Python迅速掌握语音识别之知识储备篇
目录
- 概述
- RNN
- 计算
- RNN 存在的问题
- LSTM
- GRU
- Seq2seq
- Attention 模型
- Teacher Forcing 机制
概述
从今天开始我们将开启一个新的深度学习章节, 为大家来讲述一下深度学习在语音识别 (Speech Recognition) 的应用. 语音识别技术可以将语音转换为计算机可读的输入, 让计算机明白我们要表达什么, 实现真正的人机交互. 希望通过本专栏的学习, 大家能够对语音识别这一领域有一个基本的了解.

RNN
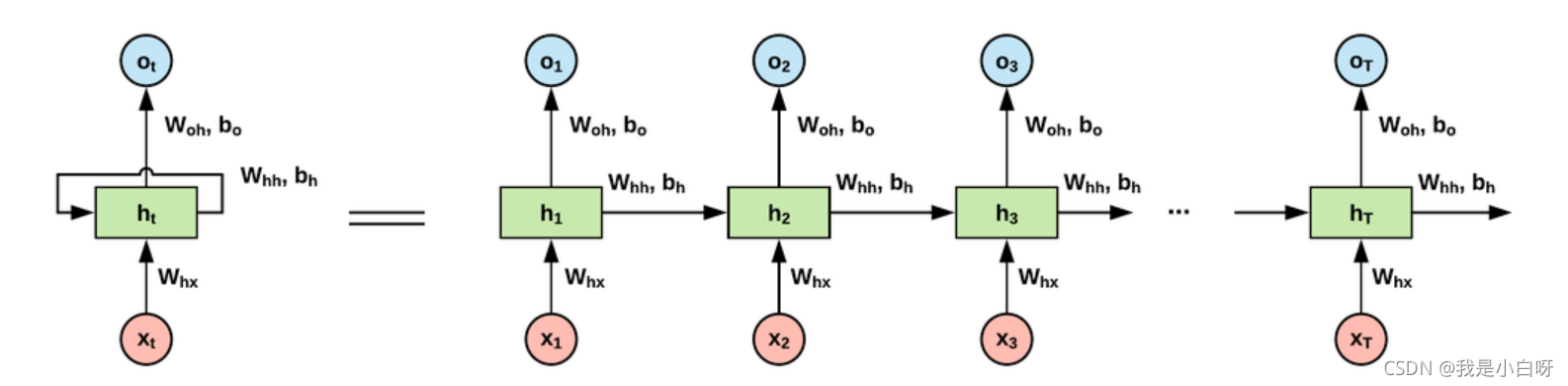
RNN (Recurrent Neural Network) 即循环神经网络, 用于处理输入有相关性的任务. RNN 网络包括一个输入层, 一个隐层, 和一个输出层组成, 如图:
计算
隐层 (Hidden Layer) 定义了整个网络的状态, RNN 网络的计算过程如下:
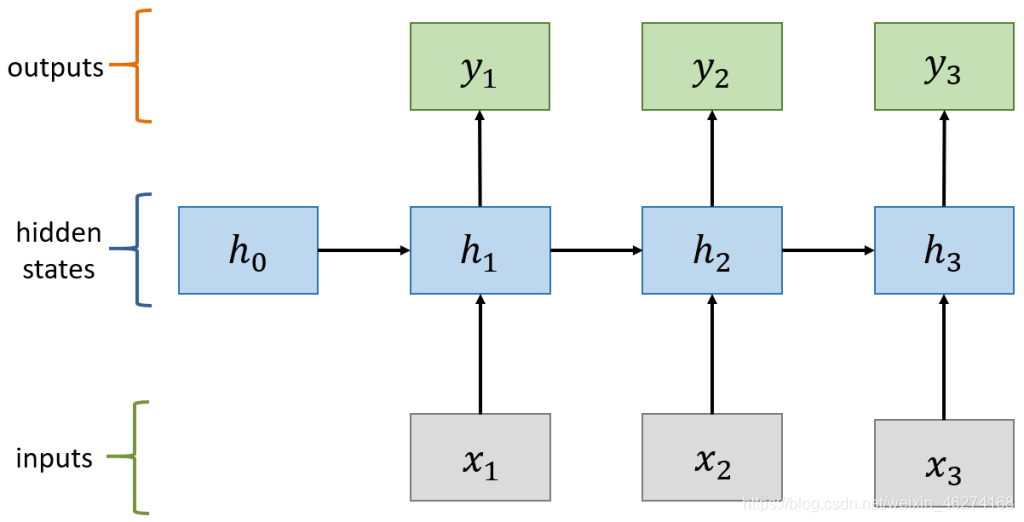
计算状态 (State)
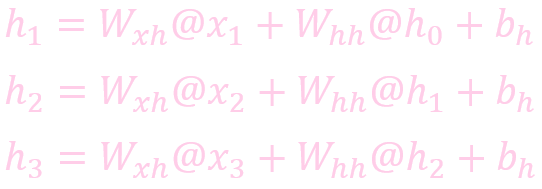
计算输出:

RNN 存在的问题
梯度消失问题 (Vanishing gradient problem). 如果导数小于 1, 随着网络层数的增加梯度跟新会朝着指数衰减的方向前进, 这就是梯度消失, 如图:

我们可以看出, 随着时间的增加, 深层的网络对浅层的感知变得越来越微弱, 梯度接近于0.
梯度爆炸问题 (Exploding gradient problem). 如果导数大于 1, 随着网络层数的增加梯度跟新会朝着指数增加的方向前进, 这就是梯度爆炸. 当 RNN 网络导数大于 1 时就会出现时序依赖, 从而造成梯度爆炸.

LSTM
LSTM (Long Short Term Memory), 即长短期记忆模型. LSTM 是一种特殊的 RNN 模型, 解决了长序列训练过程中的梯度消失和梯度爆炸的问题. 相较于普通 RNN, LSTM 能够在更长的序列中有更好的表现. 相比 RNN 只有一个传递状态 ht, LSTM 有两个传递状态: ct (cell state) 和 ht (hidden state).
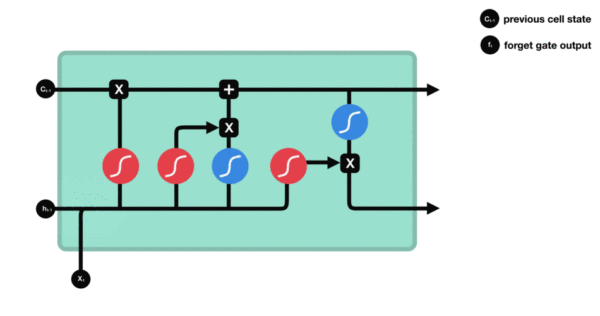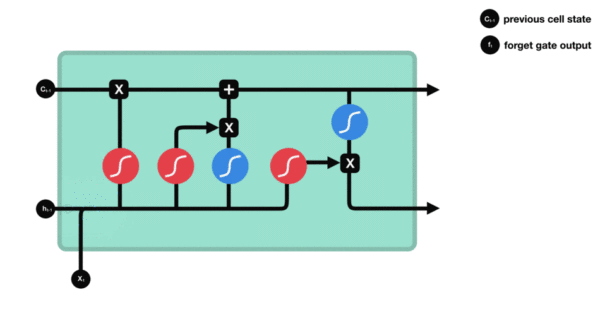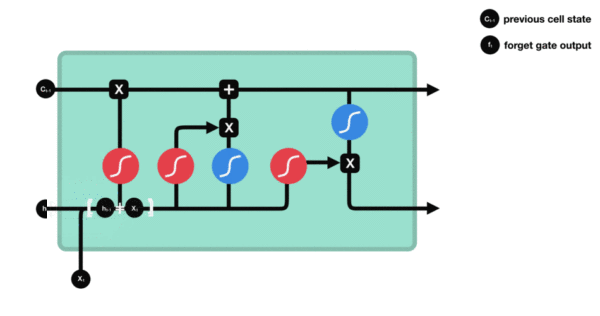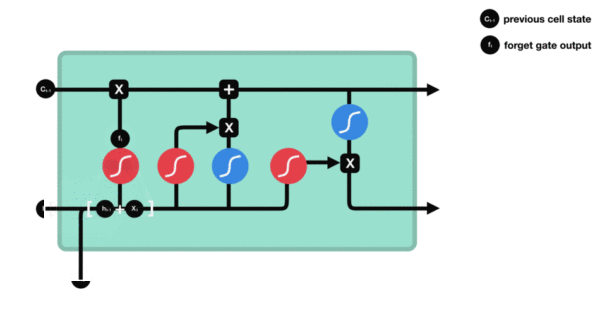
LSTM 增加了输入门, 输出门, 遗忘门 三个控制单元. LSTM 的 cell 会决定哪些信息被留下, 哪些信息被遗忘, 从而解决神经网络中长序列依赖的问题.
GRU
GRU (Gate Recurrent Unit) 和 LSTM 类似, 但是更易于计算. GRU 由重置门, 更新门, 和输出门组成. 重置门和 LSTM 的遗忘文作用一样, 用于决定信息的去留. 同理, 更新门的作用类似于 LSTM 的输入门.

