右击,点击检查元素)–点击网络 –>需要登录的页面登录下–> 点击网络找到 一个POST提交的链接点击–>找到post(注意该post中信息就是我们提交时需要构造的表单信息) import requests from bs4 import BeautifulSoup from http import cookies import urllib impo
-
使用Python爬取最好大学网大学排名
本文实例为大家分享了Python爬取最好大学网大学排名的具体代码,供大家参考,具体内容如下 源代码: #-*-coding:utf-8-*- ''''' Created on 2017年3月17日 @author: lavi ''' import requests from bs4 import BeautifulSoup import bs4 def getHTMLText(url): try: r = requests.get(url) r.raise_for_status r.encodi
-
python爬取”顶点小说网“《纯阳剑尊》的示例代码
爬取"顶点小说网"<纯阳剑尊> 代码 import requests from bs4 import BeautifulSoup # 反爬 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, \ like Gecko) Chrome/70.0.3538.102 Safari/537.36' } # 获得请求 def open_url(url):
-
单身狗福利?Python爬取某婚恋网征婚数据
目标网址https://www.csflhjw.com/zhenghun/34.html?page=1 一.打开界面 鼠标右键打开检查,方框里为你一个文小姐的征婚信息..由此判断出为同步加载 点击elements,定位图片地址,方框里为该女士的url地址及图片地址 可以看出该女士的url地址不全,之后在代码中要进行url的拼接,看一下翻页的url地址有什么变化 点击第2页 https://www.csflhjw.com/zhenghun/34.html?page=2 点击第3页 https://
-
用Python爬取英雄联盟的皮肤详细示例
目录 一.推理原理 二.推理代码 第一步:获取js字典 第二步:从 js字典中提取到key值生成url列表 第三步:从 js字典中提取到value值生成name列表 第四步:下载并保存数据 第五步:执行主程序 一.推理原理 1.先去<英雄联盟>官网找到英雄及皮肤图片的网址: lol.qq.com 2.从上面网址可以看到所有英雄都在,按下F12查看源代码,发现英雄及皮肤图片并没有直接给出,而是隐藏在JS文件中. 这时候需要点开Network,找到js窗口,刷新网页,就看到一个champion.j
-
python 爬取免费简历模板网站的示例
代码 # 免费的简历模板进行爬取本地保存 # http://sc.chinaz.com/jianli/free.html # http://sc.chinaz.com/jianli/free_2.html import requests from lxml import etree import os dirName = './resumeLibs' if not os.path.exists(dirName): os.mkdir(dirName) headers = { 'User-Agent
-
python爬取微信公众号文章图片并转为PDF
遇到那种有很多图的微信公众号文章咋办?一个一个存很麻烦,应朋友的要求自己写了个爬虫.2.0版本完成了!完善了生成pdf的功能,可根据图片比例自动调节大小,防止超出页面范围,增加了序号方面查看 #-----------------settings--------------- #url='https://mp.weixin.qq.com/s/8JwB_SXQ-80uwQ9L97BMgw' print('jd3096 for king 2.0 VIP8钻石永久会员版') print('愿你远离流氓软
-
python爬取豆瓣电影排行榜(requests)的示例代码
''' 爬取豆瓣电影排行榜 设计思路: 1.先获取电影类型的名字以及特有的编号 2.将编号向ajax发送get请求获取想要的数据 3.将数据存放进excel表格中 ''' 环境部署: 软件安装: Python 3.7.6 官网地址:https://www.python.org/ 安装地址:https://www.python.org/ftp/python/3.7.6/python-3.7.6-amd64.exe PyCharm 2020.2.2
-
Python爬取个人微信朋友信息操作示例
本文实例讲述了Python爬取个人微信朋友信息操作.分享给大家供大家参考,具体如下: 利用Python的itchat包爬取个人微信号的朋友信息,并将信息保存在本地文本中 思路要点: 1.利用itchat.login(),实现微信号的扫码登录 2.通过itchat.get_friends()函数获取朋友信息 代码: 本文代码只获取了几个常用的信息,更多信息可从itchat.get_friends()中取 #获取个人微信号中朋友信息 #导入itchat包 import itchat #获取个人微信号