Python爬虫实战之爬取京东商品数据并实实现数据可视化
一、开发工具
Python版本:3.6.4
相关模块:
DecryptLogin模块;
argparse模块;
以及一些python自带的模块。
二、环境搭建
安装Python并添加到环境变量,pip安装需要的相关模块即可。
三、原理简介
原理其实挺简单的,首先,我们利用之前开源的DecryptLogin库来实现一下微博的模拟登录操作:
'''模拟登录京东'''
@staticmethod
def login():
lg = login.Login()
infos_return, session = lg.jingdong()
return session
然后写几行简单的代码来保存一下登录后的会话,省得每次运行程序都要先模拟登录京东:
if os.path.isfile('session.pkl'):
print('[INFO]: 检测到已有会话文件session.pkl, 将直接导入该文件...')
self.session = pickle.load(open('session.pkl', 'rb'))
self.session.headers.update({'Referer': ''})
else:
self.session = JDGoodsCrawler.login()
f = open('session.pkl', 'wb')
pickle.dump(self.session, f)
f.close()
接着去京东抓一波包,一样的套路,有种屡试不爽的感觉:

看看请求这个接口需要提交的参数:

我们可以简单分析一下每个参数的含义:
area: 不用管,可以看作一个固定值 enc: 指定编码, 可以看作固定值"utf-8" keyword: 搜索的关键词 adType: 不用管,可以看作一个固定值 page: 当前的页码 ad_ids: 不用管,可以看作一个固定值 xtest: 不用管,可以看作一个固定值 _: 时间戳
也就是说我们需要提交的params的内容大概是这样子的:
params = {
'area': '15',
'enc': 'utf-8',
'keyword': goods_name,
'adType': '7',
'page': str(page_count),
'ad_ids': '291:19',
'xtest': 'new_search',
'_': str(int(time.time()*1000))
}
构造好需要提交的params之后,只需要利用登录后的session去请求我们抓包得到的接口:
response = self.session.get(search_url, params=params)
然后从返回的数据里解析并提取我们需要的数据就可以啦:
response_json = response.json()
all_items = response_json.get('291', [])
for item in all_items:
goods_infos_dict.update({len(goods_infos_dict)+1:
{
'image_url': item.get('image_url', ''),
'price': item.get('pc_price', ''),
'shop_name': item.get('shop_link', {}).get('shop_name', ''),
'num_comments': item.get('comment_num', ''),
'link_url': item.get('link_url', ''),
'color': item.get('color', ''),
'title': item.get('ad_title', ''),
'self_run': item.get('self_run', ''),
'good_rate': item.get('good_rate', '')
}
})
四、数据可视化
老规矩,可视化一波我们爬取到的数据呗。以我们爬取到的无人机商品数据为例。首先,我们来看看京东里卖无人机的自营店和非自营店比例吧:

咦,竟然是非自营店占多。我一直以为京东基本都是自营店,虽然我基本不用京东。真是个天大的误解T_T。