Seq2seq
Seq2seq 由 Encoder 和 Decoder 两个 RNN 组成. Encoder 将变长序列输出, 编码成 encoderstate 再由 Decoder 输出变长序列.

Attention 模型
Attention 是一种用于提升 RNN 的 Encoder 和 Decoder 模型的效果的机制. 广泛应用于机器翻译, 语音识别, 图像标注等多个领域. 深度学习中的注意力机制从本质上讲和人类的选择性视觉注意力机制类似. 核心目标也是从众多信息中选择出对当前任务目标更关键的信息.
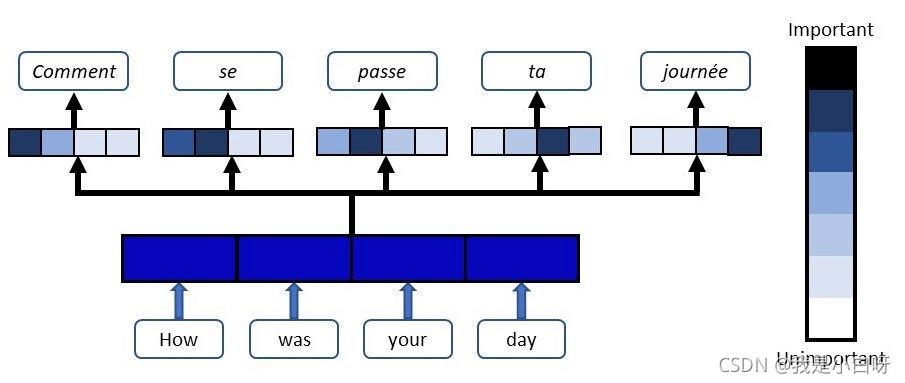
Attention 实质上是一种 content-based addressing 的机制. 即从网络中某些状态集合中选取给定状态较为相似的状态, 进而做后续的信息抽取.

首先根据 Encoder 和 Decoder 的特征计算权值, 然后对 Encoder 的特征进行加权求和, 作为 Decoder 的输入. 其作用的将 Encoder 的特征以更好的方式呈献给 Decoder. (并不是所有的 context 都对下一个状态的生成产生影响, Attention 就是选择恰当的 context 用它生成下一个状态.
Teacher Forcing 机制
早起的 RNN 在训练过程中的预测能力非常弱, 如果一个 unit 预测错了, 后面的 unit 就很难再获取对的结果. 比如我们翻译一句话:
- Life is like a box of chocolates.You never know what you're going to get
- 人生就像一盒巧克力,你永远也不知道下一块是什么味道
如果我们把 life 翻译成 “西伯利亚”, 那么后面再翻译对的可能性就几乎为 0.

