人工智能学习Pytorch梯度下降优化示例详解
目录
- 一、激活函数
- 1.Sigmoid函数
- 2.Tanh函数
- 3.ReLU函数
- 二、损失函数及求导
- 1.autograd.grad
- 2.loss.backward()
- 3.softmax及其求导
- 三、链式法则
- 1.单层感知机梯度
- 2. 多输出感知机梯度
- 3. 中间有隐藏层的求导
- 4.多层感知机的反向传播
- 四、优化举例
一、激活函数
1.Sigmoid函数
函数图像以及表达式如下:

通过该函数,可以将输入的负无穷到正无穷的输入压缩到0-1之间。在x=0的时候,输出0.5
通过PyTorch实现方式如下:

2.Tanh函数
在RNN中比较常用,由sigmoid函数变化而来。表达式以及图像如下图所示:

该函数的取值是-1到1,导数是:1-Tanh**2。
通过PyTorch的实现方式如下:

3.ReLU函数
该函数可以将输入小于0的值截断为0,大于0的值保持不变。因此在小于0的地方导数为0,大于0的地方导数为1,因此求导计算非常方便。

通过PyTorch的实现方式如下:

二、损失函数及求导
通常,我们使用mean squared error也就是均方误差来作为损失函数。
1.autograd.grad
torch.autograd.grad(loss, [w1,w2,...])
输入的第一个是损失函数,第二个是参数的列表,即使只有一个,也需要加上中括号。


我们可以直接通过mse_loss的方法,来直接创建损失函数。
在torch.autograd.grad中输入损失函数mse,以及希望求导的对象[w],可以直接求导。

注意:我们需要在创建w的时候,需要添加requires_grad=True,我们才能对它求导。
也可以通过w.requires_grad_()的方法,为其添加可以求导的属性。


2.loss.backward()
该方法是直接在损失函数上面调用的

这个方法不会返回梯度信息,而是将梯度信息保存到了参数中,直接用w.grad就可以查看。
3.softmax及其求导
该函数将差距较大的输入,转换成处于0-1之间的概率,并且所有概率和为1。

对softmax函数的求导:
设输入是a,通过了softmax输出的是p

注意:当i=j时,偏导是正的,i != j时,偏导是负的。
通过PyTorch实现方式如下:

三、链式法则
1.单层感知机梯度
单层感知机其实就是只有一个节点,数据*权重,输入这个节点,经过sigmoid函数转换,得到输出值。根据链式法则可以求得梯度。

通过PyTorch可以轻松实现函数转换以及求导。

2. 多输出感知机梯度
输出值变多了,因此节点变多了。但求导方式其实是一样的。

通过PyTorch实现求导的方式如下:
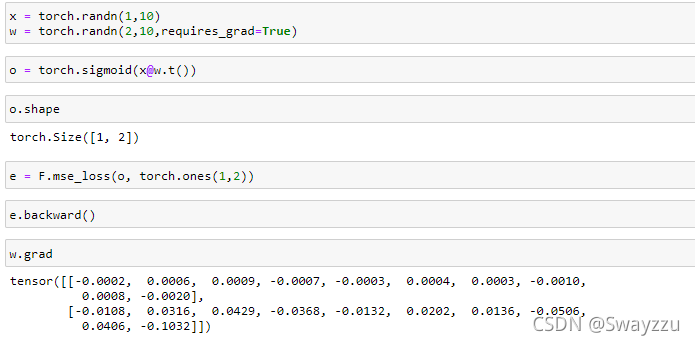
3. 中间有隐藏层的求导
中间加了隐藏层,只是调节了输出节点的输入内容。原本是数据直接输给输出节点,现在是中间层的输出作为输入,给了输出节点。使用PyTorch实现方式如下:

4.多层感知机的反向传播
依旧是通过链式法则,每一个结点的输出sigmoid(x)都是下一个结点的输入,因此我们通过前向传播得到每一个结点的sigmoid函数,以及最终的输出结果,算出损失函数后,即可通过后向传播依次推算出每一个结点每一个参数的梯度。
下面的DELTA(k)只是将一部分内容统一写作一个字母来表示,具体推导不再详述。