接着,我们再来看看京东自己给的商品排名前10的那几家店的商品评论数量呗:
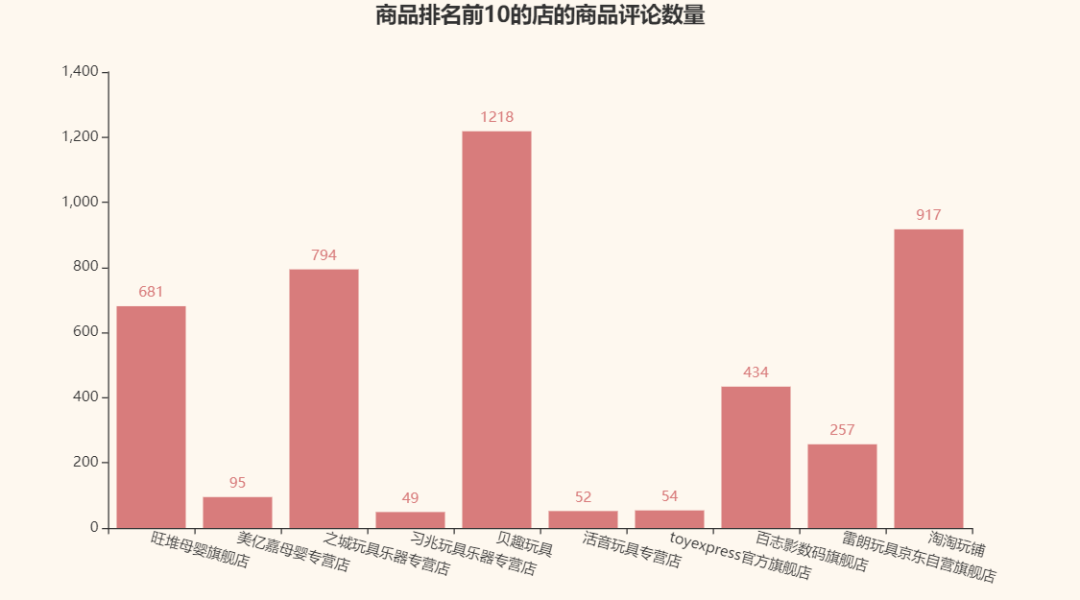
对比一下评论最多的店铺:

看来评论数量和京东给的商品排名并没有直接联系T_T,竟然没有一家店是重复的。
再来看看无人机相关商品的价格分布呗:
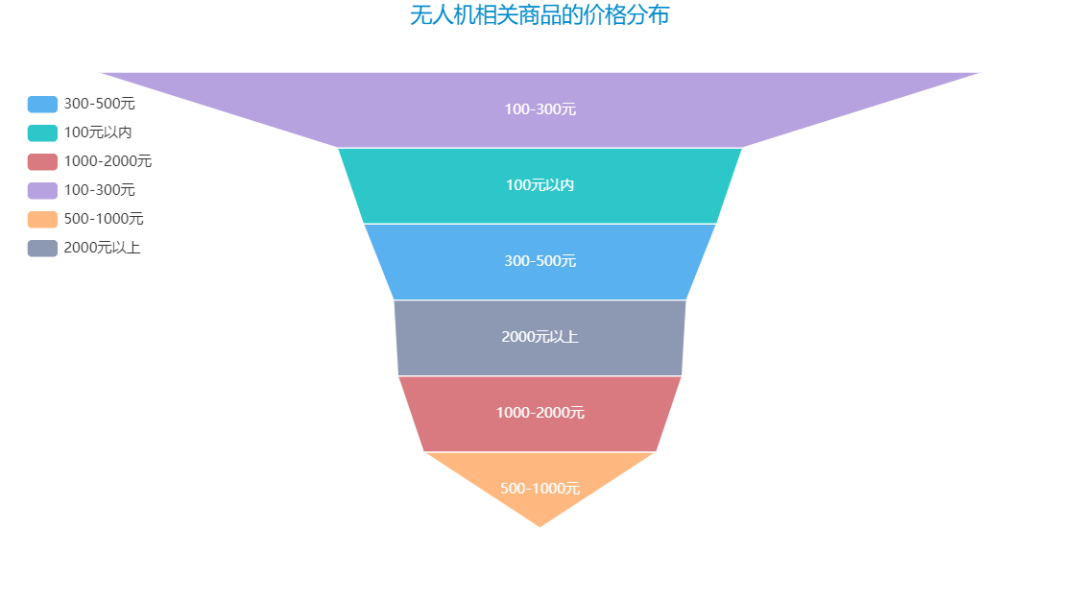
到此这篇关于Python爬虫实战之爬取京东商品数据并实实现数据可视化的文章就介绍到这了,更多相关Python可视化京东商品数据 内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python如何爬取网站数据并进行数据可视化
前言 爬取拉勾网关于python职位相关的数据信息,并将爬取的数据已csv各式存入文件,然后对csv文件相关字段的数据进行清洗,并对数据可视化展示,包括柱状图展示.直方图展示.词云展示等并根据可视化的数据做进一步的分析,其余分析和展示读者可自行发挥和扩展包括各种分析和不同的存储方式等..... 一.爬取和分析相关依赖包 Python版本: Python3.6 requests: 下载网页 math: 向上取整 time: 暂停进程 pandas:数据分析并保存为csv文件 matplotlib:
-
单身狗福利?Python爬取某婚恋网征婚数据
目标网址https://www.csflhjw.com/zhenghun/34.html?page=1 一.打开界面 鼠标右键打开检查,方框里为你一个文小姐的征婚信息..由此判断出为同步加载 点击elements,定位图片地址,方框里为该女士的url地址及图片地址 可以看出该女士的url地址不全,之后在代码中要进行url的拼接,看一下翻页的url地址有什么变化 点击第2页 https://www.csflhjw.com/zhenghun/34.html?page=2 点击第3页 https://
-
Python爬取数据并实现可视化代码解析
这次主要是爬了京东上一双鞋的相关评论:将数据保存到excel中并可视化展示相应的信息 主要的python代码如下: 文件1 #将excel中的数据进行读取分析 import openpyxl import matplotlib.pyplot as pit #数据统计用的 wk=openpyxl.load_workbook('销售数据.xlsx') sheet=wk.active #获取活动表 #获取最大行数和最大列数 rows=sheet.max_row cols=sheet.max_colum
-
Python爬虫之爬取某文库文档数据
一.基本开发环境 Python 3.6 Pycharm 二.相关模块的使用 import os import requests import time import re import json from docx import Document from docx.shared import Cm 安装Python并添加到环境变量,pip安装需要的相关模块即可. 三.目标网页分析 网站的文档内容,都是以图片形式存在的.它有自己的数据接口 接口链接: https://openapi.book11
-
Python爬虫之爬取2020女团选秀数据
一.先看结果 1.1创造营2020撑腰榜前三甲 创造营2020撑腰榜前三名分别是 希林娜依·高.陈卓璇 .郑乃馨 >>>df1[df1['排名']<=3 ][['排名','姓名','身高','体重','生日','出生地']] 排名 姓名 身高 体重 生日 出生地 0 1.0 希林娜依·高 NaN NaN 1998年07月31日 新疆 1 2.0 陈卓璇 168.0 42.0 1997年08月13日 贵州 2 3.0 郑乃馨 NaN NaN 1997年06月25日 泰国 1.2青春有
-
python爬虫之教你如何爬取地理数据
一.shapely模块 1.shapely shapely是python中开源的针对空间几何进行处理的模块,支持点.线.面等基本几何对象类型以及相关空间操作. 2.point→Point类 curve→LineString和LinearRing类: surface→Polygon类 集合方法分别对应MultiPoint.MultiLineString.MultiPolygon 3.导入所需模块 # 导入所需模块 from shapely import geometry as geo from s