Teacher Forcing 是一种网络训练的方法, 使用上一个 label 作为下一个 state 的输入. 还是用上面的例子说明: 当使用 Teacher Forcing 机制的时候, 即时我们把 life 翻译成 “西伯利亚”, 下一个 Decoder 的输入我们会使用上一个的 label 作为 state, 即 “人生”, 而不是 “西伯利亚”. 这样就大大提高了 RNN 网络的预测能力.
到此这篇关于Python迅速掌握语音识别之知识储备篇的文章就介绍到这了,更多相关Python 语音识别内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python版百度语音识别功能
本文实例为大家分享了python版百度语音识别功能的具体代码,供大家参考,具体内容如下 环境:使用的IDE是Pycharm 1.新建工程 2.配置百度语音识别环境 "File"--"Settings"打开设置面板,"Project"标签下添加Project Interpreter,点击右侧"+" 输入"baidu-aip",进行安装 新建测试文件 from aip import AipSpeech &quo
-
python语音识别的转换方法
使用pyttsx的python包,你可以将文本转换为语音. 安装命令 pip install pyttsx3 -i https://pypi.tuna.tsinghua.edu.cn/simple 运行一个简单的语音 '大家好'. import pyttsx3 as pyttsx engine = pyttsx.init() #初始化 engine.say('大家好') engine.runAndWait() 另一种文本转语音方法. from win32com.client import Dis
-
Python结合百度语音识别实现实时翻译软件的实现
一.所需库安装 pip install PyAudio pip install SpeechRecognition pip install baidu-aip pip install Wave pip install Wheel pip install Pyinstaller 二.百度官网申请服务 三.源代码分享 import pyaudio import wave from aip import AipSpeech import time # 用Pyaudio库录制音频 # out_file:
-
python语音识别指南终极版(有这一篇足矣)
[导读]亚马逊的 Alexa 的巨大成功已经证明:在不远的将来,实现一定程度上的语音支持将成为日常科技的基本要求.整合了语音识别的 Python 程序提供了其他技术无法比拟的交互性和可访问性.最重要的是,在 Python 程序中实现语音识别非常简单.阅读本指南,你就将会了解.你将学到: •语音识别的工作原理: •PyPI 支持哪些软件包; •如何安装和使用 SpeechRecognition 软件包--一个功能全面且易于使用的 Python 语音识别库. 语言识别工作原理概述 语音识别源于 20
-
使用Python和百度语音识别生成视频字幕的实现
从视频中提取音频 安装 moviepy pip install moviepy 相关代码: audio_file = work_path + '\\out.wav' video = VideoFileClip(video_file) video.audio.write_audiofile(audio_file,ffmpeg_params=['-ar','16000','-ac','1']) 根据静音对音频分段 使用音频库 pydub,安装: pip install pydub 第一种方法: #
-
Python实现语音识别和语音合成功能
声音的本质是震动,震动的本质是位移关于时间的函数,波形文件(.wav)中记录了不同采样时刻的位移. 通过傅里叶变换,可以将时间域的声音函数分解为一系列不同频率的正弦函数的叠加,通过频率谱线的特殊分布,建立音频内容和文本的对应关系,以此作为模型训练的基础. 案例:画出语音信号的波形和频率分布,(freq.wav数据地址) # -*- encoding:utf-8 -*- import numpy as np import numpy.fft as nf import scipy.io.wavfil
-
python录音并调用百度语音识别接口的示例
#!/usr/bin/env python import requests import json import base64 import pyaudio import wave import os import psutil #首先配置必要的信息 def bat(voice_path): baidu_server = 'https://aip.baidubce.com/oauth/2.0/token?' grant_type = 'client_credentials' client_id
-
python之语音识别speech模块
1.原理 语音操控分为 语音识别和语音朗读两部分. 这两部分本来是需要自然语言处理技能相关知识以及一系列极其复杂的算法才能搞定,可是这篇文章将会跳过此处,如果你只是对算法和自然语言学感兴趣的话,就只有请您移步了,下面没有一个字会讲述到这些内容. 早在上世纪90年代的时候,IBM就推出了一款极为强大的语音识别系统-vio voice , 而其后相关产品层出不穷,不断的进化和演变着. 我们这里将会使用SAPI实现语音模块. 2. 什么是SAPI? SAPI是微软Speech API , 是微软公司推
-
python3实现语音转文字(语音识别)和文字转语音(语音合成)
话不多说,直接上代码运行截图 1.语音合成 -------> 执行: 结果: 输入要转换的内容,程序直接帮你把转换好的mp3文件输出(因为下一步–语音识别–需要.pcm格式的文件,程序自动执行格式转换,同时生成17k.pcm文件,暂时不用管,(你也可以通过修改默认参数改变文件输出的位置,名称及是否进行pcm转换 <------- 2.语音处理 ----> 方便起见, 我们直接运行语音处理程序,识别我们上一步的17k.pcm文件: What?识别居然出现了点错误,不过不用担心,博主已经调
-
基于python实现百度语音识别和图灵对话
图例如下 https://github.com/Dongvdong/python_Smartvoice 上电后,只要周围声音超过 2000,开始录音5S 录音上传百度识别,并返回结果文字输出 继续等待,周围声音是否超过2000,没有就等待. 点用电脑API语音交互 代码如下 # -*- coding: utf-8 -*- # 树莓派 from pyaudio import PyAudio, paInt16 import numpy as np from datetime import datet