四、优化举例
通过以下函数进行优化。

优化流程:初始化参数→前向传播算出预测值→得到损失函数→反向传播得到梯度→对参数更新→再次前向传播→......
在此案例中,优化流程有一些不同:
优化之前先选择优化器,并直接把参数,以及梯度输入进去。
①pred = f(x)根据函数给出预测值,用以后面计算梯度。
②optimizer.zero_grad()梯度归零。因为反向传播之后,梯度会自动带到参数上去(上面有展示,可以调用查看)。
③pred.backward()用预测值计算梯度。
④pred.step()更新参数。
以上步骤循环即可。

以上就是人工智能学习Pytorch梯度下降优化示例详解的详细内容,更多关于Pytorch梯度下降优化的资料请关注我们其它相关文章!
相关推荐
-

人工智能学习Pytorch教程Tensor基本操作示例详解
目录 一.tensor的创建 1.使用tensor 2.使用Tensor 3.随机初始化 4.其他数据生成 ①torch.full ②torch.arange ③linspace和logspace ④ones, zeros, eye ⑤torch.randperm 二.tensor的索引与切片 1.索引与切片使用方法 ①index_select ②... ③mask 三.tensor维度的变换 1.维度变换 ①torch.view ②squeeze/unsqueeze ③expand,repea
-
Python人工智能深度学习CNN
目录 1.CNN概述 2.卷积层 3.池化层 4.全连层 1.CNN概述 CNN的整体思想,就是对图片进行下采样,让一个函数只学一个图的一部分,这样便得到少但是更有效的特征,最后通过全连接神经网络对结果进行输出. 整体架构如下: 输入图片 →卷积:得到特征图(激活图) →ReLU:去除负值 →池化:缩小数据量同时保留最有效特征 (以上步骤可多次进行) →输入全连接神经网络 2.卷积层 CNN-Convolution 卷积核(或者被称为kernel, filter, neuron)是要被学出来的,
-
人工智能学习Pytorch进阶操作教程
目录 一.合并与分割 1.cat拼接 2.stack堆叠 3.拆分 ①Split按长度拆分 ②Chunk按数量拆分 二.基本运算 1.加减乘除 2.矩阵相乘 3.次方计算 4. clamp 三.属性统计 1.求范数 2.求极值.求和.累乘 3. dim和keepdim 4.topk和kthvalue 5.比较运算 6.高阶操作 ①where ②gather 一.合并与分割 1.cat拼接 直接按照指定的dim维度进行合并,要求除了所需要合并的维度之外,其他的维度需要是一样的 2.stack堆叠
-
人工智能学习Pytorch张量数据类型示例详解
目录 1.python 和 pytorch的数据类型区别 2.张量 ①一维张量 ②二维张量 ③3维张量 ④4维张量 1.python 和 pytorch的数据类型区别 在PyTorch中无法展示字符串,因此表达字符串,需要将其转换成编码的类型,比如one_hot,word2vec等. 2.张量 在python中,会有标量,向量,矩阵等的区分.但在PyTorch中,这些统称为张量tensor,只是维度不同而已. 标量就是0维张量,只有一个数字,没有维度. 向量就是1维张量,是有顺序的数字,但没有"
-
人工智能学习Pytorch数据集分割及动量示例详解
目录 1.数据集分割 2.正则化 3.动量和学习率衰减 1.数据集分割 通过datasets可以直接分别获取训练集和测试集. 通常我们会将训练集进行分割,通过torch.utils.data.random_split方法. 所有的数据都需要通过torch.util.data.DataLoader进行加载,才可以得到可以使用的数据集. 具体代码如下: 2. 2.正则化 PyTorch中的正则化和机器学习中的一样,不过设置方式不一样. 直接在优化器中,设置weight_decay即可.优化器中,默认
-
人工智能学习Pytorch梯度下降优化示例详解
目录 一.激活函数 1.Sigmoid函数 2.Tanh函数 3.ReLU函数 二.损失函数及求导 1.autograd.grad 2.loss.backward() 3.softmax及其求导 三.链式法则 1.单层感知机梯度 2. 多输出感知机梯度 3. 中间有隐藏层的求导 4.多层感知机的反向传播 四.优化举例 一.激活函数 1.Sigmoid函数 函数图像以及表达式如下: 通过该函数,可以将输入的负无穷到正无穷的输入压缩到0-1之间.在x=0的时候,输出0.5 通过PyTorch实现方式
-
TensorFlow人工智能学习数据合并分割统计示例详解