-
Python爬取股票信息,并可视化数据的示例
前言 截止2019年年底我国股票投资者数量为15975.24万户, 如此多的股民热衷于炒股,首先抛开炒股技术不说, 那么多股票数据是不是非常难找, 找到之后是不是看着密密麻麻的数据是不是头都大了? 今天带大家爬取雪球平台的股票数据, 并且实现数据可视化 先看下效果图 基本环境配置 python 3.6 pycharm requests csv time 目标地址 https://xueqiu.com/hq 爬虫代码 请求网页 import requests url = 'https://xueq
-
Python爬虫之自动爬取某车之家各车销售数据
一.目标网页分析 目标网站是某车之家关于品牌汽车车型的口碑模块相关数据,比如我们演示的案例奥迪Q5L的口碑页面如下: https://k.autohome.com.cn/4851/#pvareaid=3311678 为了演示方式,大家可以直接打开上面这个网址,然后拖到全部口碑位置,找到我们本次采集需要的字段如下图所示: 采集字段 我们进行翻页发现,浏览器网址发生了变化,大家可以对下如下几页的网址找出规律: https://k.autohome.com.cn/4851/index_2.html#d
-
高考要来啦!用Python爬取历年高考数据并分析
开发工具 **Python版本:**3.6.4 相关模块: pyecharts模块: 以及一些Python自带的模块. 环境搭建 安装Python并添加到环境变量,pip安装需要的相关模块即可. pyecharts模块的安装可参考: Python简单分析微信好友 "一本正经的分析" 首先让我们来看看从恢复高考(1977年)开始高考报名.最终录取的总人数走势吧: T_T看来学生党确实是越来越多了. 不过这样似乎并不能很直观地看出每年的录取比例?Ok,让我们直观地看看吧: 看来上大学越来越
-
Python爬虫实战之爬取京东商品数据并实实现数据可视化
一.开发工具 Python版本:3.6.4 相关模块: DecryptLogin模块: argparse模块: 以及一些python自带的模块. 二.环境搭建 安装Python并添加到环境变量,pip安装需要的相关模块即可. 三.原理简介 原理其实挺简单的,首先,我们利用之前开源的DecryptLogin库来实现一下微博的模拟登录操作: '''模拟登录京东''' @staticmethod def login(): lg = login.Login() infos_return, session
-
python爬虫实战之爬取京东商城实例教程
前言 本文主要介绍的是利用python爬取京东商城的方法,文中介绍的非常详细,下面话不多说了,来看看详细的介绍吧. 主要工具 scrapy BeautifulSoup requests 分析步骤 1.打开京东首页,输入裤子将会看到页面跳转到了这里,这就是我们要分析的起点 2.我们可以看到这个页面并不是完全的,当我们往下拉的时候将会看到图片在不停的加载,这就是ajax,但是当我们下拉到底的时候就会看到整个页面加载了60条裤子的信息,我们打开chrome的调试工具,查找页面元素时可以看到每条裤子的信
-
Python爬虫实战之爬取某宝男装信息
目录 知识点介绍 实现步骤 1. 分析目标网站 2. 获取单个商品界面 3. 获取多个商品界面 4. 获取商品信息 5. 保存到MySQL数据库 完整代码 知识点介绍 本次爬取用到的知识点有: 1. selenium 2. pymysql 3 pyquery 实现步骤 1. 分析目标网站 1. 打开某宝首页, 输入"男装"后点击"搜索", 则跳转到"男装"的搜索界面. 2. 空白处"右击"再点击"检查"审
-
Python爬虫实战之爬取携程评论