目录 一.数据合并与分割 1.tf.concat() 2.tf.split() 3.tf.stack() 二.数据统计 1.tf.norm() 2.reduce_min/max/mean() 3.tf.argmax/argmin() 4.tf.equal() 5.tf.unique() 一.数据合并与分割 1.tf.concat() 填入两个tensor, 指定某维度,在指定的维度合并.除了合并的维度之外,其他的维度必须相等. 2.tf.split() 填入tensor,指定维度,指定分割的数量
-
基于Pytorch实现分类器的示例详解
目录 Softmax分类器 定义 训练 测试 感知机分类器 定义 训练 测试 本文实现两个分类器: softmax分类器和感知机分类器 Softmax分类器 Softmax分类是一种常用的多类别分类算法,它可以将输入数据映射到一个概率分布上.Softmax分类首先将输入数据通过线性变换得到一个向量,然后将向量中的每个元素进行指数函数运算,最后将指数运算结果归一化得到一个概率分布.这个概率分布可以被解释为每个类别的概率估计. 定义 定义一个softmax分类器类: class SoftmaxCla
-
Python深度学习pytorch神经网络图像卷积运算详解
目录 互相关运算 卷积层 特征映射 由于卷积神经网络的设计是用于探索图像数据,本节我们将以图像为例. 互相关运算 严格来说,卷积层是个错误的叫法,因为它所表达的运算其实是互相关运算(cross-correlation),而不是卷积运算.在卷积层中,输入张量和核张量通过互相关运算产生输出张量. 首先,我们暂时忽略通道(第三维)这一情况,看看如何处理二维图像数据和隐藏表示.下图中,输入是高度为3.宽度为3的二维张量(即形状为 3 × 3 3\times3 3×3).卷积核的高度和宽度都是2. 注意,
-
python神经网络学习数据增强及预处理示例详解
目录 学习前言 处理长宽不同的图片 数据增强 1.在数据集内进行数据增强 2.在读取图片的时候数据增强 3.目标检测中的数据增强 学习前言 进行训练的话,如果直接用原图进行训练,也是可以的(就如我们最喜欢Mnist手写体),但是大部分图片长和宽不一样,直接resize的话容易出问题. 除去resize的问题外,有些时候数据不足该怎么办呢,当然要用到数据增强啦. 这篇文章就是记录我最近收集的一些数据预处理的方式 处理长宽不同的图片 对于很多分类.目标检测算法,输入的图片长宽是一样的,如224,22
-
Go语言学习教程之反射的示例详解
目录 介绍 反射的规律 1. 从接口值到反射对象的反射 2. 从反射对象到接口值的反射 3. 要修改反射对象,该值一定是可设置的 介绍 reflect包实现运行时反射,允许一个程序操作任何类型的对象.典型的使用是:取静态类型interface{}的值,通过调用TypeOf获取它的动态类型信息,调用ValueOf会返回一个表示运行时数据的一个值.本文通过记录对reflect包的简单使用,来对反射有一定的了解.本文使用的Go版本: $ go version go version go1.18 dar
-
Git基础学习之分支操作的示例详解
目录 1.新建一个分支并且使分支指向指定的提交对象 2.思考 3.项目分叉历史的形成 4.分支的总结 1.新建一个分支并且使分支指向指定的提交对象 使用命令:git branch branchname commitHash. 我们现在本地库中只有一个 master 分支,并且在 master 分支有三个提交历史. 需求:创建一个 testing 分支,并且testing 分支指向 master 分支第二个版本. # 1.查看提交历史记录 L@DESKTOP-T2AI2SU MINGW64 /j/
-
React学习笔记之列表渲染示例详解
前言 本文主要给大家介绍了关于React列表渲染的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧. 示例详解: 列表渲染也很简单,利用map方法返回一个新的渲染列表即可,例如: const numbers = [1, 2, 3, 4, 5]; const listItems = numbers.map((number) => <li>{number}</li> ); ReactDOM.render( <ul>{listItems}<
-
Struts2学习教程之输入校验示例详解
前言 数据校验几乎是每个应用都要做的工作.用户输入的数据,发送到服务器端,天知道用户输入的数据是否是合法的,是否为恶意输入.所以一个健壮的应用系统必须对用户的输入进行校验,将非法的输入阻止在应用之外,防止这些非法的输入进入系统,从而保证系统的稳定性.安全性. 我们都知道,为了更好的用户体验,以及更高的效率,现在的Web应用都存在以下两重数据校验: 客户端数据校验 服务器端数据校验 对于客户端数据校验主要是通过JavaScript代码来完成:而对于服务器端数据校验是整个应用阻止非法数据的最后防线,