一.分析数据源 这里的数据源是指html网页?还是Aajx异步.对于爬虫初学者来说,可能不知道怎么判断,这里辰哥也手把手过一遍. 提示:以下操作均不需要登录(当然登录也可以) 咱们先在浏览器里面搜索携程,然后在携程里面任意搜索一个景点:长隆野生动物世界,这里就以长隆野生动物世界为例,讲解如何去爬取携程评论数据. 页面下方则是评论数据 从上面两张图可以看出,点击评论下一页,浏览器的链接没有变化,说明数据是Ajax异步请求.因此我们就找到了数据是异步加载过来的,这时候需要去network里面是查
-
Python如何使用正则表达式爬取京东商品信息
京东(JD.com)是中国最大的自营式电商企业,2015年第一季度在中国自营式B2C电商市场的占有率为56.3%.如此庞大的一个电商网站,上面的商品信息是海量的,小编今天就带小伙伴利用正则表达式,并且基于输入的关键词来实现主题爬虫. 首先进去京东网,输入自己想要查询的商品,小编在这里以关键词"狗粮"作为搜索对象,之后得到后面这一串网址: https://search.jd.com/Search?keyword=%E7%8B%97%E7%B2%AE&enc=utf-8,其实参数%
-
python利用urllib实现爬取京东网站商品图片的爬虫实例
本例程使用urlib实现的,基于python2.7版本,采用beautifulsoup进行网页分析,没有第三方库的应该安装上之后才能运行,我用的IDE是pycharm,闲话少说,直接上代码! # -*- coding: utf-8 -* import re import os import urllib import urllib2 from bs4 import BeautifulSoup def craw(url,page): html1=urllib2.urlopen(url).read(
-
Python多线程爬虫实战_爬取糗事百科段子的实例
多线程爬虫:即程序中的某些程序段并行执行, 合理地设置多线程,可以让爬虫效率更高 糗事百科段子普通爬虫和多线程爬虫 分析该网址链接得出: https://www.qiushibaike.com/8hr/page/页码/ 多线程爬虫也就和JAVA的多线程差不多,直接上代码 ''' #此处代码为普通爬虫 import urllib.request import urllib.error import re headers = ("User-Agent","Mozilla/5.0
-
Python爬取京东商品信息评论存并进MySQL
目录 构建mysql数据表 第一版: 第二版 : 第三版: 构建mysql数据表 问题:使用SQL alchemy时,非主键不能设置为自增长,但是我想让这个非主键仅仅是为了作为索引,autoincrement=True无效,该怎么实现让它自增长呢? from sqlalchemy import String,Integer,Text,Column from sqlalchemy import create_engine from sqlalchemy.orm import sessionmake
-
python爬虫之Appium爬取手机App数据及模拟用户手势
目录 Appium 模拟操作 屏幕滑动 屏幕点击 屏幕拖动 屏幕拖拽 文本输入 动作链 实战:爬取微博首页信息 Appium 在前文的讲解中,我们学会了如何安装Appium,以及一些基础获取App元素内容的方式.但认真看过前文的读者,肯定在博主获取元素的时候观察到了一个现象. 那就是手机App的内容并不是一次性加载出来的,比如大多数Android手机列表ListView,都是异步加载,也就是你滑动到那个位置,它才会显示出它的内容. 也就是说,我们前面爬取微博首页全部信息的时候,如果你不滑动先加载
-
Python爬虫DOTA排行榜爬取实例(分享)
1.分析网站 打开开发者工具,我们观察到排行榜的数据并没有在doc里 doc文档 在Javascript里我么可以看到下面代码: ajax的post方法异步请求数据 在 XHR一栏里,我们找到所请求的数据 json存储的数据 请求字段为: post请求字段 2.伪装浏览器,并将json数据存入excel里面 获取信息 将数据保存到excel中 3.结果展示 以上这篇Python爬虫DOTA排行榜爬取实例(分享)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.